前言
事务是mysql Innodb引擎的一大特点,可以说,在日常开发中,对于mysql事务的使用无处不在,因此深入了解并掌握mysql的事务原理很有必要。
一、mysql事务简介
- 事务 是一组操作集合,一个不可分割的工作单位;
- 事务会将所有操作作为一个整体,一起向系统提交或撤销操作请求,这些操作要么同时成功,要么同时失败;
比如 : 张三给李四转账1000块钱,张三银行账户减少1000元,而李四银行账户的钱要增加1000元。 这一组操作就必须在一个事务的范围内,要么都成功,要么都失败
二、事务四大特性
是事务的四大特性,简称ACID
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败;
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态;
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行;
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的;
三、事务案例演示
下面来模拟一个事务操作,准备如下一张表,并初始化两条数据,来模拟转账的事务操作;
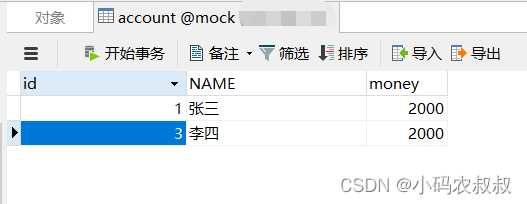
1) 测试一个正常的操作
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三余额减1000
update account set money = money - 1000 where name = '张三';
-- 3. 李四余额加1000
update account set money = money + 1000 where name = '李四';
执行完成后,可以看到效果是预期的;
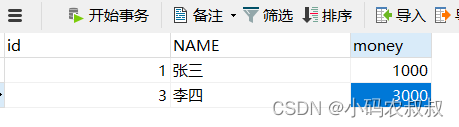
2)测试异常情况
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三余额减1000
update account set money = money - 1000 where name = '张三';
1/0
-- 3. 李四余额加1000
update account set money = money + 1000 where name = '李四';
