回复 PDF 领取资料

这是悟空的第 87 篇原创文章
本文来自我的一次真实面试经历。
这家公司的真名就叫做“三藏”,和我的名字“悟空”很契合,唐三藏给悟空面试,合情合理,还带有一丝趣味,所以我就去面试了。三藏公司是一家小厂,技术负责人面的我,欲知面试结果,文末揭晓。
本文主要内容如下:
一、MongoDB 和 MySQL
1.面试官:看你的简历上写了 MongoDB,说下 MongoDB 和 MySQL 的区别吧。
其实对于这个问题,我事先有准备,简历上写了 MongoDB,面试官肯定会问 MongoDB 和 MySQL 的区别。
MongoDB 是非关系型的数据库(NoSQL),属于文档型数据库,文档数据库就是为了解决关系数据库带来的问题。最大的特点是 no-schema,可以存储和读取任意的数据。
存储的数据格式就是 JSON(或者 BSON)。JSON 格式我们都比较熟悉,比如 Rest API 请求返回的 Response 就是 JSON 格式的。JSON 格式的数据和 XML 格式的区别是 JSON 更简单,没有那么多的标签来定义字段名。也就是说 JSON 是自描述的。另外 JSON 格式存进 MongoDB 中后,即使读取一个 JSON 中不存在的字段也不会导致 SQL 那样的语法错误。
MongoDB 优点
由于文档数据库具有 no-schema 特性,用起来有以下几个明显的好处。

(1)新增的字段不会出错。
比如用户表增加一个昵称的字段,不需要像关系型数据那样执行更新表结构的语句。我们直接查询这条文档出来就可以看到新增的字段了。
(2)查询历史数据不会出错。
上面提到新增了一个昵称字段,但是历史数据中是没有这个字段,如果查询历史数据,则返回的数据中不会有这个字段,虽然查询不会报错,但是取值时,会返回 null。如果业务代码中用到了昵称字段,则需要做兼容性处理。
(3)轻松存储复杂数据。
因为是用 JSON 存储,而 JSON 又可以表示复杂的数据结构,比如字段可以存数组,字段可以嵌套字段,而且可以存很多字段。换做 MySQL,则需要设计几张表来存。MongoDB 存数据的结构,特别适合电商这种业务场景,比如两种不同的商品,属性差别就很大,但是用 JSON 存就可以轻松应对。
但是文档数据库有什么缺点呢 ?
MongoDB 缺点
(1)目前 4.0 以前不支持多文档事务。
结合 MongoDB 文档模型内嵌数组、文档的支持,目前的单文档事务能满足绝大部分开发者的需求。为了让 MongoDB 能适应更多的应用场景,让开发变得更简单,MongoDB 4.0 将支持复制集内部跨一或多个集合的多文档事务,保证针对多个文档的更新的原子性。而在未来的 MongoDB 4.2 版本,还会支持分片集群的分布式事务。
我们来看下 MongoDB 不同版本支持的功能:
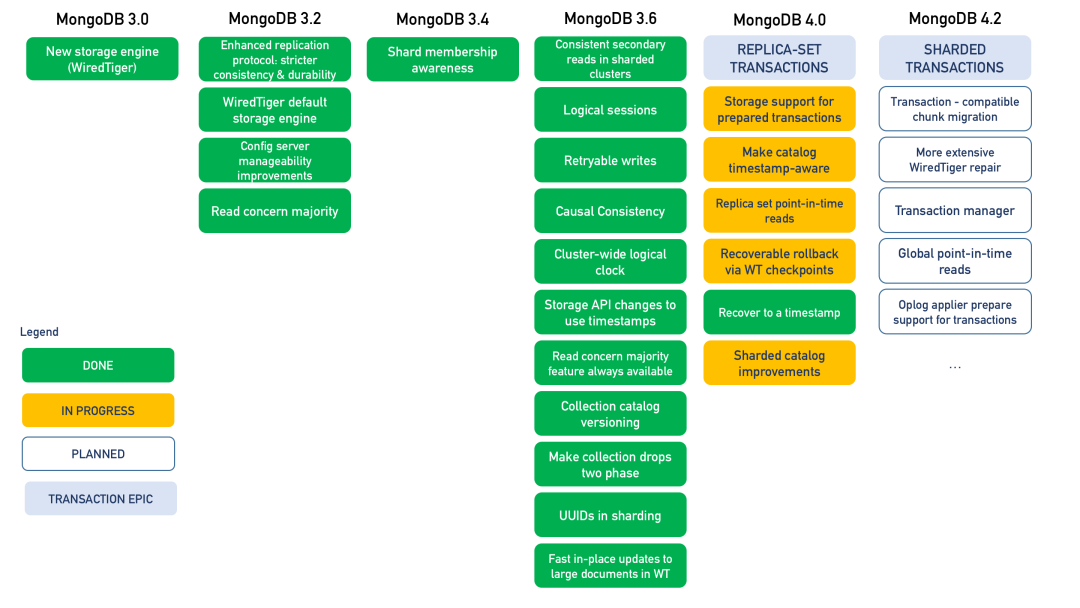
MongoDB 的事务接口非常简单,开发者只需要将需要保证原子性的更新序列放到一个 session 的 开始事务 与提交事务之间即可。下面是 Java 使用 MongoDB 事务的示例代码:
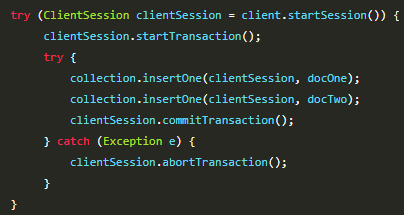
(2) 不支持关联查询。
我们都知道 MySQL 是支持关联查询的,也就是可以执行 Join 操作。比如有两张表:用户表和订单表,订单表中有用户的 id,且性别只存在用户表中。如果想购买了手机的男性用户,用关联查询,一步就能搞定。但是如果用 MongoDB,则需要查两次,先查询订单表中购买手机的用户,再查询这些用户中哪些是男性。
二、关系型数据的缺点
2.面试官:这个项目为什么不用关系型数据库?关系型数据库有哪些缺点?
顺着面试官的思路,可以知道面试官想问的是关系型数据库有哪些不足之处。
关系型数据库的不足之处
(1)存储的是行记录。
不能存储数组、嵌套字段等格式的数据。
