1 前言
Lindorm是一个低成本高吞吐的多模数据库,目前,Lindorm是阿里内部数据体量最大,覆盖业务最广的数据库产品。超高的性能和低RT一直是Lindorm追求的目标,因此Lindorm也在不断地优化和迭代,争取在每个小点上都做到极致。这次,我们的优化的目标放到了Lindorm中的Bloom Filter上。

由于Bloom Filter只需要占用极小的空间,便可以给出”可能存在“和”肯定不存在“的存在性判断,因此可以提前过滤掉许多不必要的数据块,从而节省了大量的磁盘IO。在Lindorm中Get操作就是通过运用低成本高效率的Bloom Filter来过滤掉大量无效的数据块的,从而大幅度降低磁盘IO次数。
Bloom Filter存储在了Lindorm的底层文件LDFile中。在长期的生产观察中,我们发现,Bloom Filter的空间占用远大于其他meta数据。在默认配置的错误率下,基本上100MB数据(压缩后),就会产生1MB以上的BloomFilter,也就是BloomFilter会占掉1%的存储空间。对于磁盘存储空间来说,1%的消耗并不多,但是,由于BloomFilter做为Lindorm读链路上的关键链路,通常需要缓存在内存中才能获得更好地性能。内存资源对Lindorm来说是非常宝贵的资源,对于单机管理上TB数据的Lindorm节点来说,通常只有几GB到几十GB的内存来做缓存。按照通常的规律,上TB的数据会产生几十GB的Bloom Filter,这些Bloom Filter会把缓存占满,导致数据无法进入缓存,会严重影响用户请求的内存命中率。因此,优化Bloom Filter的大小,意味着可以减少内存占用,让缓存能够加载更多用户数据,从而优化Lindorm的读性能。
为了优化BloomFilter, Lindorm也做了不少尝试,比如引入SuRF,但我们发现,在空间占用率上,SuRF并不比BloomFilter有优势。因此,我们把目光转向了2021年的一篇论文《Ribbon filter: practically smaller than Bloom and Xor》。这篇论文提出了一种新的Ribbon Filter,据论文的结论,Ribbon Filter相对Bloom Filter可以节省30%的空间。这个对我们来说是一个非常诱人的结论,节省30%空间意味着可以释放30%的缓存空间,读请求的内存命中率会有很大一部分提升。
Ribbon Filter真的有论文中说的那么神奇吗?带来空间节省的同时,会带来副作用吗?本文将这一全新的Ribbon Filter给大家做一个介绍,然后我们把Ribbon Filter引入了Lindorm中,并测试了Ribbon Filter在实际生产中的真实表现。
2 基本原理
2.1 Bloom Filter
Bloom Filter是Bloom在1970年提出的一种概率数据结构[1],用来快速测试元素是否是集合的成员,存在一定的假阳性率(一般设置为0.01),不可能有假阴性率,即查询返回“可能存在”或者“一定不存在”。可以添加元素到集合中,但不能删除(有改进版本可以实现),添加的元素越多,假阳性率越大。对于给定的假阳性率e和元素数量n,Bloom Filter有一个最佳的空间大小,使得添加元素过程中,保证逐渐变大的假阳性率小于等于e。
Bloom Filter由一个长度为n的01数组array组成。首先会将array数组每个元素初始化设为0,对于集合A中的每个元素w,做k次哈希,每次哈希值都会对n取模得到一个索引,比如第i次哈希,索引
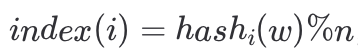
,将array数组中的对应位置置为1,最终array变成了一个部分元素为1的数组。对于待检测元素w同样会做k次哈希得到k个索引,如果数组中对应位置都为1则元素w可能存在集合A中,否者一定不存在。
2.2 Xor Filter
