Facebook 是全球最大的社交平台,可以将全球各地的用户紧密联系到一起。为了让用户不受地域、语言等条件限制,Facebook 母公司 Meta 近日宣布其 NLLB(No Language Left Behind)项目取得了突破,能为世界上大多数语言开发出高质量的机器翻译。

该 AI 模型名为 NLLB-200,可以翻译超过 200 种不同的语言。为了评估新模型的输出质量,Meta 创建了一个测试数据集,包括该模型所涵盖的每种语言的 3001 个句子对,每个句子都由专业翻译和母语人士从英语翻译成目标语言。
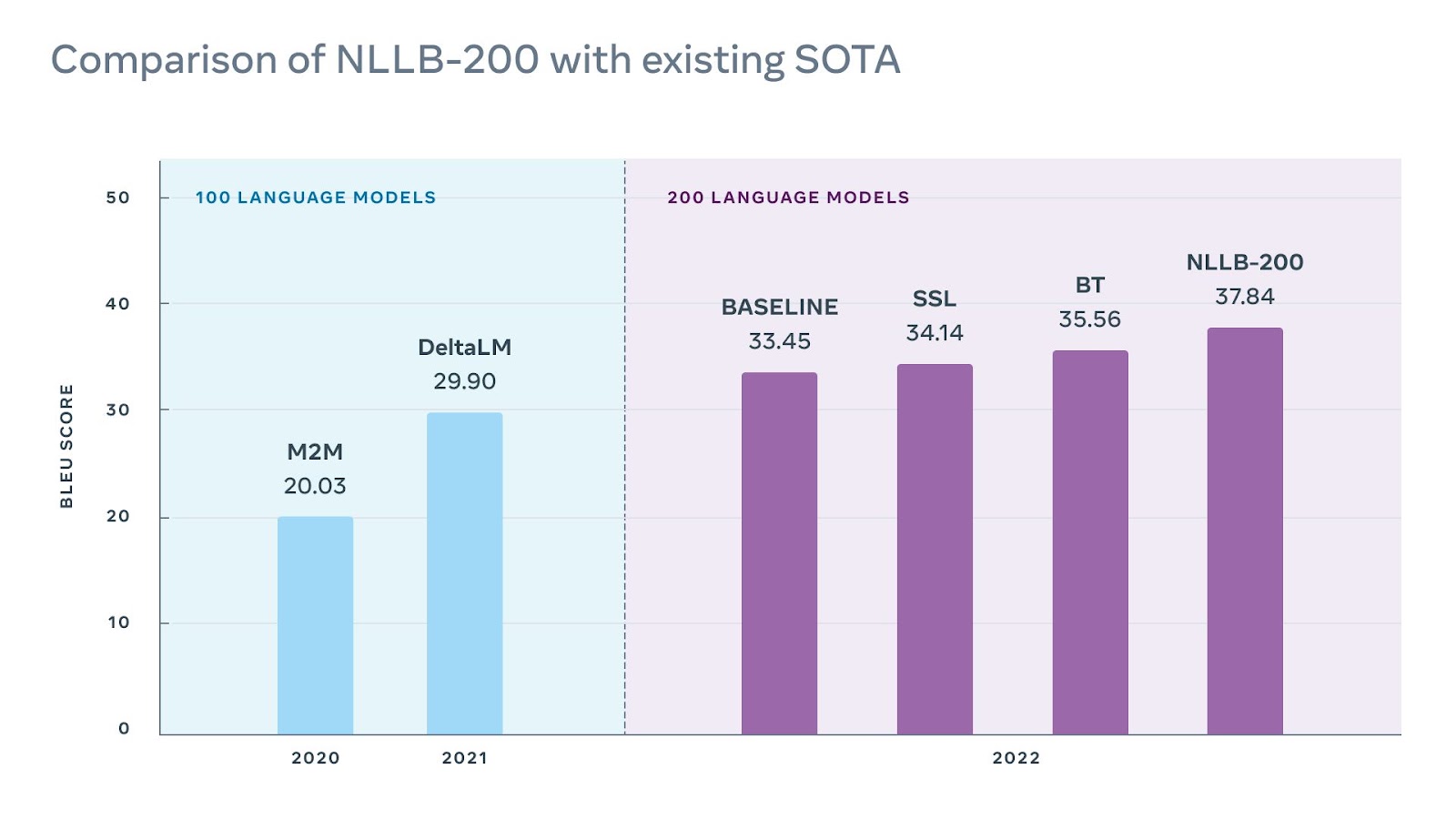
研究人员通过他们的模型运行这些句子,并使用机器翻译中常见的 BLEU 基准将机器翻译与人类翻译的参考句子进行比较。测试表明,新的 NLLB-200 模型在支持的语言中获得了平均 44% 的 BLEU 分数的提升,在针对某些非洲和印度方言的测试中甚至提升了 70%。
目前全球范围内一共有数千种不同的语言,但由于语言数据的匮乏导致如今的翻译技术仍然有很多不足之处。以大家熟知的 Google 翻译为例,它目前能够翻译的语言数量仅限于 133 种;而微软的必应翻译支持的语言比 Google 翻译更少。
虽说这些翻译工具支持的语言只有 100 多种,再加上全世界一半以上的人口所使用的语言就那么十几二十种,翻译工具是能够满足大部分用户的使用需求的,但这对那些使用低资源语言(特别是在非洲)的用户来说就十分不友好,导致这些语言的使用者和他们希望消费的内容之间的交流受到了阻碍。
马克·扎克伯格表示:
我们刚刚开源了一个我们建立的 AI 模型,它可以翻译 200 种不同的语言,其中有许多语言还是目前不被其他翻译系统所支持的。我们把这个项目称为 "No Language Left Behind",我们使用的 AI 建模技术能够为全世界数十亿人使用的语言构建出高质量的翻译。
尽管在技术上取得了突破,但 Meta 公司认为如果没有创新的合作,实现 NLLB 项目的目标将是不可能完成的。为了使其他研究人员能够扩大语言范围,建立更多的包容性技术,Meta 将 NLLB-200 模型开源了,与此同时还向非营利组织提供了高达 20 万美元的资助,以便将 NLLB-200 应用于他们的业务。
维基媒体基金会目前已在 Content Translation 工具中引入了 NLLB-200 模型背后的技术,维基百科的编辑们可以使用该技术更有效地翻译和编辑源自其他代表性不足的语言的文章,这有助于使全世界的维基百科读者以更多的语言获得更多的知识。
NLLB-200 技术演示地址:https://nllb.metademolab.com/