提纲
Part 1 智慧医疗下的器官图像分割技术
● Introduction
● 针对样本不平衡与对抗形状约束的放疗危及器官分割框架
● 基于协同训练和平均模型的多器官分割
● What's next
Part 2 Q&A
智慧医疗下的器官图像分割技术
1. Introduction
放疗(Radiotherapy)是肿瘤的主流治疗方法。据世界卫生组织的数据显示,大约有70%的癌症患者需要接受放射治疗。放疗利用高能射线打入患者的体内,从而去破坏癌细胞的DNA结构,达到彻底杀死癌细胞的目的。但高能射线的放射性对于正常的组织器官同样是有害的,它也会无可避免地损伤到肿瘤周围的一些正常器官。因此在制定放疗计划的阶段,放疗医生需要精确地勾画出肿瘤靶区,以及周围的危及器官的轮廓,保证放射剂量主要集中在肿瘤靶区,同时保护危及器官不被过多的照射而导致损伤。
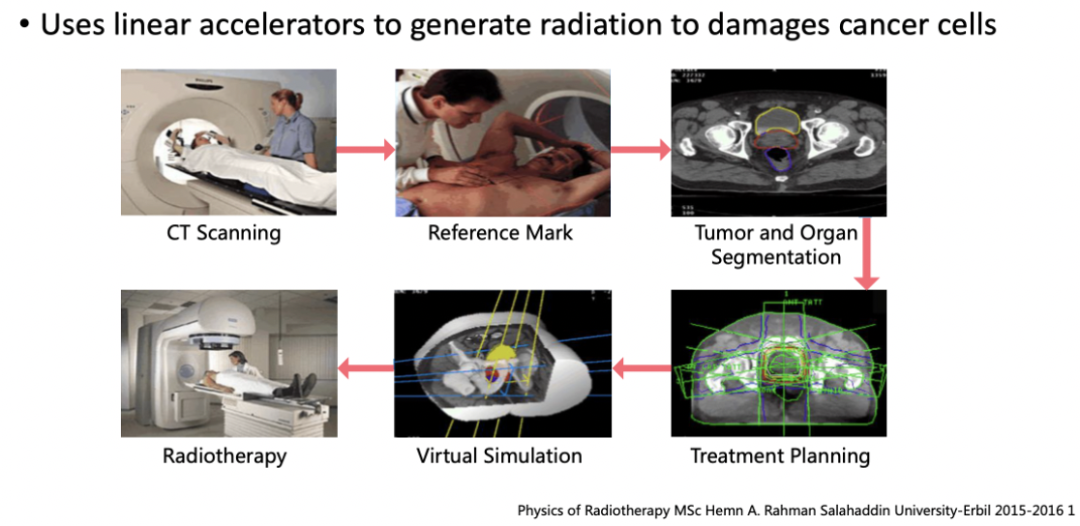
在放疗的工作流中,首先是CT的模拟定位,目的是模拟放疗时射线照射的位置和范围:对患者的体位进行固定,然后进行CT扫描,同时也会在患者的体表做参考的标记用于定位。随后医生和物理师会在定位CT上对肿瘤靶区以及危及器官做勾画。
勾画完成之后,物理师会进行治疗计划的设计。其中主要包括了射野角度以及计量等重要参数的设计。例如确定要使用多少条射线、每一条射线分别从哪个角度打入、打多少剂量等等。计划制定完成之后,物理师会验证计划的可行性,最终把治疗计划传输到的加速器上,对患者实施治疗。可以看出放疗是一个比较复杂的技术,需要多个岗位的技术人员同时配合,才能够顺利地完成治疗。
