标签(空格分隔): 王小草Tensorflow笔记
笔记整理者:王小草
笔记整理时间:2017年2月26日
对应的官方文档地址:https://www.tensorflow.org/get_started/tflearn
官方文档上次更新时间:2017年2月15日
今天我们要向Tensorflow高级API的学习门槛迈进一步。别听到高级API就觉得是难度高的意思,其实高级API恰恰是为了降低大家的编码难度而设置的。Tensorflow更高层的API使得配置,训练,评估多种多样的机器学习模型更简单方便了。
本文将使用高层API:tf.contrib.learn 来构建一个分类神经网络,将它放在“鸢尾花数据集”上进行训练,并且估计模型,使得模型能根据特征(萼片和花瓣几何形状)预测出花的种类。
1. 加载鸢尾花数据集到Tensorflow上
首先介绍一下我们今天要使用的数据集:
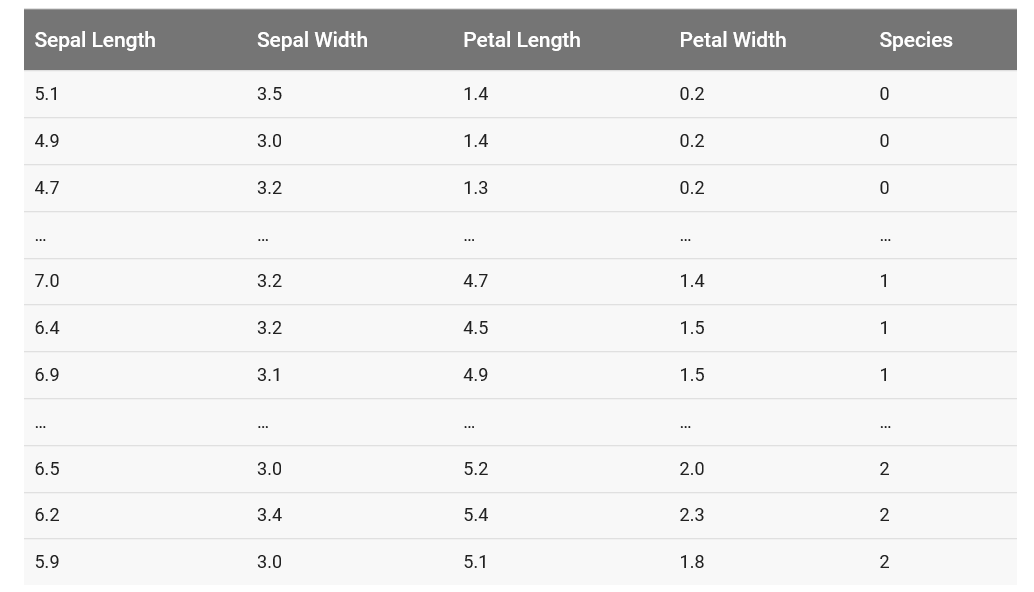
鸢尾花数据集:Iris data set 由150个样本组成。其中,总共有3个类别:山鸢尾(Iris setosa),虹膜锦葵(Iris virginica),变色鸢尾 (Iris versicolor) ,每个类别50个样本。
下图,从左到右分别是 Iris setosa , Iris versicolor, and Iris virginica三类花的图片:

数据的每一行(也就是每个样本)包含了样本的特征与类别标签。
特征有:萼片的长度,萼片的宽度,花瓣的长度,花瓣的宽度。
类别标签用整型数字表示:0表示萼片,1表示Iris versicolor,2表示Iris virginica
数据格式如下:
在机器学习的建模中,我们一般将数据集拆分成训练集与测试集,训练集用来训练模型,测试集用来测试模型的泛化能力。所以此处,也将150个样本的数据集随机地拆分成两个部分:
(1)训练集包含120个样本(放在iris_training.csv文件中)
(2)测试集包含30个样本(放在iris_test.csv文件中)
在开始写程序之前,要先下载好这两个数据集哦~
现在我们已经了解了数据集大概的样子了,于是开始上代码喽~
首先,还是先导入要用的库
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import numpy as np接着,把下载好的训练集与测试集根据它们的路径加载的dataset中,使用的是learn.datasets.base中的load_csv_with_header()这个方法。这个方法需要传入3个参数:
(1)filename:文件路径/文件名
(2)target_dtype:标签类别的数据类型
(3)features_dtype:特征的数据类型
# 定义数据集的路径
IRIS_TRAINING = "iris_training.csv"
IRIS_TEST = "iris_test.csv"
# 加载数据集
# # 加载训练集
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING,
target_dtype=np.int,
features_dtype=np.float32)
# # 加载测试集
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TEST,
target_dtype=np.int,
features_dtype=np.float32)注意,加载建立后的Dataset是命名元组,可以使用training_set.data调用训练数据集的特征数据,使用training_set.target调用训练数据集的类别标签数据。对test_set的测试数据集也是同理。
2. 构建深度神经网络分类模型
tf.contrib.learn提供了多种多样的预定义模型,叫做Estimators(估计器),这些Estimator在你拟运行训练与评估模型的操作的时候可以实现开箱即用,也就是说,当你要使用某个模型的时候,不再需要去写他的内部逻辑,直接调用这个模型的接口,用一句代码搞定即可。
于是,这里我们就来使用tf.contrib.learn配置一个深层神经网络的分类模型,只需要了了几行代码~
# Specify that all features have real-value data
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
# Build 3 layer DNN with 10, 20, 10 units respectively.
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")以上代码首先定义了模型的特征列,并且指定了特征数据的数据类型。在上一节中我们看到所有的特征都是连续型变量,所以tf.contrib.layers.real_valued_column这个函数被用来构建特征列。另外,我们的数据集中有4个特征,故传入参数dimension=4.
