内存屏障指令是系统编程中很重要的一部分,特别是在多核并行编程中。本章重点介绍内存屏障指令产生的原因、ARM64处理器内存屏障指令以及内存屏障的案例分析等内容。
18.2.1 使用内存屏障的场景
在大部分场景下,我们不用特意关注内存屏障的,特别是在单处理器系统里,虽然CPU内部支持乱序执行以及预测式的执行,但是总体来说,CPU会保证最终执行结果符合程序员的要求。在多核并发编程的场景下,程序员需要考虑是不是应该用内存屏障指令。下面是一些需要考虑使用内存屏障指令的典型场景。
- 在多个不同CPU内核之间共享数据。在弱一致性内存模型下,某个CPU乱的内存访问次序可能会产生竞争访问。
- 执行和外设相关的操作,例如DMA操作。启动DMA操作的流程通常是这样的:第一步,把数据写入DMA缓冲区里;第二步,设置DMA相关寄存器来启动DMA。如果这中间没有内存屏障指令,第二步的相关操作有可能在第一步前面执行,这样DMA就传输了错误的数据。
- 修改内存管理的策略,例如上下文切换、请求缺页以及修改页表等。
- 修改存储指令的内存区域,例如自修改代码的场景。
总之,我们使用内存屏障指令的目的是想让CPU按照程序代码逻辑来执行,而不是被CPU乱序执行和预测执行打乱了代码的执行次序。
18.2.2 ARM64里的内存屏障指令
ARMv8指令集提供了3条内存屏障指令。
- 数据存储屏障(Data Memory Barrier,DMB)指令:仅当所有在它前面的存储器访问操作都执行完毕后,才提交(commit)在它后面的访问指令。DMB指令保证的是DMB指令之前的所有内存访问指令和DMB指令之后的所有内存访问指令的执行顺序。也就是说,DMB指令之后的内存访问指令不会被处理器重排到DMB指令的前面。DMB指令不会保证内存访问指令在内存屏障指令之前完成,它仅仅保证内存屏障指令前后的内存访问的执行顺序。DMB指令仅仅影响内存访问指令、数据高速缓存指令以及高速缓存管理指令等,并不会影响其他指令(例如算术运算指令等)的顺序。
- 数据同步屏障(Data Synchronization Barrier,DSB)指令:比DMB指令要严格一些,仅当所有在它前面的内存访问指令都执行完毕后,才会执行在它后面的指令,即任何指令都要等待DSB指令前面的内存访问指令完成。位于此指令前的所有缓存(如分支预测和TLB维护)操作需要全部完成。
- 指令同步屏障(Instruction Synchronization Barrier,ISB)指令:确保所有在ISB指令之后的指令都从指令高速缓存或内存中重新预取。它刷新流水线(flush pipeline)和预取缓冲区后才会从指令高速缓存或者内存中预取ISB指令之后的指令。ISB指令通常用来保证上下文切换(如ASID更改、TLB维护操作等)的效果。
