文章目录
神经网络是什么?
神经网络是机器学习中的一种模型,是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
神经网络结构图
一个经典的神经网络,一般包含三个层次的神经网络。红色的是输入层,绿色的是输出层,紫色的是中间层(也叫隐藏层)。输入层有3个输入单元,隐藏层有4个单元,输出层有2个单元。

几点说明:
- 设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定;
- 神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别;
- 结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。
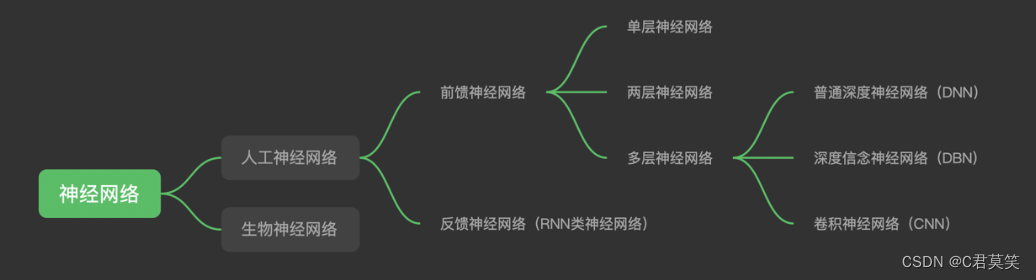
神经网络的分类
- 前馈神经网络:在网络中,当前层的输入只依赖于前一层的节点输出,与更早的网络输出状态无关;
- 反馈神经网络:将输出经过一步时移再接入到输入层,输入不仅仅取决于上一层节点的输出
深度学习、神经网络
- 深度学习的概念源于人工神经网络的研究,但是并不完全等于传统神经网络。
- 不过在叫法上,很多深度学习算法中都会包含”神经网络”这个词,比如:卷积神经网络、循环神经网络。
- 所以,深度学习可以说是在传统神经网络基础上的升级,约等于神经网络。
传统机器学习 VS 深度学习
传统机器学习和深度学习的相似点
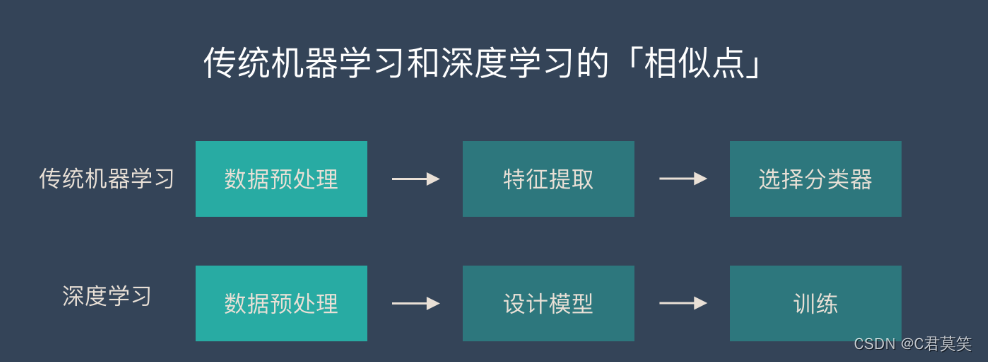
在数据准备和预处理方面,两者是很相似的。
他们都可能对数据进行一些操作:
- 数据清洗
- 数据标签
- 归一化
- 去噪
- 降维
传统机器学习和深度学习的核心区别
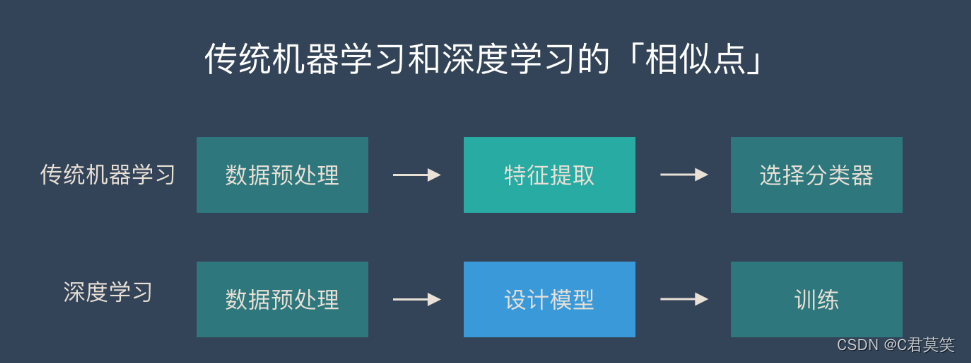
传统机器学习的特征提取主要依赖人工,针对特定简单任务的时候人工提取特征会简单有效,但是并不能通用。
深度学习的特征提取并不依靠人工,而是机器自动提取的。这也是为什么大家都说深度学习的可解释性很差,因为有时候深度学习虽然能有好的表现,但是我们并不知道他的原理是什么。
深度学习的优缺点

