子查询篇
子查询
说白了子查询就是嵌套查询
SQL 中子查询的使用大大增强了 SELECT 查询的能力
因为很多时候查询需要从结果集中获取数据,或者需要从同一个表中先计算得出一个数据结果,然后与这个数据结果(可能是某个标量,也可能是某个集合)进行比较。
需求分析
如果我们遇见下面这种问题,就要用到子查询了

现有方法:
- 先查出Abel的工资,然后那结果在查询一次进行筛选
#方式一:
SELECT salary
FROM employees
WHERE last_name = 'Abel';
SELECT last_name,salary
FROM employees
WHERE salary > 11000;
- 自连接
SELECT
e2.last_name,
e2.salary
FROM
employees e1,
employees e2
WHERE
e1.last_name = 'Abel'
AND e1.`salary` < e2.`salary`
- 子查询
SELECT
last_name,
salary
FROM
employees
WHERE
salary > (
SELECT
salary
FROM
employees
WHERE
last_name = 'Abel')
子查询的分类
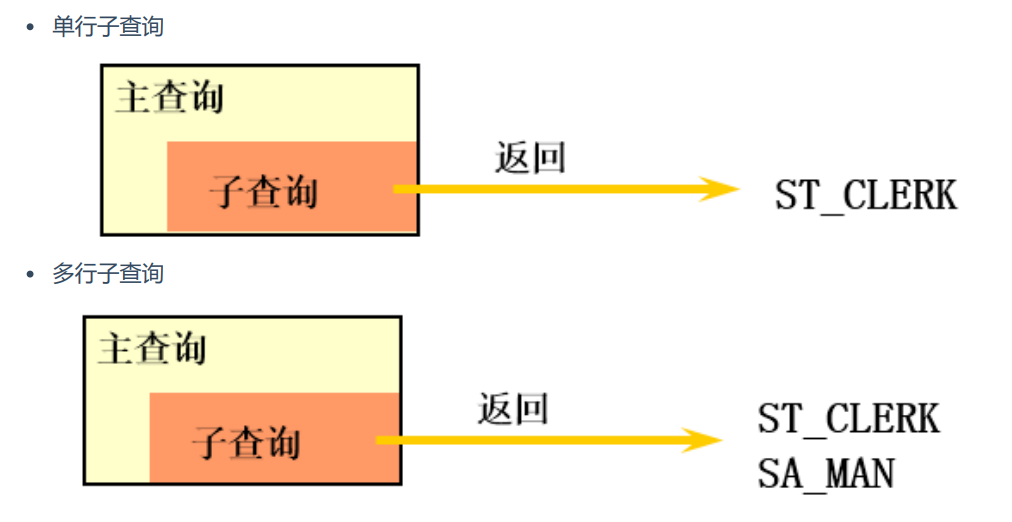
单行、多行子查询
按查询的结果返回一条还是多条记录,将子查询分为单行子查询、多行子查询
- 子查询(内查询)在主查询之前一次执行完成。
- 子查询的结果被主查询(外查询)使用 。
- 注意事项
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧(提高可读性)
- 单行操作符对应单行子查询,多行操作符对应多行子查询
- 单行子查询就是子查询查出的结果就一条
- 多行子查询就是子查询查出的结果不止一条
相关、不相关子查询
我们按内查询是否被执行多次,将子查询划分为 相关(或关联)子查询 和 不相关(或非关联)子查询 。
子查询从数据表中查询了数据结果,如果这个数据结果只执行一次,然后这个数据结果作为主查询的条 件进行执行,那么这样的子查询叫做不相关子查询。(子查询的结果是固定的)
同样,如果子查询需要执行多次,即采用循环的方式,先从外部查询开始,每次都传入子查询进行查 询,然后再将结果反馈给外部,这种嵌套的执行方式就称为相关子查询。(子查询的结果不固定,会根据外面传过来的值改变)
单行子查询
单行比较操作符
什么是单行操作符
就是它只能匹配一行数据,如果你的子查询查出了多条数据,那么它就报错

代码示例
题目:查询工资大于149号员工工资的员工的信息
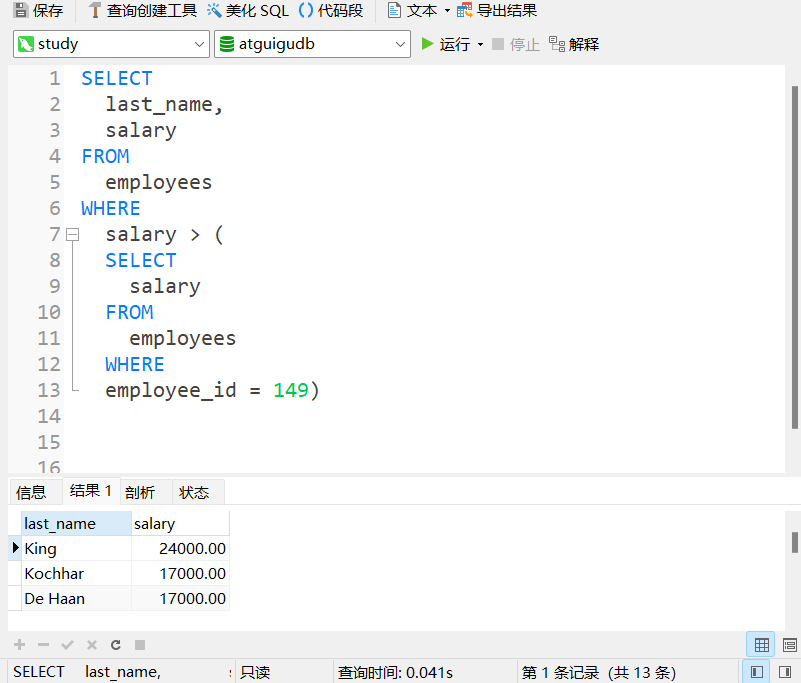
题目:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
写子查询什么思路呢?
根据题目,先单独写出子查询,最后添加到查询语句中
比如题目说返回job_id与141号员工相同,那我们就可以先写出141号员工的job_id是多少的查询语句,之后在放到总查询语句中
SELECT
last_name,
job_id,
salary
FROM
employees
WHERE
job_id = ( SELECT job_id FROM employees WHERE employee_id = 141 )
AND salary > ( SELECT salary FROM employees WHERE employee_id = 143 )
题目:返回公司工资最少的员工的last_name,job_id和salary
先通过子查询获得工资最少的工资数,然后把这个当成筛选条件获取是谁的工资这么低
SELECT
last_name,
job_id,
salary
FROM
employees
WHERE
salary = ( SELECT MIN(salary) FROM employees )
题目:查询与141号或174号员工的manager_id和department_id相同的其他员工的employee_id, manager_id,department_id
