IPFS概述
参考视频:9分钟简单理解IPFS
背景
传统的网络信息都是中心化存储的,通常都存储在大型的服务器群中,由一家公司控制,如果公司的服务器出现问题,很容易造成信息的丢失。同时,中心化的存储还存在政府审查的问题,由于内容只托管在少数几台服务器上,政府很容易就能够阻止对它们的访问(2017年,土耳其政府下令互联网封锁维基百科)。
但为什么我们一直使用这样的模型呢?那是因为我们对网络有很高的期望,我们希望网页、图像和视频实时加载,并且是高质量加载(例如高清晰度、流畅度等等),中心化服务器允许公司完全控制提供所有这些内容的速度。我们使用这种模式的另一个原因是,没有一个好的和快速的替代方案。
如何寻址
基于地址寻址:传统的网络是基于地址寻址,假设你想从网上下载一张照片,传统的网络是你告诉电脑照片的IP地址或者是域名,然后到这个地址去下载照片,但如果这个地址无法访问,你就无法获取照片。然而,很有可能其他人之前已经下载了这张照片,并且仍然有他的副本,而你的电脑无法从那个人那里获取副本。为了解决这个问题,IPFS从“基于位置”寻址改为“基于内容”寻址。
基于内容寻址:每个文件都有唯一的哈希值,可以比作指纹。当你想要下载某个文件时,可以问网络“谁拥有带有这个散列的文件”,IPFS网络上的其他人会提供给你。同时,因为使用散列值来请求文件,当你收到文件时,可以检查文件的散列值与你想要的散列是否匹配,以此可以检查你收到的文件有没有被篡改。使用散列值处理内容的另一个很好的特性是重复数据删除,当多人在IPFS上发布相同的文件时,它只会被创建一次,这使得网络非常高效。
如何存储文件
文件存储在IPFS对象中,这些对象可以存储最多256kb的数据,并可以包含到其他IPFS对象的链接,一个非常小的“Hello World”文本文件可以存储在一个IPFS对象中

大于256kb的数据可以被分成多个IPFS对象,大小都是256kb,然后系统将创建一个空的IPFS对象,将对象链接到文件的所有其他部分。
