ES是什么?
来自官方文档的解释:
基于Luence的开源搜索引擎,有以下特性
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
可以看到ES是一个搜索引擎,能提供高性能的搜索分析功能。和平时使用最多的MySQL这种关系型数据库有着概念级别的区别。
解决什么问题
存放在关系型数据库中的数据也经常被检索,但是有着明显的痛点,就是只能简单地针对某一个字段进行搜索,在有复杂的搜索需求的时候会束手无策。
在有复杂数据分析聚合的业务下,MySQL这种的group by 有着较差的性能,难以快速实时地进行聚合分析。
关系型数据库扩展的代价较大,当有数据分区的时候,有很多查询都会受限制,管理也相对复杂。
ES就是为解决搜索 ,数据聚合,扩展这几大痛点而生的。
如何组织数据
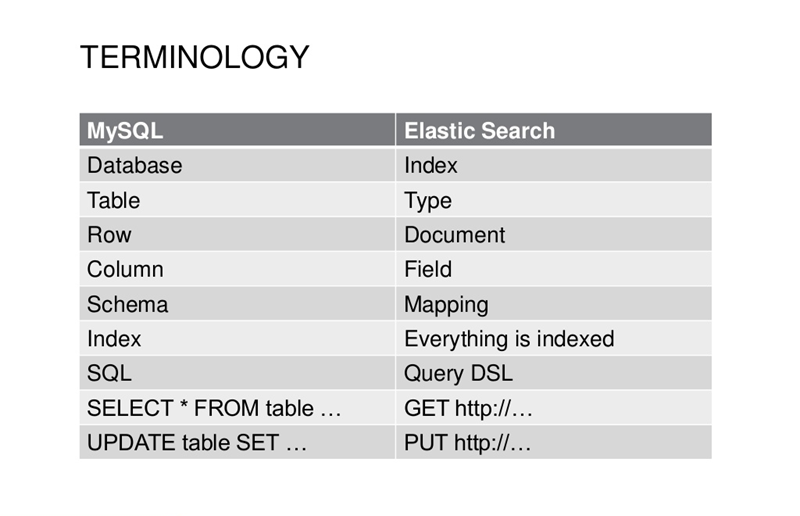
用MySQL做对比。MySQL里面是以 库>表>行 这种层级单位来组织数据。一个项目可以对应一个库,这个库下面有很多表,每张表下面有很多行,最小的完整数据实体是`行`。
在ES中,对应的层级关系是 索引>类型>文档。一个索引下面可以有多个类型(后面据说只会支持一个类型),每个类型下面有多个文档。 最小的完整数据实体是文档,这个和MongoDB有些类似。
例如储存在MySQL中的program库中的users表的小明的数据:
+----+------+-------------+--------------+ | id | name | email | phone | +----+------+-------------+--------------+ | 1 |小明 | [email protected] | 157****1171 | +----+------+-------------+--------------+
现在要将这条数据导入ES中,在ES中的储存方式大概是这样:
program(索引)> users(类型)
# 文档
{
"name" : "小明",
"email": "[email protected]",
"phone": 157***
}
如何增删改查数据
关系型数据库通过SQL语句对数据进行增删改查,ES会启动一个HTTP服务,客户端通过REST API接口来对数据进行增删改查。
为什么ES能做全文检索
传统的关系型数据库的索引,是针对某一张表的一个或多个字段,将索引数据有序地组织在B树之上,这样有以下缺点:
- 索引是针对某一个或多个字段,当数据分布在多张表的多个字段上时,要检索数据,就需要遍历相关的所有索引。这在数据分散的情况下是难以接受的
- 索引的匹配粒度太大。输入的检索数据需要和索引的字段数据高度匹配,不然不能成功匹配。一般都有最左前缀的限制,对细粒度的数据匹配无能为力
这就导致了很多关系型数据库是无法进行全文检索的,那么ES是如何做的呢? 答案是 倒排索引(inverted index)
根据吴军的《数学之美》中介绍的搜索引擎的原理: 互联网上有超过百亿数量级的文档,在搜索引擎中输入关键字就能查找到相关的文档。这个时候,如果针对文档做索引,那么查询时就需要遍历所有的文档索引,这显然是不可能的,常规的索引思路是不可行的。
倒排索引换了一个角度,也可以叫反向索引。通过对关键词建立索引,记录每一个独立关键词和所有文档的关联关系,这个关联关系就是倒排索引。
索引的数据部分是一个超长的二进制串,它的长度等于互联网上所有文档数量的总数。每一个文档在搜索引擎中都有一个编号,编号和二进制串的位依次对应,编号为1的文档就对应二进制串中的第0位。如果某个关键词和该文档有关联,那么对应的这个二进制bit就为1,反之为0 。这样就可以让每个关键词和所有文档建立一个关联关系。举个例子:
美女 0101000000000000000000000··
上面就是美女这个关键词对应的索引,它表示着 编号为 2和4 的文档中包含此关键词。当搜索美女这个词时,就可以直接将这两片文档呈现给用户。
当用户 搜索 “中国长腿美女”的时候,搜索引擎会将词条分词为 “中国” “长腿” “美女”
中国 0100000010001000001001000·· 长腿 0100000001000001000000000··
上面是其他两个词的索引,当搜索三个词的时候,搜索引擎会将他们对应的二进制串做 & ,得到的结果就是
0100000000000000000000000··
意思就是,编号为2的文档满足此次搜索的所有关键词,则将文档2 呈现给用户。这是最简单的概念呈现,实际的情况复杂度高非常多。
ES中也是以这种思路建立倒排索引,他会记录某个词在出现在了哪些文档中,出现在什么位置(包括起始),根据官方文档,索引大概是这样的:
有两片文档:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
索引结构为:
Term Doc_1 Doc_2 ------------------------- Quick | | X The | X | brown | X | X dog | X | dogs | | X fox | X | foxes | | X in | | X jumped | X | lazy | X | X leap | | X over | X | X quick | X | summer | | X the | X | ------------------------
和上面介绍的原理几乎一致。但实际的数据结构目前不得而知(还需要学习),因为搜索结果需要有相关性排序,所以还有很多数据需要储存,例如: 在文档中出现的次数,是否出现在标题中,不同的字段有不同的权重等等。
ES是以面向文档的方式储存对象。不像关系型数据库以严格的行和列来结构化数据,在每次查询时又根据格式重新构造出对象。ES将对象作为一个整体以一个文档的形式保存,并对整个文档进行索引,这样ES就可以支持针对文档的复杂的搜索需求。
ES是基于Java的,安装一个试试吧。