最后的AND employee_id NOT IN (174, 141);是为了去掉141、174员工它们本身,因为题目要求是求其他员工的…
这里的IN属于多行子查询操作符,这里提前用到了。因为子查询结果不唯一
-- 不成对比较
SELECT
employee_id,
manager_id,
department_id
FROM
employees
WHERE
manager_id IN ( SELECT manager_id FROM employees WHERE employee_id IN ( 174, 141 ) )
AND department_id IN ( SELECT department_id FROM employees WHERE employee_id IN ( 174, 141 ) )
AND employee_id NOT IN ( 174, 141 );
(manager_id,department_id)这里为什么要给条件加上括号呢?
和后面的结果做匹配
-- 成对比较
SELECT
employee_id,
manager_id,
department_id
FROM
employees
WHERE
( manager_id, department_id ) IN ( SELECT manager_id, department_id FROM employees WHERE employee_id IN ( 174, 141 ) )
AND employee_id NOT IN ( 174, 141 );
HAVING 中的子查询
-
首先执行子查询。
-
向主查询中的HAVING 子句返回结果。
题目:查询最低工资大于50号部门最低工资的部门id和其最低工资
SELECT
department_id,
MIN( salary )
FROM
employees
GROUP BY
department_id
HAVING
MIN( salary ) > ( SELECT MIN( salary ) FROM employees WHERE department_id = 50 );
CASE中的子查询
题目:显式员工的employee_id,last_name和location。其中,若员工department_id与location_id为1800 的department_id相同,则location为’Canada’,其余则为’USA’。
若员工department_id与location_id为1800的department_id相同,则location为’Canada’,其余则为’USA’
这题明显的CASE,也就是SWITCH形式的
1、根据location_id为1800的department_id先写出这个查询
2、然后CASE后面跟的条件就是department_id,拿CASE后面跟的条件去和子查询查出的条件相比即可
3、给它起个别名location
SELECT
employee_id,
last_name,
( CASE department_id WHEN ( SELECT department_id FROM departments WHERE location_id = 1800 ) THEN location = 'Canada' ELSE 'USA' END ) location
FROM
employees;
空值问题
意思就是子查询查出来的结果是空值,导致外面的查询对应的结果也是空值
SELECT
last_name,
job_id
FROM
employees
WHERE
job_id = ( SELECT job_id FROM employees WHERE last_name = 'Haas' );
非法使用子查询
Subquery returns more than 1 row
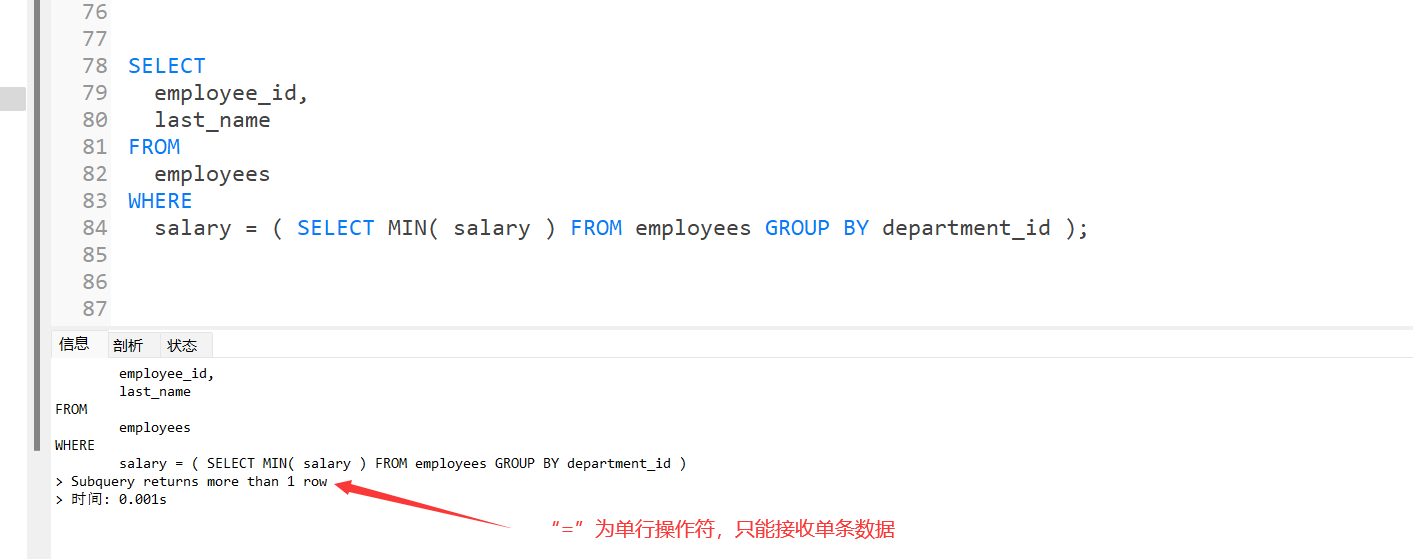
多行子查询
什么是多行子查询?
- 内查询返回多行
- 使用多行比较操作符
多行比较操作符
| 操作符 | 含义 |
|---|---|
| IN | 等于列表中的任意一个 |
