文章目录
本章重点
- 主要掌握HTTP请求中的报头字段信息
- 总点掌握
Cookie作用
HTTP请求
我们上篇博客已经初步了解了HTTP协议的大致内容,已经明白了HTTP协议分请求和响应两部分,而且这两个部分的协议报具有不同到格式,需要我们掌握协议格式里的每个字段代表的信息,能够通过Fiddler抓包工具抓取HTTP协议报从而真正理解学习应用层HTTP协议!
而我们本章主要详细了解HTTP协议的请求格式,掌握里面的每个字段对应的信息,从而可以读懂一个HTTP请求,最终到达可以直接编写一个HTTP请求的效果!
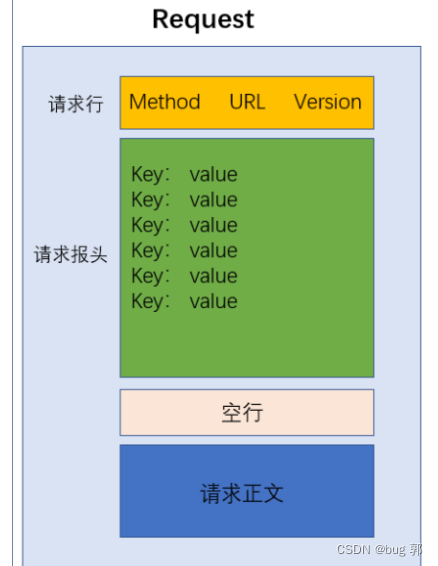
请求报头(header)
我们知道请求头header中的内容采用键值对的形式存储!
所以有一些KEY值具有具体的含义,我们来学习一下常见KEY值的的含义!
我们抓取一个请求报进行辅助学习!
GET https://csdnimg.cn/public/common/libs/jquery/jquery-1.9.1.min.js?1655271269501 HTTP/1.1
Host: csdnimg.cn
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Referer: https://editor.csdn.net/
Sec-Fetch-Dest: script
Sec-Fetch-Mode: no-cors
Sec-Fetch-Site: cross-site
可以看到这里的键值对格式:
键和值之间用: 冒号和空格进行分割!
一对键值对存在于一行中,进而分割键值对
Host
Host用于保存这个请求协议的域名!
可以看到我们抓取包的域名信息Host: csdnimg.cn
Content-Length
表示body中的数据长度!
显然只有POST方法的请求协议报头中才包含了body数据!
所以我们抓取一个POST请求!
POST https://incoming.telemetry.mozilla.org/submit/firefox-desktop/baseline/1/176aad6a-352f-4834-bfb9-9fa2575f8863 HTTP/1.1
Host: incoming.telemetry.mozilla.org
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
content-length: 691
content-type: application/json; charset=utf-8
x-telemetry-agent: Glean/44.1.1 (Rust on Windows)
date: Wed, 15 Jun 2022 05:46:32 GMT
Connection: keep-alive
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: no-cors
Sec-Fetch-Site: none
Pragma: no-cache
Cache-Control: no-cache
{"ping_info":{"seq":4365,"start_time":"2022-06-15T13:36+08:00","end_time":"2022-06-15T13:46+08:00","reason":"inactive"},"client_info":{"telemetry_sdk_build":"44.1.1","first_run_date":"2021-08-09+08:00","app_build":"20220608170832","app_channel":"release","app_display_version":"101.0.1","architecture":"x86_64","os":"Windows","os_version":"10.0","client_id":"0bacdc5f-939a-4115-93bf-a619c5f31b07"},"metrics":{"counter":{"browser.engagement.active_ticks":108,"browser.engagement.uri_count":18},"datetime":{"glean.validation.first_run_hour":"2021-08-09T12+08:00"},"labeled_counter":{"glean.error.invalid_state":{"glean.baseline.duration":1},"glean.validation.pings_submitted":{"baseline":1}}}}
我们可以看到POST请求报头中就有Content-Length键值对!
content-Length: 691
说明这里的POST请求body字段长度是671
这里的Content-Length有啥作用呢!
我们在传输层中知道TCP要解决粘包问题,就需要在应用层协议动手!
