一、DOM结构操作
- 新增/插入节点
- 获取子元素列表,获取父元素
- 删除子元素
- 移动节点
const div1 = document.getElementById('div1')
const div2 = document.getElementById('div2')
// 新建节点
const p1 = document.createElement('p')
p1.innerHTML = 'this is p1'
// 插入节点
div1.appendChild(p1)
// 移动节点,p1是已有节点,这里是移动了
const p1 = document.getElementById('p1')
div2.appendChild(p1)
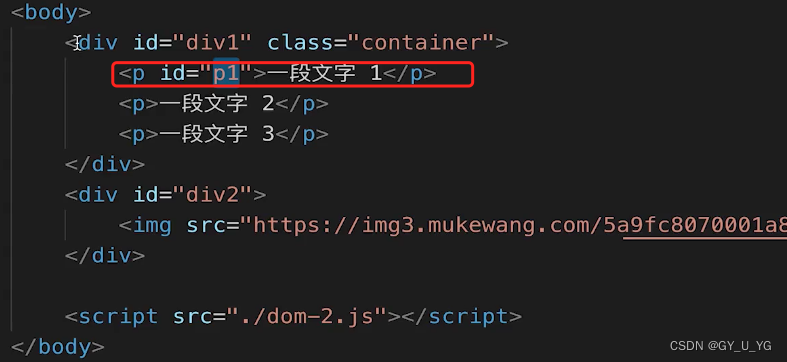
移动后
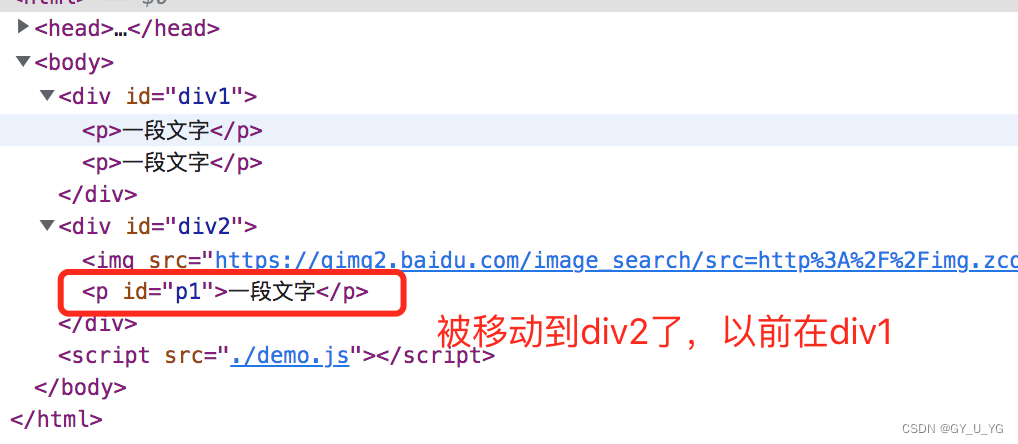
获取子元素列表:
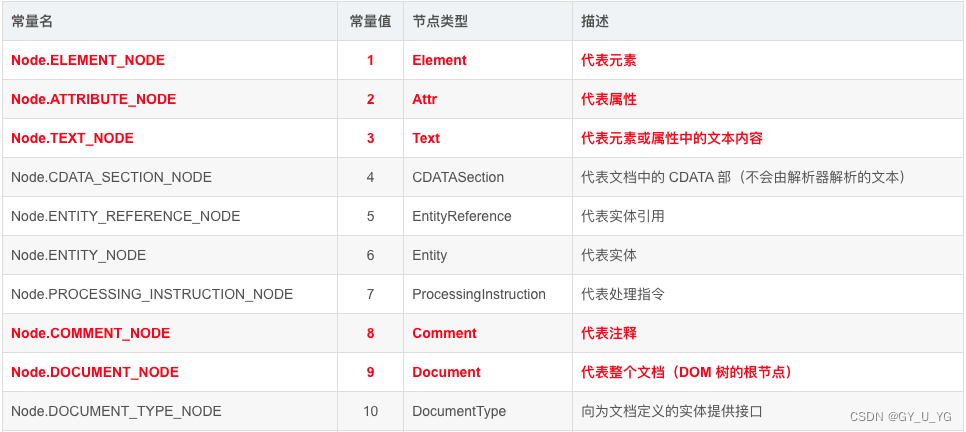
JavaScript 中的所有节点类型都继承自 Node 类型,因此所有节点类型都共享着相同的基本属性和方法。 Node 类型常会被忽视的三个属性:nodeType、nodeName、nodeValue
<!DOCTYPE html>
<html>
<head>
<title>areyouok</title>
</head>
<body>
<div id="div1">
<p id="p1">一段文字</p>
<p>一段文字</p>
<p>一段文字</p>
</div>
<div id="div2">
<img src="https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fimg.zcool.cn%2Fcommunity%2F01bfe456d7e72f32f875520f24ad5f.jpg&refer=http%3A%2F%2Fimg.zcool.cn&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1658028113&t=15cf745bbf40f20b1fd4da8d48078a67" style="width: 50px;height: 50px;"/>
</div>
<script src="./demo.js"></script>
</body>
</html>
const div1 = document.getElementById('div1')
// 获取子元素列表
const div1ChildNodes = div1.childNodes
console.log(div1ChildNodes, typeof div1ChildNodes)
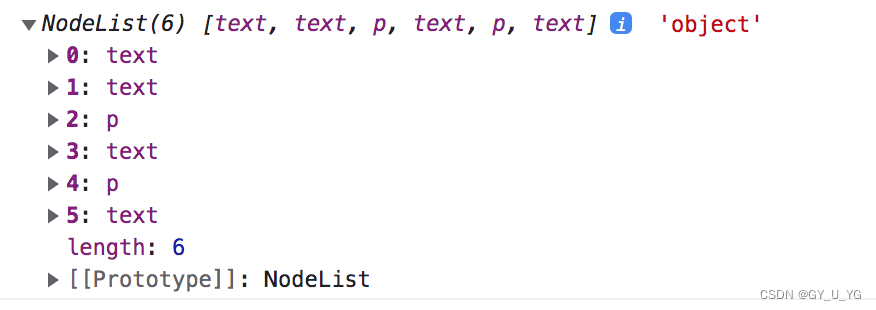
其实这些text就是换行,p标签与p标签之间的换行就是一个text。
那么怎么才能过滤出这些无用的text呢,答案是用filter,但是filter是数组的方法,nodeList并不是数组,而是类数组,没有filter方法
const div1 = document.getElementById('div1')
// 获取子元素列表
const div1ChildNodes = div1.childNodes
console.log(div1ChildNodes, typeof div1ChildNodes)
// 你会发现打印出来了很多text节点,并不全是我们想要p标签
// 下面用两种方法筛选出p标签
const pNodes = Array.from(div1ChildNodes).filter(kid => kid.nodeType === 1)
console.log(pNodes)
// 方法二
const pN = Array.prototype.slice.call(div1ChildNodes).filter(kid => kid.nodeType === 1)
console.log(pN)