(2)扩展表结构不方便。
操作不存在的列会报错,而增加列又需要执行 SQL 语句才行。而且修改时需要特别注意,因为更新表时会长时间锁表,这对线上环境可能造成严重影响。
(3)占用内存高。
关系型数据库在对大量数据的表进行统计之类的运算时,占用内存会很高,因为它即使只针对某一列进行运算,也会将整行数据从存储设备读入内存。
(4)全文搜索性能差
类似于 MySQL 的关系型数据库,只能用 like 进行整表扫描的匹配,效率很低。现如今,有很多场景需要支持模糊匹配,而且必须支持高效查找。比如查询包含关键字的日志信息,又或者是根据某个商品关键字查询商品列表。
针对以上的不足之处,我们这个项目用了两种非关系型的数据存储方案:MongoDB 和 ElasticSearch。
三、NoSQL 的分类和特点
3.面试官:你知道的有哪些 NoSQL 数据库?分别有什么特点?
NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。
我知道的有 Redis、MongoDB、HBase、全文搜索引擎 Elasticsearch。他们是不同的非关系型存储方案。
K-V 存储型
比如 Redis,它可以用 K-V 键值对的方式来存储数据,而存储的值可以有好几种格式,如 string、hash、list、set、bitmap 等。
文档存储型
比如 MongoDB,存储的 JSON 格式的文档,解决了关系型数据库的表约束的问题,比如查询不存在的字段会报错。另外也解决了部分存储格式的问题,因JSON 可以表示数组,还可以嵌套字段存储。
列式存储型
比如 HBase,按照列来存储数据,解决了大数据场景下的 I/O 问题。
关系型数据库按照行来存储数据,所以称作行式数据库。按照行来存储有以下优势:
-
读一行数据就能读取到多个列,只需要一次磁盘操作就能把多个列的数据读取到内存中。 -
写一行数据可以对多个列进行写操作,保证了行数据的原子性和一致性。而对列式存储的多列写操作,可能会导致有些列成功,有些失败,产生数据的不一致。
全文搜索引擎
这个用到的最多的地方就是日志系统,还有搜索商品信息等类似场景。如下图所示的电商网站。
我们项目中用到日志搜索就是利用 ELK。
Elasticsearch 就是 ELK 中的 E。Elasticsearch 就是全文搜索引擎,注意:他是一种 NoSQL 方案,并不是 NoSQL 数据库。
Logstash 就是 ELK 中的 L。它是 Elastic Stack 的核心产品之一,可用来对数据进行聚合和处理,并将数据发送到 Elasticsearch。Logstash 是一个开源的服务器端数据处理管道,允许您在将数据索引到 Elasticsearch 之前同时从多个来源采集数据,并对数据进行充实和转换。
Kibana 就是 ELK 中的 K。是一款适用于 Elasticsearch 的数据可视化和管理工具,可以提供实时的直方图、线性图等。
如下图所示:
传统的关系型的数据库主要是通过索引来进行快速查询,但如果放在全文搜索的场景下,就行不通了。
我们来看看为什么关系型数据库很难做到高效的全文搜索:
-
因为在全文搜索中,搜索的条件是可以随意排列组合的,比如字段 A、B、C,可以排列成 6 种,如果要用索引来支持快速查询的话,则需要创建多个索引,这是非常麻烦的,同时,多个索引对数据的插入效率也是有影响的。 -
模糊匹配只能用 like 查询,而 like 查询是整表扫描,效率是非常低的。
之前我写过一篇 Elasticsearch 原理的:《别只会搜日志了,求你懂点原理吧》,通过倒排索引实现高效的全文检索。下面举个倒排索引的例子给大家看看:
假如数据库有如下电影记录:
1-大话西游
2-大话西游外传
3-解析大话西游
4-西游降魔外传
5-梦幻西游独家解析
分词,将整句分拆为单词:
| 序号 | 保存到 ES 的词 | 对应的电影记录序号 |
