点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:DQiaole | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/496739824

本文介绍复旦大学付彦伟老师课题组在CVPR2022的一篇文章:Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding
文章作者:董巧乐*,曹辰捷*,付彦伟
单位:复旦大学
论文:https://arxiv.org/abs/2203.00867
主页:https://dqiaole.github.io/ZITS_inpainting
代码(已开源):
https://github.com/DQiaole/ZITS_inpainting
一句话总结:利用Transformer修复结构,增量式的将结构加到后续CNN纹理修复网络中。
1. 简介
图像修复旨在填充图像中的缺失区域并保持填充区域的结构合理性以及纹理一致性。得益于最近卷积神经网络以积极生成对抗网络的发展,图像修复模型在某些场景上已经可以表现得非常好了。然而,现存的模型仍然面临如下困境:
有限的感受野:受限于卷积的局部归纳偏置以及有限的感受野,利用传统的CNN学习语义相合的纹理是非常困难的。面对大的掩蔽区域或者高分辨图像,即使是膨胀卷积也会失效。
缺少对整体结构的理解:如果没有对图像的整体结构的理解,在高分辨弱纹理场景中恢复关键的边缘和线框是非常困难的。
大的计算量:在高分辨图像上训练生成对抗网络需要非常多的技巧,并且遇到更高分辨率的图像,模型的修复性能也会退化的非常严重。
缺少对掩蔽区域的位置信息:如果缺少掩蔽区域的位置信息,模型在大的掩蔽区域内部往往会倾向于生成重复的无意义的纹理。
这启发了我们为图像修复网络增量式地注入整体结构信息和掩蔽区域位置信息。具体来说,我们利用了一个基于Transformer的模型推断整体结构(边缘+线框)。利用简单的CNN,我们可以把这种结构图非常轻松的上采样到任意分辨率。进一步地,我们提出了利用零初始化残差连接技术增量式地将结构注入到后续CNN纹理修复网络。相比于从头训一个基于结构辅助信息的图像修复模型,这种增量式的技巧只需要继续训练几千步就可以达到非常好的性能。最后,为了提高模型对大掩蔽区域的修复性能,我们还对掩蔽区域引入了位置编码。
2. 方法