删除节点
const div1 = document.getElementById('div1')
// 获取子元素列表
const div1ChildNodes = div1.childNodes
console.log(div1ChildNodes, typeof div1ChildNodes)
// 你会发现打印出来了很多text节点,并不全是我们想要p标签
// 下面用两种方法筛选出p标签
const pNodes = Array.from(div1ChildNodes).filter(kid => kid.nodeType === 1)
console.log(pNodes)
// 方法二
const pN = Array.prototype.slice.call(div1ChildNodes).filter(kid => kid.nodeType === 1)
console.log(pN)
// 删除节点,比如要删除第一个p标签
div1.removeChild(pN[0])
删之前

删了之后
二、DOM性能
- DOM操作非常昂贵,避免频繁的DOM操作
- 对DOM查询做缓存(查到之后先存着)
- 将频繁操作改为一次性操作(打包操作)
// 不缓存DOM查询结果
for (let i = 0; i < document.getElementsByTagName('p').length; i++) {
// 每次循环,都会计算length,频繁进行DOM查询
// 也许你会问,JS引擎会自动优化啊,会自动缓存啊,其实不会,因为JS运行可能会操作DOM,万一DOM改了就得重新查询
// 所以,是否缓存,交给程序员自己决定
}
// 缓存DOM查询结果
const pList = document.getElementsByTagName('p')
const l = pList.length
for (let i = 0; i < length; i++) {
// 缓存length,只进行一次DOM查询
}
重要知识点,createDocumentFragment()
1.createDocumentFragment()方法,是用来创建一个虚拟的节点对象,或者说,是用来创建文档碎片节点。它可以包含各种类型的节点,在创建之初是空的,存在于JS内存中。
2.DocumentFragment节点不属于文档树,继承的parentNode属性总是null。它有一个很实用的特点,当请求把一个DocumentFragment节点插入文档树时,插入的不是DocumentFragment自身,而是它的所有子孙节点,即插入的是括号里的节点。这个特性使得DocumentFragment成了占位符,暂时存放那些一次插入文档的节点。它还有利于实现文档的剪切、复制和粘贴操作。
另外,当需要添加多个dom元素时,如果先将这些元素添加到DocumentFragment中,再统一将DocumentFragment添加到页面,会减少页面渲染dom的次数,效率会明显提升。
3.如果使用appendChid方法将原dom树中的节点添加到DocumentFragment中时,会删除原来的节点。
const list = document.getElementById('list')
// 先借一个片段,片段位于内存中,在片段中操作完成时候,再将整个片段插入到真实DOM中
// 创建一个文档片段,此时还没有插入到DOM树中
// createDocumentFragment创造了一个占位符,在内存中,不是真正的DOM中
// 插入的不是DocumentFragment自身,而是它的所有子孙节点
const frag = document.createDocumentFragment()
for(let i = 0; i < 10; i++) {
const li = document.createElement('li')
li.innerHTML = `list item ${
i}`
frag.appendChild(li)
}
// 都完成之后,再插入到DOM树中
list.appendChild(frag)