| ANY | 需要和单行比较操作符一起使用,和子查询返回的某一个值去比较 |
| ALL | 需要和单行比较操作符一起使用,使子查询返回所有值比较 |
| SOME | 实际上是ANY的别名,作用相同,一般常使用ANY |
代码示例
题目:返回其它job_id中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id 以及salary
-- 1、job_id为‘IT_PROG’部门员工的工资
SELECT salary FROM employees WHERE job_id = 'IT_PROG'
-- 2、比上面任一结果低的信息
SELECT
employee_id,
last_name,
job_id,
salary
FROM
employees
WHERE
job_id <> 'IT_PROG'
AND salary < ANY ( SELECT salary FROM employees WHERE job_id = 'IT_PROG' );
题目:返回其它job_id中比job_id为‘IT_PROG’部门所有工资都低的员工的员工号、姓名、job_id以及salary
SELECT
employee_id,
last_name,
job_id,
salary
FROM
employees
WHERE
job_id <> 'IT_PROG'
AND salary < ALL ( SELECT salary FROM employees WHERE job_id = 'IT_PROG' );
题目:查询平均工资最低的部门id
1、这道题的关键就是要把查出来的平均工资数据当成一个新的表来查
2、聚合函数不能嵌套查询(MIN(AVG(SALARY)))
3、派生表要有自己的别名,不然会出现如下错误:
Every derived table must have its own alias(每个派生表都必须有自己的别名)
4、为了最后结果SQL的美观,前面做的小查询最好把它写成简写形式
-- 1.每个部门的平均工资
SELECT AVG(salary) FROM employees WHERE department_id IS NOT NULL GROUP BY department_id;
-- 2.平均工资最低
SELECT MIN(avg_salary) FROM (
SELECT AVG(salary) avg_salary FROM employees WHERE department_id IS NOT NULL GROUP BY department_id) avg_emp_salary
-- 3.平均工资最低的部门
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
AVG( salary ) = ( SELECT MIN( avg_salary ) FROM ( SELECT AVG( salary ) avg_salary FROM employees WHERE department_id IS NOT NULL GROUP BY department_id ) avg_emp_salary );
方式二:让平均工资小于所有平均工资最小的,那直接就满足条件了
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
AVG( salary ) <= ALL ( SELECT AVG( salary ) FROM employees GROUP BY department_id );
空值问题
意思就是子查询查出来的结果是空值,导致外面的查询对应的结果也是空值
SELECT last_name
FROM employees
WHERE employee_id NOT IN (
SELECT manager_id
FROM employees
)
相关子查询
相关子查询执行流程
子查询的结果不固定,会根据外面传过来的值改变
相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。
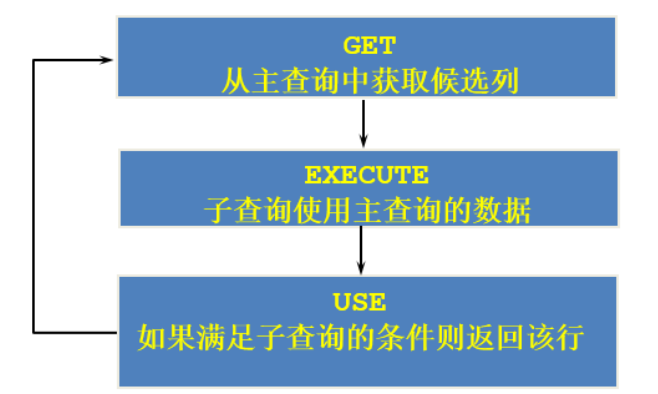
