点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
转载自:腾讯优图实验室
近日,欧洲计算机视觉国际会议ECCV 2022(European Conference on Computer Vision)发布了论文录用结果。本届ECCV 2022论文总投稿数超过8170篇,其中1629篇论文中选,录用率不足20%。
ECCV(European Conference on Computer Vision)是国际顶尖的计算机视觉会议之一,每两年举行一次。随着人工智能的发展,计算机视觉的研究深入和应用迅速发展,每次ECCV的举行都会吸引大量的论文投稿,而今年ECCV 2022的投稿量更是接近ECCV 2020的两倍,创下历史新高。今年,腾讯优图实验室共有29篇论文入选,内容涵盖人脸安全、图像分割、目标检测、掌纹识别等多个研究方向,展示了腾讯在计算机视觉领域的科研及创新实力。
以下为腾讯优图实验室入选论文概览:
01
基于熵驱动采样和训练的条件扩散生成算法
Entropy-driven Sampling
and Training Scheme
for Conditional Diffusion Generation
*本文由腾讯优图实验室和浙江大学共同完成
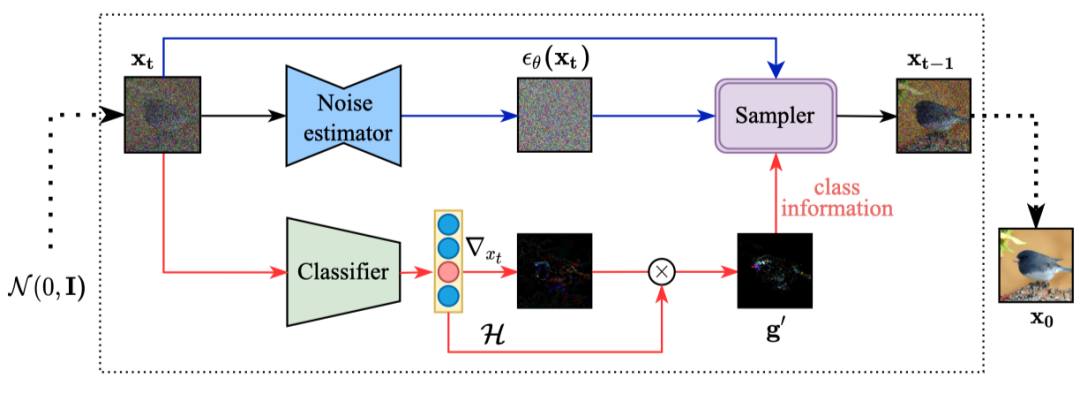
去噪扩散模型(DDPM)能够进行从先验高斯噪声到真实数据的条件图像生成,通过引入一个额外训练的噪声敏感的分类器,在去噪过程的每一个时间步提供条件梯度的指导。
由于分类器很容易识别出未生成完全的、仅有高层结构语义信息的图像中的条件类别,因此蕴含条件信息的梯度指导往往过早消失,使得条件生成过程坍塌到无条件的过程。为了解决这个问题,本文从训练和采样的视角提出了简单而有效的方法。
在采样过程中,我们引入分类器预测分布的信息熵当做指导消失程度的一种度量,提出了熵相关的梯度放缩方法,来自适应地恢复条件语义指导。在分类器的训练阶段,我们提出熵相关的优化目标,来减轻分类器对于噪声数据的过渡自信预测。
针对数据集ImaegNet256,我们提出的方法在预训练的条件和无条件的DDPM模型上,分别获得10.89% 和43.5% 的FID性能增益。
02
长尾分布下的类增量学习
Long-Tailed Class Incremental Learning
*本文由腾讯优图实验室和南开大学共同完成
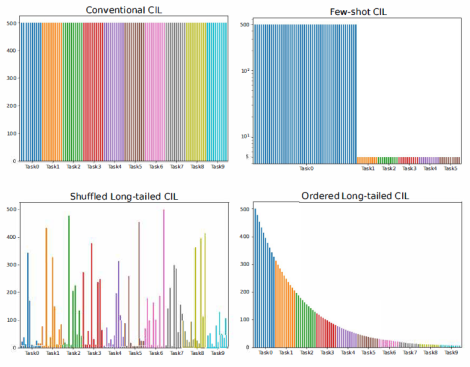
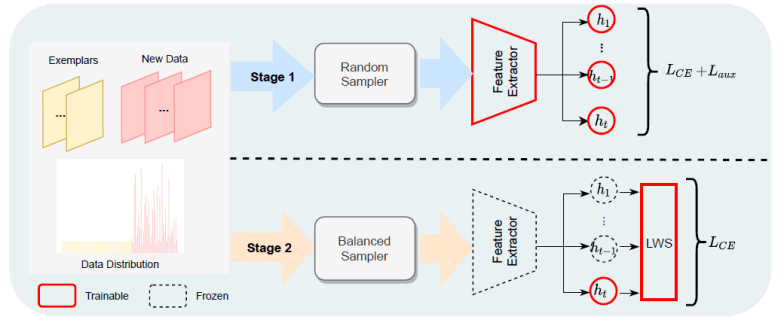
目前,大部分类增量学习的研究都集中在数据量平衡,即每个任务当中每个类别的数据量都是固定的情况下的增量学习。这种场景对实际情况进行了很大程度的简化,在实际的生活场景当中,我们可能面对的各个任务的类别数量是不固定的,同时每个类别的样本数量也是不固定的。为了模拟实际情况,我们提出了一种更接近于实际情况的类增量学习场景,在该场景当中,每个类当中所包含的样本的数量服从一个长尾分布,也就是说每个类别所包含的样本数量都不相同,且有些类包含的样本数量极少。
进一步,针对这种长尾分布的类增量学习,我们提出了一种能够直接应用于各种现有模型的训练范式,通过在模型分类器后加入一个可学习的参数缩放模块,并在模型完成每个任务的学习后进行一次额外阶段的学习来更新分类器和缩放模块的参数。经实验验证,这种方式得到的模型在实际场景中能够更加适应不均衡的数据分布,进而提升在实际场景当中的分类效果。同时,将该训练流程应用到常规的类增量学习任务当中,也能够使原有的模型性能得到进一步提升。
03
弱监督场景下基于跨域先验知识迁移的
3D人体姿态估计算法
C3P: Cross-domain Pose Prior Propagation for Weakly Supervised
3D Human Pose Estimation
*本文由腾讯优图实验室和华中科技大学共同完成
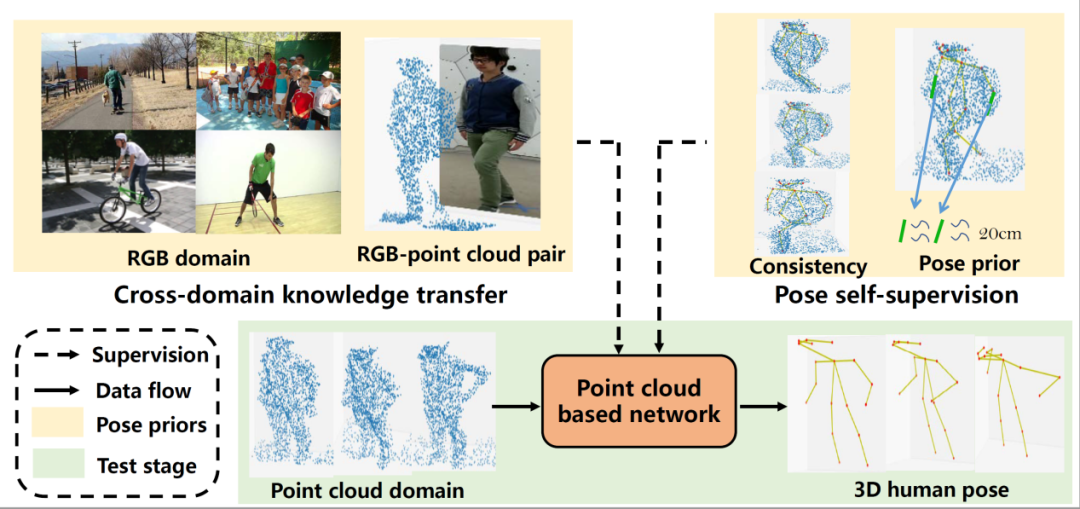
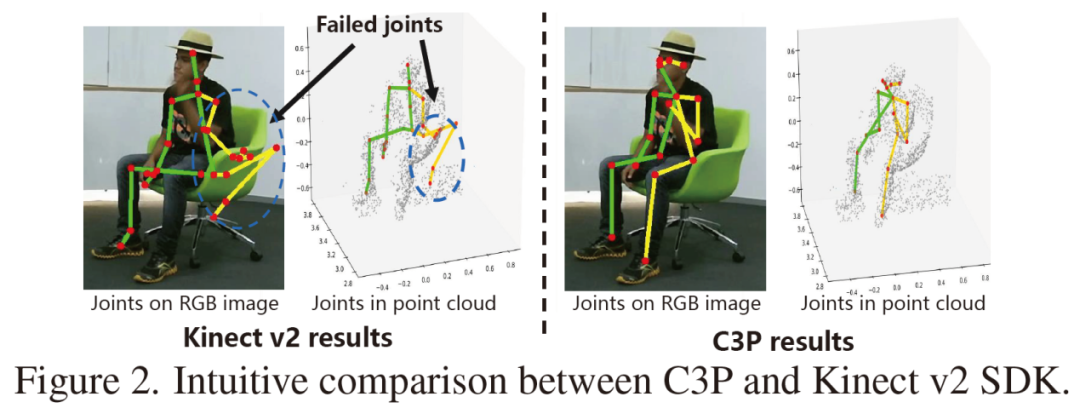
在这篇论文中,我们首次提出弱监督条件下的3D点云人体姿态估计算法-C3P,所提出的方法不需要对3D的点云数据进行人体姿态的繁琐标注。
为了实现这一目的,我们通过使用RGB图像和点云组成的一一对应的数据对,将RGB的信息迁移到3D空间中来。与此同时,点云数据中人体的姿态约束,包括物理姿态约束、人体对称性约束、骨骼长度以及时序运动等约束也被考虑进来进一步提升算法性能。