由于这个语句中出现了一个不符合sql语法的错误,执行到1/0的时候报错,导致第三步无法正常执行,最终的结果如下,即张三扣减了1000,但是李四并没有加1000,即数据在操作前后不一致了;
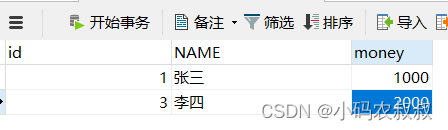
基于上面产生的异常情况,在实际开发过程中,假如是运行在程序中的,为了避免出现这样的问题,就需要通过事务来进行控制;
通过事务控制
在操作之前,我们需要了解下面两个命令
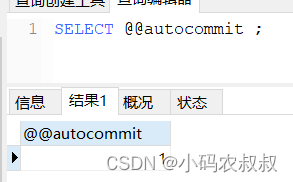
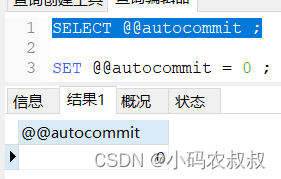
1、查看当前的事务提交方式
SELECT @@autocommit ;
“1”表示自动提交,即在默认情况下,事务是自动提交的,为了模拟事务的效果,我们需要修改下这个事务的自动提交方式;
2、设置事务提交方式
SET @@autocommit = 0 ;
即将提交方式设置为手动提交
1) 测试正常操作
-- 开启事务
start transaction
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三余额减1000
update account set money = money - 1000 where name = '张三';
-- 3. 李四余额加1000
update account set money = money + 1000 where name = '李四';
-- 如果正常执行完毕, 则提交事务
commit;
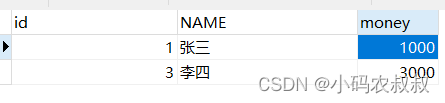
注意,在未走到 commit之前,上面的更新操作不会被写入到表中,只有执行commit,才算结束,观察数据,发现满足预期的效果;
2)测试异常操作
在上面没有添加事务操作时,走到 1/0 的时候发现数据最终异常了,这时候我们添加上事务的操作,看看效果如何;
首先执行下面一系列操作
start transaction
select * from account where name = '张三';
update account set money = money - 1000 where name = '张三';
1/0;
update account set money = money + 1000 where name = '李四';
这时候,由于有 1/0 的存在,导致执行错误,但是这个时候由于我们开启了手动提交事务,在这种出现了异常的情况下,可以通过执行rollback,执行完成之后,即便发生异常,数据仍然恢复到操作之前的一致状态;
