关注作者,持续阅读作者的文章,学习更多知识!
https://blog.csdn.net/weixin_53306029?spm=1001.2014.3001.5343
一、列表
列表(list)是Python中的一种数据结构,它可以存储不同类型的数据。不同元素以逗号分隔。
eg:
A = [1,'zhangsan','a', [2, 'b']]
列表使用规则
1.使用方括号[]表示开始和结束。
2.不同元素以逗号分隔。
3.每个元素的排列是有序号的,元素相同但排列不同的列表属于不同的列表。
4.列表索引是从0开始的,我们可以通过下标索引的方式来访问列表中的值。
//下标索引访问
A = ['xiaoWang', 'xiaoZhang', 'xiaoHua']
print(A[0])
print(A[1])
列表的循环遍历
1.使用for循环遍历列表
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
for name in namesList:
print(name)
2.使用while循环遍历列表
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
length = len(namesList)
i = 0
while i<length:
print(namesList[i])
i+=1
列表的增删改查
1.在列表中增加元素
在列表中增加元素的方式有多种,具体如下:
通过append可以向列表添加元素
通过extend可以将另一个列表的元素添加到列表中。
通过insert在指定位置index前插入元素object。
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
namesList.append('xiaoLiu')
print(namesList)
namesList2 = ['ximen','xiahou']
namesList.extend(namesList2)
print(namesList)
namesList.insert(2,'huangfu')
print(namesList)
2.在列表中查找元素
在列表中查找元素的方法包括:
- in(存在),如果存在那么结果为true,否则为false。
- not in(不存在),如果不存在那么结果为true,否则false。
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
print('xiaowang' in namesList)
print('xiaowang' not in namesList)
3.在列表中修改元素
列表元素的修改,也是通过下标来实现的:
nameList = ['xiaoWang','xiaoZhang','xiaoHua']
nameList[1] = 'xiaoLu'
print(nameList)
4.在列表中删除元素
列表元素的常用删除方法有三种,具体如下:
del:根据下标进行删除(例:del l[0])
pop:删除最后一个元素(例:l.pop())
remove:根据元素的值进行删除(例:l.remove('xiaoWang'))