子查询中使用主查询中的列,这句话是重点!
代码示例
题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
方式一:相关子查询
在内部查询中使用外部的表建立关联关系即可实现相关子查询
举个例子:
当外部查出第一条数据的时候department_id为10,那么进到子查询就是查department_id为10的平均工资
当外部查出第二条数据的时候department_id为20,那么进到子查询就是查department_id为20的平均工资
…
-- 1.60号部门的平均工资
SELECT AVG(salary) FROM employees WHERE department_id=60
-- 2.员工中工资大于60号部门的平均工资
SELECT
last_name,
salary
FROM
employees
WHERE
salary > (SELECT AVG(salary) FROM employees WHERE department_id=60)
-- 3.那本部门怎么表示呢?
-- 在内部查询中使用外部的表建立关联关系即可
SELECT
last_name,
salary
FROM
employees e1
WHERE
salary > (SELECT AVG(salary) FROM employees e2 WHERE department_id=e1.department_id);
方式二:在 FROM 中使用子查询
1、先把部门平均工资查询出来,把查询结果当成新表e2来用
2、和员工表e1进行连接
3、通过添加条件**e1.salary > e2.avg_salay(员工的工资大于每个部门的平均工资)**进行筛选
4、FROM使用的情况就是很多时候我们想查询的时候数据是不存在的,我们需要先把数据查出来然后把这个查出来的数据当成一个新的表来使用
SELECT
e1.last_name,
e1.salary
FROM
employees e1,(
SELECT AVG( salary ) avg_salay, department_id FROM employees e2 GROUP BY department_id ) e2
WHERE
e1.department_id = e2.department_id
AND e1.salary > e2.avg_salay;
from型的子查询:子查询是作为from的一部分,子查询要用()引起来,并且要给这个子查询取别 名, 把它当成一张“临时的虚拟的表”来使用。
题目:查询员工的id,salary,按照department_name 排序
很明显department_name 在department表中,所以这又是一个相关子查询,还是带多写
SELECT
employee_id,
salary
FROM
employees e
ORDER BY
(SELECT department_name FROM departments d WHERE e.department_id = d.department_id )
题目:若employees表中employee_id与job_history表中employee_id相同的数目不小于2,输出这些相同 id的员工的employee_id,last_name和其job_id
SELECT
employee_id,
last_name,
job_id
FROM
employees e
WHERE
2 <= ( SELECT COUNT(*) FROM job_history WHERE employee_id = e.employee_id );
结论:在查询语句中,除了GROUP BY和LIMIT之外,其他位置都可以声明子查询
SELECT … , … ,…(存在聚合函数)
FROM … (LEFT/ RIGHT)JOIN …ON多表的连接条件(LEFT /RIGHT)JOIN …ON …
WHERE不包含聚合函数的过滤条件GROUP BY …,…
HAVING包含聚合函数的过滤条件ORDER BY …, … (AsC / DESC )LIMIT …,… .