-- 如果执行过程中报错, 则回滚事务
rollback;

四、并发事务问题
在真实的业务场景中,并发操作在大部分情况下,最终将归为对数据库表的并发操作,并发需要解决的问题也就是mysql事务并发需要解决的问题,一般来说,数据库的事务并发带来的影响也是不同的,常见的问题主要分为下面几种;
- 脏读:一个事务读取到另一个事务还未提交的数据;
- 不可重复读:一个事务先后读取同一条数据,但是两次读取到的值不同,叫做不可重复读;
- 幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,却发现这条数据已经存在,好像出现了幻影一样;
五、事务隔离级别
上面介绍了几种并发事务执行过程中可能遇到的问题,这些问题有轻重缓急之分,我们给这些问题按照严重性来排一下序:
脏写 > 脏读 > 不可重复读 > 幻读
一般来说,我们愿意舍弃一部分隔离性来换取一部分性能,可以结合业务的实际情况,设立不同的隔离级别,当然隔离级别越低,并发问题发生的就越多。常用的隔离级别总结如下:
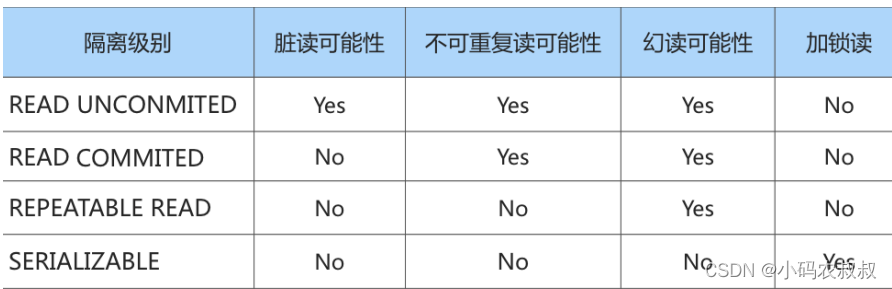
- READ UNCOMMITTED :读未提交,在该隔离级别下,所有事务都可以看到其他未提交事务的执行结果。不能避免脏读、不可重复读、幻读;
- READ COMMITTED :读已提交,一个事务只能看见已经提交事务所做的改变。这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。可以避免脏读,但不可重复读、幻读问题仍然存在;
- REPEATABLE READ :可重复读,事务A在读到一条数据之后,此时事务B对该数据进行了修改并提交,那么事务A再读该数据,读到的还是原来的内容。可以避免脏读、不可重复读,但幻读问题仍然存在。这是MySQL的默认隔离级别;
- SERIALIZABLE :可串行化,确保事务可以从一个表中读取相同的行。在这个事务持续期间,禁止其他事务对该表执行插入、更新和删除操作。所有的并发问题都可以避免,但性能十分低下。能避免脏读、不可重复读和幻读;
针对不同的隔离级别,并发事务可以发生不同严重程度的问题,具体情况如下:
1、查看事务隔离级别
SELECT @@TRANSACTION_ISOLATION;
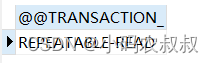