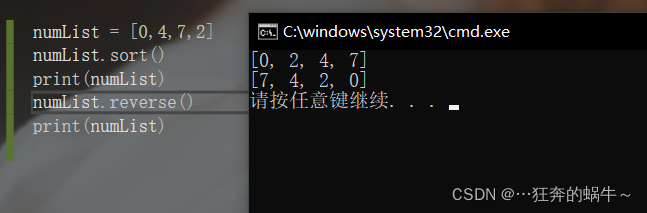
列表的排序操作
列表的排序可以通过下面两个方法实现:
- sort方法:列表的元素按照特定顺序排列(默认升序)。
- reverse方法:将列表逆置。
列表的运算符操作
+:将两个列表中的元素合并在一起产生一个新的列表。(相当于extend函数)

例:
print([1, 2, 3] + ['a', 'b', 'c'])
>>> [1, 2, 3, 'a', 'b', 'c']
*:将列表中的元素重复N次,产生一个新的列表
例:
print([1, 2, 3] * 3)
>>>[1, 2, 3, 1, 2, 3, 1, 2, 3]
==,<,>:比较运算符与字符串比较大小相似
例:
list1 = [1, 2, 3]
list2 = [1, 2, 3]
print(list1 == list2) # True
print(list1 == [1, 3, 2]) # False(顺序不对)
in 和 not in:判断列表中是否存在指定的元素
例:
print(1 in [1, 2, 3]) #True
print([1, 2] in [1, 2, 3]) # False
列表的嵌套
列表的嵌套指的是一个列表的元素又是一个列表。
schoolNames = [['北京大学','清华大学'],
['南开大学','天津大学','天津师范大学'],
['山东大学','中国海洋大学']]
二、元组
Python的元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。
tup1 = ('physics', 'chemistry', 1997, 2000)
tup2 = (1, 2, 3, 4, 5 )
写法2:(不建议)
tup3 = "a", "b", "c", "d"
元组使用规则
1.使用圆括号()表示开始和结束。
2.不同元素以逗号分隔。
3.每个元素的排列是有序号的,元素相同但排列不同的元组属于不同的元组。
4.元组可以使用下标索引来访问元组中的值 。
5.元组不允许修改元组。
tup1 = (12, 34.56)
# 以下修改元组元素操作是非法的。
tup1[0] = 100
元组的遍历
a_tuple = (1, 2, 3, 4, 5)
for num in a_tuple:
print(num,end=" ") #end指定结尾符,默认回车
a_tuple = (1, 2, 3, 4, 5)
i = 0
while i < len(a_tuple):
print(a_tuple[i],end=" ")
i += 1
元组的内置函数

元组的运算符操作
+:将两个元组中的元素合并在一起产生一个新的元组。(和列表相同)
*:将元组中的元素重复N次,产生一个新的元组
print((1, 2, 3) +(4, 5, 6))
print((1, 2, 3) * 3)
#(1, 2, 3, 4, 5, 6)
# (1, 2, 3, 1, 2, 3, 1, 2, 3)
三、字典
字典是一种存储数据的容器,它和列表一样,都可以存储多个数据。
每个元素都是由两部分组成的,分别是键和值。
info = {