人工神经网络学习导图

实战一、搭建一个最简单的神经网络模型
构建一个最简单的神经网络对小D今天是否去爬山做个预测
1.去不去爬山?
为了能说清楚神经网络的本质和实际意义,我们首先引入生活中的一个场景——去不去爬山?
小A、小B、小C、小D是登山爱好者,经常相约一起去爬山。我们用数字“1”表示去爬山了,数字“0”表示没去爬山,前五次的结果如下表:

今天四个人又相约去爬山,结果如下:

现在我们根据上面的几组数据找一下规律,预测下小D今天去不去爬山呢?
我们可能已经发现了,小D是不是喜欢小B呢?因为每次小B去,小D也会去。今天小B决定去爬山,所以我们预测小D也会去爬山。刚刚我们动用了1000亿个神经元的人脑神经网络对上述问题进行信息收集、处理和计算,最终得到小D会去爬山的结果,待会我们用只有一个神经元的人工神经网络对上述问题进行预测。
核心源码
构建一个最简单的神经网络对小D今天是否去爬山做个预测。
from numpy import array,exp,random,dot
#创建数据
X = array([[0,1,0],[1,1,0],[1,0,1],[0,0,1],[0,1,1]])
y = array([[1,1,0,0,1]]).T
#初始假设
random.seed(1)
weights = 2 * random.random((3,1))-1
#神经元计算
for it in range(100000):
output = 1/(1+exp(-dot(X,weights)))
error = y - output
delta = error * output *(1-output)
weights += dot(X.T,delta)
#运行结果
print("误差为:\n",error)
print("相关系数为:\n",weights)
climbing_probability = 1/(1+exp(-dot([[0,1,0]],weights)))
print("小D会去爬山的概率为:\n",climbing_probability)

可以看出小D去不去爬山与小A去不去爬山的相关系数为-1.5662,与小B去不去爬山的相关系数为11.31693,与小C去不去爬山的相关系数为-5.56755,小D今天(第六次)去爬山的概率为0.999。
实战二、搭建BP神经网络实现手写数字识别
BP(back propagation)神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,是应用最广泛的一种神经网络。BP神经网络算法的基本思想是学习过程由信号正向传播和误差反向传播两个过程组成。
手写数字数据集介绍
我用的手写数字数据集是sklearn.datasets中的一个数据集,使用load_digits()命令就可以载入数据集,数据集包含了1797个样本,也就是有1797张手写数字的图片,每个样本包含了64个特征,实际上每个样本就是一张8x8的图片,对应着0-9中的一个数字。看一下第一个样本长什么样子:
from matplotlib import pyplot as plt
from sklearn.datasets import load_digits
# 载入数据集
digits = load_digits()
# 展示第一张图片,
plt.imshow(digits.images[0])
plt.show()