Ribbon Filter是基于Xor Filter做的,在介绍Ribbon Filter之前,得先了解Xor Filter。Xor Filter是Thomas Mueller Graf和Daniel Lemire在2020年提出的[2],也是用来检测一个元素是不是集合中的一个成员,相比Bloom Filter,Xor Filter核心差异主要是如下:
- Xor Filter有固定的三个哈希函数,而Bloom Filter哈希函数由假阳性率确定;
- Xor Filter采用XOR方式按slot匹配,Bloom Filter使用AND方式进行按位匹配;
- Xor Filter由一个二维bit数组组成,Bloom Filter是一个一维bit数组;
- Xor Filter相比Bloom Filter最高能节省20%的空间。
输入的元素经过多个哈希函数生成的哈希值不会像Bloom Filter一样映射到一个bit位,而是映射到一个固定长度的slot,一个slot有多个bit位,且每个slot的bit位数相同。对于待检测元素w,会经过k个哈希函数生成k个哈希值分别映射到对应slot上,然后对所有的k个slot中的元素进行异或运算得到结果r,元素w还会经过另外一个独立的哈希函数生成指纹fingerprint(w),和r作对比,如果相同则元素w可能存在集合A中,否者一定不存在。
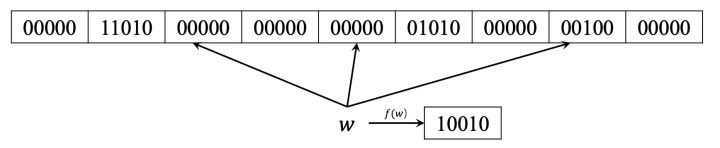
接下来介绍Xor Filter的构造原理
开始先介绍几个关键变量:
- B存放着的r-bit的Xor Filter
- n是参与构建Xor Filter的集合A元素数量
- k是哈希函数的个数(固定值3)
- m是slot的个数
初始时令r=5,n=3,k=3,m=9,B所有元素为0,元素x,y,z分别经过3个哈希函数映射到3个slot上,每一个元素经过一个独立的哈希函数生成指纹f(x)=11010,f(y)=10000,f(z)=01110,
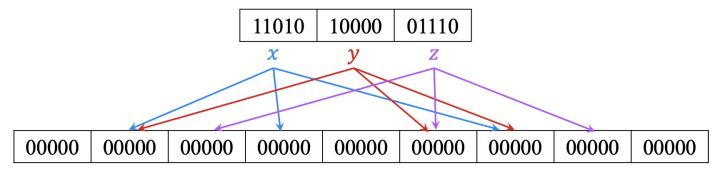
我们可以看到slot7被元素z独享,所以slot7能够唯一标识z,将slot7打上标记z,并去除元素z的映射
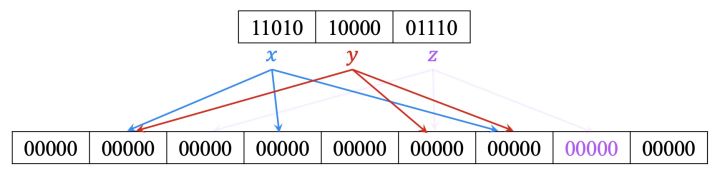
此时slot5可以唯一标识元素y,将slot5打上标记y,并去除元素y的映射
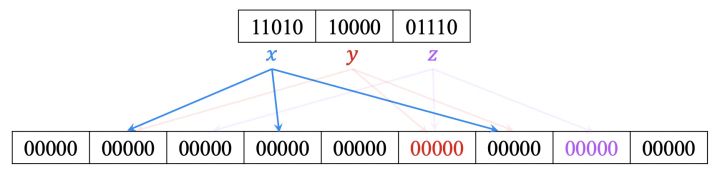
现在只剩下最后一个元素x,f(x)可以放在slot1、slot3、slot6任一位置,这里选择slot1,slot3和slot6置为的5-bit 0,将f(x) xor slot2 xor slot3的结果放在slot1中,11010^00000^00000=11010,并回填其它带有标记的slot,和前面操作一样y元素slot5=f(y) xor slot1 xor slot6=10000^11010^00000=01010,z元素slot7=f(z) xor slot2 xor slot5=01110^00000^01010=00100
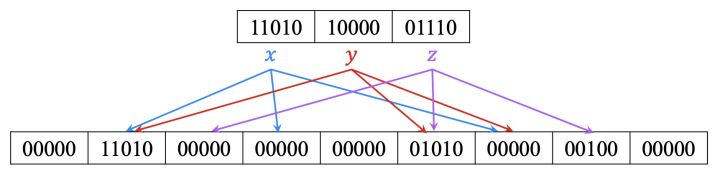
最终得到了构建好的Xor Filter,测试的时候,待检测的元素w经过3个哈希函数得到对应的slot索引h1(w),h2(w),h3(w),以及经过另一个哈希函数得到指纹f(w),将指纹与B(h1(w)) xor B(h2(w)) xor B(h3(w))进行比较。如若相等,则表示元素w可能存在,否者一定不存在。
2.3 Ribbon Filter
Ribbon Filter是Peter C. Dillinger和Stefan Walzer在2021年提出的[3],Ribbon Filter主体是Xor Filter的实现,在其基础上构建可以高效运算的矩阵,从而利用矩阵本身的高效运算来解决Xor Filter构建过程中的重复操作,相比Bloom Filter,Ribbon Filter会消耗更多的CPU,Ribbon Filter的核心优势在于节省空间,所以会针对Xor Filter的二维数组的求解过程做计算优化,Ribbon Filter会将二维数组的求解过程转化成解线性方程组Ax=b,并应用了基于行列式的高斯消元法,线性代数中求解线程方程组时会用到行列式运算,高斯消元法就是在求解线程方程组的过程中,将一个行列式转化成上三角或者下三角矩阵。