'name':'张三', 'sex':'f', 'address':'北京'}
#‘name’为键,‘张三’为值。
字典使用规则:
1.使用花括号{}表示开始和结束,并且每个元素是以key:value方式成对出现。
2.不同元素以逗号分隔。
3.每个元素的排列是无序的,元素相同但排列不同的字典属于相同的字典。
4.根据键访问值。(注意:如果使用的是不存在的键,则程序会报错。)
info = {
'name':'班长', 'id':100, 'sex':'f', 'address':'北京'}
print(info['name'])
print(info['address'])
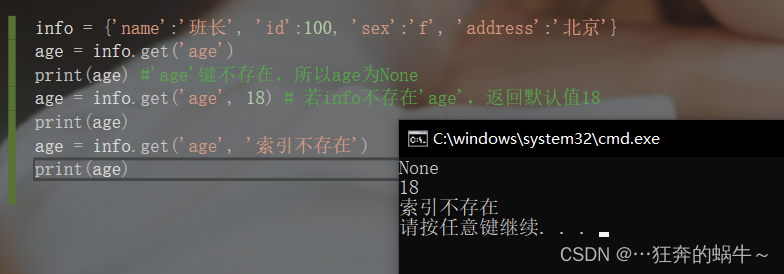
如果我们不确定字典中是否存在某个键而又想获取其值时,可以使用get方法,还可以设置默认值。
info = {
'name':'班长', 'id':100, 'sex':'f', 'address':'北京'}
age = info.get('age')
print(age) #'age'键不存在,所以age为None
age = info.get('age', 18) # 若info不存在'age',返回默认值18
print(age)
age = info.get('age', '索引不存在')
print(age)
字典的增删改
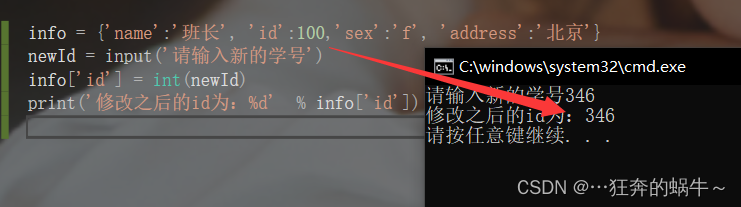
修改字典的元素
info = {
'name':'班长', 'id':100,'sex':'f', 'address':'北京'}
newId = input('请输入新的学号')
info['id'] = int(newId)
print('修改之后的id为:%d' % info['id'])
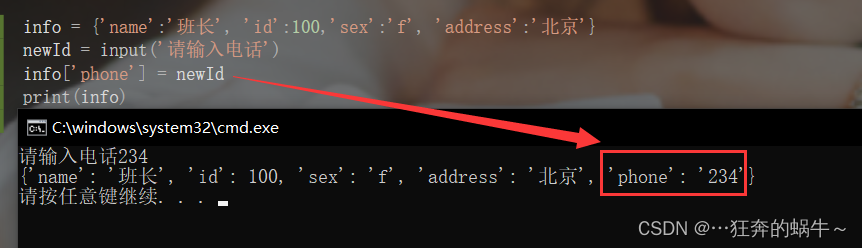
添加新的字典元素
法1:
info = {
'name':'班长', 'id':100,'sex':'f', 'address':'北京'}
newId = input('请输入电话')
info['phone'] = newId
print(info)
法2:
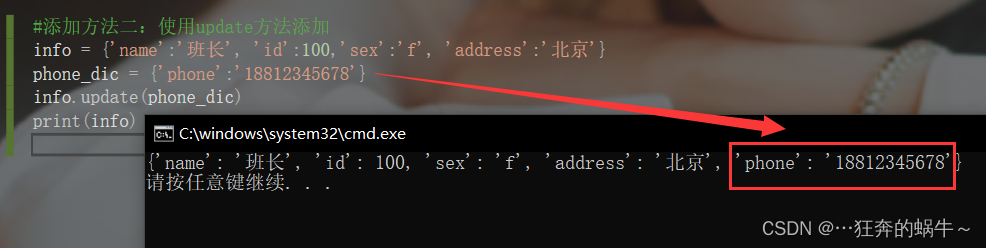
#添加方法二:使用update方法添加
info = {
'name':'班长', 'id':100,'sex':'f', 'address':'北京'}
phone_dic = {
'phone':'18812345678'}
info.update(phone_dic)
print(info)
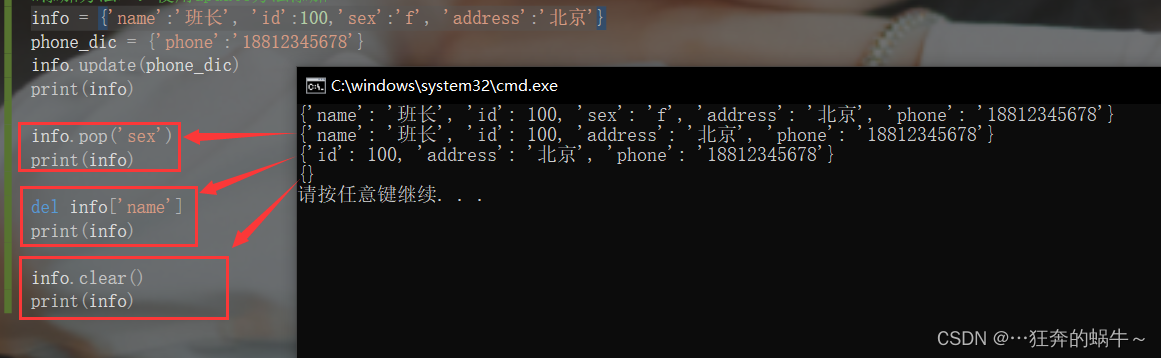
删除字典元素
-
del:可删除字典中元素或者删除字典;删除字典后,字典完全不存在了,无法再根据键访问字典的值。
del info['sex'], del info; -
pop:删除元素并返回value值。
info.pop('sex') -
clear:只是清空字典中的数据,字典还存在,只不过没有元素。
info.clear()
计算字典中键值对的个数
dicts = {
'Name': 'Zara', 'Age': 7}