|---|---|---|
| A | 西游 | 1,2, 3,4, 5 |
| B | 大话 | 1,2, 3 |
| C | 外传 | 2,4, 5 |
| D | 解析 | 3,5 |
| E | 降魔 | 4 |
| F | 梦幻 | 5 |
| G | 独家 | 5 |
检索:独家大话西游
将 独家大话西游 拆分成 独家、大话、西游
ES 中 A、B、G 记录 都有这三个词的其中一种, 所以 1,2, 3,4, 5 号记录都有相关的词被命中。
1 号记录命中 2 次, A、B 中都有 ( 命中 2 次 ) ,而且 1 号记录有 2 个词,相关性得分:2 次/2 个词=1
2 号记录命中 2 个词 A、B 中的都有 ( 命中 2 次 ) ,而且 2 号记录有 2 个词,相关性得分:2 次/3 个词= 0.67
3 号记录命中 2 个词 A、B 中的都有 ( 命中 2 次 ) ,而且 3 号记录有 2 个词,相关性得分:2 次/3 个词= 0.67
4 号记录命中 2 个词 A 中有 ( 命中 1 次 ) ,而且 4 号记录有 3 个词,相关性得分:1 次/3 个词= 0.33
5 号记录命中 2 个词 A 中有 ( 命中 2 次 ) ,而且 4 号记录有 4 个词,相关性得分:2 次/4 个词= 0.5
所以检索出来的记录顺序如下:
1-大话西游 ( 相关性得分:1 )
2-大话西游外传 ( 相关性得分:0.67 )
3-解析大话西游 ( 相关性得分:0.67 )
5-梦幻西游独家解析 ( 相关性得分:0.5 )
4-西游降魔 ( 相关性得分:0.33 )
Elasticsearch 与 mysql 的对比
| 序号 | Mysql | Elasticsearch |
|---|---|---|
| 1 | Mysql 服务 | ES 集群服务 |
| 2 | 数据库 Database | 索引 Index |
| 3 | 表 Table | 类型 Type |
| 4 | 记录 Records ( 一行行记录 ) | 文档 Document ( JSON 格式 ) |
另外的 NoSQL 还有图形数据库,这里不做展开。
关系型和 NoSQL 怎么选?
4.面试官:关系型和 NoSQL 怎么选呢?
关系型和NoSQL数据库的选型,考虑几个指标,数据量、并发量、实时性、一致性要求、读写分离、安全性、运维性等。根据这些指标,软件系统可分成几类。
-
管理型系统,如运营类系统,首选关系型。 -
大流量系统,且多字段、数据量增长快,首选 NoSQL。 -
日志型系统,首选 Elasticsearch -
搜索型系统,指站内搜索,非通用搜索,如商品搜索,首选 Elasticsearch。 -
事务型系统,如库存、交易、记账,选关系型+缓存+一致性协议。 -
离线计算,如大量数据分析,首选列式数据库。 -
实时计算,如实时监控,可以选时序数据库,或列式数据库。
面试结果:技术负责人觉得还行,但 HR 今天不在,等 HR 下次通知吧。后续就没通知了。完。

参考资料:
https://mongoing.com/archives/5560
https://time.geekbang.org/column/article/8377
https://dzone.com/articles/history-databases-%E2%80%9Cno-tation%E2%80%9D
https://www.runoob.com/mongodb/nosql.html
- END -
 周日写的文章《大佬,你的网站崩了》忘了嵌入视频,这次给大家看下。
周日写的文章《大佬,你的网站崩了》忘了嵌入视频,这次给大家看下。
文末阅读原文也可以进入到这个网站。

本文分享自微信公众号 - 悟空聊架构(PassJava666)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。