最终,我们的3D姿态估计网络体现为一个新颖的编码器加解码器的结构来处理点云数据。本文所提方法在CMU Panoptic和ITOP人体姿态估计数据集上取得了SOTA的效果,并且,利用无标住的NTU-RGBD数据集进行预训练,我们的算法可以取得(甚至超过)和全监督方法接近的性能。
04
基于细粒度数据分布对齐的后训练量化
Fine-grained Data Distribution Alignment for Post-Training Quantization
*本文由腾讯优图实验室和厦门大学共同完成
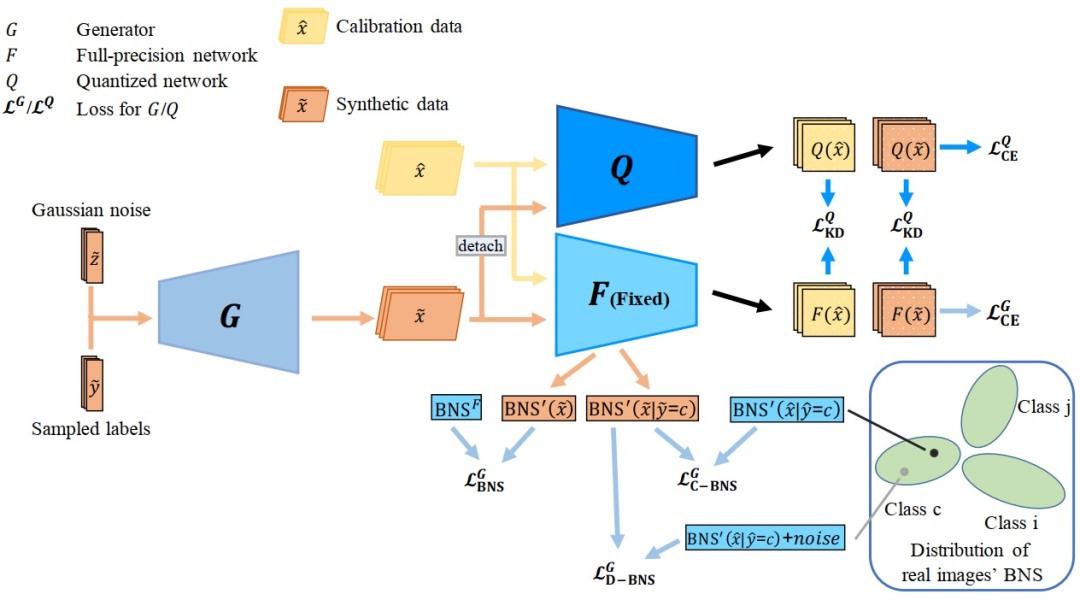
本文提出了一种基于生成数据的后训练量化方法。传统的后训练方法只利用了一个数据量很有限的矫正数据集,这些方法的性能也受限于数据量少的问题。本文利用无数据量化中生成合成数据的方法来生成假数据,从而来补充数据不足的问题,从而提高后训练量化网络的性能。
具体来说,本文提出了一种细粒度数据分布对齐(FDDA)方法来提高假数据的质量,该方法基于两个批量归一化统计(BNS)的重要性质:即类间分离和类内融合。
为了保存这个细粒度分布信息:1)我们并提出一个BNS集中损失,该损失强制不同类别的合成数据分布接近他们自己的对应的BNS中心。2)我们提出BNS失真损耗,该损失强制同一类的合成数据分布靠近加入了噪声的BNS中心。通过引入这两种细粒度损耗,我们的后训练量化方法在ImageNet上显示了先进的性能,尤其是在网络的第一层和最后一层时也被量化到低位的时候。
05
基于动态对偶可训边界的低精度超分网络
Dynamic Dual Trainable Bounds for Ultra-low Precision Super-Resolution Networks
*本文由腾讯优图实验室和厦门大学共同完成
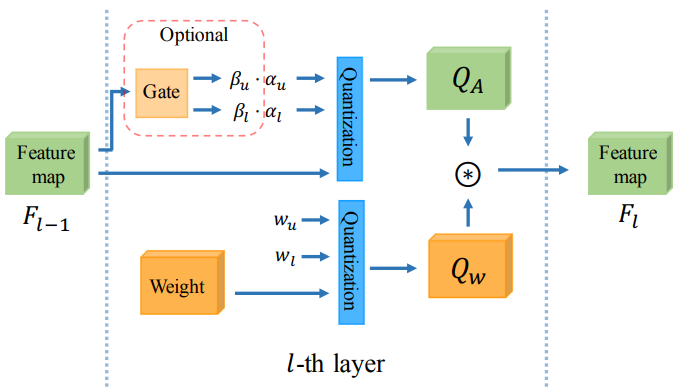
轻量超分辨率(SR)模型因其在移动设备中的适用性而备受关注。许多工作采用网络量化来压缩SR模型。然而,当使用低成本分层量化器将SR模型量化到超低精度(例如,2位和3位)时,这些方法的性能严重下降。在本文中,我们发现性能下降源于SR模型中分层对称量化器和高度不对称激活分布之间的矛盾。这种差异导致重建图像中的量化级别浪费或细节损失。
因此,我们提出了一种新的激活量化器,称为动态双可训练边界(DDTB),以适应激活的不对称性。具体来说,DDTB在以下方面进行了创新:1)具有可训练上下限的分层量化器,以解决高度不对称的激活问题。2) 动态门控制器在运行时自适应调整上下限,以克服不同样本上剧烈变化的激活范围。为了减少额外开销,动态门控制器被量化为2位,并根据引入的动态强度仅应用于SR网络的部分层。大量实验表明,我们的DDTB在超低精度方面表现出显著的性能改进。例如,当将EDSR量化为2位并将输出图像放大到x4时,我们的DDTB在Urban100基准上实现了0.70dB的峰值信噪比增加。
06
知识浓缩蒸馏
Knowledge Condensation Distillation
*本文由腾讯优图实验室和厦门大学共同完成
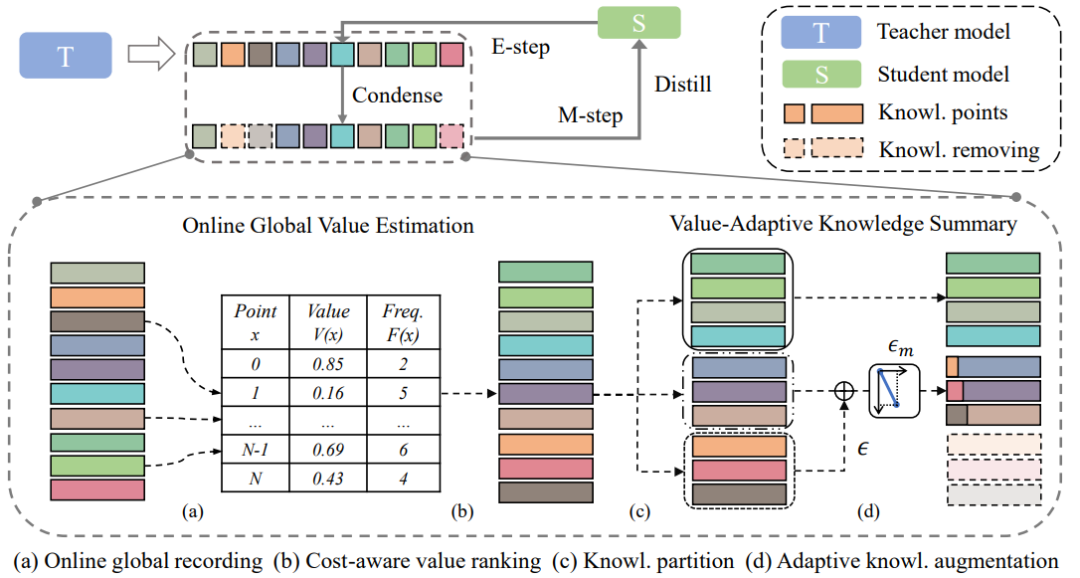
知识蒸馏 (KD) 从高容量教师网络转移知识以增强较低容量的学生网络的训练。此前的方法侧重于挖掘知识的不同线索以将教师知识完整地传递给学生,而较少关注到知识在不同阶段呈现出的不同学习价值,这将引发知识蒸馏的冗余性挑战。
本文中,从两个新颖的视角出发,我们提出了一种基于知识浓缩蒸馏的高效蒸馏方法:1)学生的学习进展向教师反馈以动态地影响教师的知识传递。2)学生主动识别出对自身学习更有价值的知识点并逐步总结出紧凑的核心知识集以提升学习效率。具体地,我们将每个样本上的知识价值编码为一个隐变量,并以此建立一个期望最大化(EM)框架交替地执行教师知识集的浓缩和学生模型的蒸馏。
本文的方法可作为一个即插即用的方案广泛地建立在当前的蒸馏方法上,提升它们性能的同时几乎不带来额外的训练参数和计算开销。在基准数据集上的实验结果表明,本文方法在精度和效率方面都超过当前的蒸馏方案。
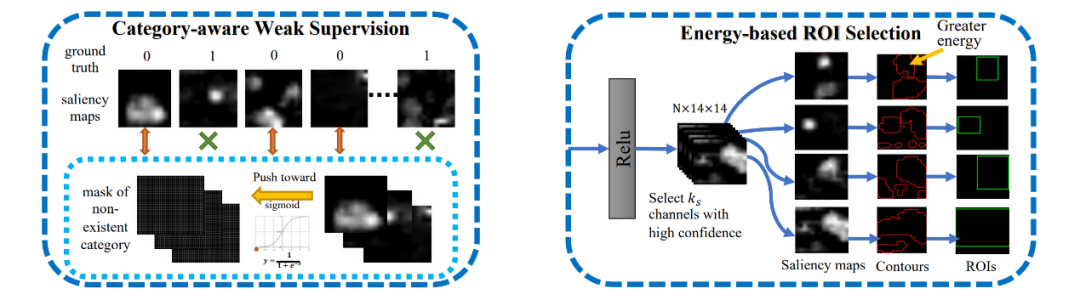
07
基于区域边界感知和实例区分的
弱监督3D场景分割
WS3D: Weakly Supervised
3D Scene Segmentation with
Region-Level Bound-ary Awareness
and Instance Discrimination
*本文由腾讯优图实验室和香港中文大学共同完成
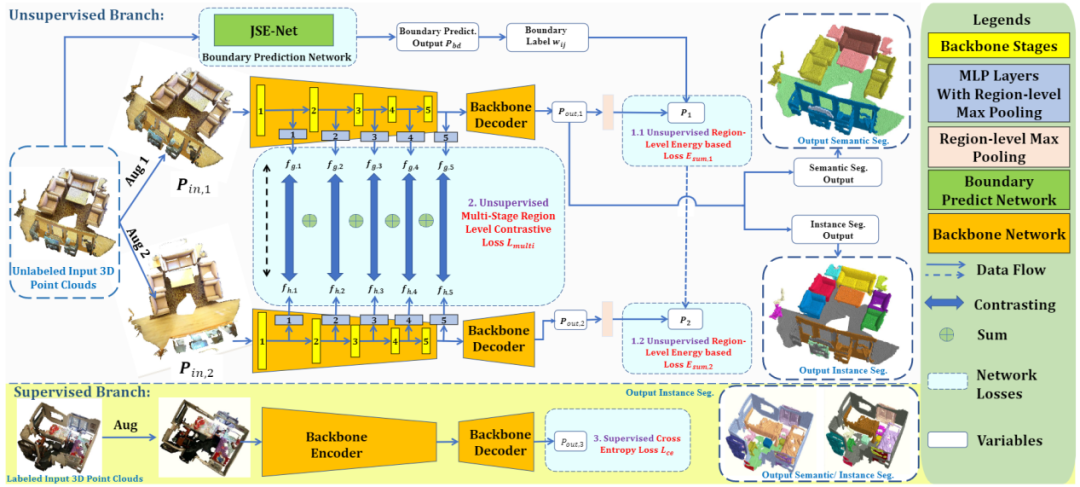