18.2.3 DMB指令
DMB指令仅仅影响数据访问的序列。注意,DMB指令不能保证任何指令必须在某个时刻一定执行完,它仅仅保证的是DMB指令前后的内存访问指令的执行次序。数据访问包括普通的加载操作(load)和存储操作(store),也包括数据高速缓存(data cache)维护指令(因为它也算数据访问指令)。
DMB指令通常用来保证DMB指令之前的数据访问可以被DMB后面的数据访问指令观察到。所谓的观察到指的是先执行完A指令,然后执行B指令,于是B指令可以观察到A指令的执行结果。如果B指令先于A指令执行,那么B指令没有办法观察到A指令的执行结果。
总之,DMB指令强调的是内存屏障前后数据访问指令的访问次序。这里有两个要点:一个是数据访问指令,另一个是保证访问的次序。
DMB指令后面必须带参数,用来指定共享属性域(share ability domain)以及指定具体的访问顺序(before-after)。
【例18-1】CPU执行下面两条指令。
ldr x0,[x1]
str x2,[x3]LDR指令读取X1地址的值,STR指令把X2的值写入X3地址。如果这两条指令没有数据依赖(data dependency)或者地址依赖(address dependency),那么CPU可以先执行STR指令或者先执行LDR指令,从最终结果来看没有区别。
数据依赖指的是相邻的读写操作是否存在数据依赖,例如,从Xn地址读取内容到Xm地址中,然后把Xm地址中的值写入Xy地址中,那么Xm为这两条指令的数据依赖,下面是伪代码。
ldr xm,[xn]
str xm,[xy]地址依赖指的相邻的读写操作是否存在地址依赖,例如,从Xn地址读取内容到Xm地址中,然后把另外的一个值Xy写入Xm地址中,那么Xm为这两条指令的地址依赖,下面是伪代码。
ldr xm,[xn]
str xy,[xm]在例18-1中,如果想要确保CPU一定按照写的序列来执行代码,那么就需要加入一条DMB指令,这样就可以保证CPU一定先执行LDR指令,后执行STR指令,例如下面的代码片段。
ldr x0,[x1]
dmb ish
str x2,[x3]【例18-2】CPU执行下面两条指令。
ldr x0,[x1]
str x0,[x3]LDR指令读取X1地址的值到X0寄存器,然后把X0寄存器的值写入X3地址。这两条指令存在数据依赖,不使用内存屏障指令也能保证上述两条指令的执行次序。
【例18-3】CPU执行如下3条指令。
ldr x0,[x1]
dmb ish
