目录
一、数据的导入导出的三种方式:
我们以t_log表内的数据为例:

我们使用delete去删除该表的全部数据:
DELETE FROM t_log
delete 耗时 1.672s
第一种导入方式:
1.使用工具,类似Sqlyog、Navicat等导入导出数据。





导入耗时有:37秒41,耗时时间长,
将数据 导入成功之后,我们再使用TRUNCATE删除:

TRUNCATE 耗时 0.105s
delete 与 truncate 的区别就显而易见了,TRUNCATE 更加快
第二种导入方式:(以命令的形式)
2.使用mysqldump导入导出
2.1 导出
2.1.1 导出表数据和表结构
执行命令时候无需登录服务端,但是执行命令需要携带数据库用户及密码
mysqldump -u用户名 -p密码 数据库名 > 数据库名.sql(这个名字随便叫)#/usr/local/mysql/bin mysqldump -uroot -pabc >abc.sql
敲回车之后提示输出密码
2.1.2 只导出表结构
mysqldump -u用户名 -p密码 -d 数据库名 > 数据库名.sql#mysqldump -uroot -p -d abc > abc.sql
注:导出的数据在mysql的bin目录下
2.2 导入
注意:首先建立空数据库
mysql>create database abc;
2.2.1 方法一
mysql>use abc; #选择数据库
mysql>set names utf8; #设置数据库编码
mysql>source /home/abc/abc.sql; #导入数据
2.2.2 方法二
mysql -u用户名 -p密码 数据库名 < 数据库名.sql
#mysql -uabc_f -p abc < abc.sql
第三种导入方式:
3.LOAD DATA INFILE
可先通过SELECT INTO OUTFILE方式,将数据导出到Mysql的C:\ProgramData\MySQL\MySQL Server 5.5\data目录下,再通过LOAD DATA INFILE方式导入。
1) select * from 表名 into outfile '/文件名.sql';
2) load data infile '/文件名.sql' into table 表名(列名1,...);
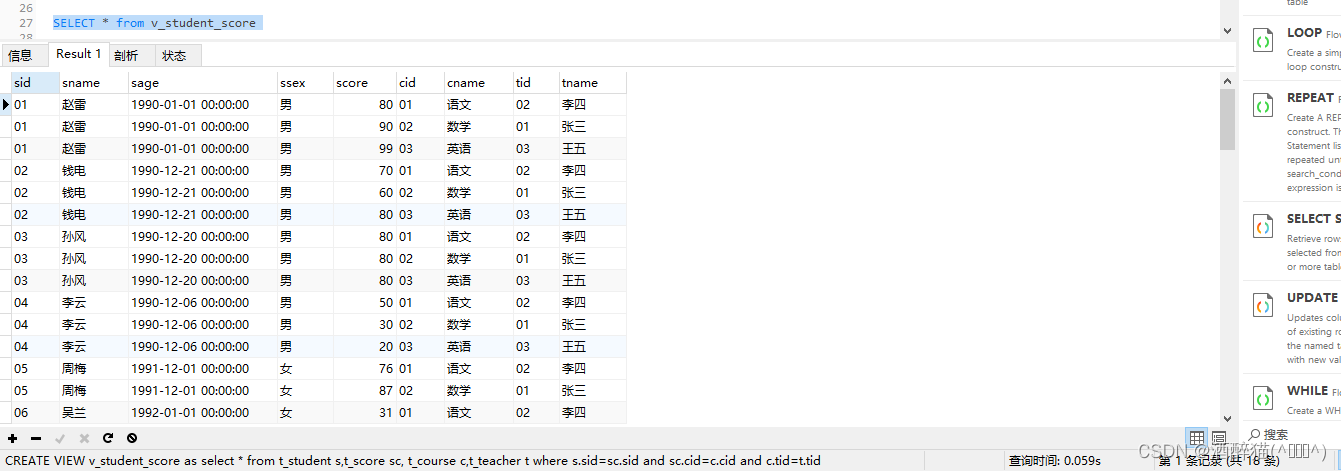
二、视图
1.什么是视图
1) 视图是一种虚拟的表,是从数据库中一个或多个表中导出来的表。
2) 数据库中存放了视图的定义,而并没有存放视图中的数据,这些数据存放在原来的表中。
3) 使用视图查询数据时,数据库系统会从原来的表中取出对应的数据。
2.视图的作用
1) 使操作简便化。
2) 增加数据的安全性。
3) 提高表的逻辑独立性。
3.基本语法
CREATE VIEW 视图名 AS SELECT 语句;