题目:若employees表中employee_id与job_history表中employee_id相同的数目不小于2,输出这些相同 id的员工的employee_id,last_name和其job_id
SELECT
employee_id,
last_name,
job_id
FROM
employees e
WHERE
2 <= ( SELECT COUNT(*) FROM job_history WHERE employee_id = e.employee_id );
EXISTS 与 NOT EXISTS关键字
- 关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
- 如果在子查询中不存在满足条件的行:
- 条件返回FALSE
- 继续在子查询中查找
- 如果在子查询中存在满足条件的行:
- 不在子查询中继续查找
- 条件返回TRUE
- NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
题目:查询公司管理者的employee_id,last_name,job_id,department_id信息
-- 自连接
SELECT
DISTINCT
e1.employee_id,
e1.last_name,
e1.job_id,
e1.department_id
FROM
employees e1 JOIN employees e2
WHERE
e1.employee_id = e2.manager_id
-- 子查询1
-- 如果能用自连接的话最好使用自连接,因为它的速度快,效率高
-- 这个子查询的思路是:
-- 1、先查出所有员工的manage_id,并进行去重,因为多个员工可能有共同的领导
-- 2、外查询在进行获取manage_id的信息
SELECT
employee_id,
last_name,
job_id,
department_id
FROM
employees
WHERE
employee_id IN (SELECT DISTINCT manager_id FROM employees)
-- 子查询2
-- EXISTS关键字是用来检查子查询中是否存在满足的条件
-- 满足返回true,打印
-- 不满足继续找,直到true为止
-- 那么NOT EXISTS意思就是和EXISTS相反
SELECT
employee_id,
last_name,
job_id,
department_id
FROM
employees e1
WHERE
EXISTS (SELECT * FROM employees WHERE e2.manager_id = e1.employee_id)方式一:
题目:查询departments表中,不存在于employees表中的部门的department_id和department_name
NOT EXISTS不存在返回true停止查找子查询,存在返回false,继续查找子查询
SELECT
department_id,
department_name
FROM
departments d
WHERE
NOT EXISTS(SELECT DISTINCT department_id FROM employees e WHERE d.department_id = e.department_id)
相关更新
题目:在employees中增加一个department_name字段,数据为员工对应的部门名称
-- 1.增加字段
ALTER TABLE employees ADD(department_name VARCHAR(14));
-- 2.插入数据
UPDATE employees e
SET department_name = ( SELECT department_name FROM departments d WHERE e.department_id = d.department_id );
相关删除
题目:删除表employees中,其与emp_history表皆有的数据
DELETE FROM employees e
WHERE employee_id IN (SELECT employee_id FROM emp_history e2 WHERE e.employee_id = e2.employee_id )
练习
表的数据尚硅谷来获取…
#1.查询和Zlotkey相同部门的员工姓名和工资
-- 1.分析题,找出定语"查询和Zlotkey相同部门"(一般"的"前面的做定于修饰后面的句子)
-- 2.写出定语的查询语句SELECT department_id FROM employees WHERE last_name = 'Zlotkey'找出了Zlotkey部门ID
-- 3.完成题目
SELECT
last_name,
salary
FROM
employees
WHERE
department_id = ( SELECT department_id FROM employees WHERE last_name = 'Zlotkey' );
#2.查询工资比公司平均工资高的员工的员工号,姓名和工资。
-- 1.分析题,找出定语"工资比公司平均工资高"
-- 2.写出定语的查询语句salary > (SELECT AVG(salary) avg_emp FROM employees)
-- 3.完成题目
SELECT
employee_id,
last_name,
salary
FROM
employees
WHERE
salary > (SELECT AVG(salary) avg_emp FROM employees)
#3.选择工资大于所有JOB_ID = 'SA_MAN'的员工的工资的员工的last_name, job_id, salary
-- 1.分析题,找出定语"工资大于所有JOB_ID = 'SA_MAN'的员工"
-- 2.写出定语的查询语句salary > ALL (SELECT salary FROM employees WHERE JOB_ID = 'SA_MAN')
-- 3.完成题目
SELECT
last_name,
job_id,
salary
FROM
employees
WHERE
salary > ALL (SELECT salary FROM employees WHERE job_id = 'SA_MAN')
#4.查询和姓名中包含字母u的员工在相同部门的员工的员工号和姓名
-- 1.分析题,找出定语"姓名中包含字母u的员工在相同部门的员工"
-- 2.写出定语的查询语句SELECT department_id,last_name FROM employees WHERE last_name LIKE '%u%'
-- 3.完成题目
SELECT
employee_id,
last_name
FROM
employees
WHERE