print("Length : %d" % len (dicts))

获取字典中键的列表
keys()方法返回在字典中的所有可用的键,可通过list(dict.keys())方式转换为列表。
dicts = {
'Name': 'Zara', 'Age': 7}
print(dicts.keys())
print(list(dicts.keys())) #可转换为list类型

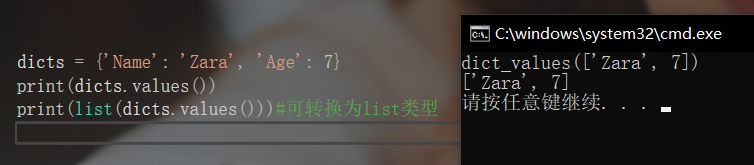
获取字典中值的列表
values()方法返回在字典中的所有可用的值,同样可通过list()转化为列表
dicts = {
'Name': 'Zara', 'Age': 7}
print(dicts.values())
print(list(dicts.values()))#可转换为list类型
计算字典中键值对的个数
items()方法返回字典的(键,值)元组对的列表
dicts= {
'Name': 'Zara', 'Age': 7}
print("Value : %s" % dicts.items())
print(type(list( dicts.items())[0]))
#查看第0个item的类型

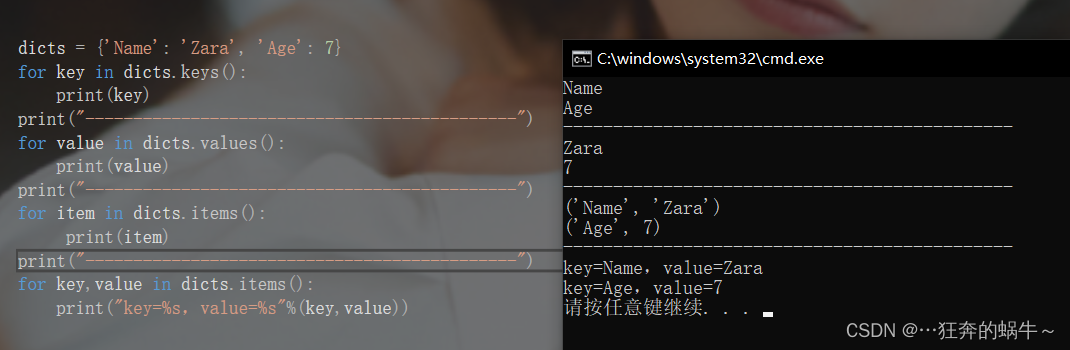
字典的遍历
1.遍历字典的键key(直接遍历,不必转换为list)
dicts = {
'Name': 'Zara', 'Age': 7}
for key in dicts.keys():
print(key)
2. 遍历字典的值value(不必转换为list)
dicts = {
'Name': 'Zara', 'Age': 7}
for value in dicts.values():
print(value)
3. 遍历字典的元素
dicts = {
'Name': 'Zara', 'Age': 7}
for item in dicts.items():
print(item)
4. 遍历字典的键值对
dicts = {
'Name': 'Zara', 'Age': 7}
for key,value in dicts.items():
print("key=%s,value=%s"%(key,value))
集合
集合(set)是一个无序的不重复元素序列。对应于数学中集合的概念。
basket = {
'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
letters = set(['apple', 'orange', 'apple', 'pear', 'orange', 'banana'])
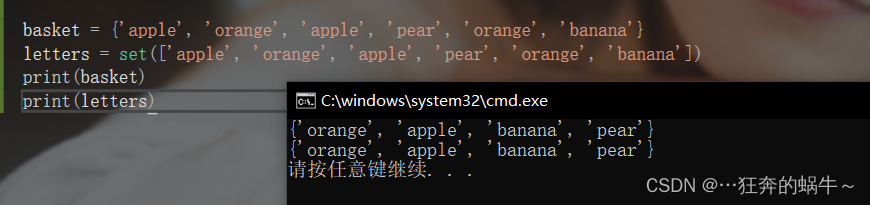
可以使用大括号 { } 或者 set() 函数创建集合;
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
集合使用规则:
- 1.使用花括号{}表示开始和结束,并且每个元素是以单个元素方式出现。
- 2.不同元素以逗号分隔。
- 3.每个元素的排列是无序的,元素相同但排列不同的集合属于相同的集合。
- 4.集合中若有重复元素,会自动删除重复值,不会报错。
