-
- 置换两个变量的值。
- 链式比较
- 真值测试
- 字符串反转
- 字符串列表的连接
- 列表求和,最大值,最小值,乘积
- 列表推导式
- 字典的默认值
- for…else…语句
- 三元符的替代
- Enumerate
- 使用zip创建键值对
- Extended unpacking
- List slices with negative step
- Zipping
- Sliding windows
- Inverting a dictionary using zip
- Flattening lists
- Generator
- Named tuples
- Inheriting from named tuples
- Sets
- Multisets
- Most common
- Double-ended queue
- Double-ended queue with maximum length
- Ordered dictionaries
- Default dictionaries
- Using default dictionaries to represent simple trees
- Cartesian products
- Combinations
- groupby
- Chaining iterables
- Permutations
- Python中“=”、切片、copy和deepcopy
- lamda函数
- lamda函数使用场景
以下为了简略,我们用P表示pythonic的写法,NP表示non-pythonic的写法
置换两个变量的值。
P
a,b = b,aNP
temp = a
a = b
b = temp链式比较
P
a = 3
b = 1
1 <= b <= a < 10 #True
NP
b >= 1 and b <= a and a < 10 #True
真值测试
P
name = 'Tim'
langs = ['AS3', 'Lua', 'C']
info = {'name': 'Tim', 'sex': 'Male', 'age':23 }
if name and langs and info:
print('All True!') #All True!NP
if name != '' and len(langs) > 0 and info != {}:
print('All True!') #All True!字符串反转
P
def reverse_str( s ):
return s[::-1] NP
def reverse_str( s ):
t = ''
for x in xrange(len(s)-1,-1,-1):
t += s[x]
return t字符串列表的连接
P
strList = ["Python", "is", "good"]
res = ' '.join(strList) #Python is goodNP
res = ''
for s in strList:
res += s + ' '
#Python is good
#最后还有个多余空格string.join()常用于连接列表里的字符串,相对于NP,P的方式十分高效,且不会犯错。
列表求和,最大值,最小值,乘积
P
numList = [1,2,3,4,5]
sum = sum(numList) #sum = 15
maxNum = max(numList) #maxNum = 5
minNum = min(numList) #minNum = 1
from operator import mul
prod = reduce(mul, numList, 1) #prod = 120 默认值传1以防空列表报错NP
sum = 0
maxNum = -float('inf')
minNum = float('inf')
prod = 1
for num in numList:
if num > maxNum:
maxNum = num
if num < minNum:
minNum = num
sum += num
prod *= num
# sum = 15 maxNum = 5 minNum = 1 prod = 120列表推导式
P
l = [x*x for x in range(10) if x % 3 == 0]
#l = [0, 9, 36, 81]NP
l = []
for x in range(10):
if x % 3 == 0:
l.append(x*x)
#l = [0, 9, 36, 81]字典的默认值
P
dic = {'name':'Tim', 'age':23}
dic['workage'] = dic.get('workage',0) + 1
#dic = {'age': 23, 'workage': 1, 'name': 'Tim'}NP
if 'workage' in dic:
dic['workage'] += 1
else:
dic['workage'] = 1
#dic = {'age': 23, 'workage': 1, 'name': 'Tim'}for…else…语句
P
for x in xrange(1,5):
if x == 5:
print 'find 5'
break
else:
print 'can not find 5!'
#can not find 5! NP
find = False
for x in xrange(1,5):
if x == 5:
find = True
print 'find 5'
break
if not find:
print 'can not find 5!'