(department_id,last_name) IN (SELECT department_id,last_name FROM employees WHERE last_name LIKE '%u%' );
#5.查询在部门的location_id为1700的部门工作的员工的员工号
-- 1.分析题,找出定语"部门的location_id为1700的部门工作的员工"
-- 2.写出定语的查询语句SELECT department_id FROM departments WHERE location_id = 1700
-- 3.完成题目
SELECT
employee_id
FROM
employees
WHERE
department_id IN (SELECT department_id FROM departments WHERE location_id = 1700)
#6.查询管理者是King的员工姓名和工资
-- 1.分析题,找出定语"管理者是King"
-- 2.写出定语的查询语句SELECT employee_id FROM employees WHERE last_name = 'King'
-- 3.完成题目
SELECT
last_name,
salary
FROM
employees
WHERE
manager_id IN (SELECT employee_id FROM employees WHERE last_name = 'King')
#7.查询工资最低的员工信息: last_name, salary
-- 1.分析题,找出定语"工资最低"
-- 2.写出定语的查询语句SELECT MIN(salary) FROM employees
-- 3.完成题目
SELECT
last_name,
salary
FROM
employees
WHERE
salary = (SELECT MIN(salary) FROM employees)
#8.查询平均工资最低的部门信息
-- 1.分析题,找出定语"平均工资最低的部门"
-- 2.写出定语的查询语句
-- SELECT MIN( avg_salary ) FROM ( SELECT AVG( salary ) avg_salary FROM employees GROUP BY department_id ) t_avg_salary
-- 3.找到平均工资后,在把这个平均工资当成一个新表来用即可.需要注意的点就是要给新表起别名,要给平均薪资字段起别名
-- 方式一:先求出平均工资,在求最低工资,因为前两次求的是平均工资最低的数据,所以最后条件要用AVG函数来接收
SELECT
*
FROM
departments
WHERE
department_id = (
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
AVG( salary ) = ( SELECT MIN( avg_salary ) FROM ( SELECT AVG( salary ) avg_salary FROM employees GROUP BY department_id ) t_avg_salary )
)
-- 方式二:求出各部门最低工资后,直接设置条件让它等于查出结果中最小的那个即可
SELECT
*
FROM
departments
WHERE
department_id = (
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
AVG( salary ) <= ALL ( SELECT AVG( salary ) avg_salary FROM employees GROUP BY department_id )
)
-- 方式三:求出各部门平均工资后,进行升序排序,然后通过分页查询取第一条数据即可
SELECT
*
FROM
departments
WHERE
department_id = (
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
AVG( salary )=(
SELECT
AVG( salary ) avg_salary
FROM
employees
GROUP BY
department_id
ORDER BY
avg_salary
LIMIT 0,
1
));
-- 方式四
-- 查询出各部门平均工资后,把数据当成新表来用,与旧表进行自连接
SELECT
d.*
FROM
departments d,(
SELECT department_id,AVG(salary) avg_sal
FROM employees
GROUP BY department_id
ORDER BY avg_sal
LIMIT 0,1) t_avg_sal
WHERE d.department_id = t_avg_sal.department_id
#9.查询平均工资最低的部门信息和该部门的平均工资(相关子查询)
-- 方式一:
-- 1.这里部门信息采用子查询查到的平均工资最低的数值
-- 2.通过平均工资最低的数值在进行查询到部门ID
-- 3.根据部门ID获取部门信息
-- 4.平均工资通过在select语句中在进行相关子查询,获得该部门的平均工资
-- 这种方式呢,是通过平均工资最低数值来获取部门ID,其实部门ID是可以直接获取的,这里相当于多走一步
SELECT
d.*,(SELECT AVG(salary) FROM employees WHERE department_id = d.department_id) avg_salary
FROM
departments d
WHERE
department_id = (
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
AVG( salary ) <= ALL ( SELECT AVG( salary ) avg_salary FROM employees GROUP BY department_id )
)
-- 方式二:
-- 在方式一基础上,获取最低工资的方式不在是和全部部门的工资作比较,而是直接让工资等于升序过后的第一个工资
SELECT d.*,( SELECT AVG( salary ) FROM employees WHERE department_id = d.department_id ) avg_salary
FROM
departments d
WHERE
department_id = (
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
AVG( salary ) = ( SELECT AVG( salary ) avg_salary FROM employees GROUP BY department_id ORDER BY avg_salary LIMIT 0, 1 )
);
-- 方式三:
-- 1.通过MIN聚合函数来获取最低平均工资
-- 2.然后在筛选平均工资为最低平均工资的部门
-- 3.获取部门信息....