现有前沿的3D场景理解方法仅在全监督模式下才有较好表现。据我们所知,还没有同时解决3D场景下语义分割和实例分割的统一框架,尤其是在标注非常有限的时候。这篇论文提出了一个在标注数据比较有限的情况下的一个简单通用的3D场景理解框架。利用边界预测网络得到的区域边界,我们提出了一个新的边界感知能量方程去利用3D边界信息提升模型能力。为了提升潜空间中实例区分度和保证效率,我们首次提出一个针对3D点云的无监督区域级语义对比学习范式。这个范式利用网络得到的可靠预测来区分多个阶段得到的中间嵌入特征。在有限的重建场景中,我们所提出的WS3D方法,在大规模的ScanNet数据集上同时获得语义分割和实例分割的优异表现。同时,我们的方法在其他的大规模真实室内和室外场景数据集S3DIS和SemanticKiTTI上也表现优异。
08
DisCo: 蒸馏对比学习拯救小模型自监督学习
DisCo: Remedy Self-supervised Learning
on Lightweight Models with Distilled Contrastive Learning
(accepted as Oral)
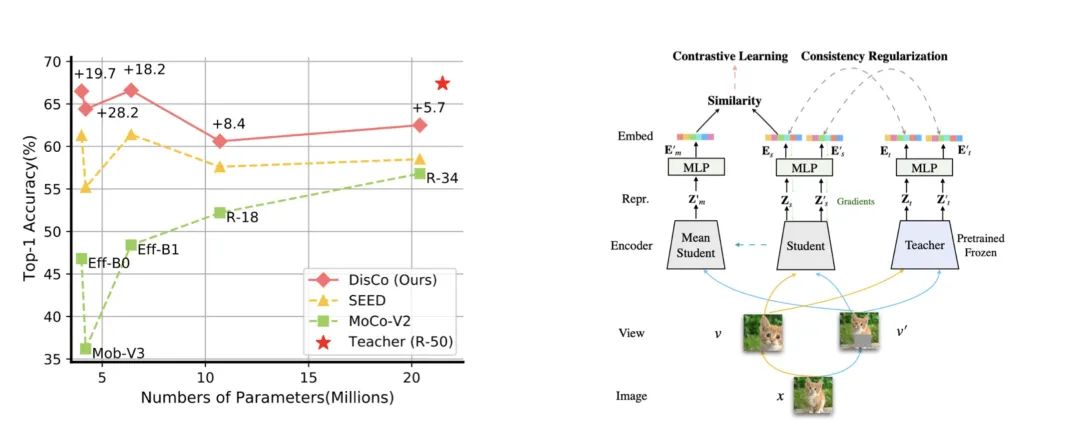
自监督学习近期受到了广泛关注,有许多学者发现当模型较小时,自监督学习的效果会受到较大的损失。因为主流自监督方法依赖对比学习来训练网络,我们提出了一个简单但有效的方法(DisCo)来提升小模型上自监督学习的效果。具体来说,我们发现主流SSL方法最后的embedding中蕴含着最丰富的信息,并提出将教师网络中最有效的embedding知识传输给学生网络。
此外,我们发现在这个传输过程中存在着Distilling BottleNeck现象,并提出扩大embedding的dimension来缓解该现象。因为MLP仅存在于自监督训练阶段,我们的方法在下游任务部署过程中没有引入额外的参数量。实验结果证明我们模型显著超过SoTA轻量化模型。特别地,当ResNet-101/ResNet-50作为教师网络来蒸馏学生EfficientNet-B0时,EfficientNet-B0在ImageNet数据集上的linear probe结果分别提升了22.1%和19.7%,这个结果非常接近ResNet-101/ResNet-50。代码及预训练模型已开源至:https: //github.com/Yuting-Gao/DisCo-pytorch。
09
基于差分隐私框架的频域下
人脸识别隐私保护算法
Privacy-Preserving Face Recognition with Learnable Privacy Budget in Frequency Domain
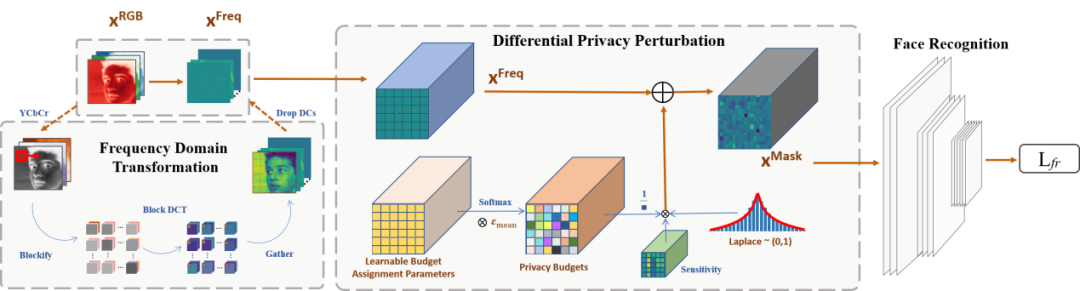
人脸识别技术因其极高的准确性在日常生活中被广泛使用,但与此同时,用户对于个人人脸图像被滥用的担忧亦与日俱增。目前保护隐私的人脸识别方法往往伴随着许多副作用,如推理时间的大幅增加和识别精度的明显下降。本文提出了一种在频域下使用差分隐私的人脸识别隐私保护算法。该方法首先将原始图像转换为频域特征,并去除其中的直流部分以消除原始图像中绝大部分的可视化信息。然后在差分隐私框架内根据后端人脸识别网络的损失学习隐私预算分配模块,并将相应的噪声添加到频域特征中。由于该方法基于差分隐私框架,隐私性的保证得到了理论支撑。并且可学习的隐私预算分配模块的加入使得噪声的添加尽可能少的影响该方法的识别精度。根据大量的实验,该方法在经典的人脸识别测试集上获得了极好的表现并在对抗攻击下具备很强的抗攻击能力。
10
具备领域自适应能力的行人搜索算法
Domain Adaptive Person Search
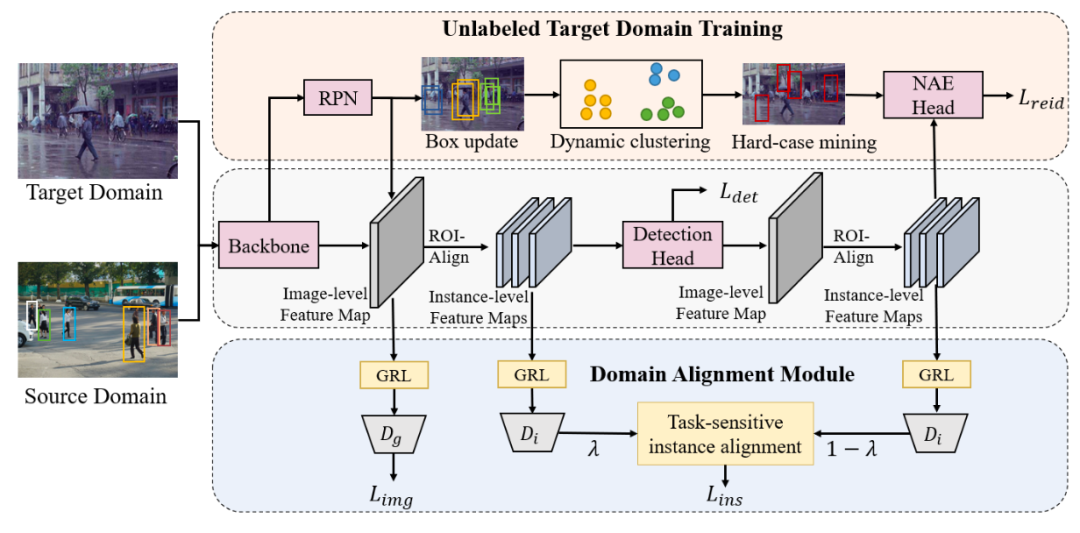
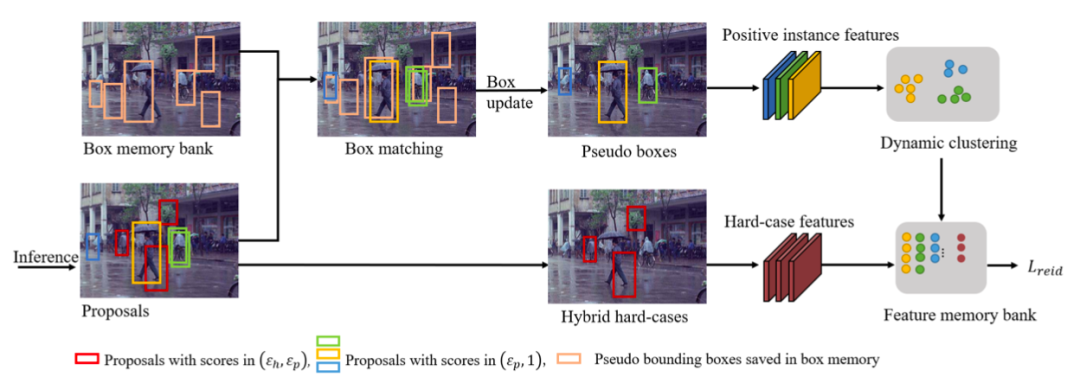

行人搜索技术旨在实现端到端联合行人检测和行人重识别任务。以前的工作在全监督和弱监督的环境下取得了重大进展。然而,这些方法忽略了行人搜索模型的跨领域泛化能力。我们进一步提出领域自适应行人搜索方法DAPS,旨在将模型从已知身份和检测框标注的源领域推广到没有任何标注的目标领域。在这种新设置下出现了两个主要挑战:一个是如何同时解决检测和行人重识别任务的领域错位问题,另一个是如何在目标域上没有可靠检测结果的情况下训练行人重识别子任务。
为了应对这些挑战,我们提出了一个具有专用设计的强大基线框架。1)我们设计了一个领域对齐模块,包括图像级和任务敏感的实例级对齐,以最小化跨领域差异。2)我们通过动态聚类策略充分利用未标记数据,并使用伪边界框来支持目标域上的检测和行人重识别联合训练。通过上述设计,我们的框架在PRW和CUHK-SYSU数据集间的跨领域迁移性能,大大超过了未经跨领域自适应直接迁移的模型。我们的无监督自适应模型的性能甚至可以超过一些全监督和仅知检测框的弱监督的方法。
