资源下载地址:https://download.csdn.net/download/sheziqiong/85895969
资源下载地址:https://download.csdn.net/download/sheziqiong/85895969
1 背景介绍
1.1 DGA 域名简介
如今,互联网上的很多恶意攻击行为开始借助由域名生成算法生成的域名来抵抗安防软件的检测。这些域名生成算法通常会借助一组随机种子,持续不断的生成大量随机域名。使用这些 DGA 域名进行攻击的流程如图 1.1 所示。
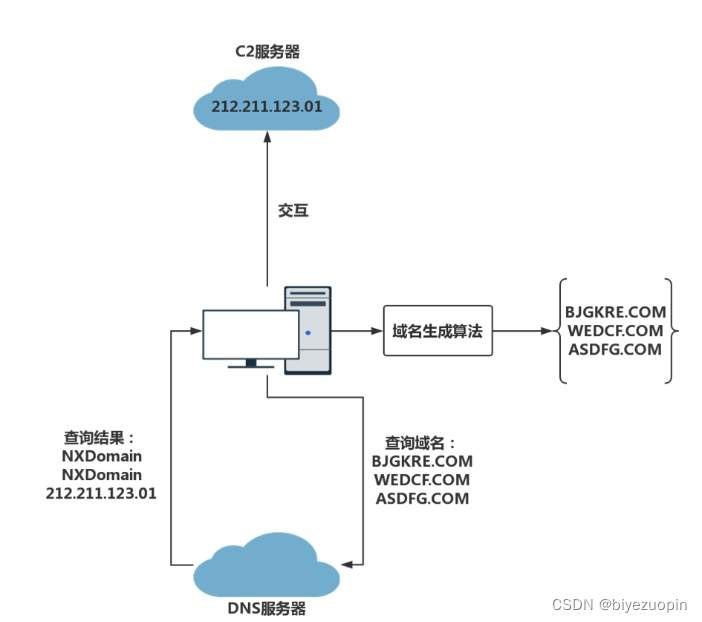
图 1.1 DGA 类攻击流程
如图 1.1 ,当某台主机或者服务器被恶意行为攻击成功之后,攻击者就会在被攻击者内部嵌入一段恶意代码。这段恶意代码会使用某种域名生成算法不断的生成 DGA 域名,并且利用被攻击者的主机去访问这些域名。同时,攻击者也会使用相同的算法生成大量 DGA 域名,并从中选取若干个进行注册。这样一来,当被攻击者成功访问某个 DGA 域名时,就说明这个域名是由攻击者注册的,比如图 1.1 中的 ASDFG.COM 这条域名。检测到这种被注册的 DGA 域名之后,嵌入到被攻击者主机内的恶意代码就会通过这条 DGA 域名查询得到的 IP 地址,与攻击者使用的 C2 服务器进行交互,使得攻击者能够持续的控制被攻击的主机并窃取数据。
1.2 传统的检测方法
DGA 域名与正常的域名相比有很多区别,传统的研究方向主要分为两种,一是对域名的字符串特征进行分析,一是对 DNS 流量上进行分析。
域名字符串分析是一种实时检测的方式,它不依赖与任何的上下文信息,只是单纯的根据域名字符串进行分析,是一种比较难的检测方式。传统的方法主要还是需要人工去设计特征,然后将这些特征输入机器学习模型。常用的字符串特征进行了汇总,包括字符串长度、元音字母与辅音字母比例、数字字符比例、字符的信息熵、字符的词频分布以及有意义的字符串占域名字符串总长度的比值,然后使用随机森林模型进行训练和判别。
这种方式存在两个比较严重的问题。首先,人工设计的特征很容易被规避,黑客很容易设计一类新的 DGA 家族规避掉已有的检测特征。其次,人工设计特征的方式非常费时费力,当有新的 DGA 家族产生时,就必须重新设计一套相应的特征。这些问题都极大的限制了域名字符串分析方式的实用性。
