一、简单查询
1.1 查询全部
请求方式: GET
请求路径: ES服务的IP:端口/索引名/{分组,可省略}/_search
以上篇文章建立的索引为例,搜索结果如下:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "user",
"_type": "novel",
"_id": "Bg36UmYBBzXJKYP4RwNP",
"_score": 1,
"_source": {
"name": "zhangsan",
"age": 15,
"create_date": "2018-05-20"
}
},
{
"_index": "user",
"_type": "novel",
"_id": "1",
"_score": 1,
"_source": {
"name": "jitwxs",
"age": 20,
"create_date": "2018-10-08"
}
}
]
}
}
默认情况下,是查询出来10条数据,并且按照score的降序排列的(因为搜索全部,这里没有score,当条件搜索的时候,会出现)。其中部分属性含义如下:
| 属性 | 含义 |
|---|---|
| took | Elasticsearch执行搜索的时间(ms) |
| timed_out | 请求是否超时 |
| _shards | 搜索了碎片成功/失败次数 |
| hits | 搜索结果 |
| hits.total | 符合我们搜索条件的文件总数 |
| hits.hits | 实际的搜索结果数组 |
| hits.sort | 对结果进行排序的键(默认使用score排序时隐藏) |
| hits.hits._score与hits.max_score | 单个结果的匹配程度和最高的匹配程度 |
| hits.hits._source | 搜索到的结果 |
1.2 单条件查询
-
match:match查询的时候,Elasticsearch会根据你给定的字段提供合适的分析器,将查询语句分词之后去匹配含有分词之后的词语。 -
term:不进行分词,直接完全匹配查询。
需要注意的是:如果你搜索的字段是keyword类型,那么无论match和term都是一样的,都不进行分词(在上篇字段数据类型中说过)。
//match进行查询
GET user/novel/_search
{
"query": {
"match": {
"name": "jitwxs"
}
}
}
//term进行查询
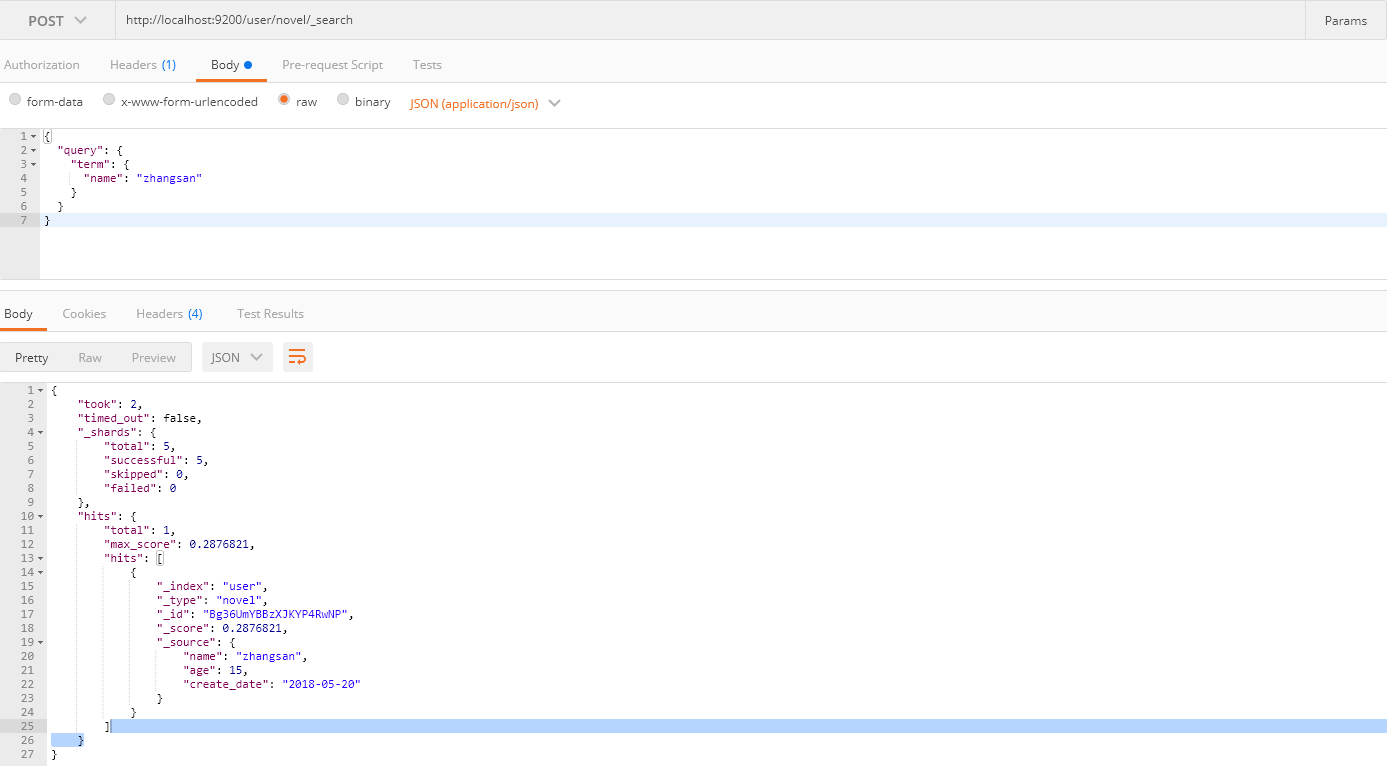
GET user/novel/_search
{
"query": {
"term": {
"name": "zhangsan"
}
}
}
你可能注意到我下面的截图并没有使用GET请求,这是因为我没有找到Postman GET请求附带请求体的方法,因此使用POST请求来查询,当然官方推荐使用GET请求。如果你安装有curl工具,可以使用这种方式请求:
curl 'localhost:9200/user/novel/_search' -d '{"query":{"match":{"name":"jitwxs"}}}'