11
大规模掌纹识别训练的“免费午餐”
Geometric Synthesis: A Free lunch for Large-scale Palmprint Recognition Model Pretraining
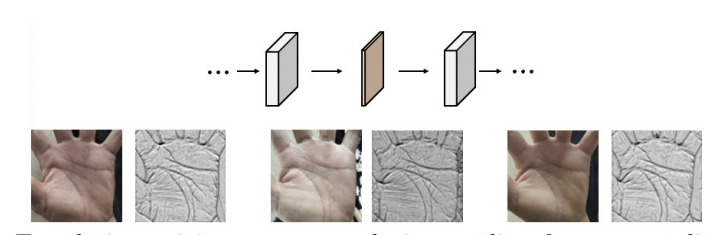

掌纹是一种稳定可靠的生物特征,并且具有很强的隐私属性。在深度学习时代,掌纹识别技术的发展被训练数据不足限制。在本文中,通过对模型响应的观察我们确定掌纹线是深度学习掌纹识别中的关键信息,可以通过人造掌纹线进行训练。具体来说,我们引入了一个直观的几何模型,该模型使用参数化的贝塞尔曲线表示掌纹线。通过随机抽样贝塞尔参数,我们可以合成大量不同身份的训练样本,进而使用预训练掌纹识别模型。实验结果表明这种使用人造数据预训练的模型有非常强的泛化性,可以高效率地迁移到真实数据集并显著提高掌纹识别的性能指标。例如在开集设置下,我们的方法在FAR=10^-6时TPR相对Arcface提升10%以上。在闭集条件下我们的方法也能减少EER一个数量级。
12
基于生成式域适应的人脸活体检测方法
Generative Domain Adaptation for Face Anti-Spoofing
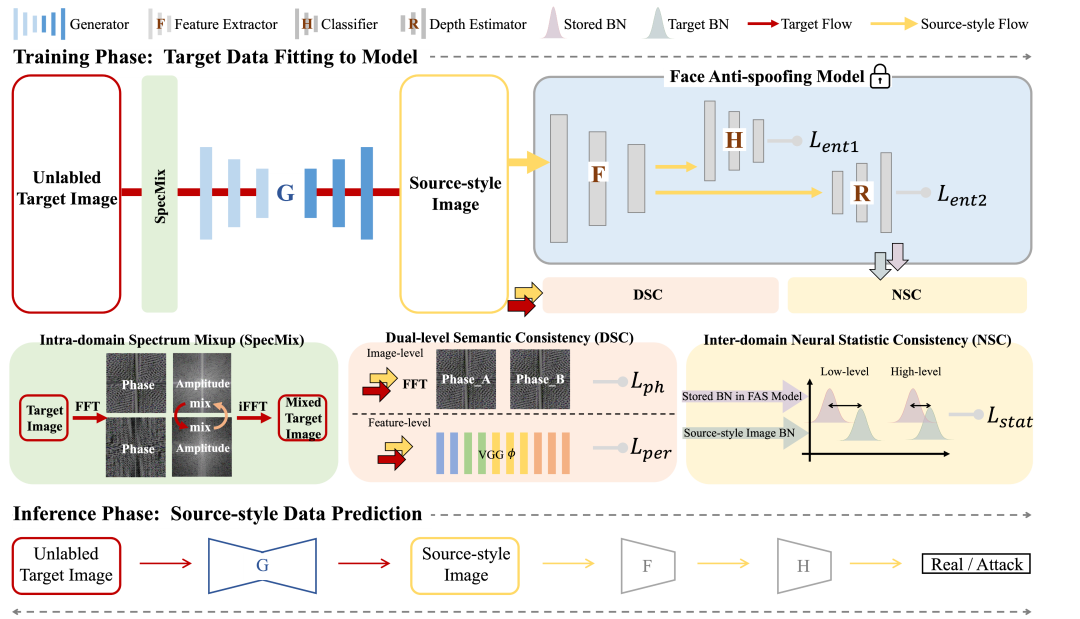
基于域适应 (DA) 的人脸活体检测 (FAS) 方法因其在目标场景中的迁移性能良好而受到越来越多的关注。大多数现有的域适应人脸活体检测方法通过对齐语义级别的高层特征分布将源域模型拟合到目标数据。然而,因为目标域上标签缺失导致的监督不足以及对于低层特征对齐的忽视限制了现有方法在人脸活体检测上的性能。
为了解决这个问题,本文从一个新的角度来解决域适应人脸活体检测问题,即让目标数据拟合到源域模型,通过图像转换将目标数据风格化为源域风格,并进一步将风格化的数据输入源域的活体检测模型进行判断。具体而言,本文提出了生成式域适应(GDA)框架,并结合域间特征分布一致性约束和双重语义一致性约束来保证生成图像风格和内容与目标的一致性;此外,我们还提出域内频谱混合模块来进一步扩展目标域数据分布并提升泛化性。多个活体检测数据集上的实验和可视化结果表明,比起当前的领先方法,我们方法具有更好的迁移性。
13
基于多层级对比学习的视频编辑检测算法
Hierarchical Contrastive
Inconsistency Learning
for Deepfake Video Detection
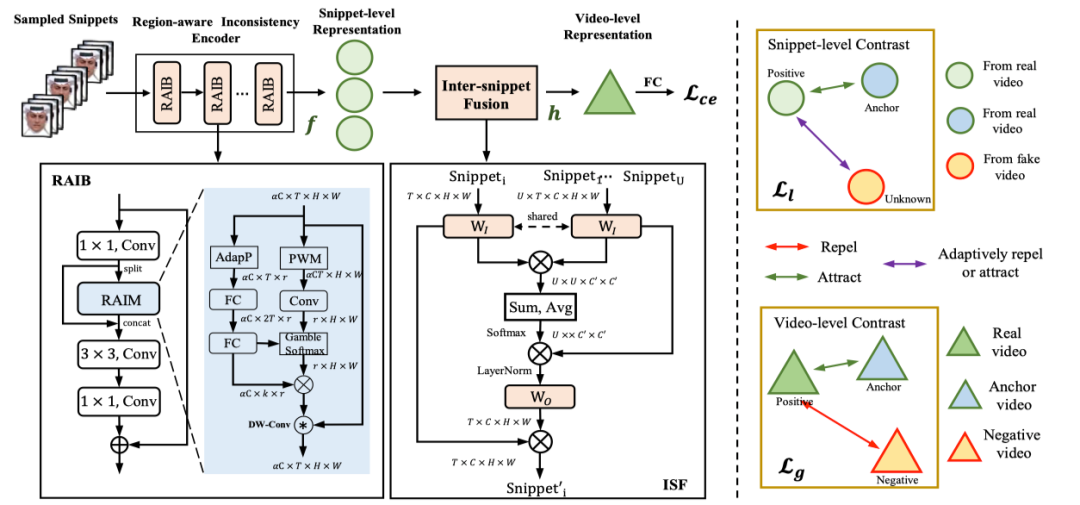
近年来,随着 Deepfake 技术的快速发展,生成逼真伪造人脸的能力引发了公众的担忧。与真实人脸视频对比,伪造视频中人脸面部运动的时序不一致性是识别 Deepfake 的有效线索,然而现有的方法往往只施加二分类监督来建模这种不一致性。在本文中,我们提出了一种新型多层级对比不一致性学习框架(HCIL)。
具体而言, HCIL 首先对视频进行多片段采样, 并同时在局部片段和全局视频层级上构建对比表征学习,从而能够捕获真假视频之间更本质的时序不一致差异。此外我们还引入了用于片段内不一致性挖掘的区域自适应模块和用于跨片段信息融合的片段间融合模块,来进一步促进特征学习。大量实验表明, HCIL 模型的性能在多个 Deepfake 视频数据集上优于当前的方法。同时, 跨数据集泛化性实验和可视化也证明了该方法的有效性。
14
基于信息注意力驱动的图像编辑检测算法
An Information Theoretic Approach
for Attention-Driven Face
Forgery Detection
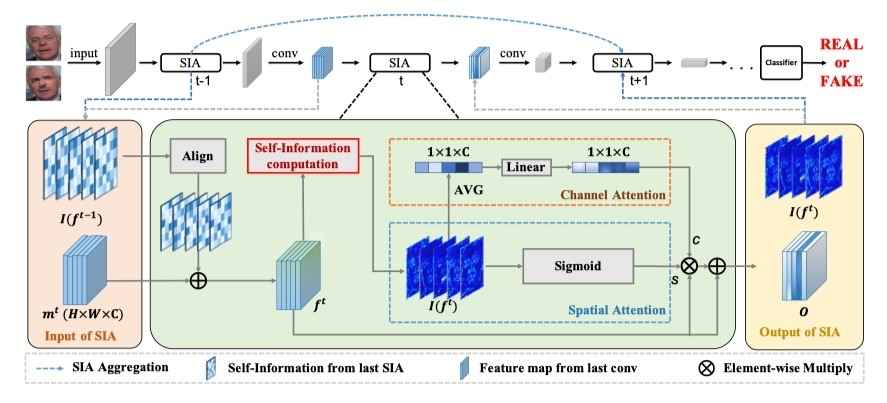
在人脸伪造检测任务中,先前基于CNN的启发式方法容易忽略细微的篡改痕迹。本文指出这些细微伪影往往富含高信息量,进而将自信息作为一种度量引入到伪造脸检测任务中,并结合注意力机制来增强网络对高信息量伪造区域的特征提取。同时本文还提出了一种跨层间的自信息聚合机制来缓解卷积神经网络下采样操作对细微伪造区域的擦除问题,进一步加强伪造区域特征的保留和提取。
具体而言,我们首先对输入特征图计算自信息,用于发掘所有潜在的高频伪造信息。随后结合自信息与双流注意力机制,分别在通道维度和空间维度计算注意力值来进一步增强潜在的高信息量区域,让网络挖掘出更多易被忽略的伪造信息。最后,当前层的自信息特征图将会跨层连接到下一个层注意力模块,更好地保留浅层细微伪造信息。本文设计的即插即用的注意力模块,可以应用到多种人脸伪造检测框架中。多个伪造人脸检测数据集上的实验表明我们的方法在增加少量参数的情况下,可以进一步提升网络的检测性能和泛化性。
