
作者:石臻臻, CSDN博客之星Top5、Kafka Contributor 、nacos Contributor、华为云 MVP ,腾讯云TVP, 滴滴Kafka技术专家 、 LogiKM PMC(改名KnowStream)。
LogiKM(改名KnowStreaming) 是滴滴开源的Kafka运维管控平台, 有兴趣一起参与参与开发的同学,但是怕自己能力不够的同学,可以联系我,当你导师带你参与开源! 。
目录
随着人工智能技术快速发展,这两年涌现出了许多运行在终端的推理框架,给开发者带来更多选择,但也同时增加了将 AI 布署到终端的成本。除了要做推理框架选型,还需要关注数据预/后处理逻辑的稳定性,模型分发使用时的包大小、数据安全等问题。本文将带着这些常见的AI终端侧落地的问题,讲解AoE背后的设计初衷和思路。
背景
AoE是什么

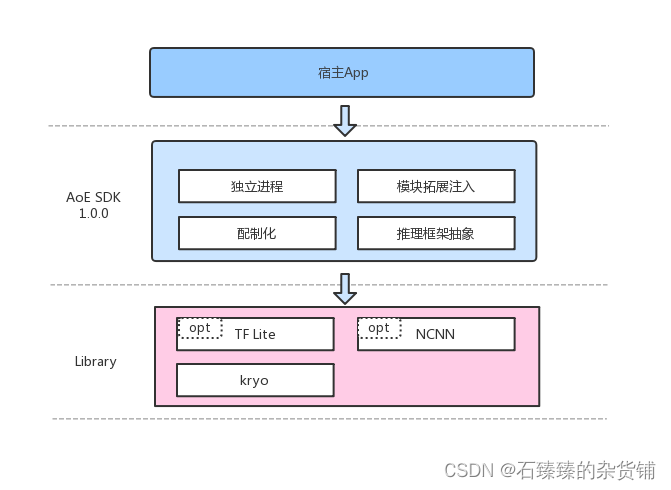
AoE (AI on Edge) 是一个滴滴开源的终端侧AI集成运行时环境(IRE)。以 “稳定性、易用性、安全性” 为设计原则,帮助开发者将不同框架的深度学习算法轻松部署到终端高效执行。
Github 地址是 https://github.com/didi/aoe。
为什么要做一个 AI 终端集成运行时框架,原因有两个:
一是随着人工智能技术快速发展,这两年涌现出了许多运行在终端的推理框架,在给开发者带来更多选择的同时,也增加了将AI布署到终端的成本;
二是通过推理框架直接接入AI的流程比较繁琐,涉及到动态库接入、资源加载、前处理、后处理、资源释放、模型升级,以及如何保障稳定性等问题。
目前AoE SDK已经在滴滴银行卡OCR上应用使用,想更加清晰地理解 AoE 和推理框架、宿主 App 的关系,可以通过下面的业务集成示意图来了解它。
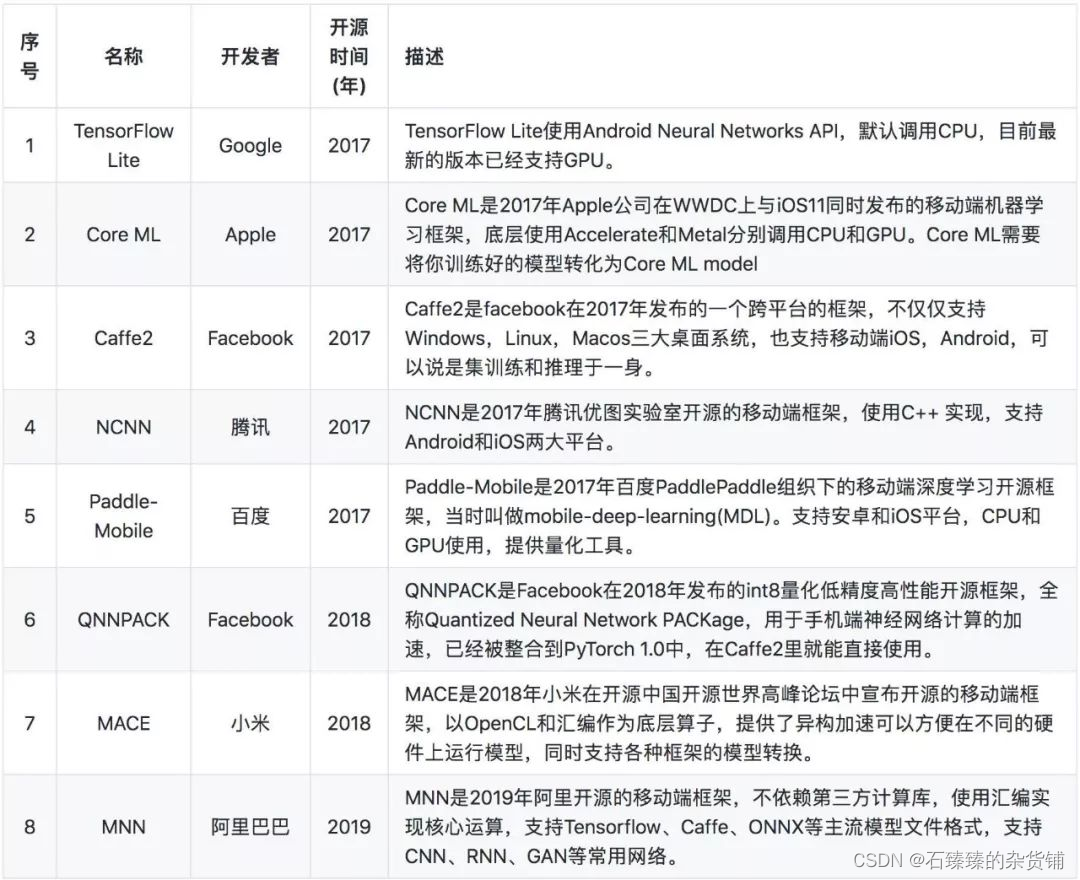
终端推理框架一览
下面是终端运行的8种主流推理框架(排名不分先后)。
AoE 如何支持各种推理框架
从本质上来说,无论是什么推理框架,都必然包含下面 5 个处理过程,对这些推理过程进行抽象,是 AoE 支持各种推理框架的基础。
目前,AoE 实现了两种推理框架 NCNN 和 TensorFlow Lite 的支持,以这两种推理框架为例,说明一下 5 个推理过程在各自推理框架里的形式。

AoE 支持哪些平台
目前,AoE 已经开源的运行时环境 SDK 包括 Android 和 iOS 平台,此外 Linux 平台运行时环境 SDK 正在紧锣密鼓地开发中
工作原理
抽象推理框架的处理过程
前面已经介绍了,不同推理框架包含着共性的过程,它们分别是初使化、前处理、执行推理、后处理、释放资源。对 AoE 集成运行环境来说,最基本的便是抽象推理操作,通过 依赖倒置 的设计,使得业务只依赖AoE的上层抽象,而不用关心具体推理框架的接入实现。这种设计带来的最大的好处是开发者随时可以添加新的推理框架,而不用修改框架实现,做到了业务开发和 AoE SDK 开发完全解耦。
在 AoE SDK 中这一个抽象是 InterpreterComponent(用来处理模型的初使化、执行推理和释放资源)和 Convertor(用来处理模型输入的前处理和模型输出的后处理),InterpreterComponent 具体实现如下:
/**
* 模型翻译组件
*/
interface InterpreterComponent<TInput, TOutput> extends Component {
/**
* 初始化,推理框架加载模型资源
*
* @param context 上下文,用与服务绑定