#can not find 5!for…else…的else部分用来处理没有从for循环中断的情况。有了它,我们不用设置状态变量来检查是否for循环有break出来,简单方便。
三元符的替代
P
a = 3
b = 2 if a > 2 else 1
#b = 2NP
if a > 2:
b = 2
else:
b = 1
#b = 2Enumerate
P
array = [1, 2, 3, 4, 5]
for i, e in enumerate(array,0):
print i, e
#0 1
#1 2
#2 3
#3 4
#4 5NP
for i in xrange(len(array)):
print i, array[i]
#0 1
#1 2
#2 3
#3 4
#4 5使用enumerate可以一次性将索引和值取出,避免使用索引来取值,而且enumerate的第二个参数可以调整索引下标的起始位置,默认为0。
使用zip创建键值对
P
keys = ['Name', 'Sex', 'Age']
values = ['Tim', 'Male', 23]
dic = dict(zip(keys, values))
#{'Age': 23, 'Name': 'Tim', 'Sex': 'Male'}NP
dic = {}
for i,e in enumerate(keys):
dic[e] = values[i]
#{'Age': 23, 'Name': 'Tim', 'Sex': 'Male'}Extended unpacking
>>> a, *b, c = [1, 2, 3, 4, 5]
>>> a
1
>>> b
[2, 3, 4]
>>> c
5List slices with negative step
>>> a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> a[::-1]
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
>>> a[::-2]
[10, 8, 6, 4, 2, 0]Zipping
>>> a = [1, 2, 3]
>>> b = ['a', 'b', 'c']
>>> z = zip(a, b)
>>> z
[(1, 'a'), (2, 'b'), (3, 'c')]
>>> zip(*z)
[(1, 2, 3), ('a', 'b', 'c')]Sliding windows
>>> from itertools import islice
>>> def n_grams(a, n):
... z = (islice(a, i, None) for i in range(n))
... return zip(*z)
...
>>> a = [1, 2, 3, 4, 5, 6]
>>> n_grams(a, 3)
[(1, 2, 3), (2, 3, 4), (3, 4, 5), (4, 5, 6)]
>>> n_grams(a, 2)
[(1, 2), (2, 3), (3, 4), (4, 5), (5, 6)]
>>> n_grams(a, 4)
[(1, 2, 3, 4), (2, 3, 4, 5), (3, 4, 5, 6)]Inverting a dictionary using zip
>>> m = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
>>> m.items()
[('a', 1), ('c', 3), ('b', 2), ('d', 4)]
>>> zip(m.values(), m.keys())
[(1, 'a'), (3, 'c'), (2, 'b'), (4, 'd')]
>>> mi = dict(zip(m.values(), m.keys()))
>>> mi
{1: 'a', 2: 'b', 3: 'c', 4: 'd'}
######2222222
>>> m = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
>>> m
{'d': 4, 'a': 1, 'b': 2, 'c': 3}
>>> {v: k for k, v in m.items()}
{1: 'a', 2: 'b', 3: 'c', 4: 'd'}Flattening lists
>>> a = [[1, 2], [3, 4], [5, 6]]
>>> list(itertools.chain.from_iterable(a))
[1, 2, 3, 4, 5, 6]
>>> sum(a, [])
[1, 2, 3, 4, 5, 6]
>>> [x for l in a for x in l]
[1, 2, 3, 4, 5, 6]
>>> a = [[[1, 2], [3, 4]], [[5, 6], [7, 8]]]
>>> [x for l1 in a for l2 in l1 for x in l2]
[1, 2, 3, 4, 5, 6, 7, 8]
>>> a = [1, 2, [3, 4], [[5, 6], [7, 8]]]
>>> flatten = lambda x: [y for l in x for y in flatten(l)] if type(x) is list else [x]
>>> flatten(a)
[1, 2, 3, 4, 5, 6, 7, 8]Generator
>>> g = (x ** 2 for x in xrange(10))
>>> next(g)
0
>>> next(g)
1
>>> next(g)
4
>>> next(g)
9
>>> sum(x ** 3 for x in xrange(10))
2025
>>> sum(x ** 3 for x in xrange(10) if x % 3 == 1)
408Named tuples
>>> Point = collections.namedtuple('Point', ['x', 'y'])
>>> p = Point(x=1.0, y=2.0)
>>> p
Point(x=1.0, y=2.0)
>>> p.x
1.0
>>> p.y
2.0Inheriting from named tuples
>>> class Point(collections.namedtuple('PointBase', ['x', 'y'])):
... __slots__ = ()
... def __add__(self, other):
... return Point(x=self.x + other.x, y=self.y + other.y)
...
>>> p = Point(x=1.0, y=2.0)
>>> q = Point(x=2.0, y=3.0)
>>> p + q
Point(x=3.0, y=5.0)Sets
>>> A = {1, 2, 3, 3}
>>> A
set([1, 2, 3])
>>> B = {3, 4, 5, 6, 7}
>>> B
set([3, 4, 5, 6, 7])
>>> A | B
set([1, 2, 3, 4, 5, 6, 7])
>>> A & B
set([3])
>>> A - B
set([1, 2])
>>> B - A
set([4, 5, 6, 7])
>>> A ^ B
set([1, 2, 4, 5, 6, 7])
>>> (A ^ B) == ((A - B) | (B - A))
TrueMultisets
>>> A = collections.Counter([1, 2, 2])
>>> B = collections.Counter([2, 2, 3])
>>> A
Counter({2: 2, 1: 1})
>>> B
Counter({2: 2, 3: 1})
>>> A | B
Counter({2: 2, 1: 1, 3: 1})
>>> A & B
Counter({2: 2})
>>> A + B
Counter({2: 4, 1: 1, 3: 1})
>>> A - B
Counter({1: 1})
>>> B - A
Counter({3: 1})Most common
>>> A = collections.Counter([1, 1, 2, 2, 3, 3, 3, 3, 4, 5, 6, 7])
>>> A
Counter({3: 4, 1: 2, 2: 2, 4: 1, 5: 1, 6: 1, 7: 1})
>>> A.most_common(1)
[(3, 4)]
>>> A.most_common(3)
[(3, 4), (1, 2), (2, 2)]Double-ended queue
>>> Q = collections.deque()
>>> Q.append(1)
>>> Q.appendleft(2)
>>> Q.extend([3, 4])
>>> Q.extendleft([5, 6])
>>> Q
deque([6, 5, 2, 1, 3, 4])
>>> Q.pop()
4
>>> Q.popleft()
6
>>> Q
deque([5, 2, 1, 3])
>>> Q.rotate(3)
>>> Q
deque([2, 1, 3, 5])
>>> Q.rotate(-3)
>>> Q
deque([5, 2, 1, 3])Double-ended queue with maximum length
>>> last_three = collections.deque(maxlen=3)
>>> for i in xrange(10):
... last_three.append(i)
... print ', '.join(str(x) for x in last_three)
...
0
0, 1
0, 1, 2
1, 2, 3
2, 3, 4
3, 4, 5
4, 5, 6
5, 6, 7
6, 7, 8
7, 8, 9Ordered dictionaries
>>> m = dict((str(x), x) for x in range(10))
>>> print ', '.join(m.keys())
1, 0, 3, 2, 5, 4, 7, 6, 9, 8
>>> m = collections.OrderedDict((str(x), x) for x in range(10))
>>> print ', '.join(m.keys())
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
>>> m = collections.OrderedDict((str(x), x) for x in range(10, 0, -1))
>>> print ', '.join(m.keys())
10, 9, 8, 7, 6, 5, 4, 3, 2, 1Default dictionaries
>>> m = dict()
>>> m['a']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'a'
>>>
>>> m = collections.defaultdict(int)
>>> m['a']
0
>>> m['b']
0
>>> m = collections.defaultdict(str)
>>> m['a']
''
>>> m['b'] += 'a'
>>> m['b']
'a'
>>> m = collections.defaultdict(lambda: '[default value]')
>>> m['a']
'[default value]'
>>> m['b']
'[default value]'Using default dictionaries to represent simple trees
>>> import json
>>> tree = lambda: collections.defaultdict(tree)
>>> root = tree()
>>> root['menu']['id'] = 'file'
>>> root['menu']['value'] = 'File'
>>> root['menu']['menuitems']['new']['value'] = 'New'
>>> root['menu']['menuitems']['new']['onclick'] = 'new();'
>>> root['menu']['menuitems']['open']['value'] = 'Open'
>>> root['menu']['menuitems']['open']['onclick'] = 'open();'
>>> root['menu']['menuitems']['close']['value'] = 'Close'
>>> root['menu']['menuitems']['close']['onclick'] = 'close();'
>>> print json.dumps(root, sort_keys=True, indent=4, separators=(',', ': '))
{
"menu": {
"id": "file",
"menuitems": {
"close": {
"onclick": "close();",
"value": "Close"
},
"new": {
"onclick": "new();",
"value": "New"
},
"open": {
"onclick": "open();",
"value": "Open"
}
},
"value": "File"
}
}Cartesian products
>>> for p in itertools.product([1, 2, 3], [4, 5]):
(1, 4)
(1, 5)
(2, 4)
(2, 5)
(3, 4)
(3, 5)
>>> for p in itertools.product([0, 1], repeat=4):
... print ''.join(str(x) for x in p)
...
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111Combinations
>>> for c in itertools.combinations([1, 2, 3, 4, 5], 3):
... print ''.join(str(x) for x in c)
...
123
124
125
134
135
145
234
235
245
345
>>> for c in itertools.combinations_with_replacement([1, 2, 3], 2):
... print ''.join(str(x) for x in c)
...
11
12
13
22
23
33groupby
>>> from operator import itemgetter
>>> import itertools
>>> with open('contactlenses.csv', 'r') as infile:
... data = [line.strip().split(',') for line in infile]
...
>>> data = data[1:]
>>> def print_data(rows):
... print '\n'.join('\t'.join('{: <16}'.format(s) for s in row) for row in rows)
...
>>> print_data(data)
young myope no reduced none
young myope no normal soft
young myope yes reduced none
young myope yes normal hard
young hypermetrope no reduced none
young hypermetrope no normal soft
young hypermetrope yes reduced none
young hypermetrope yes normal hard
pre-presbyopic myope no reduced none
pre-presbyopic myope no normal soft
pre-presbyopic myope yes reduced none
pre-presbyopic myope yes normal hard
pre-presbyopic hypermetrope no reduced none
pre-presbyopic hypermetrope no normal soft
pre-presbyopic hypermetrope yes reduced none
pre-presbyopic hypermetrope yes normal none
presbyopic myope no reduced none
presbyopic myope no normal none
presbyopic myope yes reduced none
presbyopic myope yes normal hard
presbyopic hypermetrope no reduced none
presbyopic hypermetrope no normal soft
presbyopic hypermetrope yes reduced none
presbyopic hypermetrope yes normal none
>>> data.sort(key=itemgetter(-1))
>>> for value, group in itertools.groupby(data, lambda r: r[-1]):
... print '-----------'
... print 'Group: ' + value
... print_data(group)
...
-----------
Group: hard
young myope yes normal hard
young hypermetrope yes normal hard
pre-presbyopic myope yes normal hard
presbyopic myope yes normal hard
-----------
Group: none
young myope no reduced none
young myope yes reduced none
young hypermetrope no reduced none
young hypermetrope yes reduced none
pre-presbyopic myope no reduced none
pre-presbyopic myope yes reduced none
pre-presbyopic hypermetrope no reduced none
pre-presbyopic hypermetrope yes reduced none
pre-presbyopic hypermetrope yes normal none
presbyopic myope no reduced none
presbyopic myope no normal none
presbyopic myope yes reduced none
presbyopic hypermetrope no reduced none
presbyopic hypermetrope yes reduced none
presbyopic hypermetrope yes normal none
-----------
Group: soft
young myope no normal soft
young hypermetrope no normal soft
pre-presbyopic myope no normal soft
pre-presbyopic hypermetrope no normal soft
presbyopic hypermetrope no normal softChaining iterables
>>> a = [1, 2, 3, 4]
>>> for p in itertools.chain(itertools.combinations(a, 2), itertools.combinations(a, 3)):
... print p
...
(1, 2)
(1, 3)
(1, 4)
(2, 3)
(2, 4)
(3, 4)
(1, 2, 3)
(1, 2, 4)
(1, 3, 4)
(2, 3, 4)
>>> for subset in itertools.chain.from_iterable(itertools.combinations(a, n) for n in range(len(a) + 1))
... print subset
...
()
(1,)
(2,)
(3,)
(4,)
(1, 2)
(1, 3)
(1, 4)
(2, 3)
(2, 4)
(3, 4)
(1, 2, 3)
(1, 2, 4)
(1, 3, 4)
(2, 3, 4)
(1, 2, 3, 4)Permutations
>>> for p in itertools.permutations([1, 2, 3, 4]):
... print ''.join(str(x) for x in p)
...