15
基于原型对比的语义分割迁移学习算法
Prototypical Contrast Adaptation
for Domain Adaptive
Semantic Segmentation
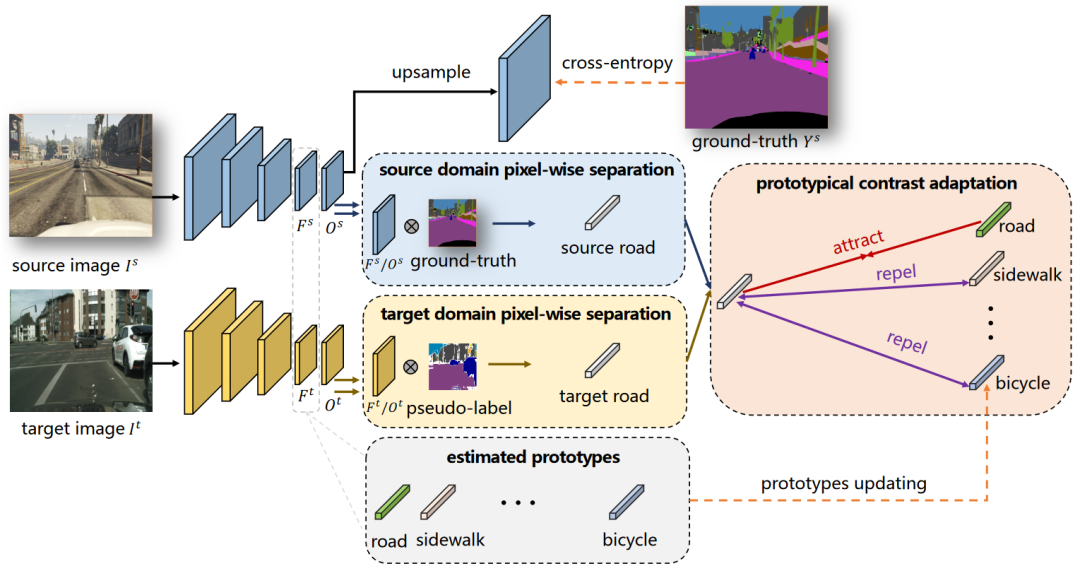
无监督迁移学习旨在将源域训练好的模型直接迁移在无标签的目标域,在实际场景如工业质检场景下有着重要作用,因为新场景下缺陷出现的概率往往很低,难以收集缺陷数据。以往的方法往往只利用特征的类间分布进行特征对齐,忽略了类间的关系建模,这就造成目标域下对齐的特征判别能力不足。
因此,本文提出通过原型对比的方式同时建模类内以及类间分布,我们的方法Prototypical Contrast Adaptation, 简称ProCA。具体地,ProCA通过对每一类维持一个原型表达,在特征对齐时,考虑同类的原型作为正样本,不同类的原型作为负样本从而实现类中心的分布对齐。相比目前已有的工作,ProCA在GTA5-Cityscapes以及SYNTHINA-Cityscapes上取得了更先进的结果。
16
基于互增强结构和对比学习的
小样本目标检测方法
Mutually Reinforcing with Box Contrastive Consistency
for Few-Shot Object Detection
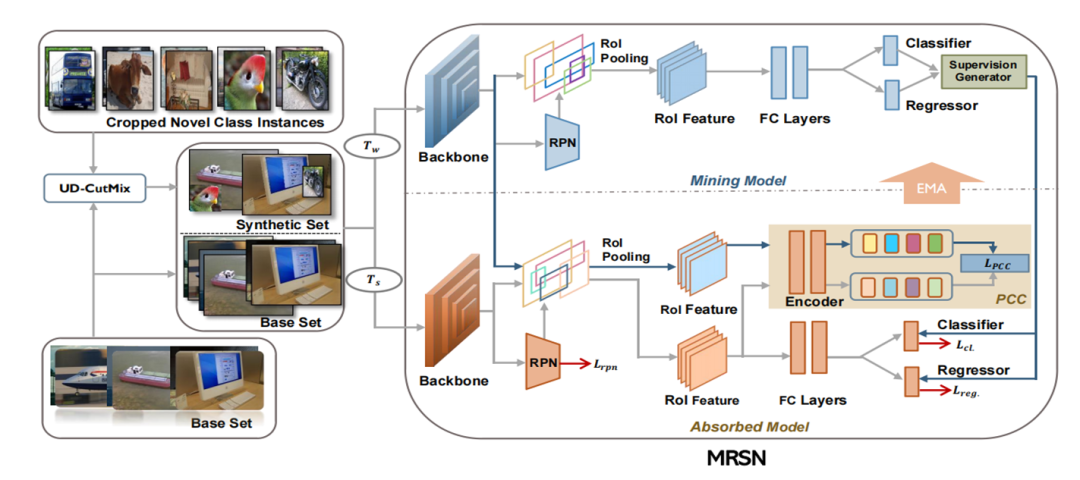
小样本目标检测依托于大量标记数据的基类来检测样本稀缺的新类。早期的解决方案主要基于元学习或迁移学习,这些方法忽略了一个重要事实:基类的图像中很可能包含未标记的新类实例,而基类中的新类实例被标记为背景将降低模型的整体检测性能和可塑性。
基于上述发现,我们提出了一种互增强网络结构(MRSN),以合理利用基类中未标记的新类实例。具体来说,MRSN由一个数据挖掘模型和吸收模型组成,前者负责挖掘未标记的新类实例,后者渐进式的迁移挖掘到的知识。然后,我们在吸收模型中设计了一个候选框对比一致(PCC)模块,以充分学习样本特征并避免伪标签噪声带来的负面影响。此外,我们提出了一种简单有效的数据合成方法UD-CutMix,以提升模型挖掘未标记新类实例的鲁棒性。大量实验表明,我们提出的方法在PASCAL VOC和MS COCO数据集上实现了较好的效果。
17
基于形状信息的图块对抗攻击方法
Shape Matters: Deformable
Patch Attack
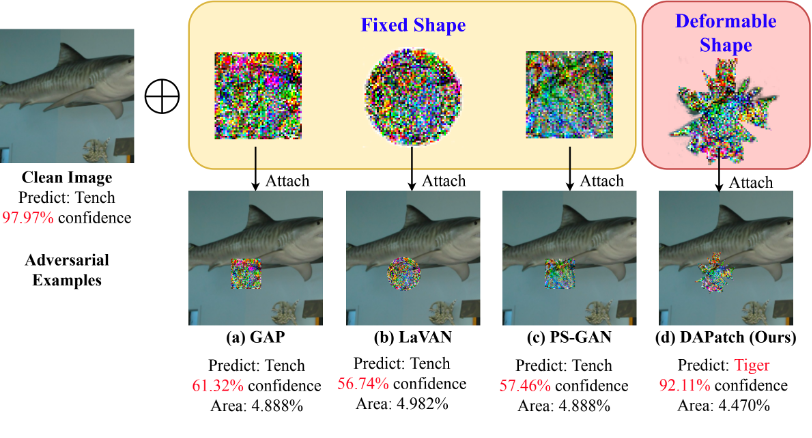
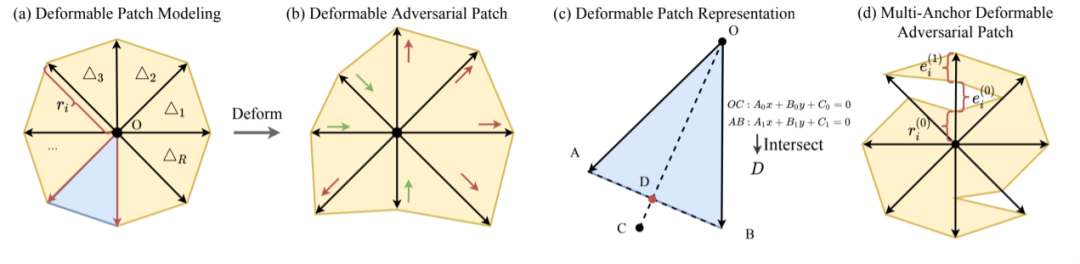
尽管深度神经网络在计算机视觉中表现出出色的性能,但它们很容易受到精心设计的对抗样本的攻击,这些对抗样本会误导神经网络输出不正确的预测。图块攻击是对抗样本中最具威胁性的形式之一,它能够威胁到现实世界系统的安全。现有工作总是假定对抗图块具有固定的形状,例如圆形或矩形,并没有将图块的形状视为图块攻击的一个影响因素。
为了探索这个问题,我们提出了一种新颖的可形变图块表示(DPR),它可以利用三角形的几何结构来支持轮廓建模和掩码之间的可微映射。基于DPR,我们提出了一种名为可形变对抗图块(DAPatch)的联合优化算法,它允许同时有效地优化形状和纹理以提高图块攻击的性能。实验结果表明,只需拥有一种攻击性的形状,图块就能有效干扰神经网络的性能,如果再结合攻击性的纹理,则能表现出更大的威胁性。在GTSRB和ILSVRC 2012数据集上,DAPatch在各种网络架构上实现了目前先进的白盒攻击性能,并且生成的图块在现实世界中具有威胁性。本工作首次从对抗样本的角度来研究形状对神经网络鲁棒性的重要性,这有助于理解和探索现有计算机视觉系统漏洞的本质。
18
统一的高保真度人脸再扮演和换脸框架
Designing One Unified Framework
for High-Fidelity Reenactment
and Swapping
图片来源于公开论文
《Voxceleb2: Deep speaker recognition》
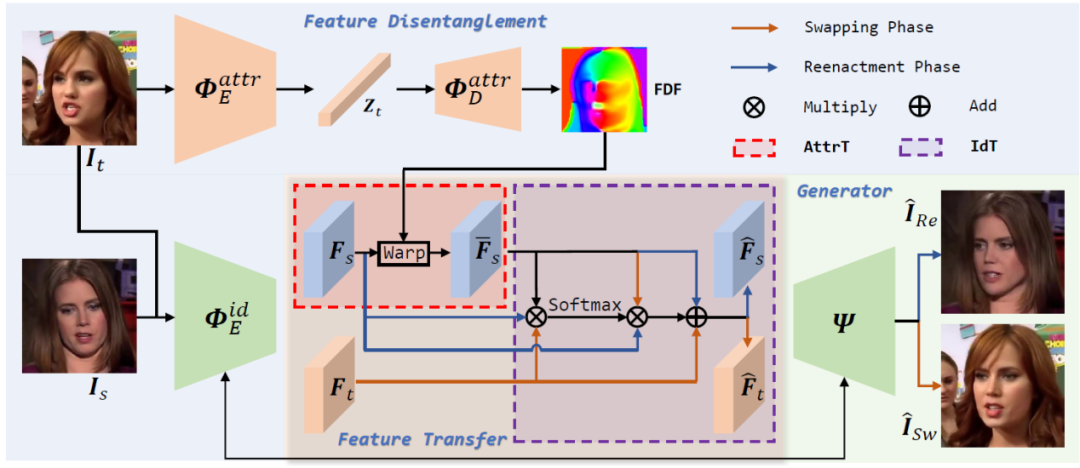
人脸再扮演和换脸是两个高度相关的任务,但目前的研究工作几乎都单独考虑每个任务,在这项工作中,我们提出了一个高效的端到端的统一的框架来实现这两个任务。区别于目前的方法直接利用预训练好的人脸结构先验提取网络来获得人脸属性和身份信息,我们使用自监督的方式来解耦得到以向量为表征的属性信息和以特征图为表征的身份信息,在推理阶段不依赖于任何的人脸先验,使得该方法在极端环境下有更棒的表现。
