目录
文章部分知识来源千峰教育讲解的zookeeper当中!
1.什么是ZAB协议
zookeeper作为⾮常重要的分布式协调组件,需要进⾏集群部署,集群中会以⼀主多从的形式进⾏部署。zookeeper为了保证数据的⼀致性,使⽤了ZAB(Zookeeper Atomic Broadcast)协议,这个协议解决了Zookeeper的崩溃恢复和主从数据同步的问题。
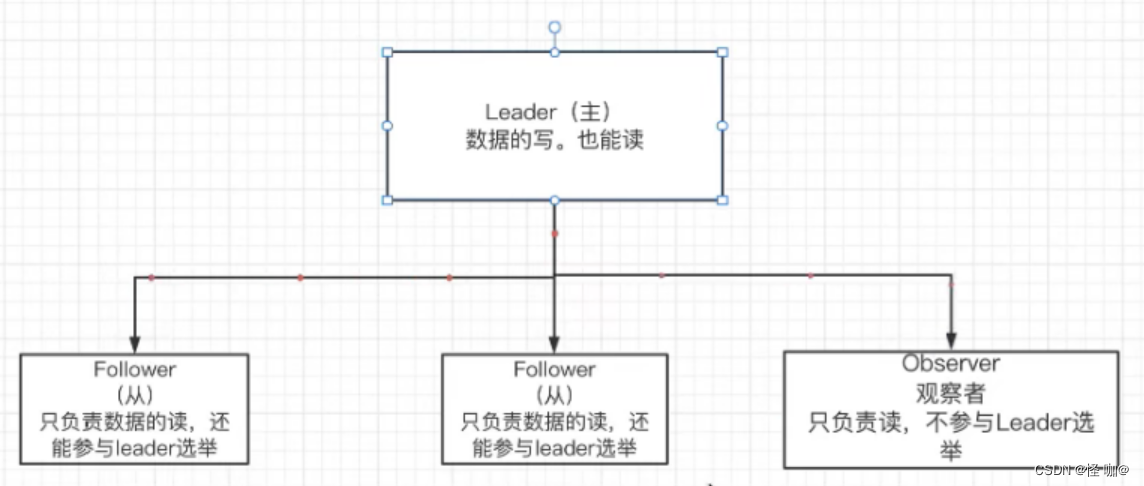
下图就是zk集群的结构,主节点主要负责节点的写,也能负责读,其他从节点只有读的权限。虽然从节点不负责写数据,但是他永远会在自己的内存当中保持一份和主节点一模一样的数据!假如主节点更新了数据,他会立马将数据同步到子节点。同步子节点的目的就是要防备主节点挂掉的准备,然后可以无缝切换主节点,也就是上面所说的崩溃恢复。
2.ZAB协议定义的四种节点状态
- Looking :选举状态。
- Following :Follower 节点(从节点)所处的状态。
- Leading :Leader 节点(主节点)所处状态。
- Observing:观察者节点所处的状态
3.集群上线时的Leader选举过程
Linux搭建Zookeeper伪集群详解:https://blog.csdn.net/weixin_43888891/article/details/125474995
选举为主节点的条件:
以上面四台服务节点为例,其中有一台状态为Observing是不参与选举的,也就是三台需要参与选举。
当超过一半票数的节点就能成为主节点,3台节点进行选举,也就意味着只要任意一个节点有两票就可以成为主节点。
zk怎么知道有几个节点的?
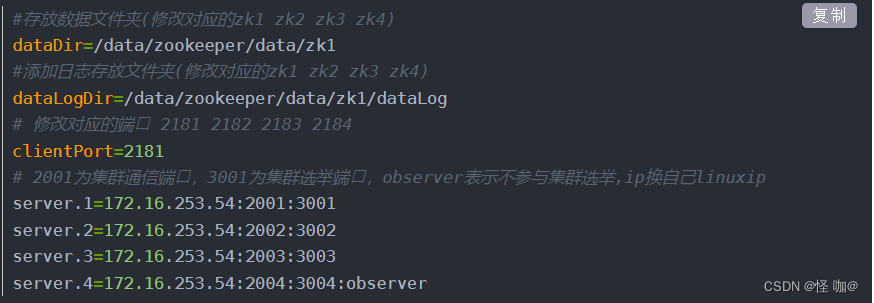
既然要求票数过半,那他怎么知道有几台节点的呢?搭建过集群的应该知道,搭建集群的时候需要在每个节点的zoo.cfg配置文件配置每个服务器的地址,这样不管哪个服务节点,都能知道当前集群一共有几台服务节点!
以下是集群下每个节点都需要配置的zoo.cfg文件:
3台节点参与竞争,那实际上几台参与选票呢?