add x2,x3,x4第一条指令是加载指令,第二条指令是DMB内存屏障指令,第三条指令是算术运算(ADD)指令。尽管加载和算术运算指令之间有一条DMB内存屏障指令,但是第三条指令是有可能在加载指令前面执行的。DMB内存屏障指令只能保证数据访问指令的执行次序,但是ADD指令不是数据访问指令,因此无法阻止ADD指令被重排到第一条指令前面。解决办法是把DMB指令换成DSB指令。
【例18-4】CPU执行如下4条指令。
ldr x0, [x2]
dmb ish
add x3, x3, #1
str x4, [x5]第一条指令是LDR指令,把X2地址的内容加载到X0寄存器。第二条指令是DMB指令,第三条指令是ADD运算指令,它不属于数据访问指令。第四条指令是STR指令,把X4寄存器的值存到X5地址处。这里的数据访问指令只有第一条和第四条,因此LDR指令的执行结果必须要被DMB后面的STR指令观察到,即LDR指令要先于STR指令执行。此外,由于这里的ADD指令不是数据访问指令,因此它可以被乱序重排到LDR指令前面。
【例18-5】CPU执行如下4条指令。
dc cvac,x6
ldr x1, [x2]
dmb ish
ldr x3, [x7]第一条指令是数据高速缓存维护指令,它用于清理X6对应地址的数据高速缓存。第二条指令是LDR指令,第三条指令是DMB指令,第四条指令也是LDR指令。前面两条指令之间没有DMB指令,而且都是数据访问指令,因此从执行顺序角度来观察,LDR指令可以乱序重排到DC指令前面。第四条指令能观察到DC指令执行完成,或者说第四条指令不能在DMB指令前面执行。
数据高速缓存和统一高速缓存(unified cache)相关的维护指令其实也算数据访问指令,所以,在DMB指令前面的数据高速缓存维护指令必须在DMB指令后面的内存访问指令之前执行完。
通过上述几个例子的分析可知,DMB指令关注的是内存访问的序列,不需要关心内存访问指令什么时候执行完。DMB前面的数据访问指令必须被DMB后面的数据访问指令观察到。
18.2.4 DSB指令
DSB指令要比DMB指令严格得多。DSB后面的任何指令必须满足下面两个条件才能开始执行。
- DSB指令前面的所有数据访问指令(内存访问指令)必须执行完。
- DSB指令前面的高速缓存、分支预测、TLB等维护指令也必须执行完。
这两个条件满足之后才能执行DSB指令后面的指令。注意,DSB指令后面的指令指的是任意指令。
与DMB指令相比,DSB指令规定了DSB指令在什么条件下才能执行,而DMB指令仅仅约束屏障前后的数据访问指令的执行次序。
【例18-6】CPU执行如下3条指令。
ldr x0,[x1]
dsb ish
add x2,x3,x4ADD指令必须要等待DSB指令执行完才能开始执行,它不能重排到LDR指令前面。如果把DSB指令换成DMB指令,那么ADD指令可以重排到LDR指令前面。