从结果也可以看出,是一张8x8的图片,这张图片显实的应该是数字0。
网络搭建背景
搭建的是一个2层的神经网络,包含一个输入层(注意:输入层一般不计入网络的层数里面),一个隐藏层和一个输出层。由于每个样本包含64个特征,所以输入层设置了64个神经元,输出层设置了10个神经元,因为我将标签进行了独热化处理(样本有10种标签,独热化处理就会将每种标签转化成一个只包含0和1,长度为10的数组,例如:数字0的标签就为[1,0,0,0,0,0,0,0,0,0],数字1的标签为[0,1,0,0,0,0,0,0,0,0],数字2的标签为[0,0,1,0,0,0,0,0,0,0],以此类推),隐藏层的神经元数量可以随便设置,我设置的是100个神经元。对于神经网络的输出,也是一个长度为10的数组,只需要取出数组中最大数字对应的索引,即为预测的结果(例如:输出为[1,0,0,0,0,0,0,0,0,0],最大数字的索引为0,即预测结果为0;输出为[0,0,0,0,0,0,0,0,0,1],最大数字对应的索引为9,即预测结果为9)。网络中使用的激活函数为sigmoid函数。
核心源码
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import load_digits
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
class NeuralNetwork:
def __init__(self, layers):
# 初始化隐藏层权值
self.w1 = np.random.random([layers[0], layers[1]]) * 2 - 1
# 初始化输出层权值
self.w2 = np.random.random([layers[1], layers[2]]) * 2 - 1
# 初始化隐藏层的偏置值
self.b1 = np.zeros([layers[1]])
# 初始化输出层的偏置值
self.b2 = np.zeros([layers[2]])
# 定义激活函数
@staticmethod
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 定义激活函数的导函数
@staticmethod
def dsigmoid(x):
return x * (1 - x)
def train(self, x_data, y_data, lr=0.1, batch=50):
"""
模型的训练函数
:param x_data: 训练数据的特征
:param y_data: 训练数据的标签
:param lr: 学习率
:param batch: 每次要训练的样本数量
:return:
"""
# 随机选择一定批次的数据进行训练
index = np.random.randint(0, x_data.shape[0], batch)
x = x_data[index]
t = y_data[index]
# 计算隐藏层的输出
l1 = self.sigmoid(np.dot(x, self.w1) + self.b1)
# 计算输出层的输出
l2 = self.sigmoid(np.dot(l1, self.w2) + self.b2)
# 计算输出层的学习信号
delta_l2 = (t - l2) * self.dsigmoid(l2)
# 计算隐藏层的学习信号
delta_l1 = delta_l2.dot(self.w2.T) * self.dsigmoid(l1)
# 计算隐藏层的权值变化
delta_w1 = lr * x.T.dot(delta_l1) / x.shape[0]
# 计算输出层的权值变化
delta_w2 = lr * l1.T.dot(delta_l2) / x.shape[0]
# 改变权值
self.w1 += delta_w1
self.w2 += delta_w2
# 改变偏置值
self.b1 += lr * np.mean(delta_l1, axis=0)