现阶段肿瘤靶区和危及器官勾画占据了医生和物理师大量的时间和精力。以鼻咽癌为例,鼻咽癌对放射线比较敏感,因此放疗是鼻咽癌最主要的一种早期治疗手段。目前临床上在制定放疗计划的时候,超过20个的正常器官需要被保护起来的,其中包括了脑干、眼球、脊髓等,我们把这些正常器官称为危及器官(Organs-at-risk),医生需要在CT上把每一个危及器官的轮廓勾画出来。目前临床上主要采用手动勾画的方式,整个过程需要花费2-5个小时;同时器官勾画对解剖学的知识有一定的要求,熟悉临床知识的人才能够进行勾画。因此器官勾画占据了医生大量的时间,这就导致病人通常需要等待比较长的时间才能够得到治疗。
另外由于主观因素的影响,不同的医生对于同一个患者以及同一位医生在不同时刻,勾画结果都有可能是不完全一致的。如果危及器官的勾画不精确的话,就有可能会导致一些严重的并发症。例如有些病人在做完放疗之后,会出现口干、进食困难等症状,严重的还可能会患上脑脊髓病。因此一个准确鲁棒的 AI 辅助危及器官分割系统,能够显著提高放疗的效率以及质量,有效地解决当下放疗医生的工作痛点,同时能够缩短病人的等待的时间,使得在相同时间内有更多的病人接受到更高质量的放疗。
2. 针对样本不平衡与对抗形状约束的放疗危及器官分割框架
本工作主要关注头颈部 CT 的危及器官的勾画。头颈部的器官具有非常复杂的解剖结构,放疗时有20多个正常器官需要被保护起来;器官的大小和形状都有很大差异;由于 CT 成像的局限性,有部分的软组织器官的对比度是比较低的,导致一些器官在 CT上看不到明显的边界。
首先我们统计了每一个器官包含的 voxel的个数,发现比较小的器官,例如晶状体、视神经、视交叉、脑垂体,有几十到几百个 voxel;比较大器官,例如腮腺,颞叶,具有上万个 voxel,大小器官之间的体积的差异达到了上千倍。另外在三维医学图像上,占据最大的是 background 的部分,因此器官之间以及器官和背景之间极度的不平衡,会很大程度地影响神经网络的训练。