相比Xor Filter, Ribbon Filter主要差异如下:
- Ribbon Filter哈希映射到数组连续的一片索引,而Xor Filter仅有的3个哈希函数每个都随机映射;
- Ribbon Filter构建过程使用高斯消元法,Xor Filter使用Peeling算法;
- Ribbon Filter二维bit数组使用列式存储,Xor Filter是行式存储;
- Ribbon Filter相比Bloom Filter最高能节省30%的空间。
让我们看一下上节Xor Filter的元素w的查询测试过程,哈希映射用h(x)表示,
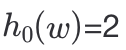
,
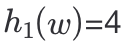
,
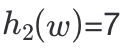
,即

= B[2] xor B[4] xor B[7] ,那是不是可以表示成

,其中

是元素w哈希映射的特征向量,第2,4,7位为1(索引从0算起),对应了
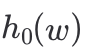
,
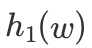
,
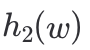
的值,Z是二维bit数组B的矩阵形式,
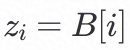
,同时注意
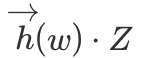
计算过程中加法运算要变成异或XOR运算。可以计算出query(w)=00100,
=

上节Xor Filter的构建过程可以用线性方程组表示成:

,二维bit数组B可以通过求解该方程组得到,方程组的系数矩阵为

,第1行对应了元素x哈希映射的特征向量,第2行y,第3行z。
除了引入矩阵运算,Ribbon Filter还对二维bit数组的存储结构进行了调整,在Xor Filter中每个slot的r-bit连续存储,且保证第i个slot中所有的bit都在第i+1个slot的r-bit前面,这种称为行式存储结构,而Ribbon Filter使用列式存储,保证每w个slot的第j个bit都在第j+1个bit前面,w是Ribbon Filter哈希映射到的连续索引的宽度,一般w>>r,如果使用行式存储,查询的时候需要从内存读取所有的w个r-bit,然后做异或计算得到结果并与指纹对比,现在使用列式存储,可以先读取第1个w-bit,做一下异或计算并将结果与指纹的第1个bit比较,如果不同则表示查询的元素不在集合内,直接返回False,否者继续读取接下来的w-bit并重复之前的过程。列式存储带来的好处有:
- 查询过程不用读取所有的bit,减少查询时间;
- 对空间更友好,访问w个连续内存空间变成了访问r个连续内存空间。一般w=64,r=7。
2.4 性能对比
依据Ribbon Filter论文的性能对比结论,我们提取出本文关心的Bloom,Xor,Ribbon三者的性能对比。这里的key用的是long数据类型,Construct包括添加key和求解方程。
| Filter | false positive rate | space overhead | ns/key,n=10^6,Construct | ns/key,n=10^6,Query |
| BlockedBloom | 1% | 52.0% | 11 | 14 |
| Xor | 1/2^8≈0.39% | 23.0% | 148 | 15 |
| Ribbon | 1/2^7≈0.78% | 10.1% | 83 | 39 |
从表中可以看出:
- Ribbon构建时间是BlockedBloom的7.5倍;