【例18-7】CPU执行如下4条指令。
dc civa x5
str x1, [x2]
dsb ish
add x3,x3,#1第一条指令是DC指令,它清空虚拟地址(X5寄存器)对应的数据高速缓存并使其失效。第二条指令把X1寄存器的值存储到X2地址处。第三条指令是DSB指令。第四条指令是ADD指令,让X3寄存器的值加1。
DC指令和STR指令必须在DSB指令之前执行完。ADD指令必须等到DSB指令执行完才能开始执行。尽管ADD指令不是数据访问指令,但是它也必须等到DSB指令执行完才能开始执行。
在一个多核系统里,高速缓存和TLB维护指令会广播到其他CPU内核,执行本地相关的维护操作。DSB指令等待这些广播并收到其他CPU内核发送的应答信号才算执行完。所以,当DSB指令执行完时,其他CPU内核已经看到第一条DC指令执行完。
18.2.5 DMB和DSB指令的参数
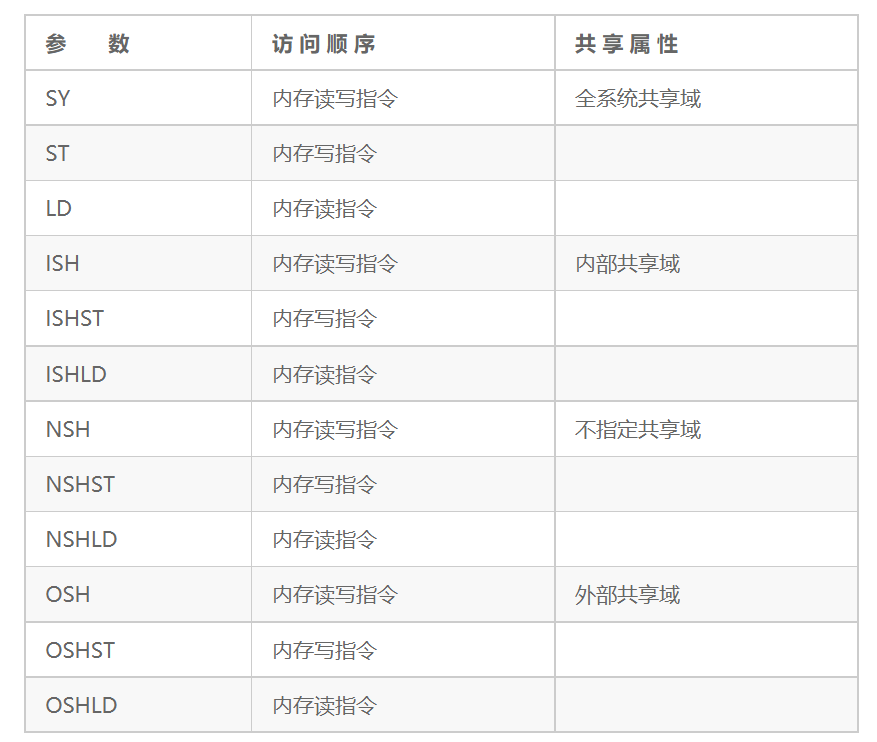
DMB和DSB指令后面可以带参数,用于指定共享属性域以及具体的访问顺序。
共享属性域是内存屏障指令的作用域。ARMv8体系结构里定义了4种域。
- 全系统共享(full system sharable)域,指的是全系统的范围。
- 外部共享(outer sharable)域。
- 内部共享(inner sharable)域。
- 不指定共享(non-sharable)域。
除指定范围之外,我们还可以进一步细化内存屏障指令的访问方向,例如,细分为读内存屏障、写内存屏障以及读写内存屏障。
第一种是读内存屏障(Load-Load/Store)指令,在参数里的后缀为LD。在内存屏障指令之前的所有加载指令必须完成,但是不需要保证存储指令执行完。在内存屏障指令后面的加载和存储指令必须等到内存屏障指令执行完。
第二种是写内存屏障(Store-Store)指令,在参数里的后缀为ST。写内存屏障指令仅仅影响存储操作,对加载操作则没有约束。
第三种为读写内存屏障指令。在内存屏障指令之前的所有读写指令必须在内存屏障指令之前执行完。
第一种和第二种指令相当于把功能弱化成单一功能的内存屏障指令,而第三种指令就是全功能的内存屏障指令。
内存屏障指令的参数如表18.1所示。
表18.1 内存屏障指令的参数
18.2.6 单方向内存屏障原语
ARMv8指令集还支持隐含内存屏障原语的加载和存储指令,这些内存屏障原语影响了加载和存储指令的执行顺序,它们对执行顺序的影响是单方向的。
- 获取(acquire)屏障原语:该屏障原语之后的读写操作不能重排到该屏障原语前面,通常该屏障原语和加载指令结合。