三、索引
1.什么是索引
索引是由数据库表中一列或多列组合而成,其作用是提高对表中数据的查询速度。
类似于图书的目录,方便快速定位,寻找指定的内容。
2.索引的优缺点
优点:提高查询数据的速度。
缺点:创建和维护索引的时间增加了,同时占用硬盘空间。
3.索引分类
1) 普通索引:是最基本的索引,它没有任何限制;
2) 唯一索引:与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一;
3) 主键索引:是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值;
4) 组合索引:指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合;
5) 全文索引:使用FULLTEXT参数可以设置,全文索引只能创建在
CHAR,VARCHAR,TEXT类型的字段上。主要作用是提高查询较大字符串类型的速度;只有MyISAM引擎支持该索引,MySQL默认引擎不支持;mysql5.7+
4.创建索引
CREATE [UNIQUE|FULLTEXT] INDEX 索引名 ON 表名(字段名[(长度)][ASC|DESC])
5.修改索引
ALTER TABLE 表名 ADD [UNIQUE|FULLTEXT] INDEX 索引名(字段名[(长度)][ASC|DESC])
6.删除索引
DROP INDEX 索引名 ON 表名
案例:
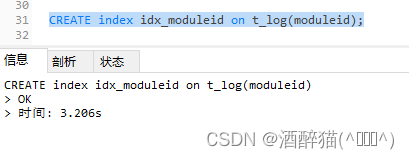
1) 普通索引案例
create index 索引名 on 表名(字段名)select * from t_log where moduleid='110204999';
CREATE index idx_moduleid on t_log(moduleid);
2) 唯一索引案例(对应列值不允许相同)
create unique index 索引名 on 表名(字段名)create UNIQUE index idx_url on t_log(url);
3) 主键索引案例
create table 表名(
id int not null auto_increment primary key,
...
)select * from t_log where id='094228e7b3be48218fe23c7d1a26c566';
4) 组合索引案例 (最左列段匹配原则)
create index 索引名 on 表名(字段名1,字段名2,...)create index idx_userid_moduleid_url on t_log(userid,moduleid,url);EXPLAIN SELECT * FROM t_log;
EXPLAIN SELECT * FROM t_log where userid='';
EXPLAIN SELECT * FROM t_log where userid='' and moduleid = '';







EXPLAIN SELECT * FROM t_log where userid='' and url = '';

EXPLAIN SELECT * FROM t_log where userid='' and moduleid = '' and url='';
EXPLAIN SELECT * FROM t_log where url='';


EXPLAIN SELECT * FROM t_log where moduleid ='';
补充说明:
批量导入:LOAD DATA INFILE(推荐)
可先通过SELECT INTO OUTFILE方式,将数据导出到Mysql的C:\ProgramData\MySQL\MySQL Server 5.5\data目录下,再通过LOAD DATA INFILE方式导入。
1) select * from 表名 into outfile '/文件名.sql';
2) load data infile '/文件名.sql' into table 表名(列名1,...);
四、执行计划



1.什么是执行计划?
使用 EXPLAIN 关键字可以模拟优化器执行SQL查询语句,从而知道MYSQL是如何处理你的sql语句的。分析你的查询语句或是表结构的性能瓶颈。
语法: Explain + sql
2.执行计划的作用:
1) 表的读取顺序
2) 数据读取操作的操作类型
3) 哪些索引可以使用
4) 哪些索引被实际使用
5) 表之间的引用
6) 每张表有多少行被优化器查
3.执行计划包含的信息
3.1 id - 获取select子句的操作表顺序,有几种情况:
1) id 相同的情况下执行顺序是由上到下。
2) id 越大优先级越高,如果是子查询,ID 序列号会递增,id值越大,优先级越高,越先执行。
3) id 相同又有不相同的,序列号大的会先执行,然后相同的从上到下执行。
3.2 select_type - 查询的类别,
主要用于区别普通查询,联合查询,子查询等的复杂查询
1) simple: 简单的select 查询,不包含子查询或者 union
2) primary: 查询中包含任何复杂的子部分,最外层查询则被标记
3) subquery: 在 select 或者 where 列表中包含了子查询
4) derived: 在from 列表中包含子查询被标记为 derived Mysql 会递归执行这些子查询,把结果放到临时表里
5) union: 若在第二个 select 中出现 union之后,则被标记为 union 若union包含在 from 子句的子查询中,外层 select 将被标记为 derived
6) union result: 从 union 表获取结果的 SELECT
案例:
示例一:explain
EXPLAIN SELECT * FROM t_user;
EXPLAIN SELECT * FROM t_user u where u.roleid =(select roleid from t_role where rolename='管理员' )
示例二:id
1)id相同,从上往下一次执行
左外联
EXPLAIN SELECT * FROM t_user u left join t_role r on u.roleid=r.roleid
右外联
EXPLAIN SELECT * FROM t_user u right join t_role r on u.roleid=r.roleid 
注:通过left join 和 right join 验证;id一样(注意执行计划的table列),left join 先扫描a表,再扫描b表;right join 先扫描b表,再扫描a表
2)id越大优先级越高
示例三:select_type
1)SIMPLE(简单SELECT,不使用UNION或子查询等)EXPLAIN SELECT * FROM t_user;2)PRIMARY(查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
SUBQUERY(子查询中的第一个SELECT)EXPLAIN SELECT * FROM t_user u where u.roleid =(select roleid from t_role where rolename='管理员' )3)UNION(UNION中的第二个或后面的SELECT语句)
UNION RESULT: 从 union 表获取结果的 SELECTEXPLAIN SELECT u1.* FROM t_user u1 where u1.id=3 union select u2.* from t_user u2 where u2.roleid=3
4)DERIVED(派生/衍生表的SELECT, FROM子句的子查询)

示例四:正确使用索引
1)使用 like 语句时,%在右边才会使用索引。
有效:
EXPLAIN SELECT * FROM t_user where username like '张%'
无效:
EXPLAIN SELECT * FROM t_user where username like '%张%'
2)or条件中有未建立索引的列才索引失效
无效:
EXPLAIN select * FROM t_user where username ='张三' or `Password`=123456;
有效:
EXPLAIN select * FROM t_user where username ='张三' and `Password`=123456;
3)条件的类型不一致
无效:
EXPLAIN select * from t_user where username=1有效:
EXPLAIN select * from t_user where username='1'
4)!= 号(例外:如果是主键,则会走索引)
无效:
EXPLAIN select * from t_user where username!='张三'
6)order by
EXPLAIN select * from t_user where username!='张三'
order by roleid7)组合索引(遵循最左前缀)