Hbase没有提供类似于hive根据已有表的建表建表语句,如在hive中创建一个和已有表表结构完全一样的表可执行SQL:create table tbl_test1 like tbl_test,在hbase只能采用笨办法,将其表结构拷贝出来建表。如:

稍作整理:
create 'solrHbase2', {NAME => 'f1', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'SNAPPY', MIN_VERSIONS => '0',KEEP_DELETED_CELLS => 'false', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
需要将原表结构中的TTL => 'FOREVER'去掉才能建。
1. 导出数据
使用hbase org.apache.hadoop.hbase.mapreduce.Driver export tablename hdfspath
或hbase org.apache.hadoop.hbase.mapreduce.Export tablename hdfspath
eg:hbase org.apache.hadoop.hbase.mapreduce.Driver export solrHbase /home/hdfs/export
此命令可加参数:
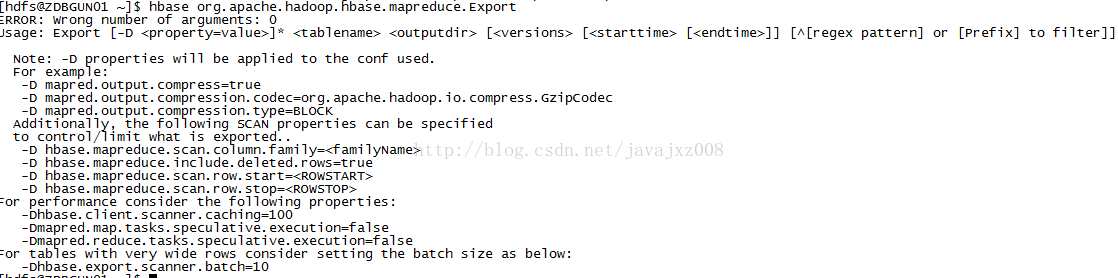
解释如下:
Usage: Export [-D <property=value>]* <tablename> <outputdir> [<versions> [<starttime> [<endtime>]] [^[regex pattern] or [Prefix] to filter]]
Note: -D properties will be applied to the conf used.
For example:
-D mapred.output.compress=true 输出压缩
-D mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec 压缩方式
-D mapred.output.compression.type=BLOCK 按块压缩
Additionally, the following SCAN properties can be specified
to control/limit what is exported..
-D hbase.mapreduce.scan.column.family=<familyName> 列簇