实际上也就两台参与投票,因为就算有3台服务节点,他启动也是有先后顺序的,只有前两个启动的服务节点能够参与投票,记住这里是参与投票,而并不是参与竞争,实际上3台都有竞争机会,但是票数过半就成主节点了,也就是两票就确定主节点了,所以前两台参与投票即可,后一台既不参与投票也不可能成为主节点!
针对于这一点我亲自做了试验,当三台节点的时候,启动两台的时候已经触发选举机制,当第三台还没启动的时候,已经选好主节点了。第三台启动后,要想再次触发选举机制,除非有一台服务挂掉!
投票的依据:
会根据myid和zXid大小进行投票选举,选择出一个主节点!
- myid:就是创建的myid文件当中的值
- zXid:事务id,就是只要在这个服务下做的增删改操作,查不算,每操作一次,那么zxid就会+1
投票流程详解:
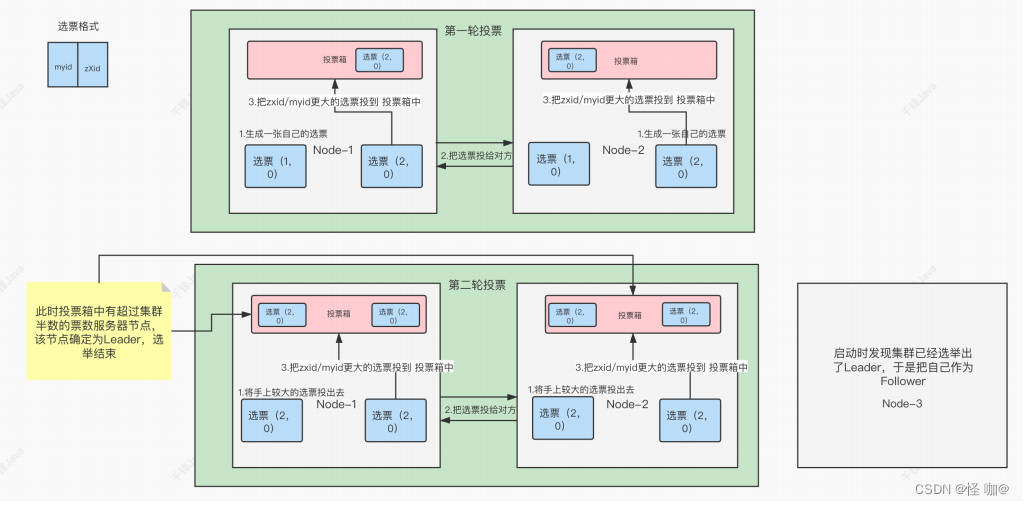
通过上面了解到,三台参与选举,由于票数过半就可以成为主节点,所以在第三台服务器还没启动的时候主节点就已经诞生了。而两个节点在进行投票的时候一共需要进行两轮投票:
第一轮投票:
- 两个节点各自生成各自的选票,选票就是myid和zXid
- 把票都互相交给对方(说白了就是我把我的情况告诉你,你把你的情况告诉我,咱俩公平点,选出一个能胜任的来当老大)
- 两个节点各自选出zxid/myid最大的,放到投票箱当中
第二轮投票:
- 把手上较大票交换给对方
- 这时候再进行投票,选择zxid/myid最大的 投到箱子中
通过两轮的选票后,2号节点成功上任主节点!之所以要通过两轮就是为了确保选举的可靠性!