接着,以上代码使用了tf.contrib.learn.DNNClassifier这个函数来直接构建DNN模型。(记得前面两个笔记,无论是讲简单的分类模型softmax regression还是稍微复杂的卷积神经网络,都是自己一层一层地去写模型的逻辑结构,相当繁琐,看!高级的API已经为我们封装好了这些模型,我们只需要直接调用方法就行)
DNNClassifier这个方法需要传入4个参数:
(1)feature_columns=feature_columns,将刚刚预先定义好的特征列传给参数feature_columns。
(2)hidden_units=[10, 20, 10],设置隐藏层中的神经元个数,这里表示共有3个隐藏层,依次的神经元个数为10,20,10。
(3)n_classes=3,设置目标分类的个数,这个是3类,分成3种鸢尾花。
(4)model_dir=/tmp/iris_model,这是保存模型训练过程中的checkpoint检查点的数据的路径
3. 模型拟合真实数据进行训练
上面一步建立了一个模型,现在你可以将鸢尾花的训练数据集利用fit()这个方法来拟合进模型。主要是通过传入参数的方式,将训练集中的特征传给x,将训练集中的标签传给y,并且定义了训练的次数(比如这里是2000次):
# Fit model
classifier.fit(x=training_set.data, y=training_set.target, steps=2000)注意的是,模型的状态会在训练中被缓存在分类器中classifier,所以你可以按照自己的喜好来分开迭代,例如,上面代码等同于下面两句代码:
classifier.fit(x=training_set.data, y=training_set.target, steps=1000)
classifier.fit(x=training_set.data, y=training_set.target, steps=1000)4.评估模型的精度
第1步导入了数据,第2步构建了模型,第3步在训练集上进行了训练学,现在第4步,我们要去评估训练好的模型了。
评估模型的时候使用的是测试集,与.fit()方法相似,评估模型调用.evaluate()方法,并且将测试集的特征传入给x,测试集的标签传入给y,并且指定计算的是accuracy。
accuracy_score = classifier.evaluate(x=test_set.data, y=test_set.target)["accuracy"]
print('Accuracy: {0:f}'.format(accuracy_score))运行以上的所有代码,会打印出最后的精度:
Accuracy: 0.966667
每次训练的accuracy可能会有点不相同,但都应该是在90%之上的哈~
5.预测新的数据
模型建好了,也通过了评估,现在终于到了用武之时呢~我们要用模型与预测新的数据。

比如,现在新来了两条未知的数据,至知道这两朵花的4个特征,却不知道它们的种类,于是调用.predict()方法进行预测:
# 新的两个样本
new_samples = np.array(
[[6.4, 3.2, 4.5, 1.5], [5.8, 3.1, 5.0, 1.7]], dtype=float)
# 预测
y = list(classifier.predict(new_samples, as_iterable=True))
# 打印
print('Predictions: {}'.format(str(y))).predict()返回的是一个数组,预测的结果打印出来应是如下,第一个样本为1类,第二哥赝本为二类。
Prediction: [1 2]
将以上代码所有整合在一起如下:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import numpy as np
# Data sets
IRIS_TRAINING = "iris_training.csv"
IRIS_TEST = "iris_test.csv"
# Load datasets.
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING,
target_dtype=np.int,
features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TEST,
target_dtype=np.int,
features_dtype=np.float32)
# Specify that all features have real-value data
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
# Build 3 layer DNN with 10, 20, 10 units respectively.
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")
# Fit model.
classifier.fit(x=training_set.data,
y=training_set.target,
steps=2000)
# Evaluate accuracy.
accuracy_score = classifier.evaluate(x=test_set.data,
y=test_set.target)["accuracy"]
print('Accuracy: {0:f}'.format(accuracy_score))
# Classify two new flower samples.
new_samples = np.array(
[[6.4, 3.2, 4.5, 1.5], [5.8, 3.1, 5.0, 1.7]], dtype=float)
y = list(classifier.predict(new_samples, as_iterable=True))
print('Predictions: {}'.format(str(y)))
tf.contrib.learn包括了各种类型的深度学习和机器学习的算法。它是从Tensorflow官方Scikit Flow直接迁移过来的,其使用的风格与Scikit-learn相似(用python写机器学习的小伙伴应该很熟悉)。
从Tensorflowv0.9版本时候,tf.learn已经能够无缝与其他contrib模型结合起来使用啦~