提高精度
- 这部分主要从数据、先验框(anchor box)、模型三方面入手改进。
数据改进
几何数据增强
- 我们知道这次的训练数据只有250张,所以数据增强是一定要的,看了一下测试集之后觉得用普通的几何增强手段足以,具体用了随机水平翻转,随机裁剪,随机旋转这些方式就不多说了。
mix-up增强
-
这里要提一点就是后期分析错误的时候发现了某些困难样本很难识别,尝试了mix-up增强的方法从数据入手改善,mix-up简单来说就是图片的加权和,可以看下图:

-
但是在本场景使用mix-up后因为整个场景背景较为复杂,两个复杂图片的叠加使得很多有效信息得不到很好的表达,模型的表现没有得到提高
填鸭式增强
- 这个叫法是之前看各种kaggle大佬分享方案的时候看到的,具体的原理就是将一些目标(特别是后期分析检测效果差的)扣出来,放到没有目标的图上去,增加图像的鲁棒性。后面分析错误的时候我发现有一些在钢筋上的石头就被误判成钢筋,觉得使用填鸭式增强应该可以改善这个问题,但因为时间问题以及这个方法感觉太过手动就没有尝试,感觉应该是有效的。
先验框(anchor box)改进
-
我们知道YOLO是基于anchor box来预测偏移,那anchor box的size就很重要,我们先可视化一下钢筋框的长宽(归一化后):

-
我们可以看到基本上是1:1,我们再看看YOLO v3的anchor box:
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
- 既有1:1也有1:2,但这是否意味着我们就不需要1:2?于是我一开始把他们稍微都改成1:1(手动),发现一般的钢筋检测效果确实变好了,但是很多遮挡的钢筋(非1:1比例)检测效果就变差了,所以手动修改比例是不可行的。
- 那如果我们使用kmeans来聚类生成我们的anchor box呢?我们来可视化一下(这里和原版一样也选择了9个聚类中心):
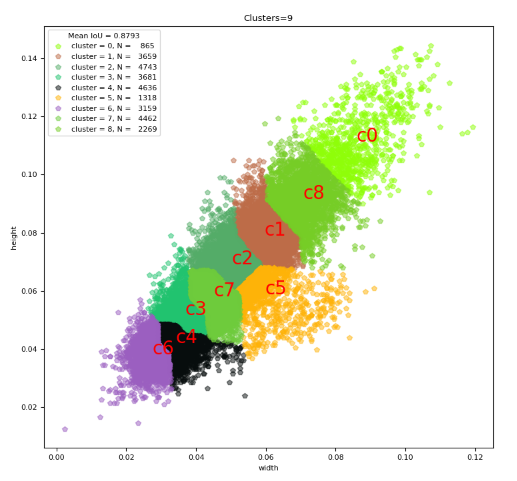
- 感觉9个聚类确实有点强行,但是同时mean iou可以达到0.8793,实际上可能6个聚类中心甚至3个聚类中心就已经足够,但是在试验中发现使用聚类之后的anchor box效果却比原版在coco上聚类得到的anchor box效果要差,这里猜测跟muti_scale多尺度训练有关系,不过由于本来框的检测效果也不错,所以就放弃了修改anchor box的想法,如果有懂的朋友还希望指点一二。
模型改进
FPN(feature pyramid networks)

- 我们知道FPN(特征金字塔)可以通过特征图的跨层concat这样的操作,来使得每一层预测所用的feature map都融合了不同深度的语义特征,增强检测效果。在YOLO v3中只是使用相邻两层的特征层进行融合,我发现很多边缘的钢筋没有得到很好的检测,我的其中一个猜测是特征融合得不够好,所以我将52×52的预测分支(三个预测分支中对应检测小物体的分支)进行了特征大融合,手动将其改成3个预测分支的融合,试验后发现效果有提升,但是整体不稳定,在后面就把代码改回来了,但是后面发现那一次提交的结果就是最高的==
- 这里还有一点就是在本场景下只是对多目标单类别的检测,作为仅有的一个类别钢筋并不具有很强的语义信息,所以我觉得可能并不需要像YOLO一样用那么深FPN,这里可以考虑把最深的FPN换成一个更浅的FPN进行融合,效果应该有提升。
空洞卷积
- 前面有提到很多处于图片较边缘的钢筋没有得到很好的检测,后面总结的时候觉得和从darknet输出的感受野(ROI)比较小有关,觉得可以在darknet最后一层加一个空洞卷积来扩大感受野,空洞卷积简单来说就是通过增加计算的范围来增加感受野,这个后面会写篇文章介绍,这个因为是比较后面想到的就没有尝试,读者感兴趣可以试试。

多尺度训练
- 模型的训练我们采用多尺度图片输入进行训练,来使得模型具有尺度的鲁棒性,这里要提一点,如果是通过每次输入图片的时候来随机选择尺度方式输入(即YunYang代码中的方式)来多尺度训练,训练中的loss容易出现nan,为了避免这个问题可以在每个batch之间随机选择尺度而不是每个batch内来随机选择尺度。
背景错检
-
测试样本中出现了许多背景样本错捡的问题,我们自然而然会想到Focal loss,我们知道Focal loss有两个参数 ,其中 固定为2不用调,主要是调整 ,但在试验中我发现无论怎么调这个参数,最后训练的时候虽然收敛的速度加快许多,但是检测的效果都没有变好,这和YOLO论文中作者说加了Focal loss不work一样,后面想了很久才明白:我们知道YOLO对物体的判断有三种:正例,负例和忽视,与ground truth的iou超过0.5就会被认为ignore,我们用YOLO v1的一张图来说明:

-
我们知道整个红色框都是这只狗,但在红色框内的网格并不都与这只狗的gound truth的IOU超过0.5,这就让一些本来应该忽视的样本变成了负例,加入了我们Focal Loss的“困难样本集”,造成了label noise,让使用了Focal loss之后模型的表现变差。要解决这一点很简单,将ignore的阈值从0.5调至0.1或0.2,表现马上就提升了。(减少了很多背景错捡,但因为阈值调低的原因多了很多框,这个可以通过后期对分数阈值的控制来消除,因为那些框基本都是低分框)
soft-nms
- 很多人看到这次这么密集的目标检测肯定会想到使用soft-nms替代nms,这个在之前讲解YOLO v3的文章也有提到,具体来说就是不要直接删除所有IoU大于阈值的框,因为在密集物体的检测中会出现误删的情况,而是降低其置信度。
- 我使用高斯加权方式的soft-nms替代普通的nms,但把其中的参数
从0.1试0.7,效果都非常不好,我们具体来看效果图:
