controller-manager包含了一组控制器,它是整个集群的大脑,每个控制器会关注自己所关注的对象,这些控制器里面都会有一个固定的模式,每个控制器都会通过list watcher,去watch它所关注的对象,当这些对象发生变化以后,以事件通知的形式,告知controller,controller会注册这些事件的回调函数,并且将这些事件放在一个队列里面,同时会去启动一堆worker线程,来从队列里面取出这些对象,并且进行相关的处理。
也就是说,当读了任何一个controller manager的代码,可以将同样的思路套到其他的controller里面。
在每个节点上面都会去运行一个组件叫做kubelet。
Kubelet架构

它是承担的很多很多职责的这样一个组件。

最上层,它会提供一个api层,这个api里面就会有蛮多的职责,比如做自己的探活,还有业务指标如何上报,这些都是通过api,你可以看到它工作在不同的端口上面都有监听器,承担不同的职责。
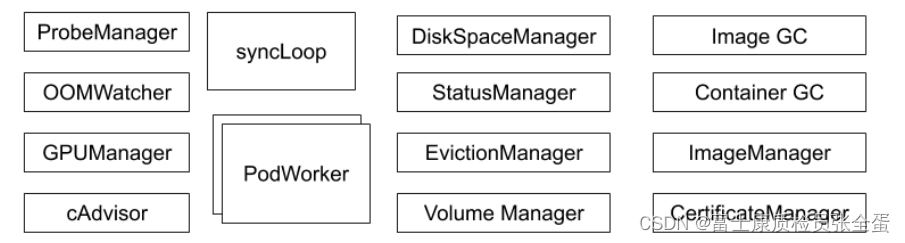
中间就是在kubelet里面运行了一个一个的manager,你可以理解为一个一个独立职责的小的管理器。
probemanager:就是为这个节点上面的pod做探活的这样一个管理器,liveless readyless probe,这些探活由kubelet发起,kubelet的probemanager会去读取当前节点上面所有probe的定义,然后它会去看这些probe有没有定义探活,如果定义了探活的属性,那么probemanager就会按照你定义的interval去做监听。
oomwatcher:kubelet是整个节点的守护神,它是一个代理,它负责所有应用的生命周期,同时它有包含节点当前继续正常工作的职责,所以它由oomwatcher来监听,比如节点出现oom问题,比如某些进程出现了oom的错误,oomwathcer就会通过oom这个事件来获取这些异常,并且上报给kubelet。
GPU manager:就是用来管理GPU等等这些扩展的device,当节点上有GPU卡的时候,GPUmanager就是用来管理这张GPU卡的。
cadvisor:是独立开源的软件,kubelet里面会内嵌cadvisor,它其实基于cgroup技术去获取节点上运行应用的资源状态,整个集群的监控都是由cadvisor收集上来的,并且通过kubelet上报的。
diskspacemanager:这个节点的磁盘空间大小,包括每个应用,你上去了临时空间,你是不是超了,由diskspacemanager来管理。
statusmanager:用来管理节点的状态的。
evictionmanager:kubelet是这个节点的守护神,它会去监听当前节点上所有pod所消耗的资源,比如说内存,内存是不可压缩资源,可压缩资源cpu,cpu是基于分时复用的,当你多个进程去抢cpu的时候,反正我们按照协商好的比例去分cpu时间片,当出现竞争的时候,顶多受损,不会异常退出。但是内存不一样,内存是不可压缩资源,针对内存,kubelet就会做比较激进的动作,eviction,evictionmanager就是承担这个职责的组件。它会去监听当前节点的资源使用情况,如果它发现内存已经达到了一个水位,比如10g内存使用了9g,如果不制止这种情况,那么可能整个节点都会受到影响。evictionmanager就会去监听这个水位,当这个内存达到一定水位的时候,它就会去做驱逐,它会去按照既定策略将低优先级的业务,而且占用内存又比较大的,超出了自己预设值的这些进程驱逐掉,也就是将pod从这个节点删除掉。通过这种极端的方式来保护整个节点。
volumemanager:pod启动要挂载磁盘,要挂载存储卷的,这个是由volumemanager去做的。
imagegc:如果我这个节点不断的启动应用,每个应用都需要拉取自己的image,如果我不做一些清理工作,就会导致这个节点的image会越来越多,把磁盘占满,所谓的imagegc就会去扫描一些不怎么活跃的镜像,把这些镜像清除掉。
containegc就是你的进程可能会退出,它会有一个exit的container,这个container其实它的文件层是没有清理掉的,所谓的container gc就是会清除这些退出的容器。
imagemanager:就是做镜像管理的。
certificatesmanager:kubelet有签证书的能力,当我们需要kubelet去管理证书的时候,certificatesmanager就可以起作用。
中间还有一个syncgroup,所谓的syncgroup又是控制器模式了,它要去watch一堆对象,也就是当前节点的pod对象,syncgroup做完之后,下面内嵌了一堆的worker,pod worker就是当我的syncgroup接收到pod的变更通知的时候,那么这个podworker就会去干活,也就是去维护pod的生命周期。
kubelet要去监听apiserver去获取当前节点的pod清单,获取pod清单之后,然后获取的pod清单,每个pod都是一个一个的通知事件,然后podworker就会处理这些事件。
它会去调用cri,然后获取当前节点pod对应的容器是不是在启动的状态。如果没有启动,那么他就会去启动这些容器进程,把这个应用拉起来,它就是通过cri的接口。
cri接口传统都是通过dockershim去做的,但是随着kubernetes架构不断升级,它废弃了docker-shim这条线,它决定不再支持比较臃肿的dokcer shim,而是通过remote container interface,比如通过containerd,或者cri来支持整个运行时。