在 DNS 流量方面,第一步通常是对比正常域名的 DNS 流量和 DGA 域名 DNS 流量,从中找出具有区分度的特征,常见的特征有域名的访问频率、访问规律性、共享 IP、平均 TTL、NXDomain 流量等。提出特征之后,便使用随机森林、聚类等算法去训练模型,用训练好的模型去检测恶意域名。
但是,这种方法常常需要去监控整个网络,通过一段时间的信息收集整理之后才能获取到域名的各项特征,进而才能检测一个域名是否是恶意的。这种方式不仅难以实现,而且无法满足实时性的需求,无法在恶意域名出现的时刻就对其进行检测与拦截,也就无法有效的抑制恶意攻击的产生。
1.3 最新进展
2016 年,论文 Predicting domain generation algorithms with long short-term memory networks 首次实现了使用深度学习方法进行 DGA 域名检测。在数据处理方面,该论文参考自然语言处理方面的研究内容,将域名字符串转换成了词向量。在模型构建方面,该论文使用了 RNN 的变种 LSTM 模型,该模型对于处理序列输入问题有很好的效果。
使用深度学习进行 DGA 域名检测不仅节省了人工设计特征所需要的开销,同时能够对域名进行实时检测,并且在准确率和泛化性上有了质的提升,对网络安全有着重大的促进意义。
2 数据与模型
2.1 数据来源
在本实验中,正常域名来自于 Alexa 网站的域名点击排行,总共收集了 100 万个正常域名。 DGA 域名则来自于 360 网络实验室和 osint 公开的 DGA 域名种子网站,它们都属于公开的数据源。其中,从 360 网络实验室收集了 34 类不同家族的 DGA 域名,总共 136 万个 DGA 域名。从 osint 网站上收集了 44 类不同家族的 DGA 域名,总共 144 万个 DGA 域名。
2.2 数据集构造
为了增加实验结果的可信度,本实验从两个不同的来源收集了 DGA 域名。因此,也将构造两个数据集用于实验评估。
其中,第一个数据集由 100 万个正常域名加上来自于 360 网络实验室收集的 34 类不同家族的 136 万个 DGA 域名构成,第二个数据集由 100 万个正常域名加上来自于 osint 公开的 DGA 域名种子网站收集的 44 类不同家族的 144 万个 DGA 域名构成。