- 释放(release)屏障原语:该屏障原语之前的读写操作不能重排到该屏障原语后面,通常该屏障原语和存储指令结合。
- 加载-获取(load-acquire)屏障原语:含有获取屏障原语的读操作,相当于单方向向后的屏障指令。所有加载-获取内存屏障指令后面的内存访问指令只能在加载-获取内存屏障指令执行后才能开始执行,并且被其他CPU观察到。如图18.1所示,读指令1和写指令1可以向前(如图18.1中指令执行的方向)越过该屏障指令,但是读指令2和写指令2不能向后(如图18.1中指令执行的方向)越过该屏障指令。
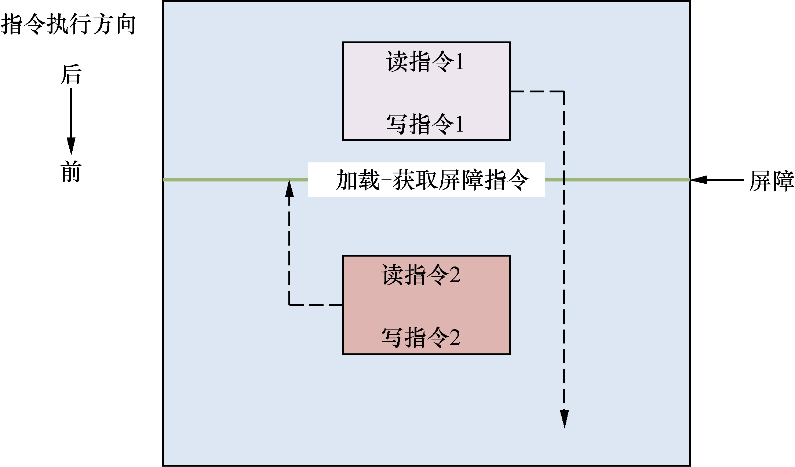
▲图18.1 加载-获取屏障原语
- 存储-释放(store-release)屏障原语:含有释放屏障原语的写操作,相当于单方向向前的屏障指令。只有所有存储-释放屏障原语之前的指令完成了,才能执行存储-释放屏障原语之后的指令,这样其他CPU可以观察到存储-释放屏障原语之前的指令已经执行完。读指令2和写指令2可以向后(如图18.2中指令执行的方向)越过存储-释放屏障指令,但是读指令1和写指令1不能向前(如图18.2中指令执行的方向)越过存储-释放屏障指令。
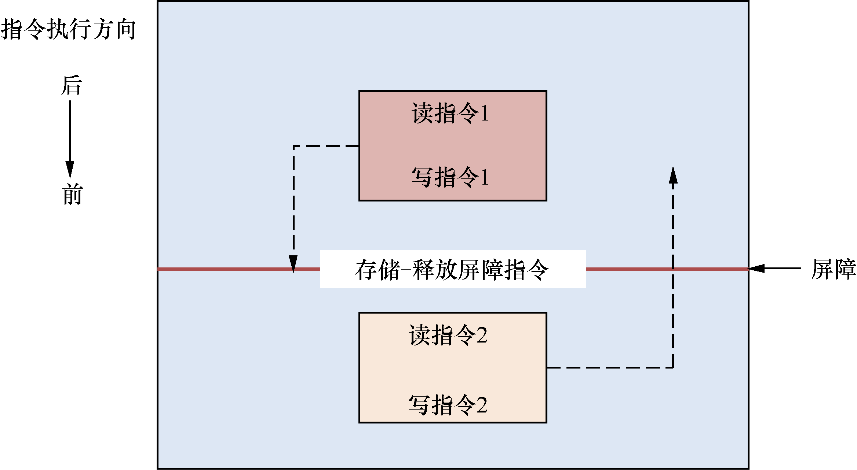
▲图18.2 存储-释放屏障原语
加载-获取和存储-释放屏障指令相当于单方向的DMB指令,而DMB指令相当于全方向的栅障。任何读写操作都不能越过该栅障。它们组合使用可以增强代码灵活性并提高执行效率。
如图18.3所示,加载-获取屏障指令和存储-释放屏障指令组成了一个临界区,这相当于一个栅障。
- 读指令1和写指令1可以挪到加载-获取屏障指令后面,但是不能向前(如图18.3中指令执行的方向)越过存储-释放屏障指令。
- 读指令3和写指令3不能向后(如图18.3中指令执行的方向)越过加载-获取屏障指令。
- 在临界区中的内存访问指令不能越过临界区,如读指令2和写指令2不能越过临界区。
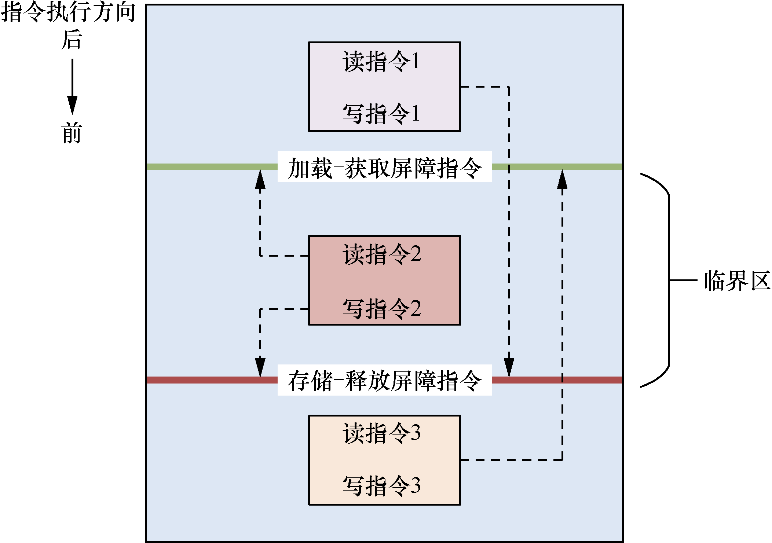
▲图18.3 加载-获取屏障指令与存储-释放屏障指令
ARMv8 体系结构还提供一组新的加载和存储指令,其中显式包含了上述内存屏障原语,如表18.2所示。
表18.2 新的加载和存储指令
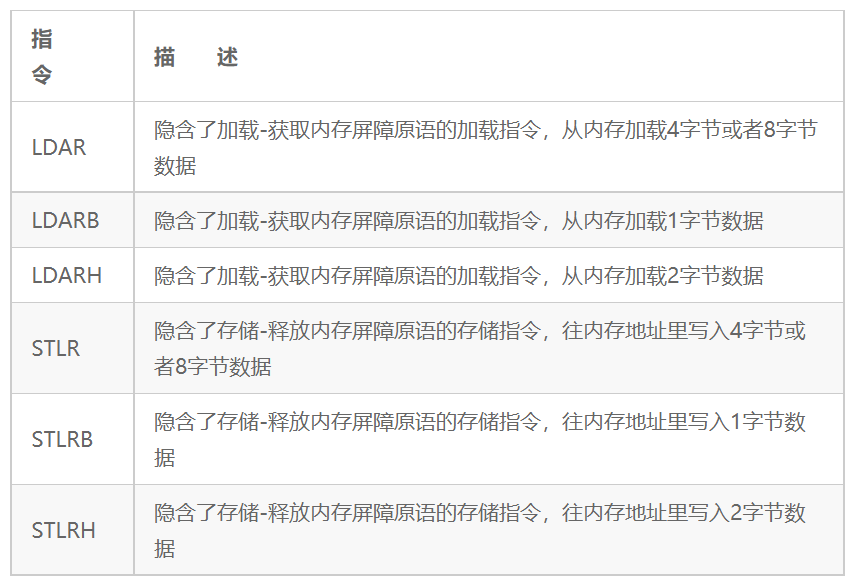
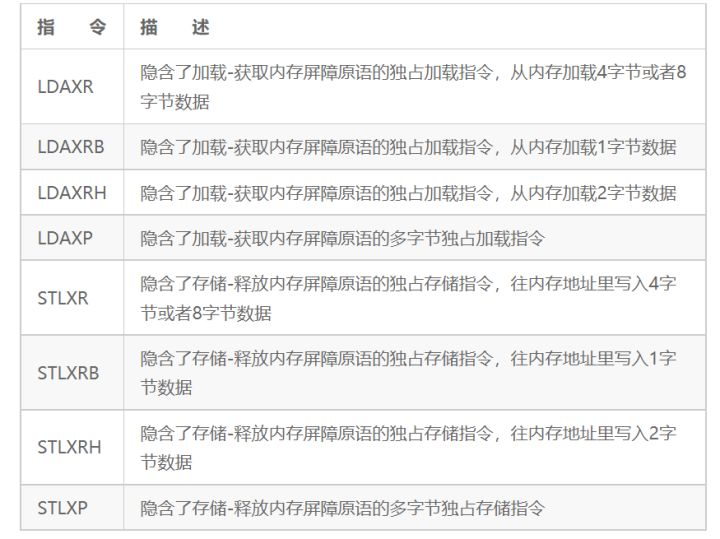
此外,ARMv8指令集还提供一组内置了上述屏障原语的独占加载与存储指令,如表18.3所示。
表18.3 独占加载和存储指令
18.2.7 ISB指令