此外,目前的方法没有充分考虑两个任务之间的内在联系导致统一框架下两个任务性能都有所降低,我们分别精心设计了属性和人脸迁移模块,同时根据两个任务之间的关系将对应的模块高效的组合到一块来提升各个任务的性能。大量的实验证明了我们的统一结构在人脸再扮演和换脸两个任务中都取得了更先进的结果。
19
基于关键点特征和上采样Transformer的点云补全方法
SeedFormer: Learning Patch Seeds
in Point Cloud Completion
with Upsample Transformer

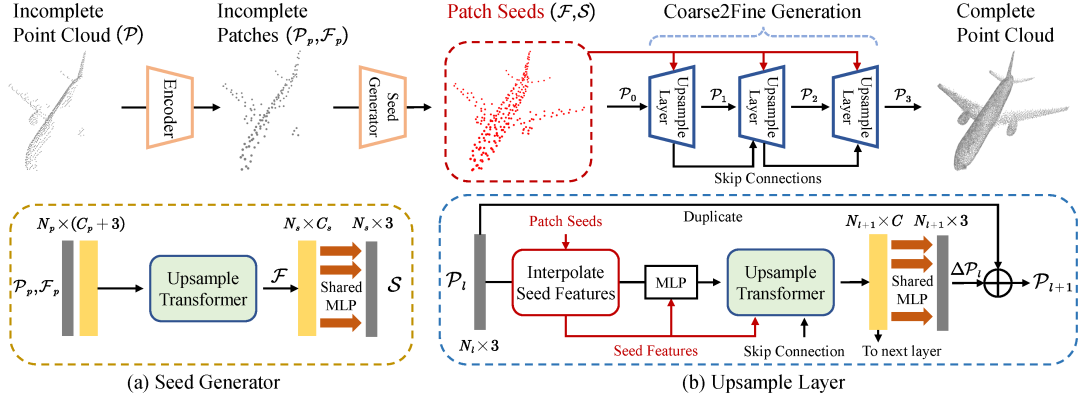
三维点云补全,作为三维扫描数据修复过程中不可缺少的一步,近年来受到了广泛的关注和研究,并应用于诸多3D生成任务之中。在这项工作中,我们提出了SeedFormer,一种用于解决点云补全任务中细节丢失和修复不完整等问题的补全框架。与以往的基于全局特征的方法不同,我们提出了Patch Seeds,一种基于关键点特征的点云表示形式,不仅能够完整地捕捉三维物体整体性的特征,更有利于保留局部范围内重要的细节和结构。此外,我们设计了一种新的三维生成器,即上采样Transformer,通过将Transformer自注意力机制应用到点云生成中,可以有效地提取局部邻域内坐标空间和语义空间中的特征和关联。大量实验结果表明,SeedFormer在PCN、ShapeNet55等多个公开数据集上取得了先进的结果。
20
百万像素级的高保真身份解耦人脸渲染算法
StyleFace: Towards High-fidelity
Disentangled Face Rendering
on Megapixels
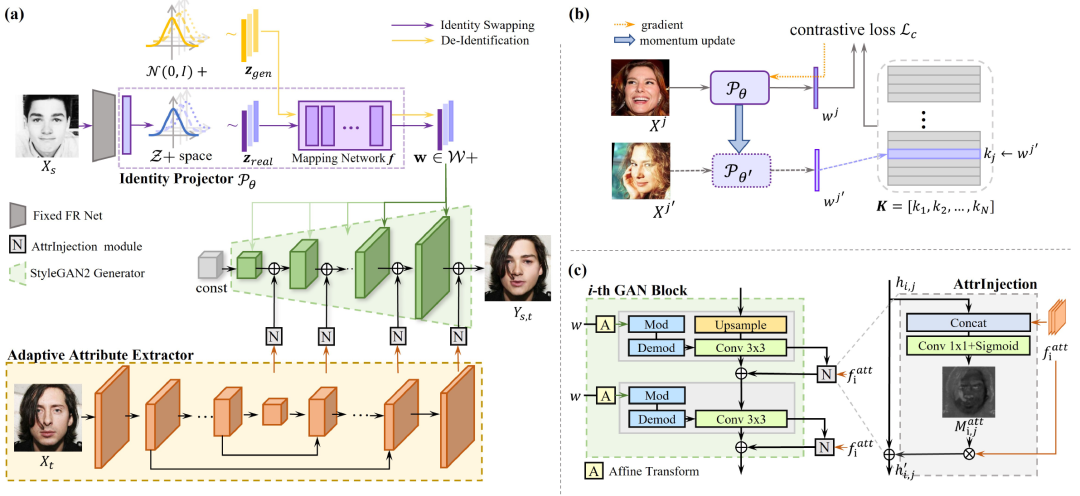
换脸和人脸匿名化是身份解耦人脸图像生成的两个重要应用。虽然这两个任务有类似的问题定义,但在研究工作中经常被分开处理,另外百万像素级的身份解耦人脸生成也一直在探索中。在这项工作中,我们提出了 StyleFace,一个百万像素级的高保真换脸和匿名化的统一框架。为了对真实人脸身份进行编码同时支持虚拟身份生成,我们将身份表示为潜变量,并利用对比学习进行潜空间正则化。除此之外,我们魔改了StyleGAN2来提高生成质量,并设计了一个自适应属性提取器以简单而有效的方式提取与身份无关的属性特征。大量实验证明了 StyleFace 在换脸和匿名化上均取得了更先进的结果。
21
基于颜色记忆和混合注意力Transformer的图像上色方法
ColorFormer: Image Colorization via Color Memory assisted
Hybrid-attention Transformer
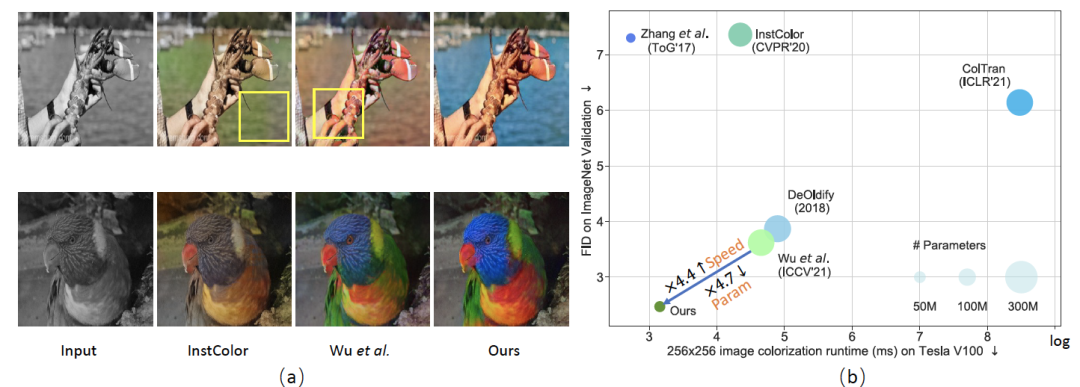
自动图像着色是一项具有挑战性的任务,吸引了很多研究兴趣。以前使用深度神经网络的方法已经产生了令人印象深刻的结果。然而,这些着色图像仍然不能令人满意,离实际应用还很远。原因是语义一致性和色彩丰富度是现有方法忽略的两个关键要素。在这项工作中,我们提出了一种通过颜色记忆辅助混合注意力Transformer的自动图像着色方法,即 ColorFormer。我们的网络由一个基于Transformer的编码器和一个颜色记忆解码器组成。编码器的核心模块是我们提出的全局-局部混合注意力操作,它提高了捕获全局感受野依赖关系的能力。
凭借在不同场景中对灰度图像的上下文语义信息进行建模的强大能力,我们的网络可以产生语义一致的着色结果。在解码器部分,我们设计了一个颜色记忆模块,用于存储图像自适应查询的各种语义颜色映射。查询到的颜色先验作为参考,帮助解码器产生更加生动多样的结果。实验结果表明,与先进的方法相比,我们的方法可以生成更逼真和语义匹配的彩色图像。此外,由于提出的端到端架构,推理速度在 V100 GPU 上达到 40FPS,满足实时要求。
22
基于Transformer语义滤波器的小样本学习方法
tSF: Transformer-based
Semantic Filter for Few-Shot Learning
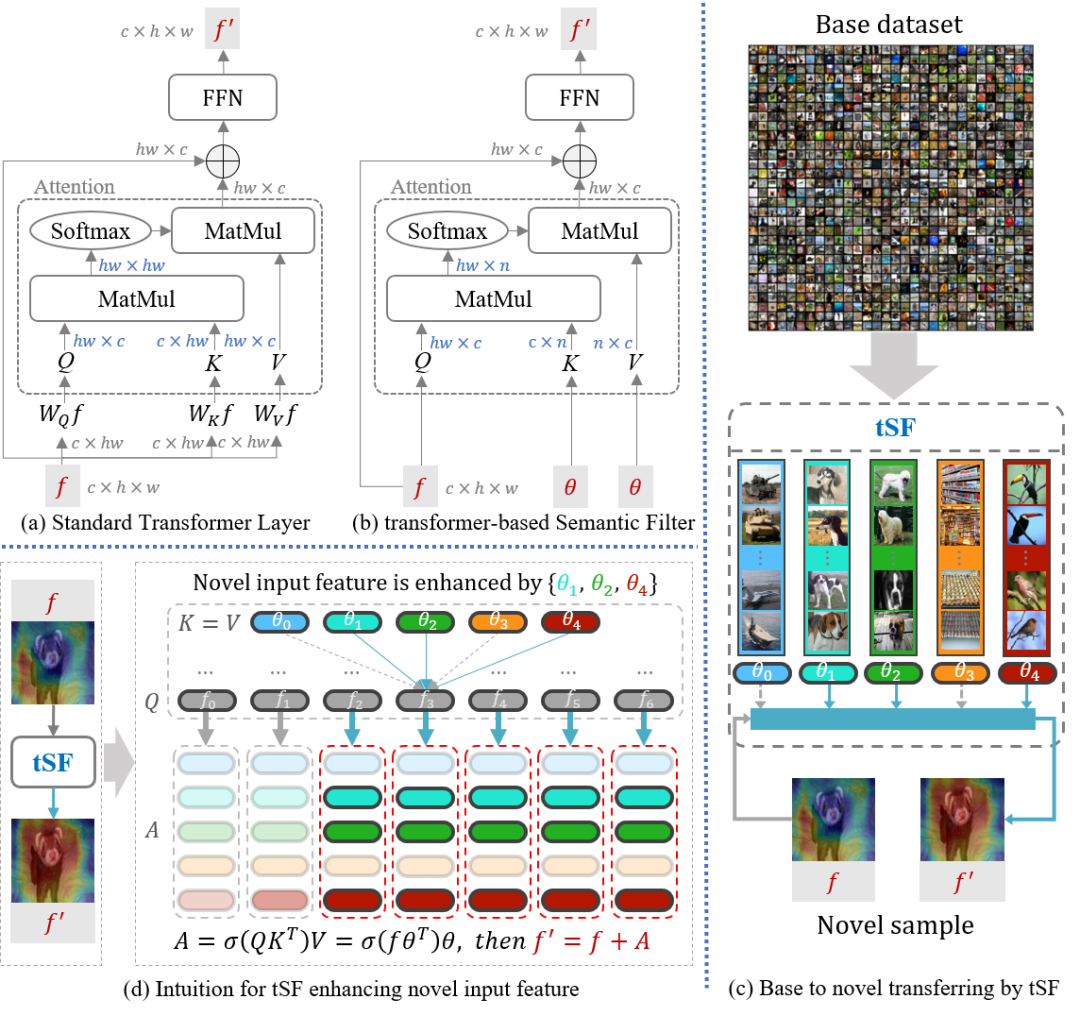
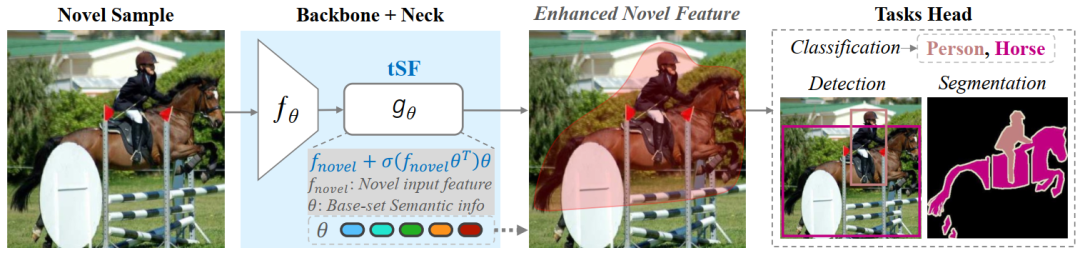
小样本学习为了缓解新类别数据匮乏导致的过拟合问题,通常先在大规模的旧类别数据上进行模型预训练,再迁移到新类别数据。为了提升模型的泛化性,最近小样本学习方法针对不同学习任务(例如分类、分割和目标检测)设计了特定的特征模块,但这些模块在不同学习任务间往往不通用。为此,我们提出了一个适用于不同小样本学习任务的轻量且通用的特征模块,称为基于transformer的语义滤波器(tSF)。