对于每一个数据集,为了使数据分布的更均匀些,本论文都从其中的正常域名以及每一类 DGA 家族域名中各随机抽取 80% 的域名样本作为训练集,剩下 20% 的域名样本作为测试集,总共构造了两组训练集与测试集,训练集的组成如表 2.1 所示。
表 2.1 数据集构成
| 训练集 | 测试集 | |||||
|---|---|---|---|---|---|---|
| 正常域名 | DGA 域名 | DGA 种类 | 正常域名 | DGA 域名 | DGA 种类 | |
| 360 数据集 | 800,000 个 | 1090,000 个 | 34 类 | 200,000 个 | 270,000 个 | 34 类 |
| osint 数据集 | 800,000 个 | 1150,000 个 | 44 类 | 200,000 个 | 290,000 个 | 44 类 |
2.3 数据处理
在数据处理阶段,本实验首先根据单词列表将域名字符串转换成了一维整数矩阵,这种简单的线性转换并不能很好的体现出原始域名字符串中字符之间的关联信息,这也是自然语言处理中最基本的问题之一。因此,本实验参考自然语言处理方面的处理方法,对一维矩阵进一步处理,将其转换成携带更多原始数据信息的二维词向量,最终再输入到模型中。
为了降低实验的复杂度,提高可复现性,在生成词向量的过程中,本实验没有单独设计并训练一个语言模型,然后从中获取生成词向量所需要的参数矩阵,而是借助了 Keras 库中的 Embedding 层来生成词向量。
Embedding 层的数据处理的流程如图 2.1 所示。

图 2.1 Embedding 层数据处理流程
为了方便显示,图 2.1 只简单的展示了一个 3 维整数数组转换成(3,7)的二维词向量的流程。
2.4 模型设计
在论文 Predicting domain generation algorithms with long short-term memory networks 中使用的 LSTM 网络的基础上,本实验加入最近比较流行的 Attenton 机制,以提高模型的性能。
原始 LSTM 网络的结构如图 2.2 所示,要由 LSTM 层、Dropout 层、全连接层和激活层构成。