mysql默认事务隔离级别:REPEATABLE-READ(可重复读)
2、设置事务隔离级别
可以通过下面的语句来手动设置事务的隔离级别
SET [ SESSION | GLOBAL ] TRANSACTION ISOLATION LEVEL { READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE }
注意:事务隔离级别越高,数据越安全,但是性能越低
六、事务隔离级别操作演示
1、读未提交
这种隔离级别最低,即A事务可以读取到另一个事务未提交的数据,仍然使用上面的accounbt表,开启两个命令行操作窗口;
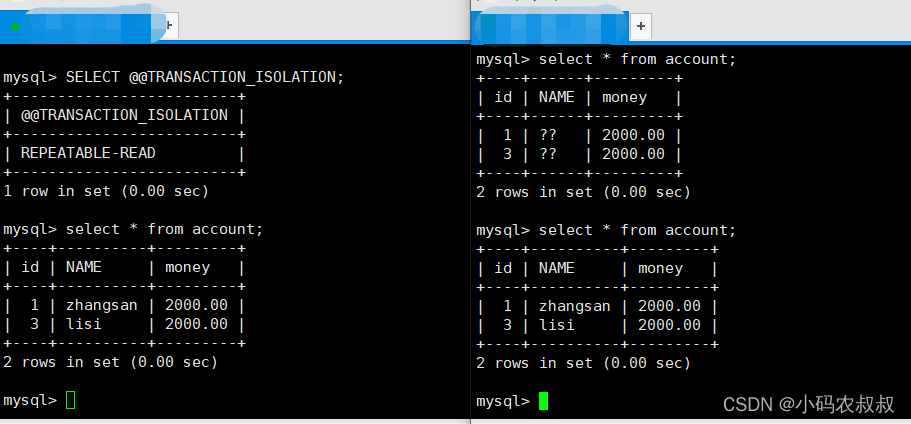
将当前左边的事务会话隔离级别设置为读未提交
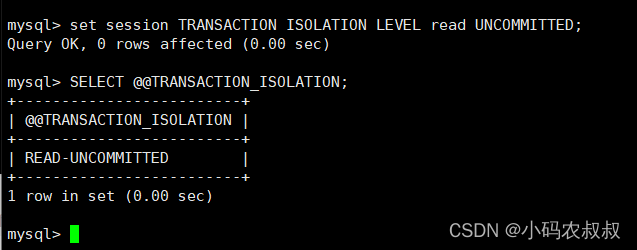
然后,在两个session会话窗口分别开启事务,这时候,在右边的窗口执行更新操作,再次在左边的窗口查询右边窗口更新的这条数据,发现竟然读到了右边窗口未提交的数据,这就是读未提交的效果(脏读);
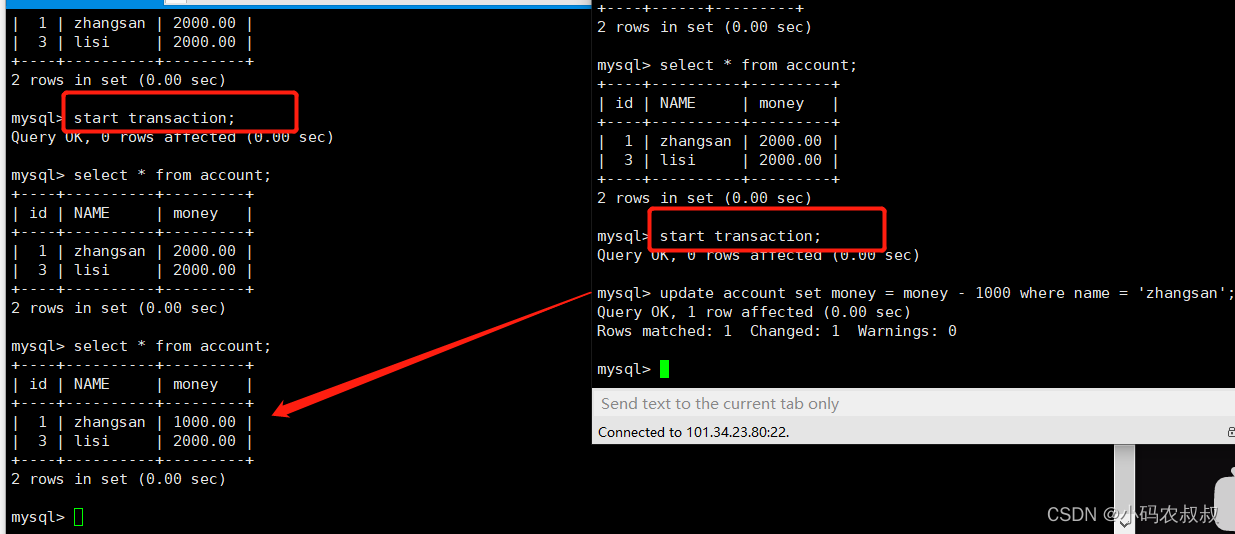
2、读已提交
在读未提交,产生了脏读问题,那么使用读已提交这个隔离级别就可以解决这个问题
设置左边的隔离级别为读已提交
set session TRANSACTION ISOLATION LEVEL read COMMITTED;
将表的数据复原后再次重复上面的操作过程,通过结果展示可以发现,在这种隔离级别下,脏读的问题就解决了;
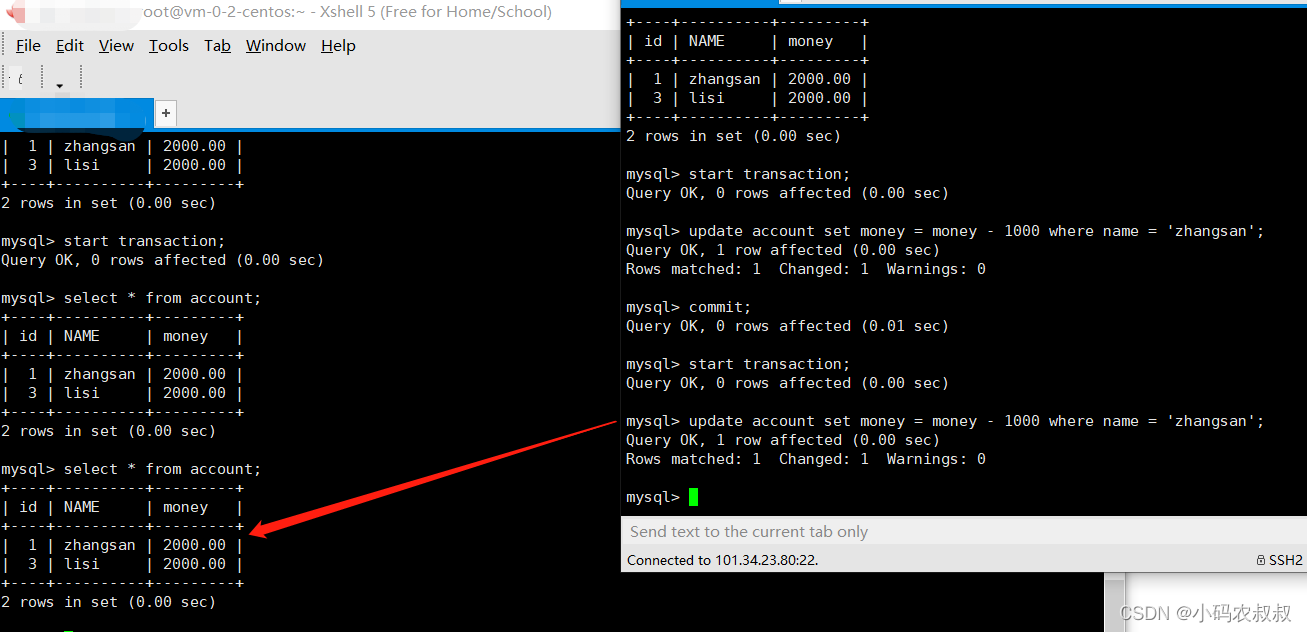
剩下的其他两种操作,有兴趣的同学可以按照同样的方式来操作下,要注意的是各自解决的问题点是什么即可;
spring 框架中的事务
在springboot项目中,通常不需要大家手动去配置事务管理器,这是spring框架在启动的时候,默认会启用jdbc的事务管理器,只需要在使用事务的方法上面,去配置相关的注解即可;

在spring的spring.factories配置文件中,提供了一个默认的 DataSourceTransactionManagerAutoConfiguration 事务管理器,在spring容器初始化的时候,会将这个默认的事务管理器加载到容器中;
七、事务实现原理
通过上面的讲解,我们了解到mysql的事务有4种特性:原子性、一致性、隔离性和持久性。那么事务的四种特性是基于什么机制实现呢?
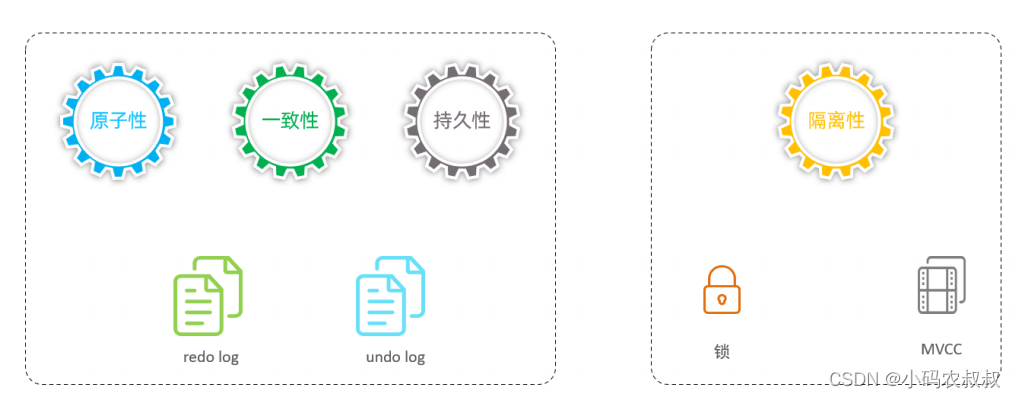
- 事务的隔离性基于锁机制 实现;
- 而事务的原子性、一致性和持久性由事务的 redo 日志和undo 日志来保证;
REDO LOG:
重做日志 ,提供再写入操作,恢复提交事务修改的页操作,用来保证事务的持久性
该日志文件由两部分组成:重做日志缓冲(redo log buffer)及重做日志文件(redo logfile),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到该日志文件中, 用于在刷新脏页到磁盘,发生错误时, 进行数据恢复使用;
为什么需要REDO日志
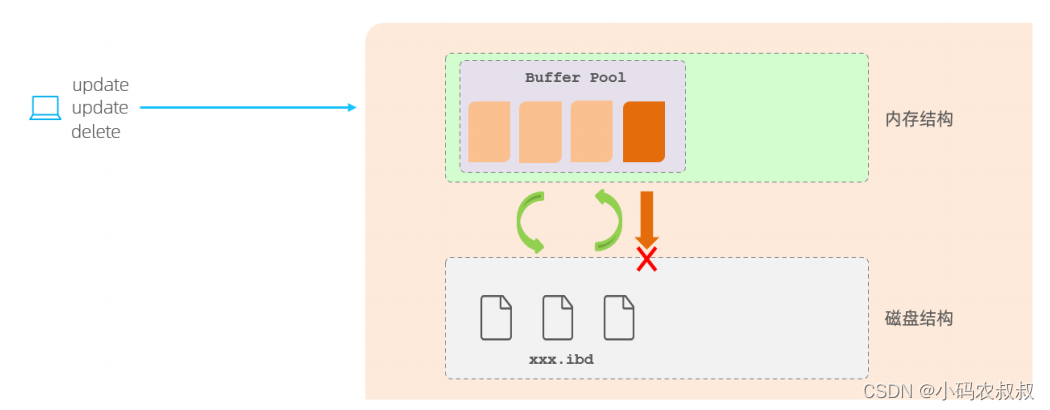
- 在InnoDB引擎的内存结构中,主要的内存区域就是缓冲池,在缓冲池中缓存了很多的数据页,在一个事务执行增删改查等操作时,InnoDB引擎会先操作缓冲池中的数据,如果缓冲池中没有数据,才会通过后台线程,将磁盘中的数据加载到缓冲池,并放到缓冲区内存中,然后对缓冲区的数据进行修改,修改的数据页也叫做脏页;
- 脏页则会在一定的时机,通过后台线程刷新到磁盘中,从而保证缓冲区与磁盘的数据一致;
