文章目录
目的
最近在做一些 DXBC to HLSL 的工作,其中遇到一些 DX HLSL 中的 mul(pos, matrix) 和 GL GLSL 中的 mul(matrix, pos) 的差异
为了更加方便做 shader 逆向,所以多记录一下 DX, GL 中的一些区别
问题
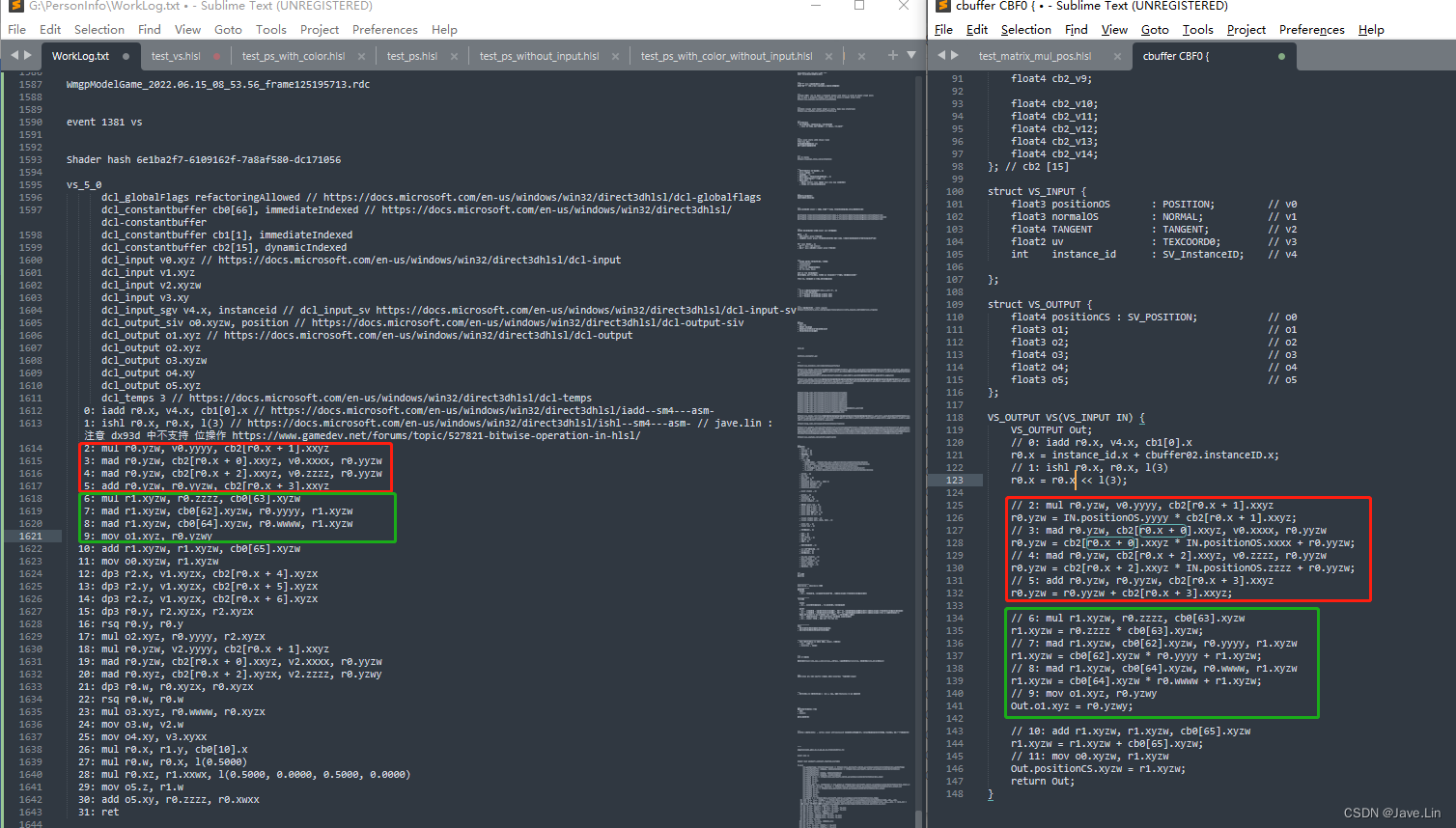
上面 红色框中 和 绿色框 中的代码,我大概看得出来就是 一些矩阵变换的运算
但是还原到 对应HLSL 时,或是看到一些 HLSL 示例时,发现 DX, GL 的 mul 函数用法 有丢丢 不同
这些 DX 与 GL 差异真的很烦,容易忘记,而且 Unity 使用的是 column major 的方式 来构建结构体
但是运算又是 GL 的方式来构建矩阵,差点把我懵逼了。。。
再记一次吧,不然容易忘记、搞混(毕竟没有经常去用 微软的 HLSL、FXC 编译器)
上图中的 一段代码其实可以改写为对应 HLSL 中 mul(floatN, matrixNxN)
// 2: mul r0.yzw, v0.yyyy, cb2[r0.x + 1].xxyz
r0.yzw = IN.positionOS.yyyy * cb2[r0.x + 1].xxyz;
// 3: mad r0.yzw, cb2[r0.x + 0].xxyz, v0.xxxx, r0.yyzw
r0.yzw = cb2[r0.x + 0].xxyz * IN.positionOS.xxxx + r0.yyzw;
// 4: mad r0.yzw, cb2[r0.x + 2].xxyz, v0.zzzz, r0.yyzw
r0.yzw = cb2[r0.x + 2].xxyz * IN.positionOS.zzzz + r0.yyzw;
// 5: add r0.yzw, r0.yyzw, cb2[r0.x + 3].xxyz
r0.yzw = r0.yyzw + cb2[r0.x + 3].xxyz;
// jave.lin : 上面 2~5 lines的 DXBC 代码分析,可以等价于
float4x4 matrixL2W = {
// jave.lin : local to world matrix
cb2[r0.x + 0].xxyz, // jave.lin : 新坐标基:x轴
cb2[r0.x + 1].xxyz, // jave.lin : 新坐标基:Y轴
cb2[r0.x + 2].xxyz, // jave.lin : 新坐标基:Z轴
cb2[r0.x + 3].xxyz // jave.lin : 放射变换的 xyz 平移量
};
r0.yzw = mul(float4(IN.positionOS, 1.0), matrixL2W);
从这 DXBC 看着还好,因为我之前习惯了 GL 中的 矩阵左乘写法,但是写成 HLSL 的话,就需要注意 DX 和 GL 的区别
我自己在 excel 中画了一些图来总结
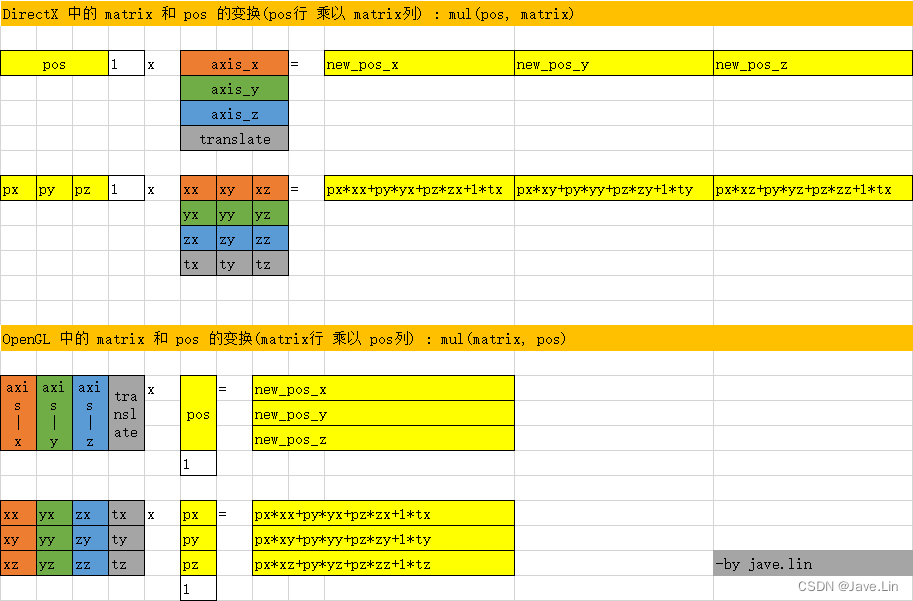
OpenGL 中的 matrix[0] 取的是 列
DirectX 中的 matrix[0] 取的是 行
下面列出一些示例代码,和 官方 一两段 描述 和 代码
show me the code, talk is cheap.
示例
OpenGL:
vec3 pos = ...;
mat3x3 model_mat = mat3x3(