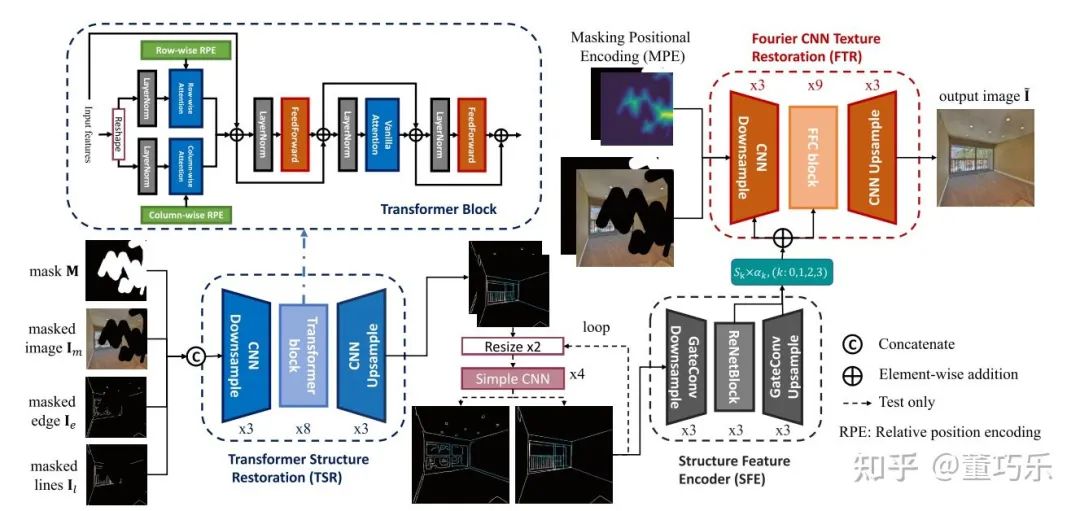
我们的模型整体架构如图1所示。我们首先利用一个基于普通注意力和轴向注意力机制的Transformer修复低分辩图像的结构信息(边缘+线框),修复的结构信息可以用一个简单的CNN网络进行上采样到与输入图片相同的分布率。利用零初始化残差连接技术,我们利用一个编码器抽取结构信息的特征并增量式的加到预训练好的CNN纹理修复模型上,最后再简单的微调我们的模型即可。此外,我们提出的针对掩蔽区域的位置编码也可以通过零初始化残差连接技术增量式的加到预训练好的CNN网络中。在本文中,我们选取了基于快速傅里叶卷积的LaMa作为我们的预训练CNN纹理修复网络(FTR),得益于傅里叶变换的性质,FTR可以拥有全图的感受野,从而极大的提升了图像修复的效果。
3. 定量结果
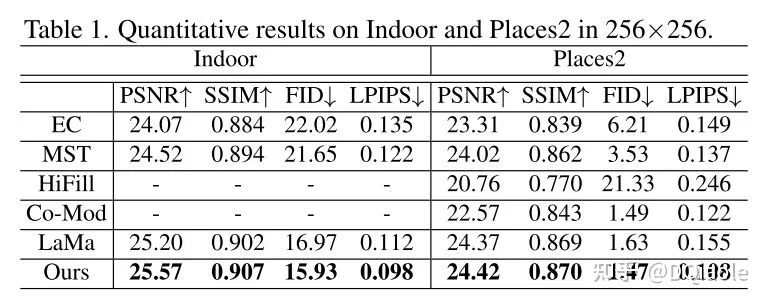
下表对比了我们的模型与其他模型在Indoor和Places2俩个数据集上的结果,图片分辨率是 256 x 256 。可以看到我们模型的效果显著优于其他模型。
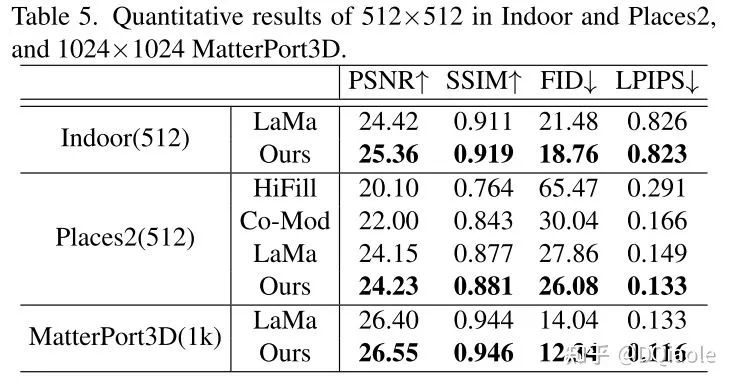
我们还在分辨率为 512 x 512 以及 1024 x 1024 的数据集上做了测试,实验结果如下表所示:
4. 定性结果
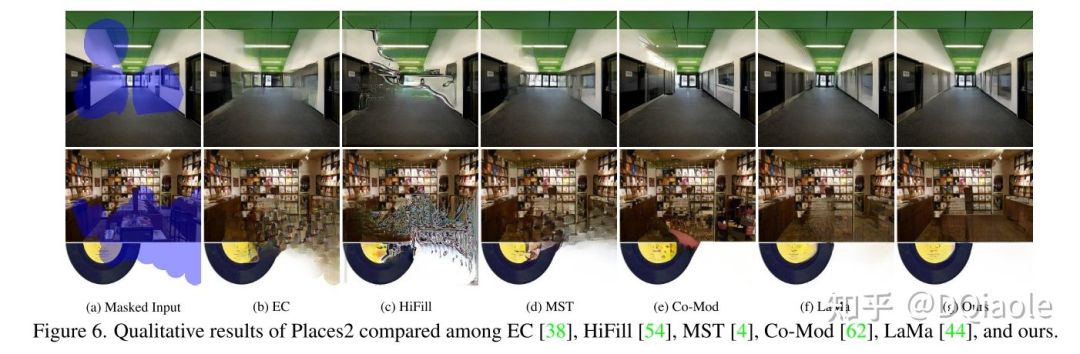
在图2和图3中,我们提供了模型在Indoor和Places2上的定性结果(图片分辨率为 256 x 256),可以看到我们模型对整体结构的恢复更加合理,且面对大掩蔽面积的图像表现效果也显著优于其他模型。

5. 更多1K图像的修复结果
图4和图5展示了我们的模型在1K图片上的表现,面对高分辨的图像,我们模型的修复结果也非常不错。


6. 总结
我们提出了一个增量式结构增强的图像修复模型ZITS。我们利用了基于Transformer的结构恢复网络去推断图像的整体结构。然后,崭新的零初始化残差连接策略被用于增量式的将结构信息引入预训练好的CNN纹理修复网络。提出的掩蔽区域位置编码策略进一步地改进了图像修复性能。此外,我们的模型还可以在高分辨图像上给出比其他SOTA模型更好的效果。
点击进入—> CV 微信技术交流群
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看