tSF是一种即插即用的特征模块,可以将它插入到backbone后端,为小样本学习任务提升特征泛化性。tSF是transformer结构的变体,使用在旧类别数据上学习到的语义信息,对新类别特征进行语义过滤,来增强新类别前景特征。此外,tSF 的参数量只有transformer的一半(小于1M)。在实验中,我们的 tSF 在不同的小样本学习任务中均能获得性能提升(大约 2% 提升),尤其在多个分类基准数据集(miniImageNet 和 tieredImageNet)上优于先进的小样本分类方法。
23
基于Transformer网络的高效检测器
Efficient Decoder-free Object Detection with Transformers
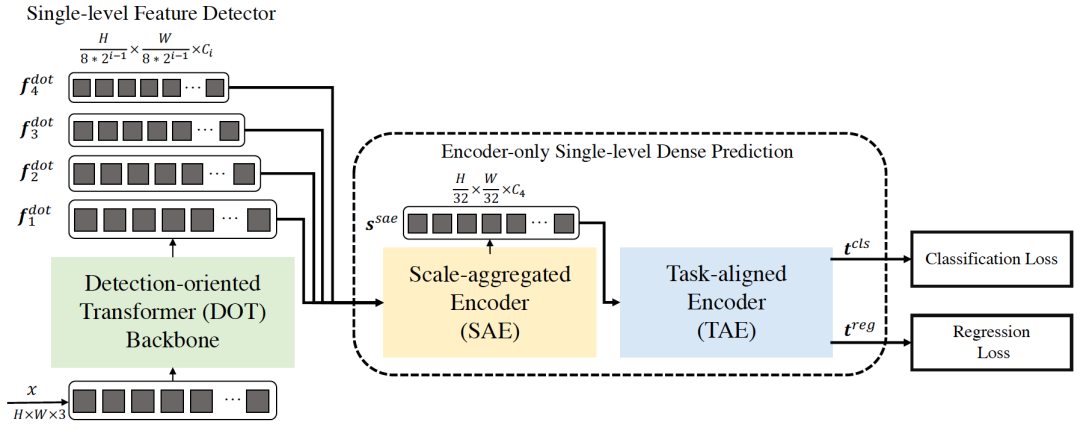
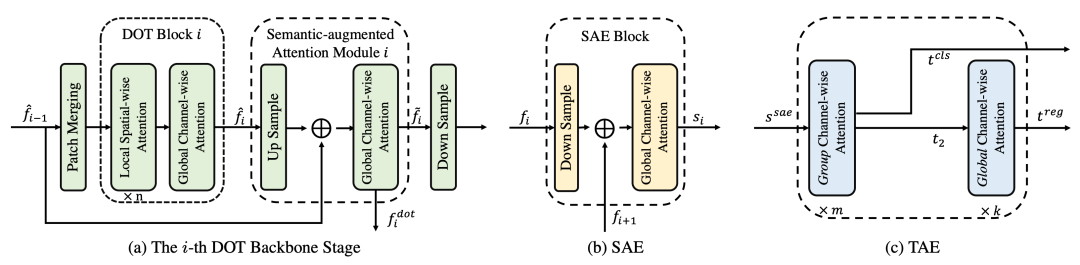
本文中,我们提出了一种高效的基于Transformer的目标检测网络(Efficient Decoder-free Fully Transformer-based Object Detector, DFFT)。首先,DFFT去掉了基于Transformer的检测器中,导致训练效率低的解码器,将目标检测任务简化成了一个只需编码且单层输出的预测任务, 并利用Transformer强大的空间和语义关系建模能力, 提出了两个具有强大功能的编码器(多尺度聚合编码器和任务对齐编码器)来将多尺度的特征聚合到单个特征图中,并对目标检测中的分类和回归任务进行特征对齐。
其次,我们还针对目标检测任务,在transformer网络中引入了全局通道的关注模块和语义增强的关注模块,以获得具有更加丰富的语义信息的底层特征。与其他的Transformer网路相比,我们提出的面向目标检测的高效Transformer网络,使用了更少的通道数和层数达到了同等的效果。最后,我们在MS COCO数据集上进行了实验,验证了DFFT方法的高效性。与DETR方法相比,DFFT降低了20%的收敛时间,增加了61%的推理速度,同时获得了2%的精度提升。
24
ARM:实时超分方法
ARM: Any-Time
Super-Resolution Method
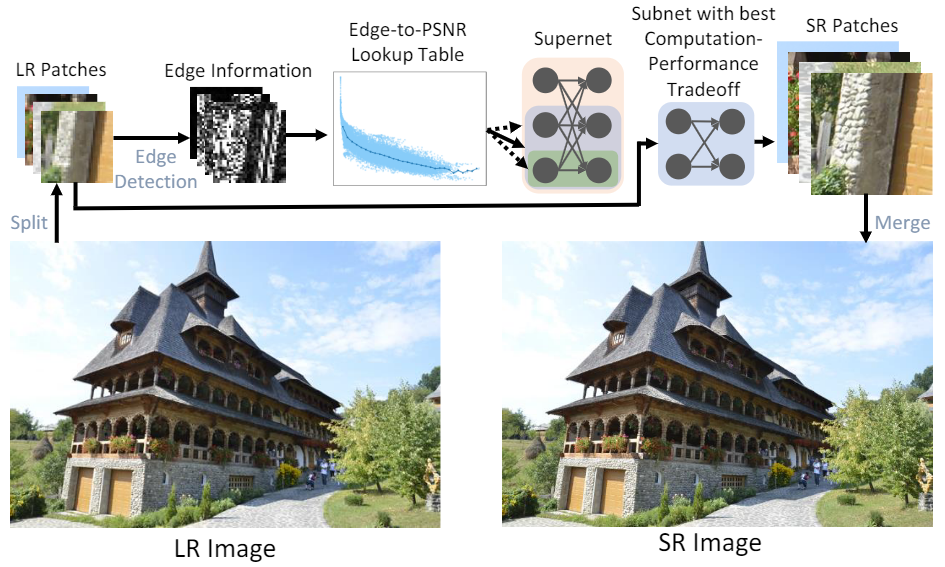
单图超分辨率任务旨在通过学习低分辨率图片到高分辨率图片的重建过程,将一幅的低分辨率图片重建恢复出高分辨率图片。此前的方法无法在推理时根据推理样本和可用计算资源动态调整计算开销,因次此一个模型无法适应多种设备平台和多变的资源情况。
基于此,我们提出一种任意时间超分方法(ARM),从而使得一个超分网络能够在推理时调整为任意的计算开销。第一,我们训练了一个包含不同大小子网的ARM超网,其中包含多个推理开销不同的子网,以便在推理时进行切换。第二,我们基于边缘检测分数与PSNR的相关性的发现,构建了一个Edge-to-PSNR查找表,用于通过边缘分数来预测不同子网对某个样本的预期PSNR。第三,我们设计了一个由超参η控制的子网选择函数,该函数可以根据不同子网的预期PSNR和对应的计算量进行子网的选择。
最后在推理时,我们设计了一套patch切分、patch推理、patch拼接的推理流程,其中patch推理的部分使用子网选择函数自适应地选择子网进行推理。实验结果显示本文方法效果超过了最先进的动态超分方法,并在FSRCNN、CARN和SRResNet等经典超分骨干网络上的实验结果取得的SOTA的效果。
25
可任意指定关键点的快速图像匹配算法
ECO-TR: Efficient Correspondences Finding
Via Coarse-to-Fine Refinement
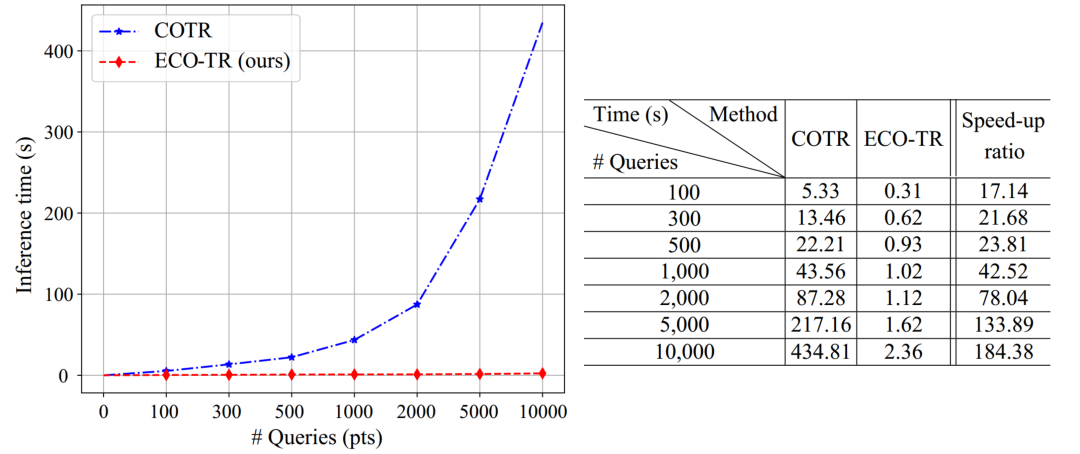
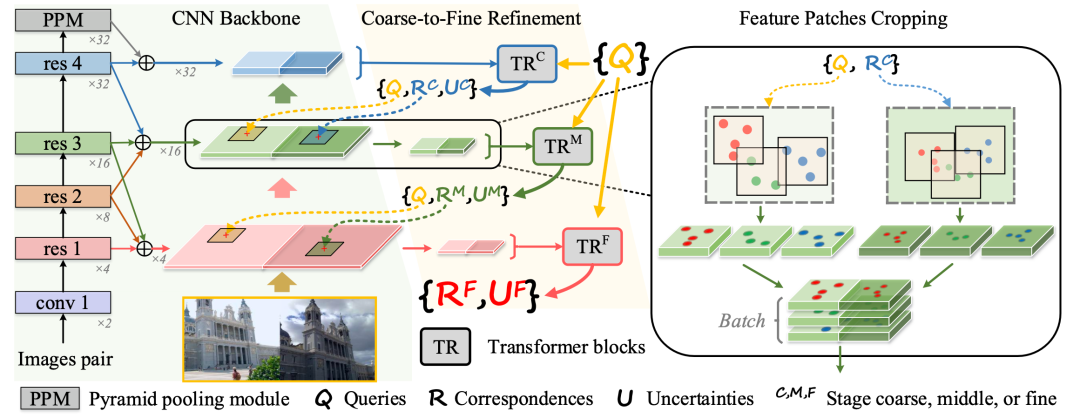
传统的图像匹配算法可分为稠密匹配和稀疏匹配。近期逐渐有算法希望可以通过一种统一的框架来同时实现稠密关键点和稀疏关键点。然而这些方法无论从效果还是耗时都无法达到实际可用的水平。本文提出了一种端到端的训练框架,可以通过用户输入任意关键点坐标进行匹配,可同时支持稀疏的关键点匹配和稠密关键点匹配等任务,同时较之前的方法在效果保持一致或更好的前提下,速度可提升两个数量级。相关实验证明我们的方法在效率和效果上都可以达到目前的最好水平。
26
渐进式图片生成
PixelFolder: An Efficient Progressive Pixel Synthesis Network