self.b2 += lr * np.mean(delta_l2, axis=0)
def predict(self, x):
"""
模型的预测函数
:param x: 测试数据的特征
:return: 返回一个包含10个0-1之间数字的numpy.array对象
"""
l1 = self.sigmoid(np.dot(x, self.w1) + self.b1)
l2 = self.sigmoid(np.dot(l1, self.w2) + self.b2)
return l2
# 载入数据集
digits = load_digits()
X = digits.data
T = digits.target
# 数据归一化
X = (X - X.min()) / (X.max() - X.min())
# 将数据拆分成训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, T)
# 将训练数据标签化为独热编码
labels = LabelBinarizer().fit_transform(y_train)
# 定义一个2层的网络模型:64-100-10
nn = NeuralNetwork([64, 100, 10])
# 训练周期
epoch = 20001
# 测试周期
test = 400
# 用来保存测试时产生的代价函数的值
loss = []
# 用来保存测试过程中的准确率
accuracy = []
for n in range(epoch):
nn.train(x_train, labels)
# 每训练一定的次数后,进行一次测试
if n % test == 0:
# 用测试集测试模型,返回结果为独热编码的标签
predictions = nn.predict(x_test)
# 取返回结果最大值的索引,即为预测数据
y2 = np.argmax(predictions, axis=1)
# np.equal用来比较数据是否相等,相等返回True,不相等返回False
# 比较的结果求平均值,即为模型的准确率
acc = np.mean(np.equal(y_test, y2))
# 计算代价函数
cost = np.mean(np.square(y_test - y2) / 2)
# 将准确率添加到列表
accuracy.append(acc)
# 将代价函数添加到列表
loss.append(cost)
print('epoch:', n, 'accuracy:', acc, 'loss:', loss)
# 训练完成之后,使用测试数据对模型进行测试
pred = nn.predict(x_test)
y_pred = np.argmax(pred, axis=1)
# 查看模型预测结果与真实标签之间的报告
print(classification_report(y_test, y_pred))
# 查看模型预测结果与真实标签之间的混淆矩阵
print(confusion_matrix(y_test, y_pred))
plt.subplot(2, 1, 1)
plt.plot(range(0, epoch, test), loss)
plt.ylabel('loss')
plt.subplot(2, 1, 2)
plt.plot(range(0, epoch, test), accuracy)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
执行以上代码,可以看到代价函数和预测准确率随着模型的训练周期的变化,随着模型训练次数的增加,代价函数逐渐减小,然后趋于稳定,而准确率则是逐渐的增加,最后稳定在95%左右,画出图像如下图所示:
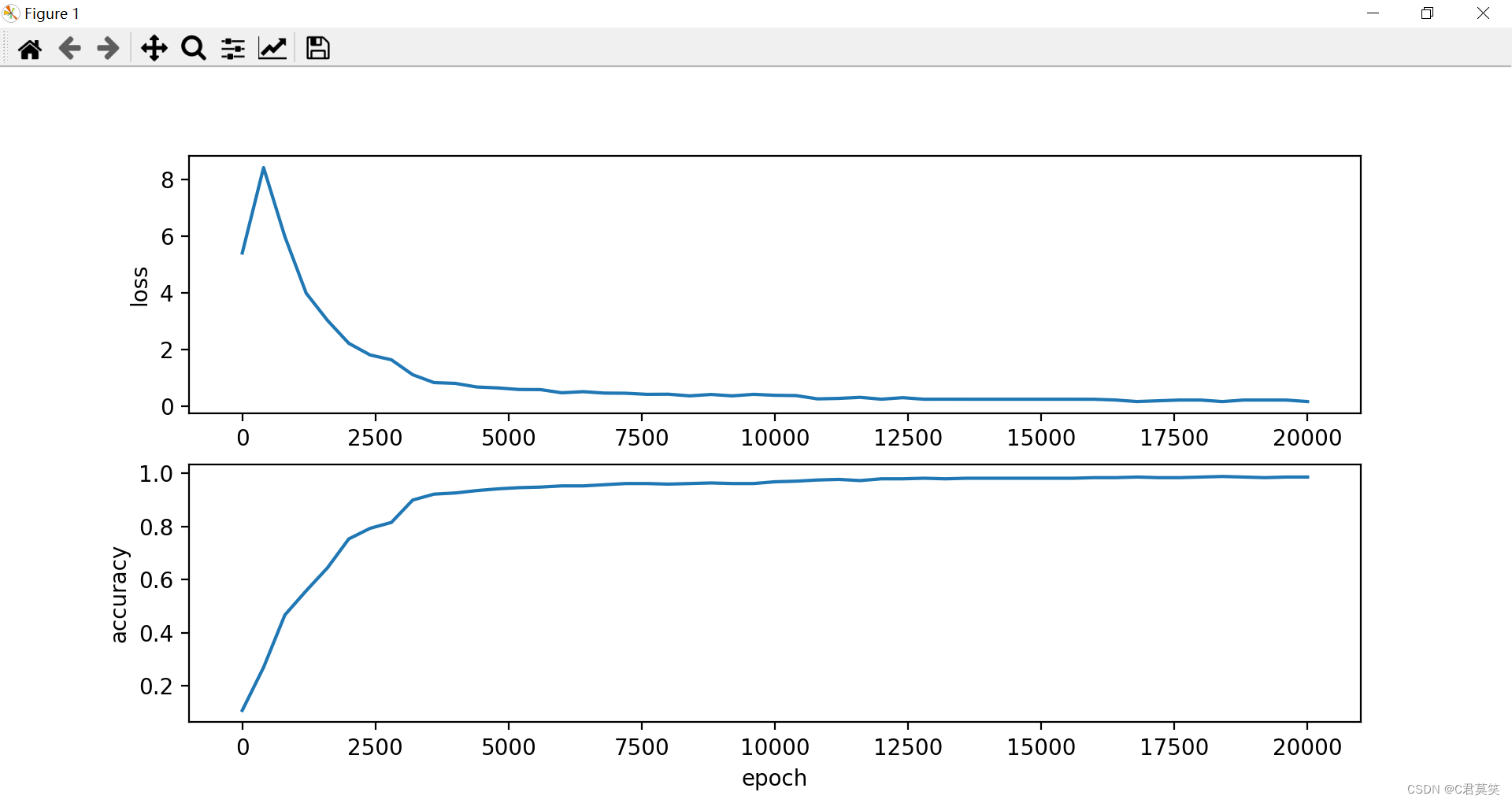
经过200001次的训练之后,模型的准确率会稳定在95%左右,对于这个数据集来说,应该可以算是还不错的模型了。