1.3 多条件查询
请求方式和单条件查询一致,请求体形如:
{
"query": {
"bool": {
"must": {
"match": {
"email": "business opportunity"
}
},
"should": [{
"match": {
"starred": true
}
},
{
"bool": {
"must": {
"match": {
"folder": "inbox"
}
},
"must_not": {
"match": {
"spam": true
}
}
}
}
]
}
}
}
其中bool可以用来实现多条件查询,bool包含的属性如下:
| 属性 | 含义 |
|---|---|
| must | 必须匹配的属性,匹配这些条件才能被包含进来 |
| must_not | 不能匹配这些条件才能被包含进来 |
| should | 如果满足这些语句中的任意语句,将增加 _score ,否则无任何影响。主要用于修正每个文档的相关性得分 |
| filter | 必须匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档 |
1.4 排序、分页
GET user/novel/_search
{
"query": {
"match": {
"name": "jitwxs"
}
},
"from": 0,
"size":10,
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
from表示分页开始的条数(从0开始),size表示你要查询的数量,sort表示排序的字段,order表示排序方式。
二、中文分词
2.1 下载IK分词器
默认的分词器对中文很差,这里还是使用我们的老朋友——IK分词器,到elasticsearch-analysis-ik下载与版本对应的IK分词器。

解压并将将文件复制到Elasticsearch的安装目录/plugin/ik下面即可,完成之后效果如下:

重新启动Elasticsearch服务。
以对“我是中国人”分词为例,使用默认分词结果:
POST http://localhost:9200/_analyze
{
"text":"我是中国人"
}
// 响应内容
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "中",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "国",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "人",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
}
]
}
IK分词器结果:
POST http://localhost:9200/_analyze
{
"analyzer": "ik_max_word",
"text":"我是中国人"
}
// 响应内容
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "中国",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "国人",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}
对于上面两个分词效果的解释:
-
如果未安装IK分词器,那么,你如果写 “analyzer”: “ik_max_word”,那么程序就会报错,因为你没有安装IK分词器
-
如果你安装了IK分词器之后,你不指定分词器,不加上 “analyzer”: “ik_max_word” 这句话,那么其分词效果跟你没有安装IK分词器是一致的,也是分词成每个汉字。
2.2 创建指定分词器的索引
索引创建之后就可以使用IK进行分词了,当你使用ES搜索的时候也会使用ik对搜索语句进行分词,进行匹配。下面给出一个例子以供参考:
PUT http://localhost:9200/book
{
"settings":{
"number_of_shards": "6",
"number_of_replicas": "1",
"analysis":{
"analyzer":{
"ik":{
"tokenizer":"ik_max_word"
}
}
}
},
"mappings":{
"novel":{
"properties":{
"author":{
"type":"text"
},
"wordCount":{
"type":"integer"
},
"publishDate":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss || yyyy-MM-dd"
},
"bookName":{
"type":"text"
}
}
}
}
}
关于IK分词器的分词类型(可以根据需求进行选择):
-
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合; -
ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。