ISB指令会冲刷流水线,然后从指令高速缓存或者内存中重新预取指令。
ARMv8体系结构中有一个术语——更改上下文操作(context-changing operation)。更改上下文操作包括高速缓存、TLB、分支预测等维护操作以及改变系统控制寄存器等操作。使用ISB确保在ISB之前执行的上下文更改操作的效果对在ISB指令之后获取的指令是可见的。更改上下文操作的效果仅仅在上下文同步事件(context synchronization event)之后能看到。上下文同步事件包括:
- 发生一个异常(exception);
- 从一个异常返回;
- 执行了ISB指令。
发生上下文同步事件产生的影响包括:
- 在上下文同步事件发生时挂起的所有未屏蔽中断都会在上下文同步事件之后的第一条指令执行之前处理;
- 在触发上下文同步事件的指令后面的所有指令不会执行,直到上下文同步事件处理完;
- 在上下文同步事件之前完成的使TLB失效、指令高速缓存以及分支预测操作,都会影响在上下文同步事件后面出现的指令。例如,如果在上下文同步事件之前完成了使指令高速缓存失效的操作,那么在上下文同步事件之后,CPU会从指令高速缓存中重新取指令,相当于把流水线之前预取的指令清空。
另外,修改系统控制寄存器通常是需要使用ISB指令的,但是并不是修改所有系统寄存器都需要ISB指令,例如修改PSTATE寄存器就不需要ISB指令。
【例18-8】CPU执行如下代码来打开FPU功能。
//打开FPU
mrs x1,cpacr_el1
orr x1, x1 #(0x3 << 20)
msr cpacr_el1, x1
isb
fadd s0, s1, s2把cpacr_el1的Bit[21:20]设置为0x3,即可以打开浮点运算单元。但是在打开之后,马上执行一条FADD指令,有可能会导致CPU异常。因为FADD这条指令可能已经在流水线里,并且有可能会提前执行,即打开浮点运算单元之前就提前执行了,所以出现错误了。
解决办法就是插入一条ISB指令。这里的ISB指令是为了保证前面打开FPU的设置已经完成,才从指令高速缓存里预取FADD这条指令。
【例18-9】改变页表项。
1 str x10,[x1]
2 dsb ish
3 tlbi vae1is, x11
4 dsb ish
5 isb在第1行中,[x1]是页表项的地址,这里STR指令用来更新这个页表项的内容。
在第2行中,DSB指令保证STR指令执行完。
在第3行中,使页表项对应的TLB项失效。
在第4行中,DSB指令保证TLB指令执行完。
在第5行中,触发一个上下文同步事件,保证ISB后面的指令可以看到上述操作都完成,并且从指令高速缓存里重新预取指令。
第5行是否可以换成DSB指令?
