因子挖掘是量化交易的基础。除传统的基本面因子外,从中高频行情数据中挖掘有价值的因子,并进一步建模和回测以构建交易系统,是一个量化团队的必经之路。
近年来,DolphinDB 逐步成为国内外大量基金(私募和公募)与券商自营团队进行因子挖掘的利器。


在量化金融这样一个高度市场化、多方机构高度博弈的领域,因子的有效时间会随着博弈程度的加剧而缩短,如何使用更加高效的工具和流程,更快地找到新的有效因子,是每一个交易团队必须面对的问题。


基于大量用户的反馈,我们撰写了一份因子挖掘最佳实践白皮书,并将在5月19日(周四)晚7点于线上公开发布。届时,DolphinDB CEO 周小华博士将为大家详细讲解如何用 DolphinDB 高效快速地实现因子挖掘。
直播内容概览
01 投研阶段的因子计算
在投研阶段往往需要将每一种因子的计算封装成自定义函数,以便进行团队的代码管理和框架统一。考虑到因子类型和使用者习惯的不同,DolphinDB 为大家提供了面板和 SQL 两种数据计算模式。
在面对分钟级、日级、快照和逐笔等不同频率的数据时,如何灵活高效地进行因子计算?直播中,我们将为大家展开讲解。
02 生产环境的流式因子计算
DolphinDB 通过以流计算引擎和流数据表为核心的流计算框架,实现了批流一体功能,即在投研阶段封装好的基于批量数据开发的因子函数,可以无缝投入交易和投资等生产程序中。
流计算的核心是流式增量计算。金融领域的许多原始数据和指标,在时间上都具有延续关系,因此在计算过程中如何降低实时计算的延时、提高因子计算便捷性尤为重要。
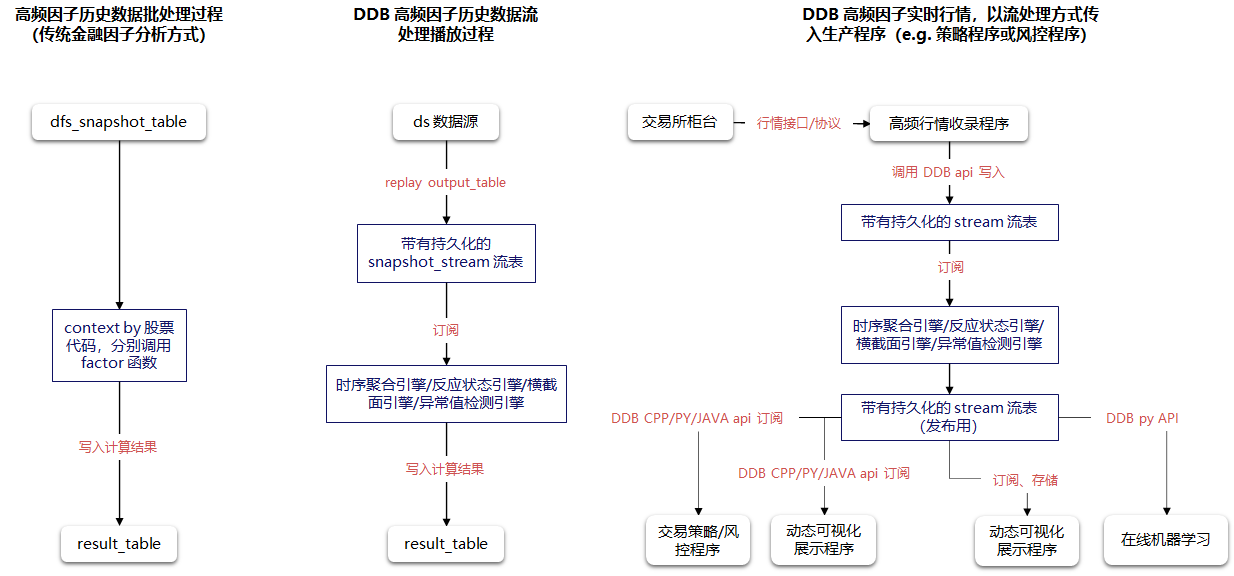
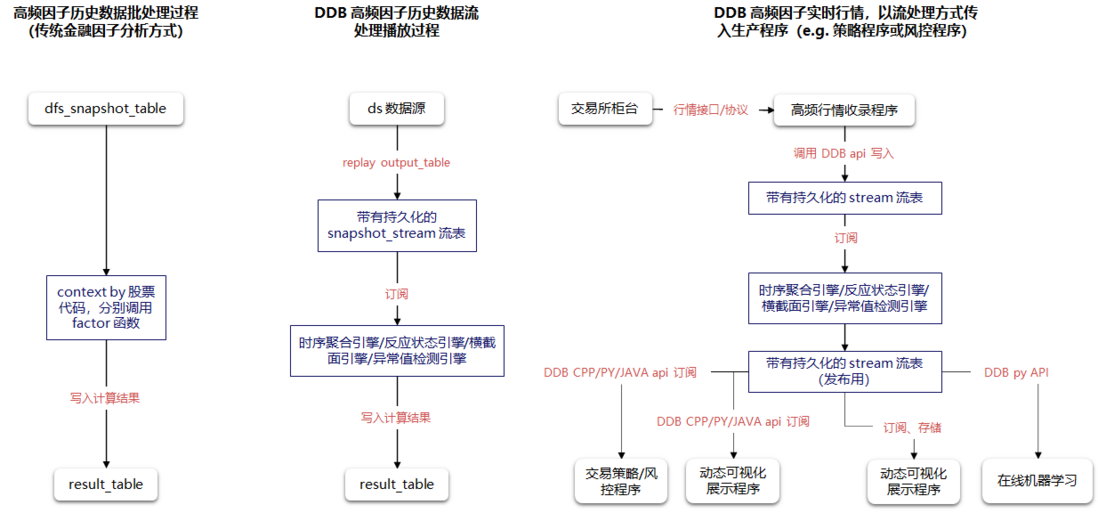
我们将通过主买成交量占比变化、大小单资金流以及更多复杂因子的计算案例,为大家展示 DolphinDB 是如何通过流计算引擎实现因子在生产环境中的增量计算的。此外,我们还将为大家讲解另一种更为简洁的批流一体实现方案,即如何通过数据回放实时计算因子值;以及如何与交易系统对接。
03 因子存储和查询
因子的保存对后续投研分析有重要意义,不同的存储方式会影响实际使用的存储空间、写入和查询速度。
面对批计算、点查询等各种不同的使用场景,应该选择何种存储引擎?是以单值纵表还是多值宽表的方式进行存储?以及海量数据如何分区?
我们将在直播中为大家详细阐述各种存储方式多维度的对比分析。
04 因子建模和回测
业务流程中,我们需要用计算出的因子信号设计投资策略,并将投资策略代入历史数据进行交易模拟,检测收益率。
直播中,我们将为大家演示如何用 DolphinDB 进行因子的相关性分析和多因子建模,并演示向量化因子回测的案例。
05 因子计算的工程化
在实际量化投研过程,研究员要聚焦策略因子研发,而因子计算框架的开发维护通常是 IT 部门人员来负责,因此进行工程化管理可以有效加强协作、提高生产效率。
我们将从代码管理、并行计算、内存管理、权限管理和任务管理方面向大家介绍 DolphinDB 的因子计算工程化管理。
直播预告
活动时间:5月19日 19:00
活动形式:本次活动将以线上直播的形式举行
报名入口:从计算、建模到回测,因子挖掘的最佳实践