- Ribbon查询时间是BlockedBloom的2.8倍;
- Ribbon空间开销是BlockedBloom的72%((1+10.1%)/(1+52.0%)),节省了28%。
通过文章中的对比,我们发现Ribbon Filter虽然比Bloom Filter节省了28%的空间,但构建时间和查询时间都有了一些明显的上升。初看是一个时间换空间的做法,不过,论文中选用的Bloom Filter是BlockedBloom,这是2019年提出的一个基于Bloom Filter的优化版本[4],本身性能就已经比较好,而且测试的Filter hash function都是针对long值的,而Lindorm中的Bloom Filter是针对byte数组做hash的,性能表现可能不完全一致。因此,Ribbon Filter是否能在任何场景下都能Lindorm带来性能提升,需要我们把Ribbon Filter引入Lindorm中,在生产环境做一些测试。
3. 应用Ribbon Filter
3.1 核心逻辑的实现
我们参考论文中的Ribbon Filter使用Java进行了实现并集成到Lindorm中。论文中有一种空间开销更小的优化版本的Ribbon Filter,但是它不能保证构造成功,需要重试,这在Lindorm中是不能接受的,Lindorm中构建过滤器是不能失败的,否则会导致Flush或者Compaction失败。所以我们最后选用了宽度w=64的Homogeneous Ribbon Filter。
最终的实现有一些工程上的取舍,因此与论文还是存在一些差异:
- 论文中实现的Ribbon Filter使用的key类型是long型,在Lindorm中每个key是一个byte数组;
- 论文中实现的Ribbon Filter构建的时候直接提供一个key数组,但是在Lindorm中key是流式的一个个来,并且数量未知;
- 论文中实现的Ribbon Filter构建提供key数组的大小n是已知的,可以通过公式
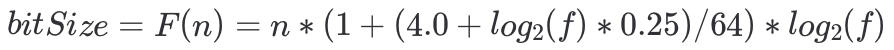
(错误率f已知)得到Ribbon Filter的空间大小,但是Lindorm中只提供空间大小bitSize和错误率f,key数量n未知,需要反向求出n;
- 论文中实现的Ribbon Filter输出的是一个long型数组,但是在Lindorm中得是一个ByteBuffer才能统一存到文件系统中;
- 论文中实现的Ribbon Filter查询过程可以使用类中全部中间变量,但是在Lindorm中查询函数是静态的,只有少部分meta信息和存有Ribbon Filter的数据块可以使用。
Ribbon Filter的构建:
Bloom Filter构建过程只需要添加元素即可,添加完了就构建完了,但是Ribbon Filter构建过程还包括求解方程阶段,这个阶段是最耗时的,这个阶段放在哪个地方在什么时间由谁调用来执行,会不会影响性能是一个大大的问题。目前是放在Ribbon Filter的写过程中执行,写之前会先求解方程,性能影响目前还没发现。
Ribbon Filter的查询:
Bloom只需要少量的meta信息然后按需加载需要的Bloom Block,就可以完成查询过程,meta信息有VERSION,byteSize,hashCount,hashType,keyCount。Ribbon不需要hashCount字段,其它都要,除此之外还需要numStarts(哈希映射到的区间上限),upperNumColumns(指纹位数的向上取整),upperStartBlock(指示floor(r)位的slot与ceil(r)的slot的分界),后续引入失败重试机制还得有哈希种子seed字段。