SELECT d.*,( SELECT AVG( salary ) FROM employees WHERE department_id = d.department_id ) avg_salary
FROM
departments d
WHERE
department_id = (
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
AVG( salary ) = ( SELECT MIN( avg_salary ) FROM ( SELECT AVG( salary ) avg_salary FROM employees GROUP BY department_id ) t_avg_salary ));
-- 方式四:
-- 平均工资最低的部门
SELECT department_id FROM employees GROUP BY department_id ORDER BY AVG(salary) LIMIT 0,1
-- 部门信息和该部门的平均工资
-- 1.这里部门信息采用子查询查到的平均工资最低的部门ID来获取部门信息
-- 2.平均工资通过在select语句中在进行相关子查询,获得该部门的平均工资
SELECT d.*,( SELECT AVG( salary ) FROM employees e WHERE d.department_id = e.department_id GROUP BY department_id ) avg_sala
FROM
departments d
WHERE
department_id = ( SELECT department_id FROM employees GROUP BY department_id ORDER BY AVG( salary ) LIMIT 0, 1 );
-- 方式五:
-- 效率最高,通过自连接
SELECT d.*,t_avg_sal.avg_sal
FROM departments d,(
SELECT
department_id,
AVG(salary) avg_sal
FROM
employees
GROUP BY
department_id
ORDER BY
AVG( salary )
LIMIT 0,1) t_avg_sal
WHERE d.department_id = t_avg_sal.department_id
#10.查询平均工资最高的 job 信息
-- 1.分析题,找出定语"平均工资最高"
-- 2.写出定语的查询语句AVG( salary ) >= ALL(SELECT AVG( salary ) avg_salary FROM employees GROUP BY job_id)
-- 3.完成题目
SELECT
j.*
FROM
jobs j,
( SELECT job_id, AVG( salary ) avg_salary FROM employees GROUP BY job_id ORDER BY avg_salary DESC LIMIT 0, 1 ) t_avg_salary
WHERE
j.job_id = t_avg_salary.job_id;
#11.查询平均工资高于公司平均工资的部门有哪些?
-- 1.分析题,找出定语"平均工资高于公司平均工资的部门"
-- 2.写出定语的查询语句AVG(salary) > (SELECT AVG(salary) FROM employees)
-- 3.完成题目
SELECT
department_id
FROM
employees
WHERE
department_id IS NOT NULL
GROUP BY
department_id
HAVING
AVG(salary) > (SELECT AVG(salary) FROM employees)
#12.查询出公司中所有 manager 的详细信息
-- 1.分析题,找出定语"公司中所有 manager "
-- 2.写出定语的查询语句employee_id IN (SELECT DISTINCT manager_id FROM employees)
-- 3.完成题目
SELECT
employee_id,
last_name,
salary
FROM
employees
WHERE
employee_id IN (SELECT DISTINCT manager_id FROM employees)
SELECT
employee_id,
last_name,
salary
FROM
employees e1
WHERE
EXISTS (SELECT * FROM employees e2 WHERE e2.manager_id = e1.employee_id)
-- 自连接
SELECT
e1.employee_id,
e1.last_name,
e1.salary
FROM
employees e1 JOIN employees e2
WHERE
e1.employee_id = e2.manager_id
#13.各个部门中最高工资中最低的那个部门的 最低工资是多少?