* @param modelOptions 模型配置列表
* @return 推理框架加载
*/
boolean init(@NonNull Context context, @NonNull List<AoeModelOption> modelOptions);
/**
* 执行推理操作
*
* @param input 业务输入数据
* @return 业务输出数据
*/
@Nullable
TOutput run(@NonNull TInput input);
/**
* 释放资源
*/
void release();
/**
* 模型是否正确加载完成
*
* @return true,模型正确加载
*/
boolean isReady();
}
Convertor的具体实现如下:
interface Convertor<TInput, TOutput, TModelInput, TModelOutput> {
/**
* 数据预处理,将输入数据转换成模型输入数据
*
* @param input 业务输入数据
* @return 模型输入数据
*/
@Nullable
TModelInput preProcess(@NonNull TInput input);
/**
* 数据后处理,将模型输出数据转换成业务输出数据
*
* @param modelOutput 模型输出数据
* @return
*/
@Nullable
TOutput postProcess(@Nullable TModelOutput modelOutput);
}
稳定性保障
众所周知,Android平台开发的一个重要的问题是机型适配,尤其是包含大量Native操作的场景,机型适配的问题尤其重要,一旦应用在某款机型上面崩溃,造成的体验损害是巨大的。有数据表明,因为性能问题,移动App每天流失的活跃用户占比5%,这些流失的用户,6 成的用户选择了沉默,不再使用应用,3 成用户改投竞品,剩下的用户会直接卸载应用。因此,对于一个用户群庞大的移动应用来说,保证任何时候App主流程的可用性是一件最基本、最重要的事。结合 AI 推理过程来看,不可避免地,会有大量的操作发生在 Native 过程中,不仅仅是推理操作,还有一些前处理和资源回收的操作也比较容易出现兼容问题。为此,AoE 运行时环境 SDK 为 Android 平台上开发了独立进程的机制,让 Native 操作运行在独立进程中,同时保证了推理的稳定性(偶然性的崩溃不会影响后续的推理操作)和主进程的稳定性(主进程任何时候不会崩溃)。
具体实现过程主要有三个部分:注册独立进程、异常重新绑定进程以及跨进程通信优化。
第一个部分,注册独立进程,在 Manifest 中增加一个 RemoteService 组件,代码如下:
<application>
<service
android:name=".AoeProcessService"
android:exported="false"
android:process=":aoeProcessor" />
</application>
第二个部分,异常重新绑定独立进程,在推理时,如果发现 RemoteService 终止了,执行 “bindService()” 方法,重新启动 RemoteService。
@Override
public Object run(@NonNull Object input) {
if (isServiceRunning()) {
...(代码省略)//执行推理
} else {
bindService();//重启独立进程
}
return null;
}