-D hbase.mapreduce.include.deleted.rows=true
-D hbase.mapreduce.scan.row.start=<ROWSTART> 开始rowkey
-D hbase.mapreduce.scan.row.stop=<ROWSTOP> 终止rowkey
For performance consider the following properties:
-Dhbase.client.scanner.caching=100 客户端缓存条数
-Dmapred.map.tasks.speculative.execution=false
-Dmapred.reduce.tasks.speculative.execution=false
For tables with very wide rows consider setting the batch size as below:
-Dhbase.export.scanner.batch=10 批次大小
输入命令后会生成mapreduce作业,不想全部将表数据导出,可采用参数-D hbase.mapreduce.scan.row.start=<ROWSTART>和-D hbase.mapreduce.scan.row.stop=<ROWSTOP>指定rowkey范围导出数据。如导出指定rowkey范围的数据:
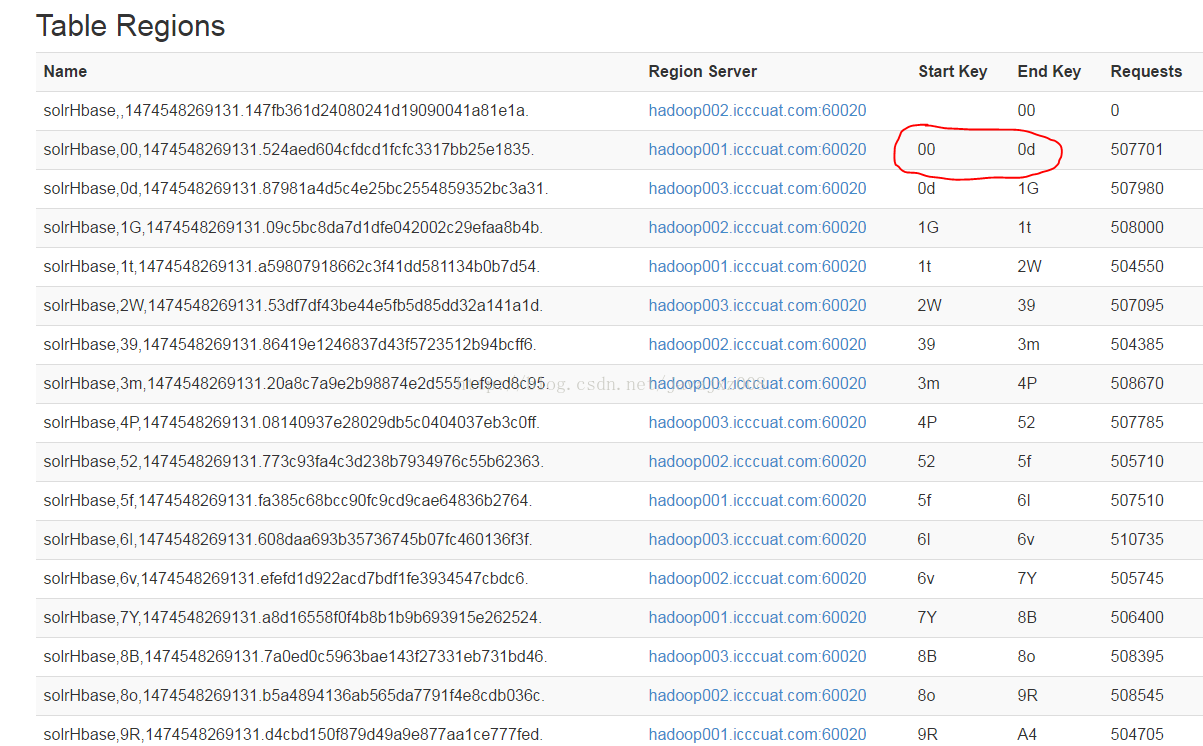
hbase org.apache.hadoop.hbase.mapreduce.Export -D hbase.mapreduce.scan.row.start=00 -D hbase.mapreduce.scan.row.stop=0d solrHbase /home/hdfs/export
这里的开始rowkey 00和结束rowkey 0d是rowkey的开头部分,该表是做过预分区的,在hbase的控制台上看:
1. 导入数据
hbase org.apache.hadoop.hbase.mapreduce.Driver import tablename hdfspath
或hbase org.apache.hadoop.hbase.mapreduce.Import tablename hdfspath
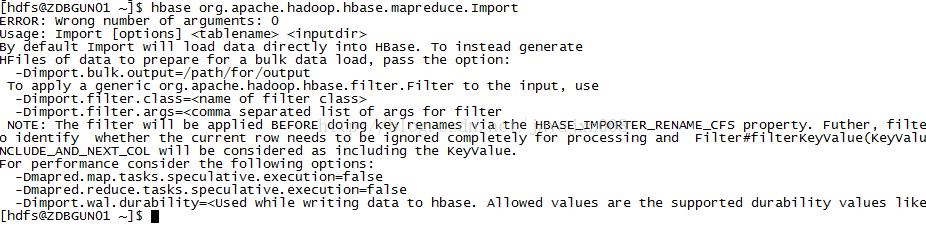
Import也有一些使用说明:
将刚刚导出的数据导入新表中:
hbase org.apache.hadoop.hbase.mapreduce.Import solrHbase2 /home/hdfs/export
输入命令生成mapreduce作业,完成后可查看新表数据是否导入成功。