答案是不可以,因为后面的指令在第2行以及第4行的指令没执行完时可能已经位于流水线中,即已经预取了旧的页表项的内容,这会导致程序执行错误。
【例18-10】下面是一段自修改代码。自修改代码就是当代码执行时修改自身的指令。要保证自修改代码执行的正确性,需要使用高速缓存维护指令和内存屏障指令。在本案例中我们重点关注内存屏障指令的使用。
首先,CPU0修改代码。
1 str x11, [x1]
2 dc cvau,x1
3 dsb ish
4 ic ivau,x1
5 dsb ish
6 str x0,[x2]
7 isb
8 br x1在第1行中,[x1]是执行代码存储的地方,这里STR指令修改和更新最新代码。
在第2行中,清理[x1]地址处的代码对应的数据高速缓存,把[x1]对应的数据高速缓存写回[x1]指向的地址中。
在第3行中,DSB指令保证DC指令执行完,所有的CPU内核都看到这条指令已经执行完。
在第4行中,使[x1]对应的指令高速缓存失效。
在第5行中,DSB指令保证其他CPU内核都能观察到,使指令高速缓存失效的操作完成。
在第6行中,[x2]表示标志位(flag),设置标志位为1,通知其他CPU代码已经更新了。
在第7行中,ISB指令保证CPU0从指令高速缓存中重新预取指令。
在第8行中,跳转到最新的代码中。
上述的第7行指令一定使用ISB指令,否则第8行指令就会提前位于流水线里,预取X1寄存器的旧数据,导致程序错误。
CPU1也开始执行新代码。
1 WAIT (x2 == 1)
2 isb
3 br x1第1行的伪代码WAIT表示等待标志位置位。当置位之后,我们需要使用一条ISB指令来保证CPU1从指令高速缓存里重新预取指令。
在这个例子里,有如下几个有趣的地方。
- 在更新代码与清理对应数据高速缓存之间(见CPU0的代码片段中的第1行和第2行)没有使用内存屏障指令。因为更新代码内容和清理数据高速缓存都操作相同的地址,它们之间有数据依赖性,可以理解为相同的观察者,所以可以保证程序执行的次序(program order)。
- 在清理数据高速缓存和使指令高速缓存无效之间需要内存屏障指令(见CPU0的代码片段中第2~4行)。虽然这两条高速缓存维护指令都操作相同的地址,但是它们是不同的观察者(一个在数据访问端,另一个在指令访问端),因此需要使用DSB指令来保证清理完数据高速缓存之后才去使指令高速缓存失效。
- 在一个多核一致性的系统中,DSB指令能保证高速缓存维护指令执行完,其他CPU内核能观察到高速缓存维护指令完。DSB指令会等待高速缓存维护指令发送广播到其他CPU内核,并且等待这些CPU内核返回应答信号。
18.2.8 高速缓存维护指令与内存屏障指令
在ARMv8体系结构里,高速缓存维护指令(例如DC和IC指令)的执行顺序需要分情况来讨论。指令单元、数据单元、MMU等都可以看成不同的观察者。
【例18-11】CPU执行如下两条指令。
dc civau x2
ic ivau x2第一条是数据高速缓存维护指令,第二条是指令高速缓存维护指令。尽管二者都对X2寄存器进行高速缓存的维护,但是IC指令可以乱序并提前执行,或者DC指令还没清理完高速缓存就开始执行IC指令,这会导致IC指令有可能获取了X2寄存器中的旧数据。
解决办法是在上述两条指令中间加入一条DSB指令,保证DC和IC指令的执行顺序,这样IC指令就可以获取X2的最新数据了。
这里加入一条DMB指令行不行?数据高速缓存维护指令可以当成数据访问指令,但是指令高速缓存维护指令不能当成数据访问指令。如果这里改成DMB指令,那么后面的IC指令可能会在DC指令前面执行。因此,这里必须使用DSB指令。
下面总结数据高速缓存、指令高速缓存以及TLB与内存屏障指令之间执行次序的关系。
1.数据高速缓存与统一高速缓存维护指令
通常L1高速缓存分成指令高速缓存和数据高速缓存,而L2和L3高速缓存是统一高速缓存。在单处理器系统中,使用一条DMB指令来保证数据高速缓存和统一高速缓存维护指令执行完。在多核系统中,同样使用DMB指令来保证高速缓存维护指令在指定的共享域中执行完。这里说的指定共享域通常指的是内部共享域和外部共享域。