- 缓冲区的脏页数据并不是实时刷新,而是一段时间之后,将缓冲区的数据刷新到磁盘中;
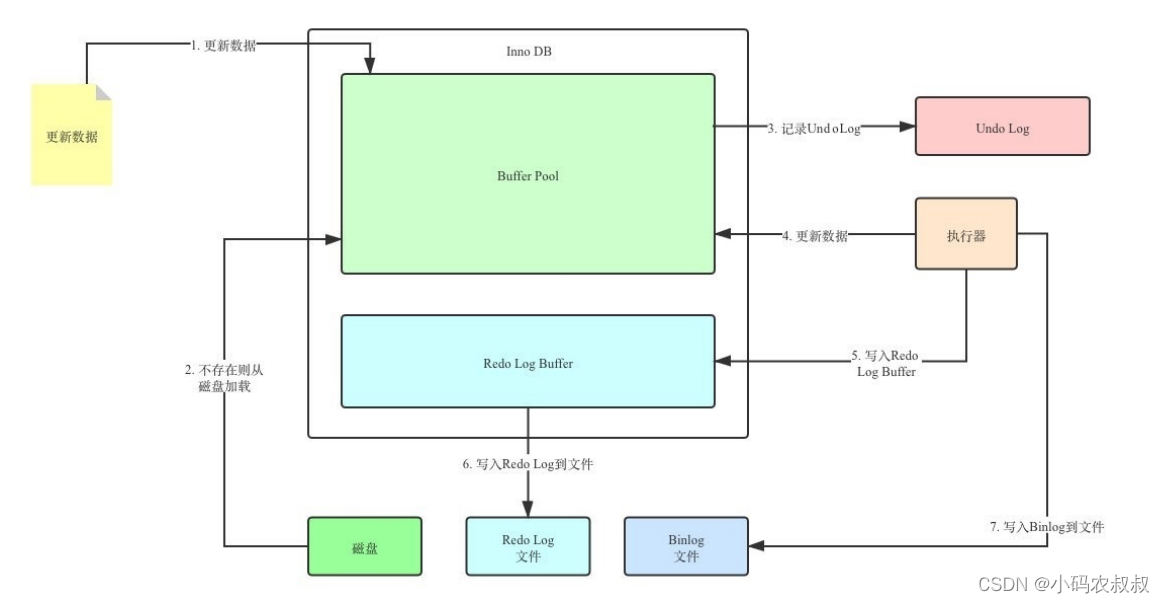
假如刷写脏页的数据到磁盘过程中出错了,而提示给用户的却是事务提交成功,这样一来,数据就没有持久化到磁盘,这就有问题了,即没有保证事务的持久性,大致的流程如下:
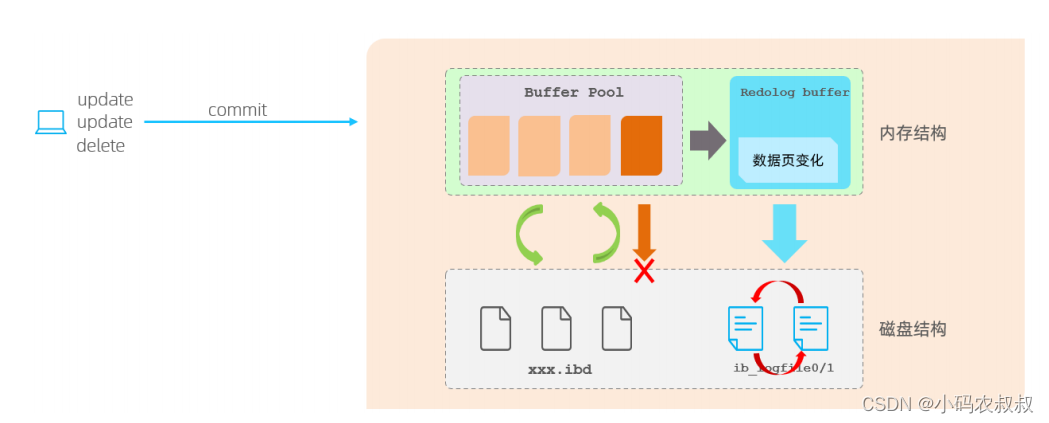
如何解决上面的问题呢?这就要用到 redo log了,在InnoDB中提供了一份日志 redo log;
- 当对缓冲区数据进行增删改操作后,会先将操作的数据页的变化,记录在redo log buffer中;
- 在事务提交时,会将redo log buffer中的数据刷新到redo log磁盘文件中;
- 一段时间后,如果刷新缓冲区的脏页到磁盘时发生错误,此时就可以借助于redo log进行数据恢复,这样就可以保证事务的持久性;
- 如果脏页成功刷新到磁盘 ,或者数据已经落盘,此时redolog就没有作用了,就可以删除了;
- 存在的两个redolog文件是循环写;
为什么每次提交事务,要刷新redo log 到磁盘中呢,而不是直接将buffer pool中的脏页刷新到磁盘呢 ?