为了不改变meta信息的长度,只将hashCount变成了slotCount(slot的数量),都是int类型,numStarts = slotCount-63,upperNumColumns = (ribbonBitSize + slotCount - 1) / slotCount,upperStartBlock = upperNumColumns * (slotCount >> 6) - (ribbonBitSize >> 6),这样就完美了,从物理存储层是不太能看出Bloom meta block和Ribbon meta block的区别的,既没增字段也没减字段也没修改字段类型。
3.2 初步测试
本次benchmark对比的是在Lindorm中应用的Bloom Filter和Ribbon Filter。这里的key用的是byte数组类型,key length是byte数组大小;错误率都为1%,hash类型都是murmur,Construct包括添加key和求解方程。
1. Construct,构建filter,单位是ns/key, n=10^6,下同。
| key length | Ribbon,ns/key, n=10^6 | Bloom,ns/key, n=10^6 | ratio (Ribbon:Bloom) |
| 10 | 109.926 | 136.012 | 80.82% |
| 25 | 143.178 | 164.247 | 87.17% |
| 50 | 196.083 | 227.898 | 86.04% |
| 250 | 334.312 | 467.884 | 71.45% |
| 2000 | 1375.165 | 2006.235 | 68.54% |
可以看到,在Lindorm中,随着Key长度的增长,构建Ribbon Filter的速度反而会更快
2. Query,查询
| key length | Ribbon,ns/key, n=10^6 | Bloom,ns/key, n=10^6 | ratio (Ribbon:Bloom) |
| 10 | 20.827 | 22.135 | 94.09% |
| 25 | 38.285 | 44.764 | 85.53% |
| 50 | 51.730 | 70.075 | 73.82% |
| 250 | 147.951 | 256.863 | 57.60% |
| 2000 | 1125.760 | 2230.200 | 50.48% |
可以看到,在Lindorm中,随着Key长度的增长,查询Ribbon Filter的速度反而更快。
3. space load,空间负载跟key length无关
| key length | Ribbon,bit/key, n=10^6 | Bloom,bit/key, n=10^6 | ratio (Ribbon:Bloom) |
| * | 7.232 | 9.585 | 75.45% |
从初步测试的结果来看,似乎测试结论比论文中更好,无论查询速度,构建速度,Ribbon Filter都比Bloom Filter更优。我们分析,这是由于Lindorm中原来使用的BloomFilter是一个没有优化过的原始版本,而且Bloom Filter查询时需要多次执行hash函数,而hash bytes的消耗比论文中hash 数字的消耗要大的多,因此Ribbon Filter的查询性能并没有论文中说的那么差,反而随着key的长度变长,查询的性能要强于原有的BloomFilter实现并且差距越来越大。
构建Filter时的结论也类似,随着key长度的上升,RibbonFilter的构建速度更快,完全优于Bloom Filter。但在生产过程中,构建过滤器只占Lindorm生产LDFile全过程中的很小一部分,基本上不会对Lindorm文件的生成速度造成影响。在空间上,相同的错误率下,Ribbon Filter确实能比Bloom Filter节省25%的空间。
基于以上测试结论,我们觉得使用Ribbon Filter替代Bloom Filter,无论从哪个角度上来说,都是一个不错的选择。
3.3 生产测试
我们把Ribbon Filter集成在Lindorm宽表引擎中,进行了全链路的压测,压测机器的配置为4核8GB,使用ESSD存储,压测工具用的是ycsb