vec3(0,0,0), // column 1
vec3(1,1,1), // column 2
vec3(2,2,2), // column 3
);
vec3 posWS = mul(model_mat, pos); // model_mat 行 乘 pos 列
DirectX:
float3 pos = ...;
float3x3 model_mat = {
0, 0, 0, // row 1
1, 1, 1, // row 2
2, 2, 2 // row 3
};
float3 posWS = mul(pos, model_mat); // pos 行 乘 model_mat 列
文档
下面参考:DirectX 中的 matrix type 的 分量操作:Per-Component Math Operations - matrix type
Overloaded versions of the multiply intrinsic function handle cases where one operand is a vector and the other operand is a matrix. Such as: vector * vector, vector * matrix, matrix * vector, and matrix * matrix. For instance:
float4x3 World;
float4 main(float4 pos : SV_POSITION) : SV_POSITION
{
float4 val;
val.xyz = mul(pos,World);
val.w = 0;
return val;
}
produces the same result as:
float4x3 World;
float4 main(float4 pos : SV_POSITION) : SV_POSITION
{
float4 val;
val.xyz = (float3) mul((float1x4)pos,World);
val.w = 0;
return val;
}
This example casts the pos vector to a column vector using the (float1x4) cast. Changing a vector by casting, or swapping the order of the arguments supplied to multiply is equivalent to transposing the matrix.
Automatic cast conversion causes the multiply and dot intrinsic functions to return the same results as used here:
{
float4 val;
return mul(val,val);
}
This result of the multiply is a 1x4 * 4x1 = 1x1 vector. This is equivalent to a dot product:
{
float4 val;
return dot(val,val);
}
References
- DirectX 中的 matrix type 的 分量操作:Per-Component Math Operations - matrix type