而我们知道然后请求报头和body中有空行分割!但是当应用层协议报分用到达接收方的接收队列中如果无法得知一个协议报字段长度大小,就可能出现粘包问题,而这里的Content-Type可以知道body的字段长度也就可以确定一个协议报的尾,从而解决粘包问题!
Content-Type
表示请求中的body数据字段格式!
常见选项格式如下:
application/x-www-form-urlencoded:
采用form表单提交的数据格式!
此时的body的字段格式形如:
title=test&content=hello
就是键和值之间用=连接,键值对之间用&分割,类似于我们的querystring查询字符串格式!
并且也需要进行urlencode!
multipart/form-data: form:
表单提交的数据格式(在 form 标签中加上enctyped="multipart/form-data" )
这和上面的application/x-www-form-urlencoded区别就是这里的表单一般用于提交图片/文件!
body格式形如:
Content-Type:multipart/form-data; boundary=----
WebKitFormBoundaryrGKCBY7qhFd3TrwA
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="text"
title
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png
PNG ... content of chrome.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
application/json:数据为json格式:
body格式形如:
{
"ping_info":{
"seq":4365,"start_time":"2022-06-15T13:36+08:00","end_time":"2022-06-15T13:46+08:00","reason":"inactive"},"client_info":{
"telemetry_sdk_build":"44.1.1","first_run_date":"2021-08-09+08:00","app_build":"20220608170832","app_channel":"release","app_display_version":"101.0.1","architecture":"x86_64","os":"Windows","os_version":"10.0","client_id":"0bacdc5f-939a-4115-93bf-a619c5f31b07"},"metrics":{
"counter":{
"browser.engagement.active_ticks":108,"browser.engagement.uri_count":18},"datetime":{
"glean.validation.first_run_hour":"2021-08-09T12+08:00"},"labeled_counter":{
"glean.error.invalid_state":{
"glean.baseline.duration":1},"glean.validation.pings_submitted":{
"baseline":1}}}}
我们现在的POST请求中的body字段一般采用json格式!
我们的POST请求从何获取呢?
我们知道GET请求占大部分,抓取一个POST请求好难!
我们通过这两种方法的一些特性就可以进准定位到POST请求!
首先我们知道GET是通过URL中的查询字符串,进行数据传输!而该URL需要暴露在页面上,如果我们进行登入注册的请求访问,那就很尴尬,直接在页面上暴露了用户信息!这样就显得很不专业!
如果使用POST请求就很好的解决了这个问题,我们的POST请求是通过body传输信息的!我们不能直接从页面上看到该信息!
所以我们的登入注册页面请求,一般都是使用POST方法!
User-Agent(UA)
表示当前用户的上网环境!
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0
这是博主的User-Agent字段信息!
可以看到我们里面还是有一些可以认识的单词信息!
Windows NT 10.0 Win64; x64;
表示当前我用的设备是PC断,操作系统是Windows 10 64位机器!
Gecko/20100101 Firefox/101.0
关于使用的浏览器的一些信息,可以看到我使用的Firefox浏览器!
UA有啥用呢?
通过这个请求报头字段携带给服务器,然后通过该UA信息,程序员就可以返回对应适配的响应!
就比如我们的PC端屏幕是宽屏,而手机端是窄屏!这就使得我们返回的需要有兼容性问题!我们通过UA就可以返回对应的响应信息!
还有就是之前浏览器不同,代码的适配度也有所不同,就比如有点图片在有的浏览器上就无法查看!使用UA也是解决了这个问题!但是现在的浏览器功能都大差不差!这个字段也失去了意义了!当时返回设备的类型还是意义重大,虽然也有一些其他的解决方案,列如分布式等,但是都不如这个来的高效!
Referer
表示这个页面从那个页面跳转而来!
如果是直接从浏览器输框或者收藏夹点开的请求就没有该字段信息,毕竟这也没跳转呀!
GET https://profile.csdnimg.cn/5/F/F/2_weixin_52345071 HTTP/1.1
Host: profile.csdnimg.cn
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0
Accept: image/avif,image/webp,*/*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Referer: https://blog.csdn.net/
Sec-Fetch-Dest: image
Sec-Fetch-Mode: no-cors
Sec-Fetch-Site: cross-site
我们抓取的这个请求报就有Referer字段!
Referer: https://blog.csdn.net/
通过这个Referer我们就可以知道我们当前域名为profile.csdnimg.cn的页面是从https://blog.csdn.net/跳转过来的!
所以Referer有什么用嘛?
我们知道这个页面从哪里来有啥意义嘛?
我们想象一下一个页面上可能有好多广告,而一个广告主会在多个平台投广告!页面上的有些广告是通过点击计费的,通过这个平台的推广,点击后来到广告主主机的服务器,而广告主通过Referer信息就可以知道这个点击从那个页面而来从而区分不同的平台,更好的进行计费!
Cookie
实现身份标识的功能!
Cookie存储了一个字符串,这个数据可能来自客户端(通过网页中的js写入的),也可能来自服务器(服务器在HTTP响应中的Header中的Set-Cookie字段给浏览器返回的数据)
所以说这么多这里的Cookie字段到底有啥作用呢?
我们知道当我们在一个网站上进行了一次登入后,后面我们打开这个网页就不需要登入了,浏览器会用户的身份信息保存一段时间!
然后每次我们登入这个网站,你都可以获取到之前的信息,因为你之前的信息都在服务器的数据库保存着!
而Cookie就是一个身份标识,通过这个Cookie信息访问网站后,服务器通过这个Cookie信息就可以找到该用户的数据信息从而访问,并且也保存在这个Cookie中!
可能说的还是不特别明白!
我们可以将Cookie想象成一个小房间!
因为我们刚刚说了在我们登入一个页面后,这个页面的信息就会在流量器中保留一段时间,这里就报留在本地浏览器的Cookie中!
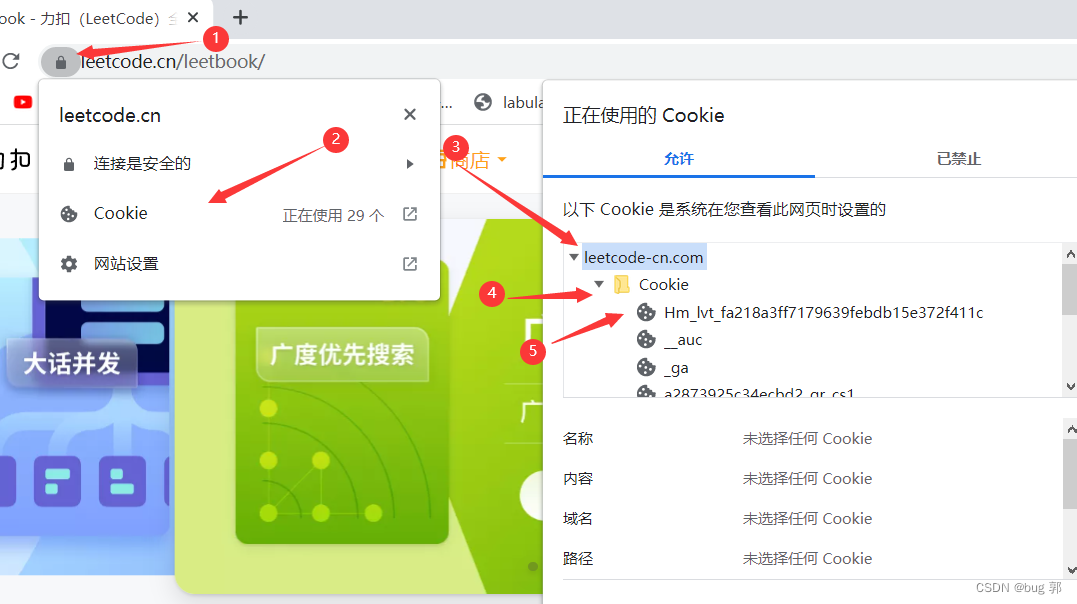
我们登入一个力扣网站!
可以看到这个小锁头就保存了网页的Cookie信息,然后我们通过找到LeetCode的Cookie信息就可以查看到这个网页当前缓存在你本地的身份标识,然后这里的Cookie也是采用了键值对的形式存储,每一条信息都是一个键值对!然后如果我们进行删除,只是把本地的Cookie信息给删除了,你重新登入后,你的LeetCode信息还在!还有不同网页具有不同的Cookie,浏览器可以缓存对应网页的信息!