本次测试的是批量读的吞吐量对比测试和延迟对比测试,以及读取过程中的缓存命中率对比测试,以及major compaction性能对比测试。读取测试根据rowKey的字节数的不同分为四个场景:10bytes,25bytes,50bytes,300bytes。
测试表单节点分布,load10亿行数据,每行数据一个列族,共5列,每列value 20bytes,每行数据大概0.1kb,表大小100G左右,批量读一次20行。
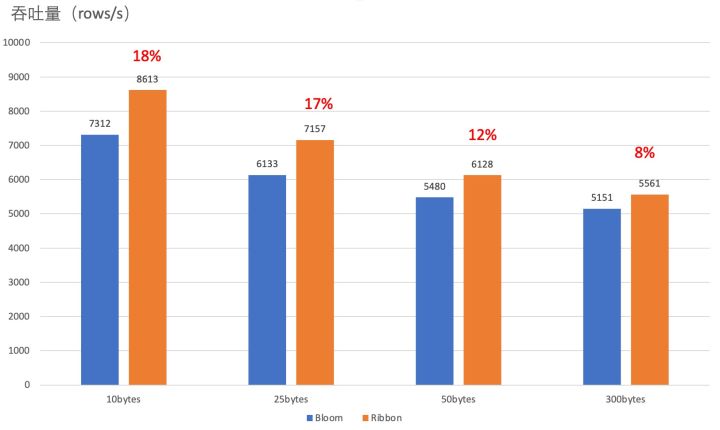
批量读吞吐量对比
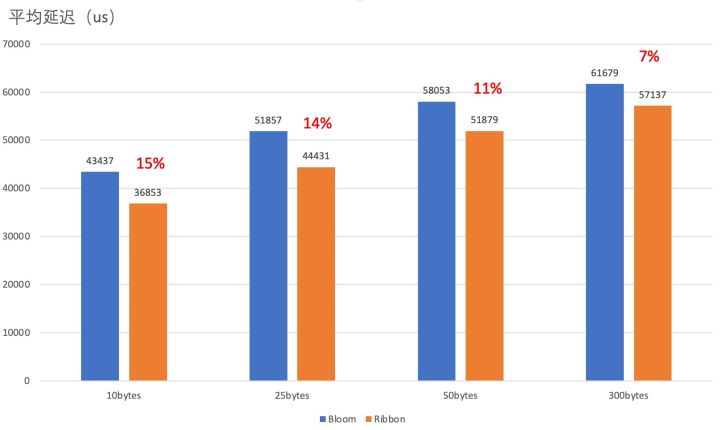
批量读平均延迟对比
读取过程中的缓存命中率对比

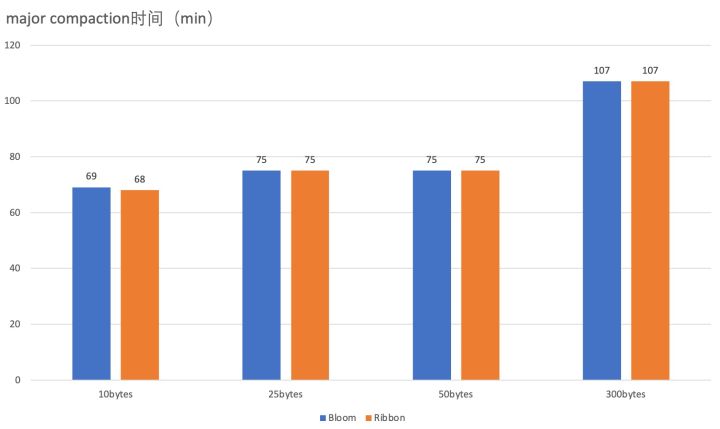
单节点major compaction性能对比(cpu打满)
Filter的meta信息对比
| 指标 | Bloom Filter | Ribbon Filter |
| Size(bytes) | 11993088 | 9043968 |
| No of Keys | 9999833 | 9999833 |
| Max Keys | 10001499 | 10005000 |
| Percentage filled | 100% | 100% |
| Number of chunks | 92 | 69 |
生产的测试证实了我们在3.2节理论分析的结果。引入Ribbon Filter后,读的吞吐最高有了18%的提升。读RT有了最高15%的下降。吞吐的提升和RT的下降主要来源于使用Ribbon Filter后,过滤器空间的减少和内存命中率的提升。并且在不同的key大小下,Ribbon Filter均有好过Bloom Filter的表现。
在Compaction的对比测试中,大家也可以看到,使用Ribbon Filter与否对Compaction的速度基本没有影响。
4 总结
本文研究了一种新的过滤器Ribbon Filter。我们根据论文的思路在Lindorm中进行了实现。经过测试,我们发现Ribbon Filter能够节省25%的过滤器空间占用,从而在各种条件下提升Lindorm的读性能。Lindorm将在下一个版本中集成Ribbon Filter,带给用户极致地性能体验。
另外,为了保证Ribbon Filter构建不失败,我们选用了一种空间占用相对较多的实现,我们将在Ribbon Filter的基础上继续做了一些探索,保证构建不失败重试的前提下,进一步节省过滤器的空间。
参考文献
[1]Burton H. Bloom. 1970. Space/Time Trade-offs in Hash Coding with Allowable Errors. Commun. ACM 13, 7 (1970), 422–426.
[2]Thomas Mueller Graf and Daniel Lemire. 2020. Xor Filters: Faster and Smaller Than Bloom and Cuckoo Filters. ACM J. Exp. Algorithmics 25 (2020), 1–16. https://doi.org/10.1145/3376122
[3]Dillinger, Peter C. and Stefan Walzer. “Ribbon filter: practically smaller than Bloom and Xor.” *ArXiv* abs/2103.02515 (2021).
[4]Harald Lang, Thomas Neumann, Alfons Kemper, and Peter A. Boncz. 2019. Performance-Optimal Filtering: Bloom overtakes Cuckoo at High-Throughput. Proc. VLDB Endow. 12, 5 (2019), 502–515.
作者:箫苏 朝戈 正研
本文为阿里云原创内容,未经允许不得转载。