-- 1.分析题,找出定语"各个部门中最高工资中最低的那个部门 "
-- 2.写出定语的查询语句salary <= ALL(SELECT MAX(salary) FROM employees GROUP BY department_id)
-- 3.完成题目
SELECT
MIN(salary)
FROM
employees
WHERE
salary <= ALL(SELECT MAX(salary) FROM employees GROUP BY department_id)
-- 自连接
SELECT
salary
FROM
employees e1,(SELECT department_id,MAX(salary) max_salary FROM employees GROUP BY department_id ORDER BY max_salary LIMIT 0,1
) t_max_salay
WHERE
e1.department_id = t_max_salay.department_id
#14.查询平均工资最高的部门的 manager 的详细信息: last_name, department_id, email, salary
-- 1.分析题,找出定语"平均工资最高的部门 "
-- 2.写出定语的查询语句salary >= ALL(SELECT AVG(salary) FROM employees GROUP BY department_id)获取最高部门的ID
-- 3.获得所有manager的信息
-- 4.设置限制条件进行匹配
SELECT
last_name,
department_id,
email,
salary
FROM
employees
WHERE
employee_id IN (SELECT DISTINCT manager_id FROM employees)
AND department_id = (SELECT department_id FROM employees WHERE salary>=ALL (
SELECT AVG(salary) FROM employees GROUP BY department_id))
-- 平均工资最高的部门
SELECT department_id,AVG(salary) avg_sal
FROM employees
GROUP BY department_id
ORDER BY avg_sal DESC
LIMIT 0,1
-- 自连接方式
SELECT *
FROM employees
WHERE employee_id IN (SELECT DISTINCT manager_id
FROM employees e,(
SELECT department_id,AVG(salary) avg_sal
FROM employees
GROUP BY department_id
ORDER BY avg_sal DESC
LIMIT 0,1
)t_avg_sal
WHERE
e.department_id = t_avg_sal.department_id)
#15. 查询部门的部门号,其中不包括job_id是"ST_CLERK"的部门号
-- 这里注意,题目说的是部门中的部门号,不是员工表中的部门号,所以也要进行子查询
SELECT
department_id
FROM
departments
WHERE
department_id NOT IN (
SELECT DISTINCT
department_id
FROM
employees
WHERE
job_id = 'ST_CLERK'
)
#16. 选择所有没有管理者的员工的last_name
SELECT
last_name
FROM
employees
WHERE
manager_id IS NULL
#17.查询员工号、姓名、雇用时间、工资,其中员工的管理者为 'De Haan'
SELECT
employee_id,
last_name,
hire_date,
salary
FROM
employees
WHERE
manager_id = (SELECT employee_id FROM employees WHERE last_name = 'De Haan')
#18.查询各部门中工资比本部门平均工资高的员工的员工号, 姓名和工资
-- 1.分析题,找出定语"各部门中工资比本部门平均工资高的员工 "
-- 2.写出定语的查询语句SELECT AVG( salary ) FROM employees e2 WHERE e2.department_id = e1.department_id GROUP BY department_id
-- 3.设置限制条件进行匹配
SELECT
e1.employee_id,
e1.last_name,
e1.salary
FROM
employees e1
WHERE
salary > ( SELECT AVG( salary ) FROM employees e2 WHERE e2.department_id = e1.department_id GROUP BY department_id );
#19.查询每个部门下的部门人数大于 5 的部门名称
-- 1.分析题,找出定语"查询每个部门下的部门人数大于 5 "
-- 2.写出定语的查询语句5 < (SELECT COUNT(*) FROM employees e2 WHERE e2.department_id = e1.department_id )
-- 3.设置限制条件进行匹配
SELECT DISTINCT
department_name
FROM
employees e1
WHERE
5 < (SELECT COUNT(*) FROM employees e2 WHERE e2.department_id = e1.department_id )
#20.查询每个国家下的部门个数大于 2 的国家编号
-- 1.分析题,找出定语"查询每个国家下的部门个数大于2"
-- 2.写出定语的查询语句2 < (SELECT COUNT(*) FROM departments d WHERE l.location_id=d.location_id)
-- 3.设置限制条件进行匹配
SELECT
country_id
FROM
locations l
WHERE
2 < (
SELECT COUNT(*)
FROM departments d
WHERE l.location_id = d.location_id
)