浏览器如何放回该用户的数据信息呢?
就是通过请求中的
Cookie信息,通过这个身份标识,拿到CookieId然后在服务器端中的数据库中找到Cookie信息通过Body返回!
接收方通过上方这个Cookie信息,可以返回对应的数据!
而放回的Cookie信息保存在body中!
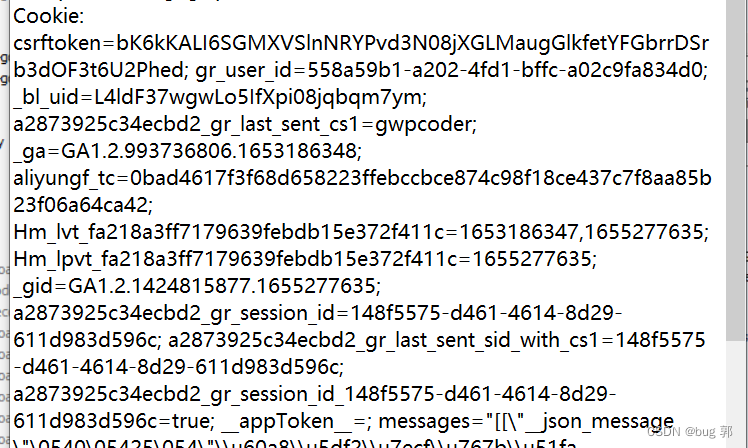
我们可以看到请求协议报中的Cookie信息采用键值对的形式:
键和值之间用=连接
键值对用;分割!
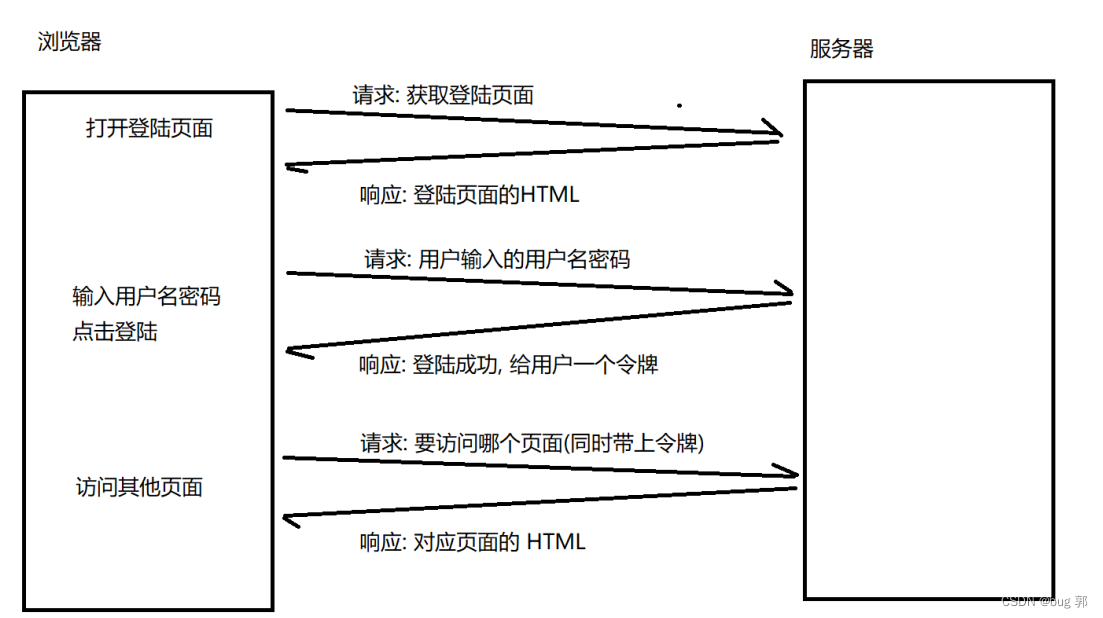
Cookie信息就类似一个令牌信息,通过这个令牌进行身份验证!
body
我们知道我们的Header和body通过空格隔开!
然后这里的body数据格式啥的主要由Header中的信息表标识好了!
Content-Typebody的格式!
Content-Lengthbody字段的长度!