for Image Generation
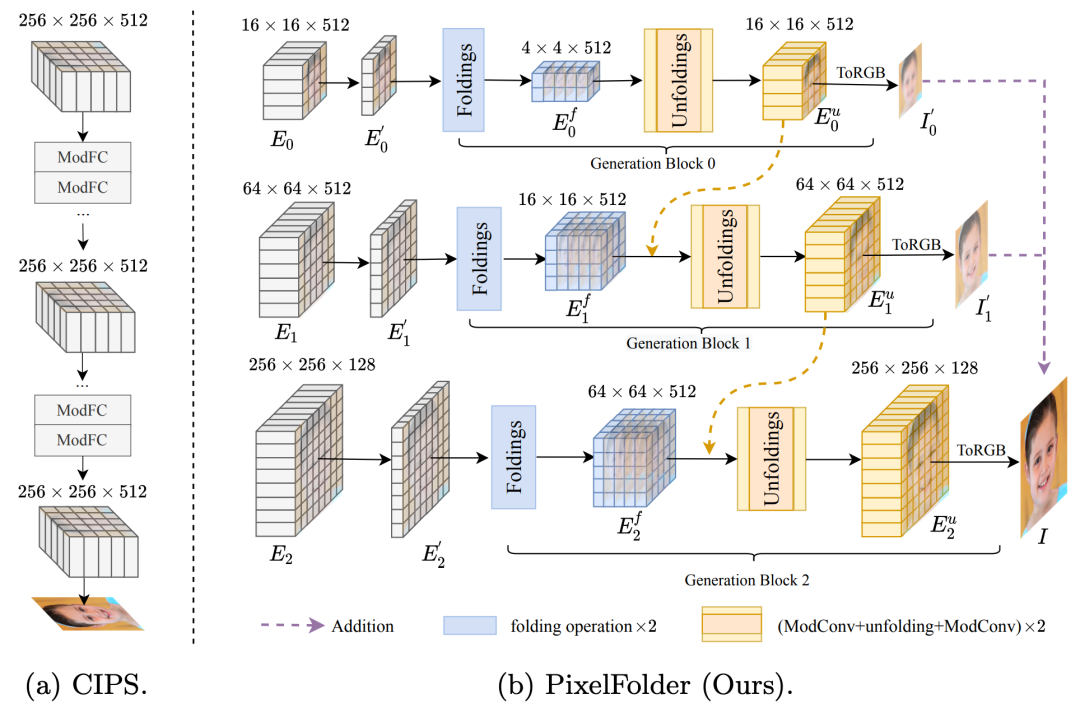
像素合成是一种很有前途的图像生成研究范式,它可以很好地利用像素级先验知识进行生成。然而,现有方法仍然存在过多的内存占用和计算开销。在本文中,我们提出了一种用于高效图像生成的渐进式像素合成网络,称为 PixelFolder。具体来说,PixelFolder 将图像生成公式化为渐进式像素回归问题,并通过多阶段范式合成图像,可以大大减少大张量变换带来的开销。此外,我们引入了新颖的像素折叠操作,以进一步提高模型效率,同时保持端到端回归的像素级先验知识。通过这些创新设计,我们大大降低了像素合成的开销,例如与最新的像素合成方法 CIPS 相比,减少了 90% 的计算量和 57% 的参数。
为了验证我们的方法,我们在两个基准数据集上进行了广泛的实验,即 FFHQ 和 LSUN Church。实验结果表明,PixelFolder 以更少的支出在两个基准数据集上获得了新的 state-of-the-art (SOTA) 性能,即 FFHQ 和 LSUN Church 上的 FID 分别为 3.77 和 2.45。同时,PixelFolder 也更比 StyleGAN2 等 SOTA 方法更高效,分别减少了约 74% 的计算量和 36% 的参数。这些结果极大地验证了所提出的 PixelFolder 的有效性。
27
SeqTR:简单且通用的视觉定位网络
SeqTR: A Simple yet Universal Network for Visual Grounding
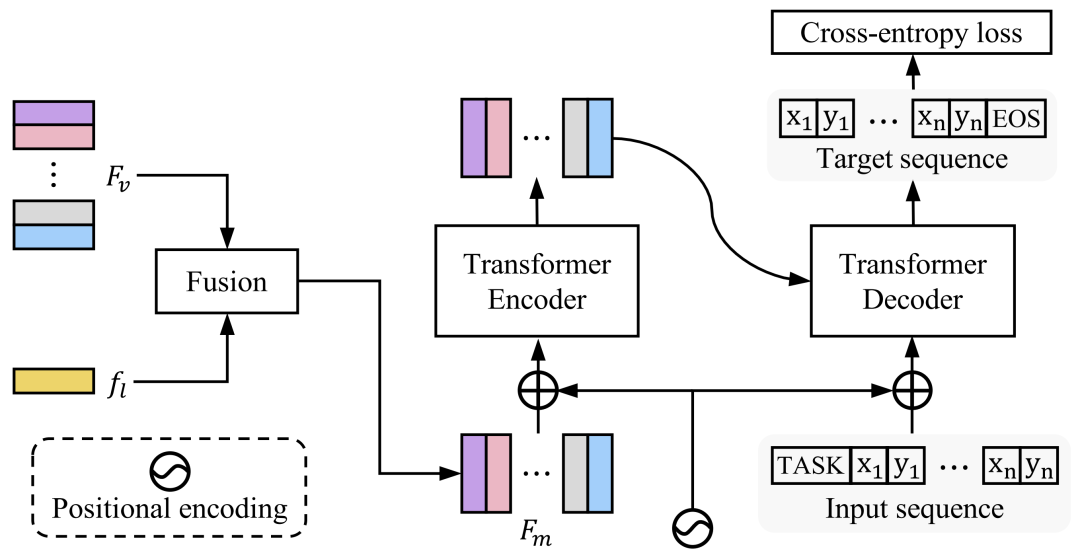
我们提出了一个简单而通用的网络SeqTR,用于视觉定位任务,如短语定位、指向性检测和指向性分割。视觉定位的典型范例通常需要有设计网络架构和损失函数方面的大量专业知识,这使得它们很难跨任务进行泛化。为了简化和统一建模,我们将视觉定位转换为以图像和文本输入为条件的点预测问题,其中边界框或二进制掩码被表示为一系列离散的坐标标记。在这种范式下,视觉定位任务统一在我们的SeqTR网络中,没有特定于任务的分支或头,例如,用于指向性分割的卷积掩模解码器,这大大降低了多任务建模的复杂性。此外,SeqTR还为所有任务共享了简单交叉熵损失作为优化目标,进一步降低了手工设计的损失函数的复杂性。在五个基准数据集上的实验表明,提出的SeqTR优于(或相当于)现有的最先进水平,证明了一种简单而通用的视觉定位方法确实是可行的。
28
基于球面学习的多标签识别算法
Hyperspherical Learning
in Multi-Label Classification
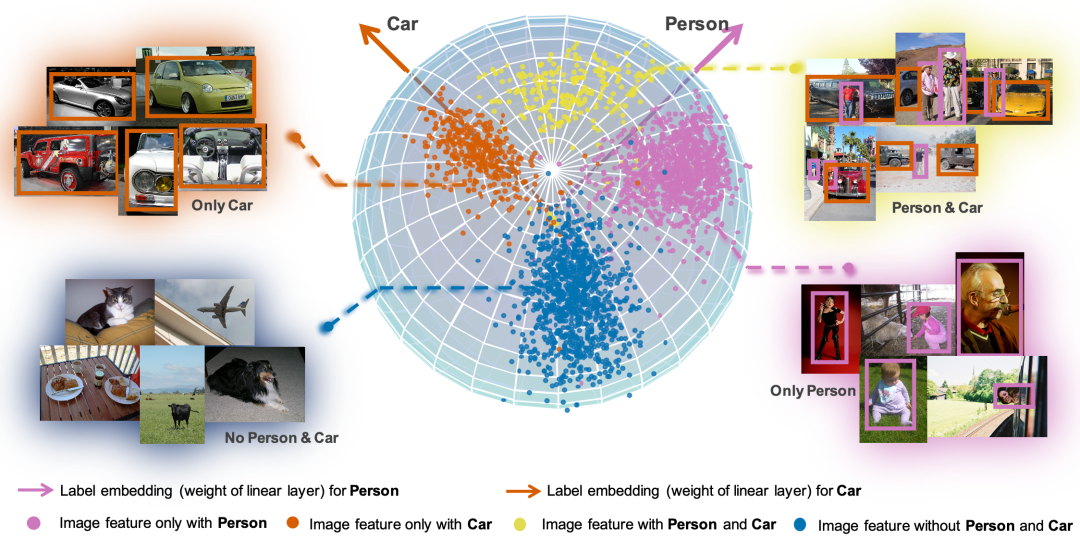
收集大规模精细标注的多标签数据集是非常昂贵的,因此实践中,我们会更多地采用部分标注正样本的方式构建多标签数据。已有的方法使用欧氏特征空间,容易受到噪声样本的影响。为了解决这个问题,我们将超球面空间引入了多标签学习当中。不同于单分类中类别之间往往是互斥的,我们在球面空间中可以看出标签之间互斥或者互补关系。进一步的,我们提出使用角度间隔去压制噪声样本的梯度,增强正样本的学习。
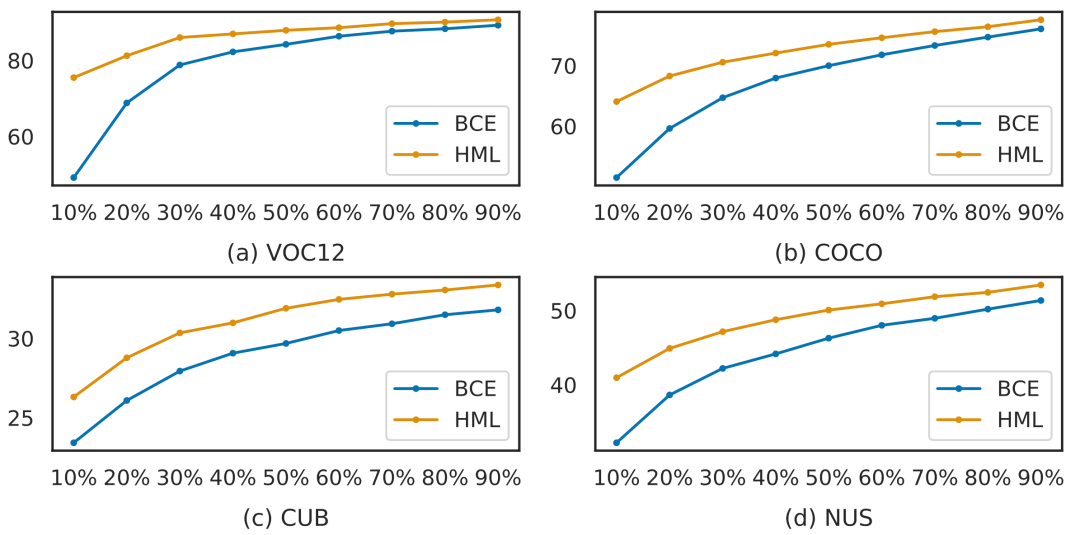
我们还提出了自适应调整超参数的训练机制,减少参数搜索的重复实验。在实验部分,我们比较了单正标签(single positive labels)、部分标注正样本(partial positive labels)和完全标注这三种实验设定。结果表明我们的方法在以上三种设定下,VOC12, COCO, CUB-200 和 NUS-WIDE 四个数据上都有效果提升。此外,为了更好地理解标签之间的相关性,我们还提出了用标签类别向量在球面空间相对关系去做量化表示。希望本工作能够推动大规模多标签识别的落地。
29
基于特征增广的长尾识别
Sample-adaptive Augmentation
for Long-Tailed Image Classification
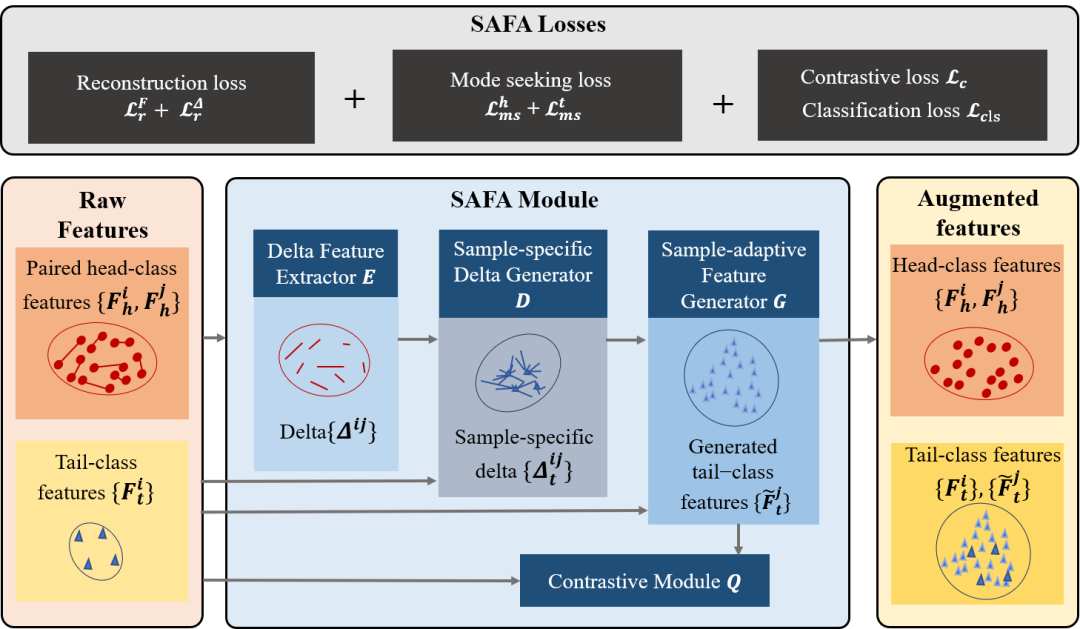
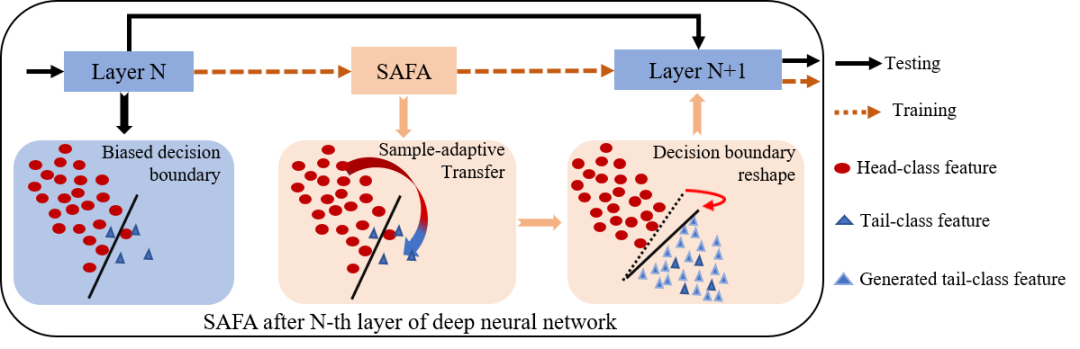
本文提出一种基于迁移的特征增广算法,针对长尾分布图片,从头部类别提取多样的语义特征信息,并自适应地应用到尾部类别特征上,有效地扩充尾部类别的特征空间用到尾部类别特征上,有效地扩充尾部类别的特征空间。
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看