第三个部分,跨进程通信优化,因为独立进程,必然涉及到跨进程通信,在跨进程通信里最大的问题是耗时损失,这里,有两个因素造成了耗时损失:
传输耗时
序列化/反序列化耗时
相比较使用binder机制的传输耗时,序列化/反序列化占了整个通信耗时的90%。由此可见,对序列化/反序列化的优化是跨进程通信优化的重点。
对比了当下主流的序列化/反序列化工具,最终AoE集成运行环境使用了kryo库进行序列化/反序列。以下是对比结果,数据参考oschina的文章《各种 Java 的序列化库的性能比较测试结果》。
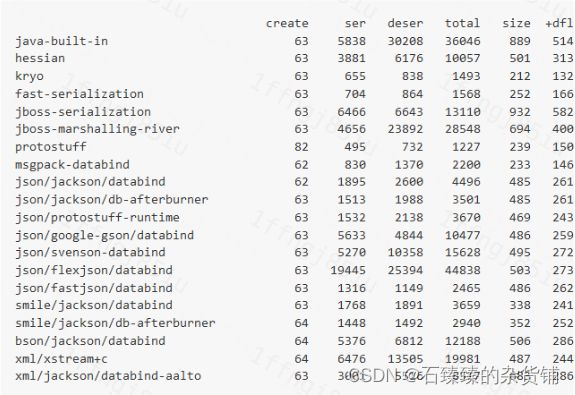
MNIST集成示例
对TensorFlowLiteInterpreter的继承
当我们要接入一个新的模型时,首先要确定的是这个模型运行在哪一个推理框架上,然后继承这个推理框架的InterpreterComponent实现,完成具体的业务流程。MNIST是运行在TF Lite框架上的模型,因此,我们实现AoE的TF Lite的Interpreter抽象类,将输入数据转成模型的输入,再从模型的输出读取业务需要的数据。初使化、推理执行和资源回收沿用TensorFlowLiteInterpreter的默认实现。
public class MnistInterpreter extends TensorFlowLiteInterpreter<float[], Integer, float[], float[][]> {
@Nullable
@Override
public float[] preProcess(@NonNull float[] input) {
return input;
}
@Nullable
@Override
public Integer postProcess(@Nullable float[][] modelOutput) {
if (modelOutput != null && modelOutput.length == 1) {
for (int i = 0; i < modelOutput[0].length; i++) {
if (Float.compare(modelOutput[0][i], 1f) == 0) {
return i;
}
}
}
return null;
}
}
运行时环境配置
接入MNIST的第二个步骤是配置推理框架类型和模型相关参数,代码如下:
mClient = new AoeClient(requireContext(), "mnist",
new AoeClient.Options()
.setInterpreter(MnistInterpreter.class)/*
.useRemoteService(false)*/,
"mnist");
推理执行
以下是MINST初使化推理框架、推理执行和资源回收的实现:
//初使化推理框架
int resultCode = mClient.init();
//推理执行
Object result = mClient.process(mSketchModel.getPixelData());
if (result instanceof Integer) {
int num = (int) result;
Log.d(TAG, "num: " + num);
mResultTextView.setText((num == -1) ? "Not recognized." : String.valueOf(num));
}
//资源回收
if (mClient != null) {
mClient.release();
}