因为在业务操作中,我们操作数据一般都是随机读写磁盘的,而不是顺序读写磁盘。 而redo log在往磁盘文件中写入数据,由于是日志文件,所以是顺序写的。顺序写的效率,要远大于随机写。 这种先写日志的方式,称之为 WAL(Write-Ahead Logging)。
Redo log 组成
Redo log可简单分为以下两部分:
- 重做日志的缓冲 (redo log buffer) ,保存在内存中,是易失;
- 重做日志文件 (redo log file) ,保存在硬盘中,是持久;
参数设置:innodb_log_buffer_size,redo log buffer 大小,默认 16M ,最大值是4096M,最小值为1M。可以通过命令行进行查看,
show variables like ‘%innodb_log_buffer_size%’;
最后总结下,以一个更新事务为例,redo log 流转过程,如下图所示:
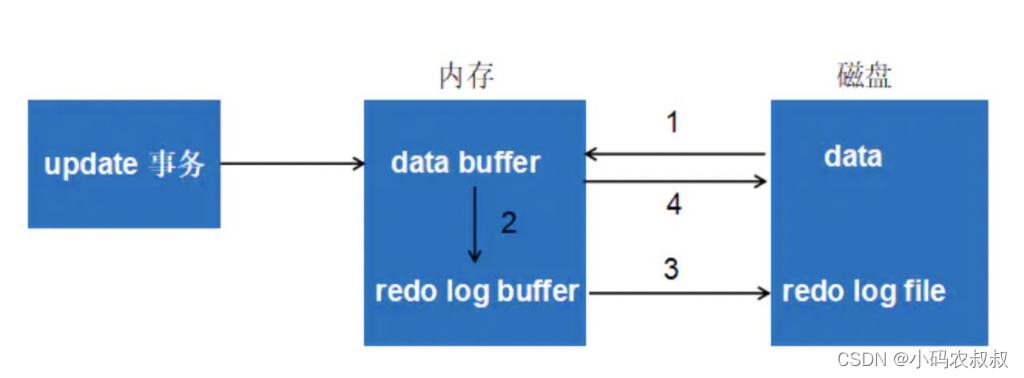
- 将原始数据从磁盘中读入内存中来,修改数据的内存拷贝;
- 生成一条重做日志并写入redo log buffer,记录的是数据被修改后的值;
- 当事务commit时,将redo log buffer中的内容刷新到 redo log file,对 redo log file采用追加 写的方式;
- 定期将内存中修改的数据刷新到磁盘中;
UNDO LOG
回滚日志 ,回滚行记录到某个特定版本,用来保证事务的原子性、一致性
- undo log和redo log记录物理日志不一样,它是逻辑日志;
- 可以认为当delete一条记录时,undolog中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录;
- 当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚;
其实在使用分布式事务框架的时候,其底层实现原理也是借助了 undo log的思想,记录了反向操作的sql语句,以便于事务回滚时使用;
undo 的类型
在InnoDB存储引擎中,undo log分为:
- insert undo log
- update undo log
undo log 生成过程
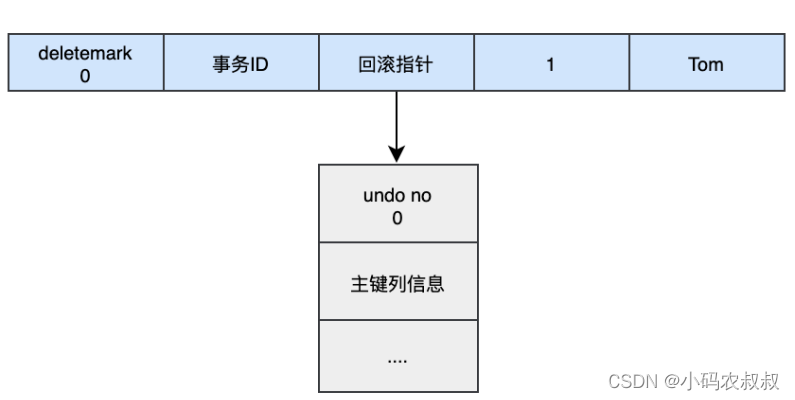
在innodb 中,表的数据行记录结构如下所示,可以理解这是一个数据行完整的逻辑存储结构;

当我们执行一个insert操作,即给表中添加一条记录时,比如下面这条语句:
INSERT INTO user (name) VALUES ("tom");
其实对应的undo log中将会反向生成一条delete的记录
同样,当执行 update语句的时候,将会记录本次更新数据之前的相关列字段信息,有了这样的认识后,我们来总结下,当发生回滚的时候,undo log是如何进行的:
- 通过undo no 定位这条数据记录中id为1的数据;
- 把id=1的数据的deletemark还原成0;
- 把id=1的数据的name还原成null;
- 把id=1的数据删除;