4.崩溃恢复时的Leader选举
Leader建⽴完后,Leader周期性地不断向Follower发送⼼跳(ping命令,没有内容的socket)。当Leader崩溃后,Follower发现socket通道已关闭,于是Follower开始进⼊到Looking状态,重新回到上⼀节中的Leader选举过程,此时集群不能对外提供服务。

5.主从服务器之间的数据同步
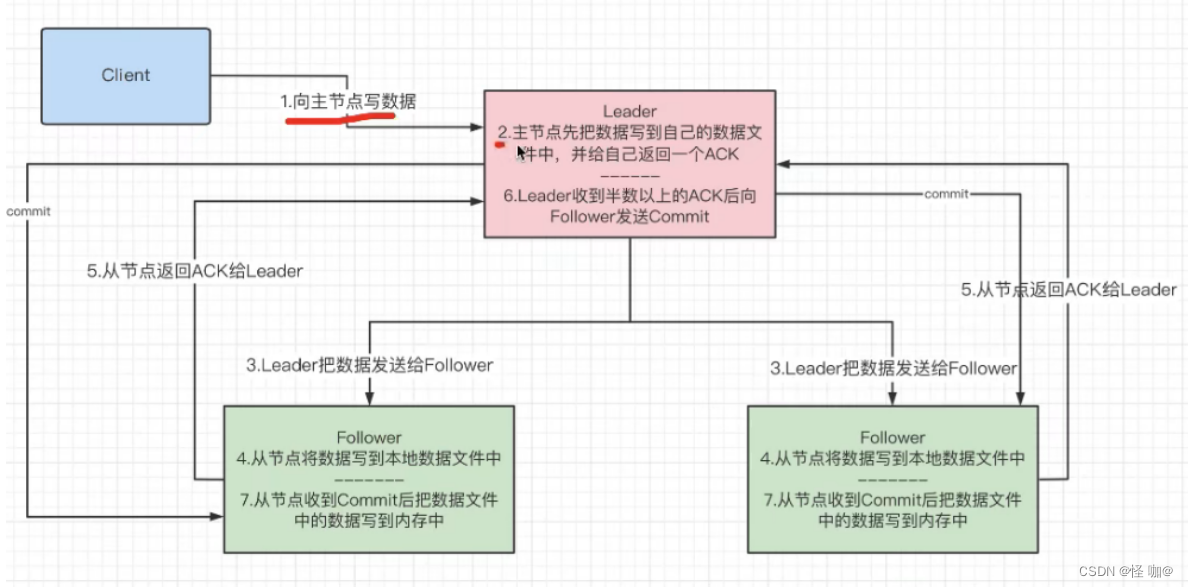
- 向zk写数据的时候
- 先写到主节点的持久化数据文件当中,写完的时候返回一个ACK。
- 主节点收到ACK后,开始将数据发送给从节点。
- 从节点收到数据后开始写到本地数据文件当中。
- 从节点持久化完数据之后,返回ACK给主节点(通知主节点写完了)。
- 主节点在收到半数以后的ACK后向从节点发送提交。
- 这时候主节点和从节点再把数据同步到内存当中。
为什么要进行选举,而不是随便拿一个节点当主节点!
之所以选举,就是为了选择出一个数据比较新的来当主节点,一般事务id比较大,那自然他的数据要比较新。而myid无非就是开放出来的一种人为干预选举的一种方式!也就是我想让哪台当主机,我可以设置myid特别大就可以了。
zk会数据同步,难道还会出现事务id不一样的情况?
在第六步的时候,只要收到半数以上就开始同步内存数据,也就意味着假如有服务器网络延迟并没有发生ACK,但是也超过了半数,超过半数就不等他了,直接数据同步内存,而当别的服务器都同步完后,这时候网络延迟的那台服务器又好了,这时他的事务id就会和其他节点数据不一致!
6.CAP 定理
2000 年 7 ⽉,加州⼤学伯克利分校的 Eric Brewer 教授在 ACM PODC 会议上提出 CAP 猜想。2年后,麻省理⼯学院的 Seth Gilbert 和 Nancy Lynch 从理论上证明了 CAP。之后,CAP 理论正式成为分布式计算领域的公认定理。
CAP 理论为:⼀个分布式系统最多只能同时满⾜⼀致性(Consistency)、可⽤性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
- ⼀致性:更新操作成功并返回客户端完成后,所有节点在同⼀时间的数据完全⼀致。
- 可⽤性:可⽤性指“Reads and writes always succeed”,即服务⼀直可⽤,⽽且是正常响应时间(指的是一切访问正常并且打开的值是自己预期的值,这叫可用)。
- 分区容错性:即分布式系统在遇到某节点或⽹络分区故障的时候,仍然能够对外提供满⾜⼀致性或可⽤性的服务。——避免单点故障,就要进⾏冗余部署,冗余部署相当于是服务的分区,这样的分区就具备了容错性。
Zookeeper追求的是CAP当中的CP,虽然追求的是一致性,但是在数据同步时,实际上并不是强⼀致性,⽽是顺序⼀致性(事务id的单调递增)。这一点从上面的主从服务器之间的数据同步就可以看出!
这里要明白一点,假如每个节点的事务id是一致的,那他们数据一定是同步的!
7.CAP 权衡
通过 CAP 理论,我们知道⽆法同时满⾜⼀致性、可⽤性和分区容错性这三个特性,那要舍弃哪个呢?