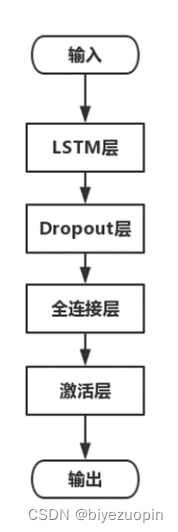
图 2.2 LSTM 网络结构
加入 Attention 机制后的网络结构如图 2.3 所示,其中 Attention 模块是权重计算模块,该模块接收 LSTM 层输出的二维特征矩阵作为输入,在模块内部经过学习计算产生一个权重矩阵,然后将输入的特征矩阵与计算得到的权重矩阵融合后输出。经过这一系列的运算处理,该模块的输出中不仅包含了词向量的特征信息,同时也包含了各个维度特征的权重信息,为后续分类模块提供了更多的参考信息。
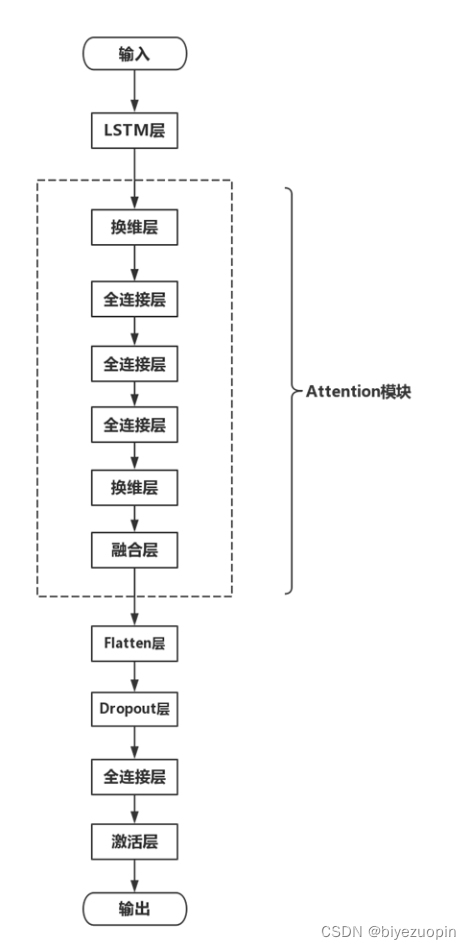
图 2.3 LSTM+Attention 网络结构
3 代码展示
本实验实验的是 Keras 框架,每部分的代码功能见注释。
3.1 Attention 模块代码
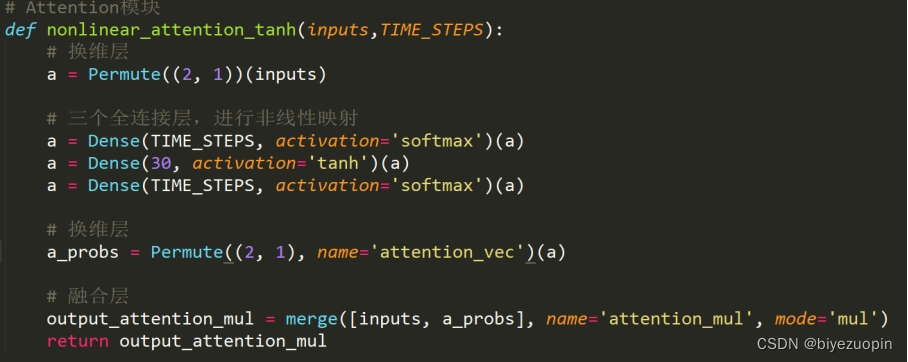
3.2 整体模型代码
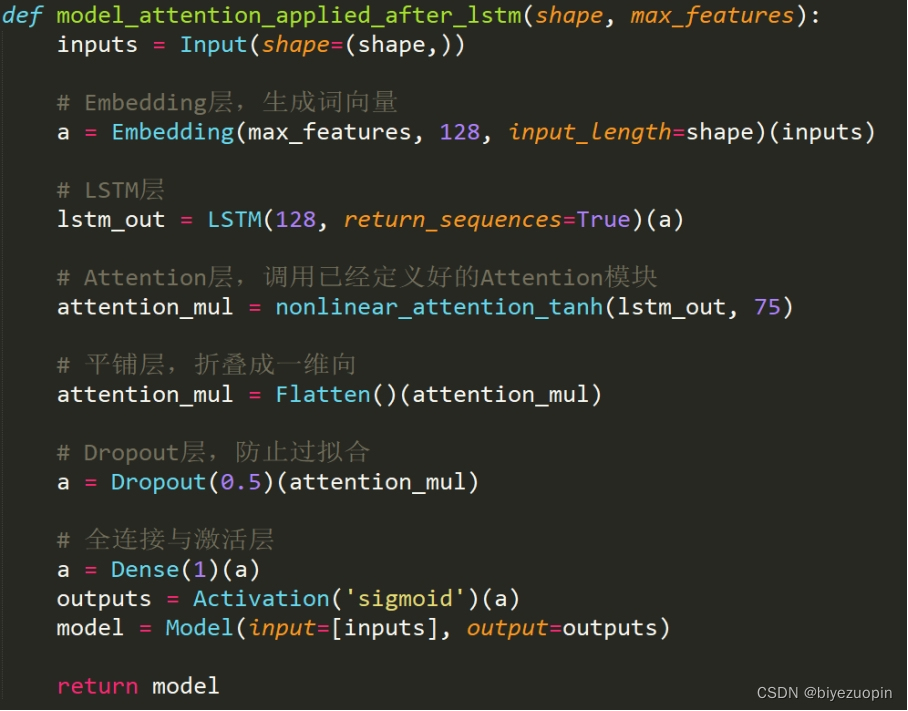
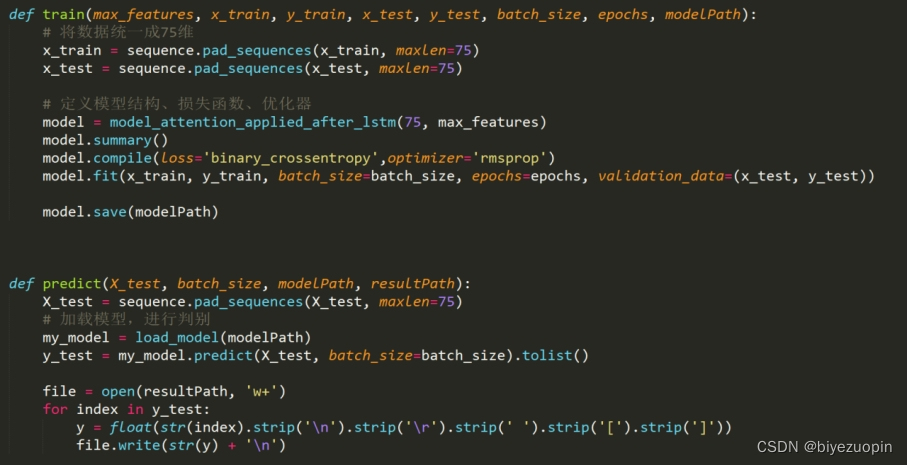
3.3 训练与预测部分代码
4 实验结果
本实验分别在两个数据集上进行多次重复训练和测试,并统计测试结果的平均值,如表 4.1 所示。
表 4.1 测试结果
| 数据集 | Precision | Recall |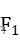
score | 误报率 | 漏报率 |
| ------------ | --------- | ------ | ----------------------------- | ------ | ------ |
| 360 数据集 | 0.9891 | 0.9918 | 0.9905 | 0.0148 | 0.0082 |
| osint 数据集 | 0.9940 | 0.9915 | 0.9928 | 0.0086 | 0.0085 |
资源下载地址:https://download.csdn.net/download/sheziqiong/85895969
资源下载地址:https://download.csdn.net/download/sheziqiong/85895969