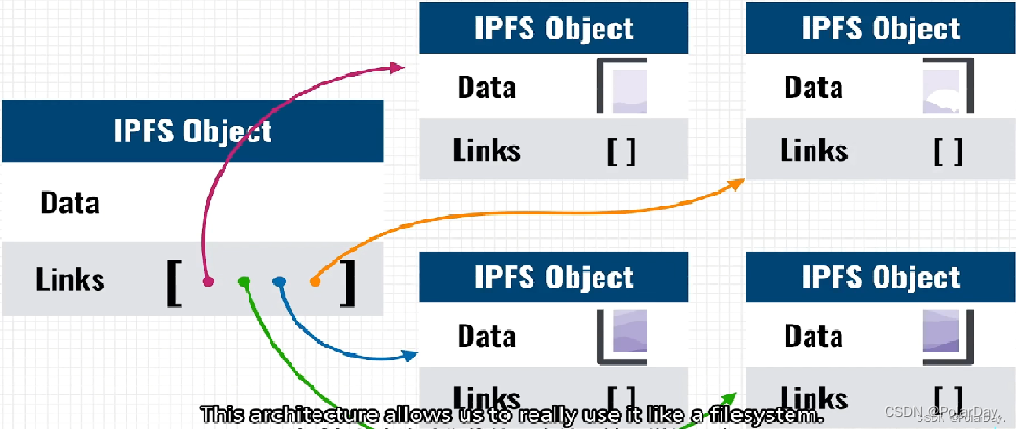
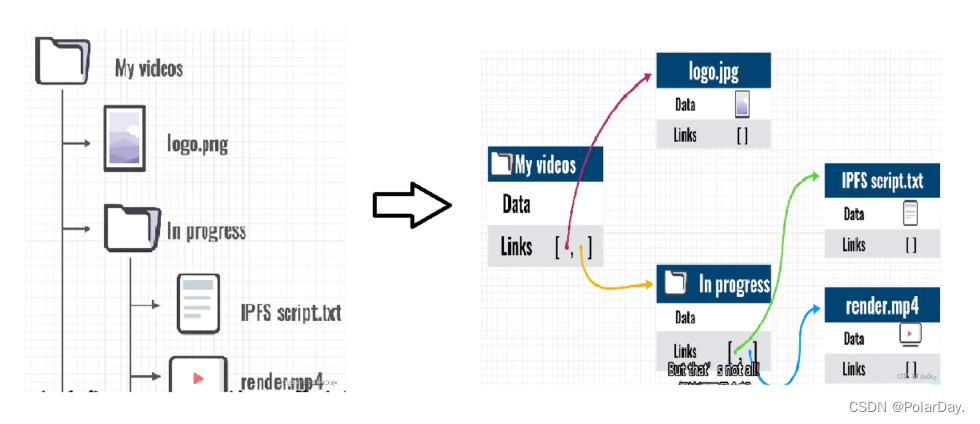
IPFS的数据架构允许我们像使用文件系统一样使用它,例如下面是一个简单的目录结构,其中包含一些文件,我们也可以将其转换为IPFS对象,为每个文件和目录创建一个对象
如何修改文件
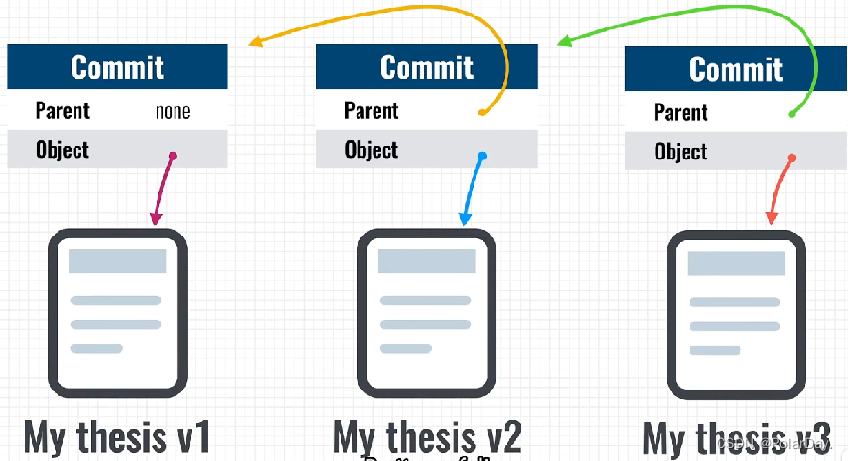
IPFS使用基于内容的寻址,一旦添加了一些东西,就不能再更改了,它是一个不可变的数据结构,很像区块链。但是你怎么改变上面的内容呢?IPFS支持文件版本控制,当你处理一个希望通过IPFS与所有人共享的重要文档时,IPFS将为你创建一个新的“Commit对象”。
这个对象非常基本,它只是告诉IPFS在它之前进行了哪些提交,并且链接到文件的IPFS对象,当你要更新文件时,你只需要将更新后的文件添加到IPFS网络,软件将为你的文件创建一个新的Commit对象,这个对象链接到前一个Commit,这个过程可以无限重复,IPFS将确保网络上的其他节点可以访问您的文件及其整个历史记录
局限性
IPFS面临的最大问题是保持文件可用,网络上的每个节点都保存着下载文件的缓存,并在其他人需要时帮助分享这些文件。但是,如果保存一个文件的所有节点都脱机了,那么这个文件就不可用了,没有人可以获取到这个文件的副本。这个问题有两种可能的解决方案,一是鼓励人们储存文件,让他们可以使用。二是鼓励人们主动分发文件,确保网络上总有一定数量的副本,而这就是FileCoin想做的事情
FileCoin
FileCoin是由创建IPFS的同一组人创建的,它基本是一个构建在IPFS之上的区块链,希望为存储创建一个去中心化的市场,如果你有一些空闲的空间,你可以把它租给别人,在这个过程中赚钱。FileCoin为节点创建了一个强大的激励机制,让它们尽可能长时间地保持文件在线,否则它们将得不到奖励,系统还确保文件被复制到许多节点上,这样它们就不会变得不可用