以DC指令为例,使某个虚拟地址(VA)失效。在多核系统中,这条使高速缓存失效的指令会向所有CPU内核的L1高速缓存发送广播,然后等待回应。当所有的CPU内核都回复了一个回应信号之后,这条指令才算执行完。DMB指令会等待和保证在指定共享域中所有的CPU都完成了使本地高速缓存失效的操作并回复了应答信号。注意,加载-获取和存储-释放内存屏障原语对高速缓存维护指令没有作用,它不能等待高速缓存的广播答应。
DC指令与其他指令之间的执行次序需要分多种情况来讨论,我们假设这些指令之间没有显式地使用DSB/DMB指令(下面不讨论DC ZVA指令)。
DC指令与加载/存储指令之间保证程序执行次序(program order)的条件如下。
- 加载/存储指令访问的地址属于内部回写或者写直通策略的普通类型内存,并且它们访问的地址在同一个高速缓存行中。
- DC指令指定的地址与加载/存储指令访问的地址具有同一个高速缓存共享属性。
DC指令与加载/存储指令之间可以是任意执行次序的情况有好几种。
第一种情况如下。
- 加载/存储指令访问的地址属于内部回写或者写直通策略的普通类型内存,并且访问的地址在同一个高速缓存行中。
- DC指令指定的地址与加载和存储指令访问的地址不具有同一个高速缓存共享属性。
- DC指令与加载/存储指令之间没有使用DSB或者DMB指令。
第二种情况如下。
- 加载/存储指令访问的地址属于设备类型内存或者没有使能高速缓存的普通类型内存。
- DC指令与加载/存储指令之间没有使用DSB或者DMB指令。
第三种情况是加载/存储指令访问的地址和DC指令指定的地址不在同一个高速缓存行。
多条DC指令之间的执行次序如下:
如果DC指令指定的地址属于同一个高速缓存行,那么多条DC指令之间可以保证程序执行次序;如果DC指令指定的地址不在同一条高速缓存行或者没有指定地址,那么多条DC指令之间可以有任意执行次序。
DC指令与IC指令之间可以有任意执行次序。
综上所述,如果想保证DC指令与其他指令的执行次序,建议在DC指令后面添加DSB/DMB等内存屏障指令。
2.指令高速缓存维护指令
指令高速缓存与数据高速缓存在内存系统中是两个独立的观察者。与指令高速缓存相关的一些操作包括指令的预取、指令高速缓存行的填充等。与数据高速缓存相关的一些操作包括数据高速缓存行填充和数据预取等。
在指令高速缓存维护操作完成之后需要执行一条DSB指令,确保在指定的共享域里所有的CPU内核都能看到这条高速缓存维护指令执行完。使指令高速缓存失效的指令会向指定共享域中所有CPU内核发送广播,DSB指令会等待所有CPU内核的回应。
3.TLB维护指令
遍历页表的硬件单元和数据访问的硬件单元在内存系统中是两个不同的观察者。遍历页表的硬件单元就包括MMU以及TLB操作。
在TLB维护指令后面需要执行一条DSB指令,来保证在指定的共享域里面的所有CPU内核都能完成了TLB维护操作。在多核处理器系统中,TLB维护指令会发广播给指定共享域中的所有CPU内核,DSB指令会等待这些CPU的应答信号。
4.ISB指令不会等待广播应答
ISB指令不会等待广播应答信号,如果有需要,则每个CPU内核单独调用ISB指令。
本文摘自《ARM64体系结构编程与实践》

1.内容系统,突出动手实践
基于树莓派4B开发板,系统介绍ARM64体系结构,内容由浅入深,帮助读者开发运行小型的OS
2.以问题为导向,提高学习效率
深入浅出的问题导向式学习方法,各大公司高频面试题,提高读者阅读兴趣
3.趣味案例,常见陷阱总结
基于树莓派4B开发板和QEMU实验平台,总结了众多一线工程师在实际项目中遇到的陷阱与经验,让你不再害怕踩雷
4.海量资源随书赠送
本书赠送配套VMware开发环境,Linux软件包,QEMU+ARM64实验平台仓库,芯片资料,实验参考代码和配套资料以及配套教学视频供读者参考学习
本书旨在详细介绍ARM64体系结构的相关技术。本书首先介绍了ARM64体系结构的基础知识、搭建树莓派实验环境的方法,然后讲述了ARM64指令集中的加载与存储指令、算术与移位指令、比较与跳转等指令以及ARM64指令集中的陷阱,接着讨论了GNU汇编器、链接器、链接脚本、GCC内嵌汇编代码、异常处理、中断处理、GIC-V2,最后剖析了内存管理、高速缓存、缓存一致性、TLB管理、内存屏障指令、原子操作、操作系统等内容。