对于多数⼤型互联⽹应⽤的场景,主机众多、部署分散,⽽且现在的集群规模越来越⼤,所以节点故障、⽹络故障是常态,⽽且要保证服务可⽤性达到 99.9999,即保证 P 和 A,舍弃C(退⽽求其次保证最终⼀致性)。虽然某些地⽅会影响客户体验,但没达到造成⽤户流程的严重程度。
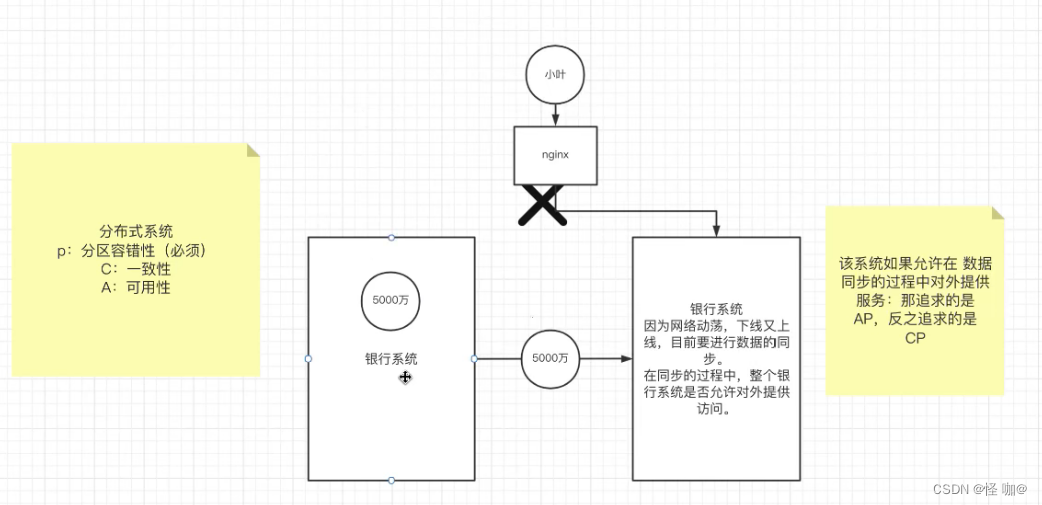
对于涉及到钱财这样不能有⼀丝让步的场景,C 必须保证。⽹络发⽣故障宁可停⽌服务,这是保证 CA,舍弃 P。貌似这⼏年国内银⾏业发⽣了不下 10 起事故,但影响⾯不⼤,报到也不多,⼴⼤群众知道的少。
还有⼀种是保证 CP,舍弃 A。例如⽹络故障是只读不写。
孰优孰略,没有定论,只能根据场景定夺,适合的才是最好的。
8.BASE 理论
eBay 的架构师 Dan Pritchett 源于对⼤规模分布式系统的实践总结,在 ACM 上发表⽂章提出BASE 理论,BASE 理论是对 CAP 理论的延伸,核⼼思想是即使⽆法做到强⼀致性(Strong Consistency,CAP 的⼀致性就是强⼀致性),但应⽤可以采⽤适合的⽅式达到最终⼀致性(Eventual Consitency)。
- 基本可⽤(Basically Available):基本可⽤是指分布式系统在出现故障的时候,
允许损失部分可⽤性,即保证核⼼可⽤。电商⼤促时,为了应对访问量激增,部分⽤户可能会被引导到降级⻚⾯,服务层也可能只提供降级服务。这就是损失部分可⽤性的体现。 - 软状态(Soft State):软状态是指允许系统存在中间状态,⽽该中间状态不会影响系统整体可⽤性。分布式存储中⼀般⼀份数据⾄少会有三个副本,
允许不同节点间副本同步的延时就是软状态的体现。mysql replication 的异步复制也是⼀种体现。 - 最终⼀致性(Eventual Consistency):最终⼀致性是指系统中的所有数据副本经过⼀定时间后,
最终能够达到⼀致的状态。弱⼀致性和强⼀致性相反,最终⼀致性是弱⼀致性的⼀种特殊情况。
9.集群节点数量最好奇数
通过以上了解到,我们假如是3台节点,只要有两台参加投票就能得出主节点。那也就是3台挂掉任意一台,仍然不影响使用,因为我还能选出主节点,也就是33.33%的容错率。
假如是偶数4台的话,那么票数过半需要三票的支持。那也就是4台的话需要有3台进行参与投票,同样也是只允许挂掉1台服务,但是他是4台服务,那么他的容错率就占比25%。
假如是奇数5台的话,那么票数过半同样也是需要三票的支持。那也就是意味着5台挂掉两台之后仍然可以使用,那么他的容错率就占比40%。
由此得出奇数在容错率上要比偶数容错率好。
10.Zookeeper中的NIO与BIO的应⽤
NIO
- ⽤于被客户端连接的2181端⼝,使⽤的是NIO模式与客户端建⽴连接
- 客户端开启Watch时,也使⽤NIO,等待Zookeeper服务器的回调
BIO
- 集群在选举时,多个节点之间的投票通信端⼝,使⽤BIO进⾏通信。