1234
1243
1324
1342
1423
1432
2134
2143
2314
2341
2413
2431
3124
3142
3214
3241
3412
3421
4123
4132
4213
4231
4312
4321Python中“=”、切片、copy和deepcopy
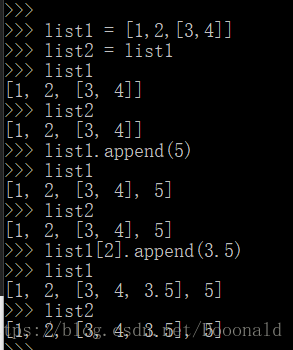
“=” 一般意义的复制
我们所说的一般意义的“等于号“相当于引用,即原始队列改变,被赋值的队列也会作出相同的改变。
直接赋值,传递对象的引用而已,原始列表改变,被赋值的b也会做相同的改变
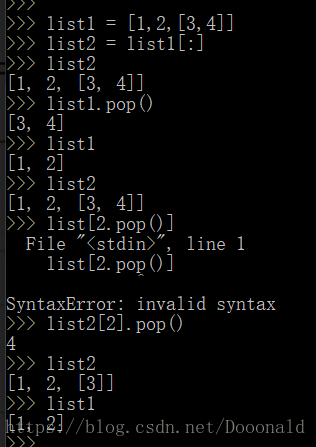
列表切片
Python中列表切片是深拷贝,即被复制的对象作为一个一个新的个体独立存在,任意改变其一不会对另一个对象造成影响。
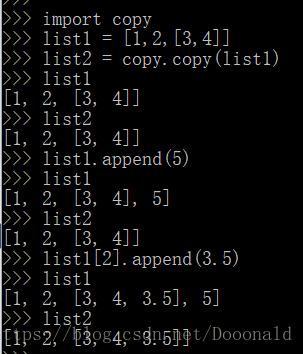
Python中的copy
copy是浅拷贝,并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了。
这里需要注意,对于简单对象来说,深拷贝、浅copy并没有区分,改变原始队列,赋值队列并不会改变。
但是对于嵌套队列来说,改变了子对象的值,浅拷贝会随之变化,深拷贝不会。
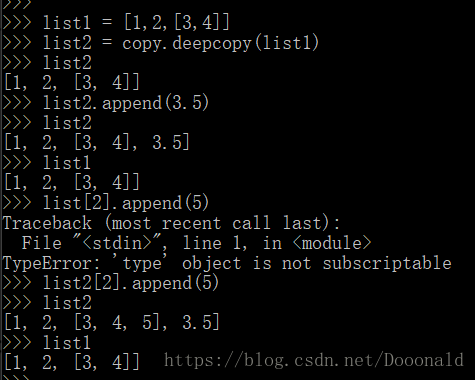
深拷贝 deepcopy
Python中的copy动作,对于一个复杂对象的子对象并不会完全复制,什么是复杂对象的子对象呢?就比如序列里的嵌套序列,字典里的嵌套序列等都是复杂对象的子对象。
对于子对象,浅拷贝动作会把它当作一个公共镜像存储起来,所有对他的复制都被当成一个引用,所以说当其中一个引用将镜像改变了之后另一个引用使用镜像的时候镜像已经被改变了。
对于子对象,深拷贝动作会将复杂对象的每一层复制一个单独的个体出来,因而二者完全独立。
lamda函数
Lambda函数,是一个匿名函数,创建语法:
lambda parameters:express
parameters:可选,如果提供,通常是逗号分隔的变量表达式形式,即位置参数。
expression:不能包含分支或循环(但允许条件表达式),也不能包含return(或yield)函数。如果为元组,则应用圆括号将其包含起来。
调用lambda函数,返回的结果是对表达式计算产生的结果。
#以下两种方法等价,都可以通过调用area(5,3),结果相同
>>> area=lambda b,h:0.5*b*h
>>> def area(b,h):
return 0.5*b*h
根据参数是否为1 决定s为yes还是no
>>> s = lambda x:"yes" if x==1 else "no"
>>> s(0)
'no'
>>> s(1)
'yes'#使用sorted()方法和list.sort()方法进行排序
>>> elements=[(2,12,"A"),(1,11,"N"),(1,3,"L"),(2,4,"B")]
>>> sorted(elements)
[(1, 3, 'L'), (1, 11, 'N'), (2, 4, 'B'), (2, 12, 'A')]
#根据elements每个元组后两项进行排序,e表示列表中每个三元组元素
#在表达式是元组,且lambda为一个函数的参数时,lambda表达式的圆括号是必需的
>>> elements.sort(key=lambda e:(e[1],e[2]))
>>> elements
[(1, 3, 'L'), (2, 4, 'B'), (1, 11, 'N'), (2, 12, 'A')]
#分片方式得到同样的效果
>>> elements.sort(key=lambda e:e[1:3])
>>> elements
[(1, 3, 'L'), (2, 4, 'B'), (1, 11, 'N'), (2, 12, 'A')]
lamda函数使用场景
#1.函数式编程:
例如:一个整数列表,要求按照列表中元素的绝对值大小升序排列
>>> list1 = [3,5,-4,-1,0,-2,-6]
>>> sorted(list1, key=lambda x: abs(x))
[0, -1, -2, 3, -4, 5, -6]
#排序函数sorted支持接收一个函数作为参数,该参数作为 sorted的排序依据,这里按照列表元素的绝对值进行排序。
当然,我也可以用普通函数来实现:
>>> def foo(x):
... return abs(x)
...
