字符串
一、字符串的定义
字符串:简称为串,是由零个或多个字符组成的有限序列。一般记为s = “a1a2 .…an" (0 ≤ ∞)。
- 空串:零个字符构成的串也称为「空字符串」,它的长度为0,可以表示为" "。
- 子串∶字符串中任意个连续的字符组成的子序列称为该字符串的「子串」。
并且有两种特殊子串,起始于位置为0、长度为 k 的子串称为「前缀」。而终止于位置 n -1、长度为 k 的子串称为「后缀」。 - 主串:包含子串的字符串相应的称为「主串」。
字符串常见的问题
- 字符串匹配问题
- 子串相关问题
- 前缀 / 后缀相关问题
- 回文串相关问题
- 子序列相关问题
二、字符串的比较(strcmp方法)
字符串之间的比较是通过组成字符串的字符之间的「字符编码」来决定的,而字符编码的是字符在对应字符集中的序号。
- 当 str1 < str2 时,strcmp 方法返回 -1。
- 当 str1 == str2 时,strcmp 方法返回 0。
- 当 str1 > str2 时,strcmp 方法返回 1。
def strcmp (str1, str2): #strcmp方法实现代码
index1, index2 = 0, 0
while index1 < len(str1) and index2 < len (str2):
if ord(str1[index1]) == ord(str2 [index2]):
index1 += 1
index2 += 1
elif ord(str1[index1]) < ord(str2[index2]):
return -1
else:
return 1
if len (str1) < len(str2):
return -1
elif len(str1) > len (str2):
return 1
else:
return 0
三、字符串的存储结构
字符串的存储结构跟线性表相同,分为「顺序存储结构」和「链式存储结构」。
顺序存储结构
在内存上是连续的。

链式存储结构
采用链表的储存方式。

四、字符串的匹配问题
字符串匹配:又称「模式匹配」。可以简单理解为,给定字符串 T 和 p,在主串 T 中寻找子串 p。主串 T 又被称为「文本串」,子串 p 又被称为「模式串」。
在字符串问题中,最重要的问题之一就是字符串匹配问题。而按照模式串的个数,我们可以将字符串匹配问题分为:「单模式串匹配问题」和「多模式串匹配问题」。
单模式匹配问题
- 基于前缀搜索方法
KMP算法 和 Shift-Or算法 - 基于后缀搜索方法
BM 算法、Horspool 算法 和 Sunday 算法 - 基于子串搜索方法
Rabin-Karp 算法、BDM 算法、BNDM 算法 和 BOM 算法 使用的就是这种思想。
其中,Rabin-Karp 算法使用了基于Hash的子串搜索算法。
多模式匹配问题
- 基于前缀搜索方法
AC自动机算法 和 Multiple Shift-And算法 - 基于后缀搜索方法
Set Horspool算法 和 Wu-Manber算法 - 基于子串搜索方法
Multiple BNDM算法、SBDM算法 和 SBOM算法
多模式串匹配算法大多使用了一种基本的数据结构:「字典树(Trie)」。
著名的 「AC 自动机算法」就是在 KMP 算法 的基础上,与「字典树」结构相结合而诞生的。而「AC 自动机算法」也是多模式串匹配算法中最有效的算法之一。所以学习多模式匹配算法,重点是要掌握 「字典树」 和 「AC 自动机算法」。
单模式串朴素匹配算法
Brute Force算法
中文意思是暴力匹配算法,也可以叫做朴素匹配算法。

在匹配过程中可能会出现回溯:当遇到一对字符不同时,模式串p直接回到开始位置,文本串也回到匹配开始位置的下一个位置,再重新开始比较。
最坏情况是每一趟比较都在模式串的最后遇到了字符不匹配的情况,每轮比较需要进行m次字符对比,总共需要进行n - m +1轮比较,总的比较次数为m * (n - m + 1)。所以BF算法的最坏时间复杂度为O(m * n)。
在最理想的情况下(第一次匹配直接匹配成功),BF 算法的最佳时间复杂度是O(m)。
def bruteForce ( T: str, p: str) -> int:
n, m = len ( T), len(p)
i, j = 0, 0 #i表示文本串T的当前位置,j表示模式串p 的当前位置
while i < n and j < m: #i或j其中一个到达尾部时停止搜索
if T[i]== p[j]: #如果相等,则继续进行下一个字符匹配
i += 1
j+= 1
else:
i = i - (j - 1) #如果匹配失败则将i移动到上次匹配开始位置的下一个位置
j = 0 #匹配失败j回退到模式串开始位置
if j== m:
return i - j #匹配成功,返回匹配的开始位置
else:
return -1 #匹配失败,返回-1
KMP算法
KMP算法思想∶对于给定文本串T与模式串p,当发现文本串T的某个字符与模式串p 不匹配的时候,可以利用匹配失败后的信息,尽量减少模式串与文本串的匹配次数,避免文本串位置的回退,以达到快速匹配的目的。
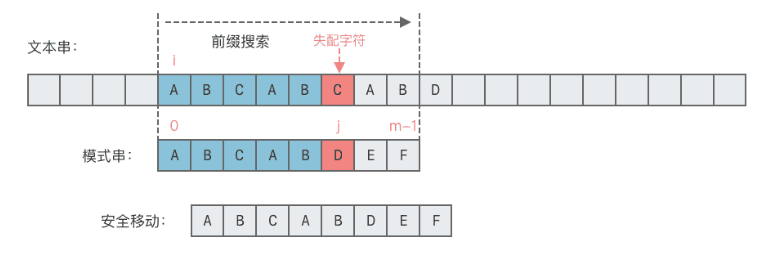
KMP 算法在构造前缀表阶段的时间复杂度为O(m),其中m是模式串p的长度。
KMP 算法在匹配阶段,是根据前缀表不断调整匹配的位置,文本串的下标 i 并没有进行回退,可以看出匹配阶段的时间复杂度是O(n),其中n是文本串T的长度。
所以KMP 整个算法的时间复杂度是O(n + m),相对于朴素匹配算法的O(n * m)的时间复杂度,KMP算法的效率有了很大的提升。
#生成next数组
# next[ j]表示下标j之前的模式串 p 中,最长相等前后缀的长度
def generateNext(p: str):
m = len(p)
next =[ 0 for _ in range ( m) ] #初始化数组元素全部为0
left = 0 #left表示前缀串开始所在的下标位置
for right in range(1, m): #right表示后缀串开始所在的下标位置
while left > 0 and p[left] != p[right]: #匹配不成功,left进行回退,left == 0时停止回退
left = next [left - 1] #left进行回退操作
if p[left] == p[right]: #匹配成功,找到相同的前后缀,先让left += 1,此时left为前缀长度
left += 1
next[right] = left #记录前缀长度,更新next[ right],结束本次循环,right += 1
return next
#KMP 匹配算法,T为文本串,p 为模式串
def kmp (T: str, p: str) -> int :
n, m = len (T), len(p)
next = generateNext(p) #生成next数组
j = 0 #j为模式串中当前匹配的位置
for i in range(n): #i为文本串中当前匹配的位置
while j > 0 and T[i]!= p[j]: #如果模式串前缀匹配不成功,将模式串进行回退,j=0时停止回退
j = next[j - 1]
if T[i] == p[j]: #当前模式串前缀匹配成功,令j+= 1,继续匹配
j += 1
if j == m: #当前模式串完全匹配成功,返回匹配开始位置
return i - j +1
return -1 #匹配失败,返回-1
本文章主要内容摘自阿里云天池leetcode训练营,主要当作笔记记录,如有错误的地方或者有没写完的地方,请见谅。