集合常见操作1
添加元素
thisset = {
"Google", "Runoob", "Taobao"}
thisset.add("Facebook")
print(thisset)
合并
thisset = {
"Google", "Runoob", "Taobao"}
newset = {
'HUAWEI','Alibaba'}
thisset.update(newset)
print(thisset)
删除元素
thisset = {
"Runoob", "Taobao"}
thisset.remove("Google") #删除没有的元素会报错
print(thisset)
thisset.discard("Google")#删除没有的元素不会报错
print(thisset)
thisset.clear()
随机删除
thisset = {
"Google", "Runoob", "Taobao"}
print(thisset) #可以发现每次输出的元素顺序不同
print(thisset.pop())
# 实际每次删除的是前边第一个元素,而集合的排列每次是随机的,所以相当于随机删除一个元素
集合的常见操作2
1.集合的交集s1 & s2,s1.intersection(s2)
2.集合的并集s1 | s2,s1.union(s2)
3.集合的差集 s1 - s2, s1.difference(s2) ,从集合s1里去掉和s2交集的部分
4.集合的交叉补集 s1 ^ s2, s1.symmetric_difference(s2) 从s1和s2并集里去掉交集的部分
使用函数不改变原集合
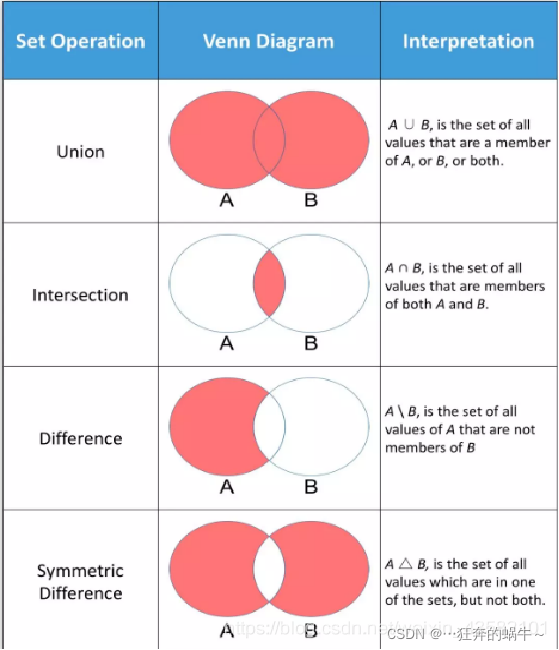
- S - T 返回一个新集合,包括在集合S但不在T中的元素
- S ^ T 返回一个新集合, 包括集合S和T中不相同元素
- S <= T 或 S < T 返回True/False, 判断S是否为T的子集、真子集(如果A包含B,且A不等于B,就说集合B是集合A的真子集。)
- S >= T 或 S > T 返回True/False, 判断S是否包含子集T、真子集T
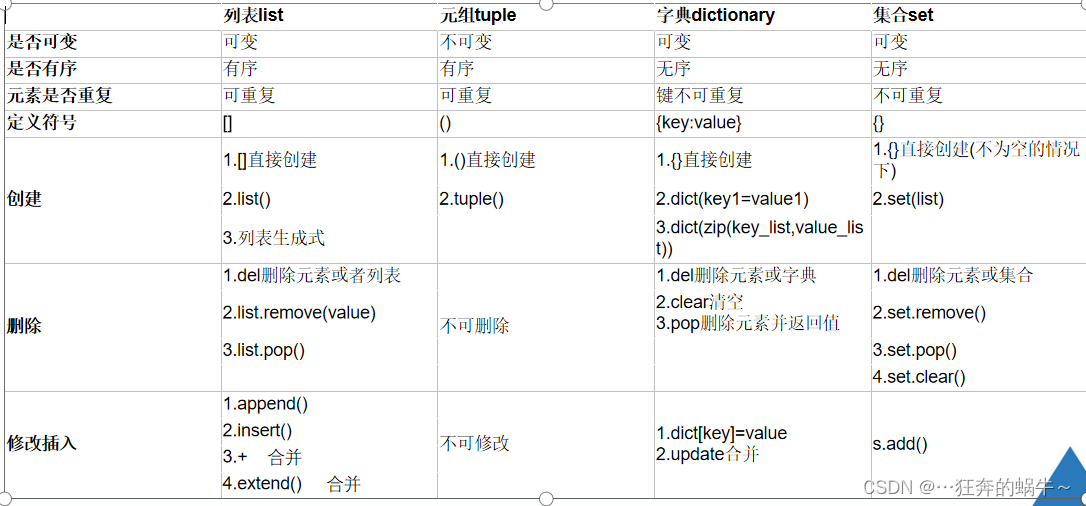
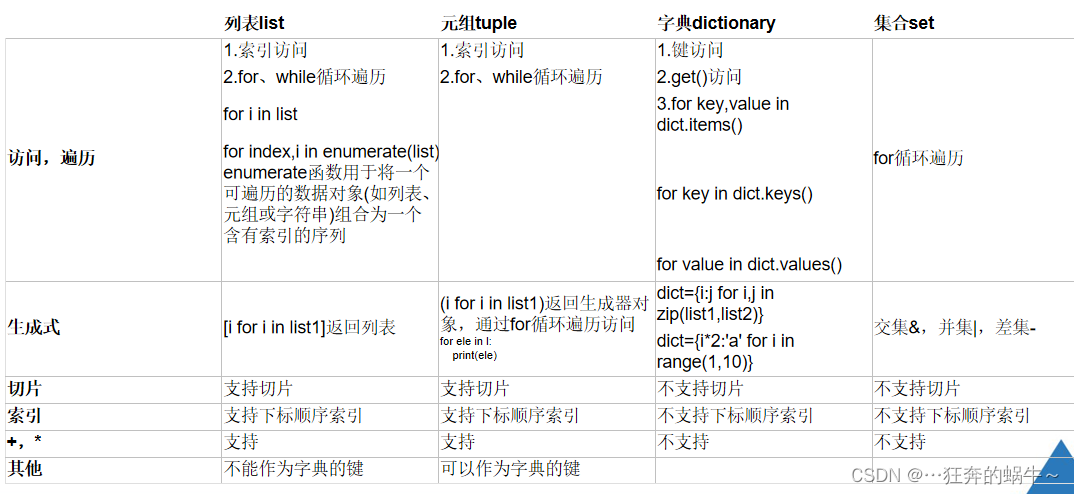
列表、元组、字典、集合对比
拓展:zip函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组。
1.如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同
2.利用 * 号操作符,可以将元组解压为列表。
a, b, c = [1,2,3], [4,5,6], [4,5,6,7,8]
zipped = list(zip(a,b)) # 打包为元组的列表
>>>[(1, 4), (2, 5), (3, 6)]
list(zip(a,c)) # 元素个数与最短的列表一致
>>>[(1, 4), (2, 5), (3, 6)]
zipped = zip(a,c)
print(*zipped)
>>>(1, 4) (2, 5) (3, 6)