>>> sorted(list1, key=foo)
[0, -1, -2, 3, -4, 5, -6]
#只不过是这种方式代码看起来不够 Pythonic 而已。
#lambda:这是Python支持一种有趣的语法,它允许你快速定义单行的最小函数,可以用在任何需要函数的地方:
>>> add = lambda x,y : x+y
>>> add(5,6)
>>> (lambda x,y:x+y)(5,6)#2.Python中最常见的filter筛选、map小刷子、reduce合并,都可以用lambda表达式来生成!
#对于序列来讲,有三个函数式编程工具: filter()、map()和reduce()。
#map(function,sequence):把sequence中的值当参数逐个传给function,返回一个包含函数执行结果的list。
#求1~20的平方
>>> list(map(lambda x:x*x,range(1,21))) #Python2.x使用map(lambda x:x*x,range(1,21))
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144, 169, 196, 225, 256, 289, 324, 361, 400]
#如果function有两个参数,即map(function,sequence1,sequence2)。
>>> list(map(lambda x,y:x+y,range(8),range(8)))
[0, 2, 4, 6, 8, 10, 12, 14]
>>> list(map(lambda x,y:x*y,range(8),range(8)))
[0, 1, 4, 9, 16, 25, 36, 49]
#filter(function,sequence):对sequence中的item依次执行function(item),将执行结果为True的item组成一个List/String/Tuple(取决于sequence的类型)返回。
#求1~20之间的偶数
>>> list(filter(lambda x:x%2 == 0,range(1,21))) #Python2.x使用filter(lambda x:x%2 == 0,range(1,21))
[2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
#reduce(function,sequence):function接收的参数个数只能为2,先把sequence中第一个值和第#二个值当参数传给function,再把function的返回值和第三个值当参数传给function,然后只返回一个结果。
#求1~100之和
>>> from functools import reduce #Python3.x之后需要导入reduce模块
>>> reduce(lambda x,y:x+y,range(1,101))
#求1~100之和,再加上10000
>>> reduce(lambda x,y:x+y,range(1,101),10000)#3.闭包
#闭包:一个定义在函数内部的函数,闭包使得变量即使脱离了该函数的作用域范围也依然能被访问到。
#来看一个用lambda函数作为闭包的例子。
>>> def add(n):
... return lambda x:x+n
...
>>> add2 = add(5)
>>> add2(15)
#这里的lambda函数就是一个闭包,在全局作用域范围中,add2(15)可以正常执行且返回值为20。之所以返回20是因为在add局部作用域中,变量n的值在闭包的作用使得它在全局作用域也可以被访问到。
#换成常规函数也可以实现闭包,只不过是这种方式稍显啰嗦。
>>> def my_add(n):
... def wrapper(x):
... return x+n
... return wrapper
...
>>> add_5 = my_add(5)
>>> add_5(2)
7zen of python 中有这样一句话是 Explicit is better than implicit(明了胜于晦涩)。记住,如果用 lambda 函数不能使你的代码变得更清晰时,这时你就要考虑使用常规的方式来定义函数。