已有的方法通常会将大器官和小器官同等对待,这会导致小器官的分割精度比较差。也有一些方法会在 Loss Function 上赋予小器官更高的权重,但这种方法也无法彻底解决不平衡的问题。另外由于 CT 成像的特性,一些软组织的器官,比如视神经交叉在 CT 上只有一半的边界是清晰的。
在这种情况下,我们的motivation是设计一个框架模仿医生的勾画。首先医生会在正常的尺度下把比较大的器官给勾画出来,对于小器官,医生会先确定小器官的位置,然后对图像进行放大,关注小器官周围的区域,进行更加精确的勾画,从而解决尺度不平衡的问题。我们的框架包含两个阶段,总体的思想是先对小器官进行定位,然后关注小器官附近的 context ,解决不平衡的问题。
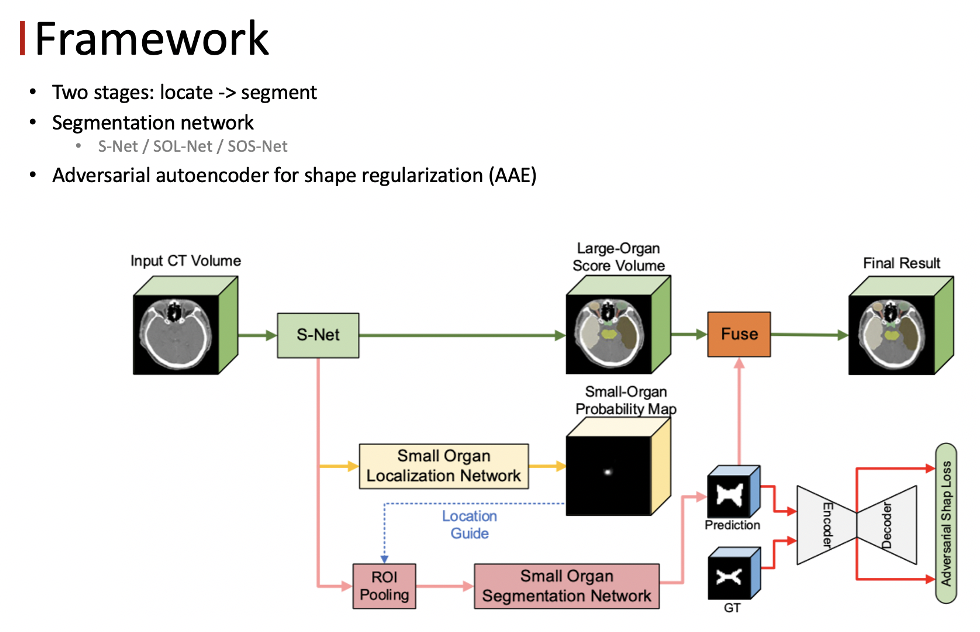
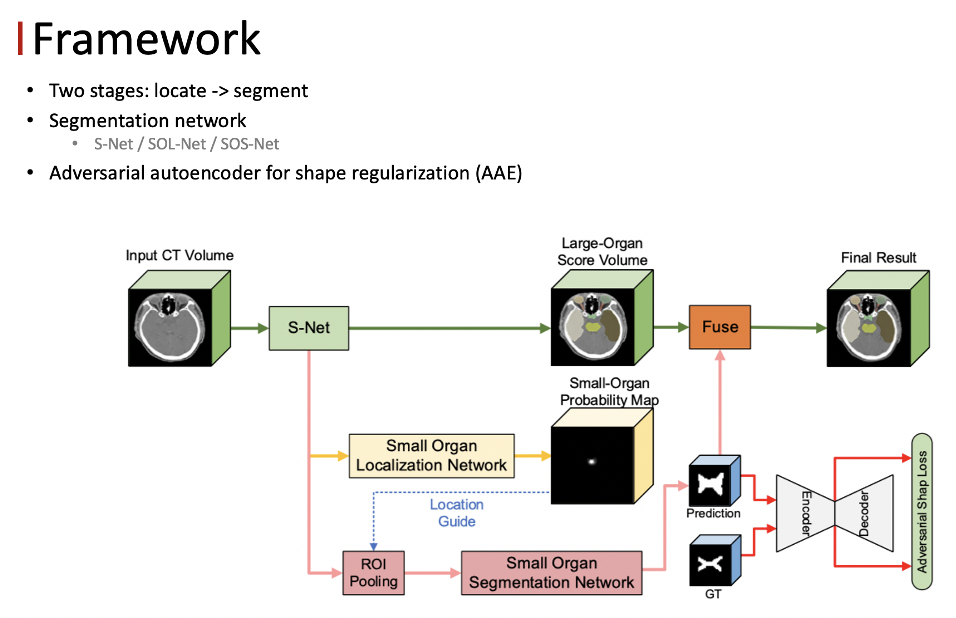
FocusNetV2 包含两个部分,第一部分是分割网络,第二部分是对抗的自编码器。其中分割网络分为三个子网络,主分割网络 S-Net 、小器官的定位网络 SOL-Net 以及小器官的分割网络 SOS-Net 。主分割网络负责对所有的器官进行分割,同时也学习多尺度的 feature ,作为后续操作的输入。
● 分割网络
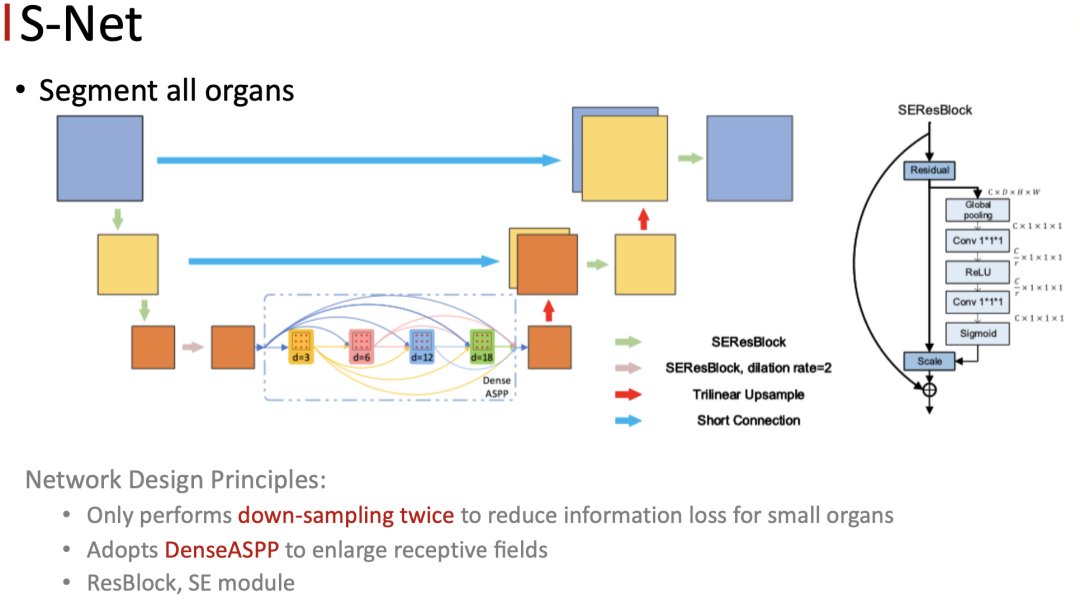
S-Net 的主体结构是一个 3D 的 unet ,但我们发现原始的 unet 在本任务上的表现不是特别的理想,主要的原因是原始的 unet 通过4次的下采样得到高层的 feature ,之后再通过对称的上采样操作来逐渐恢复空间分辨率,并且会通过跨层连接将相同分辨率的 feature 融合,以此来补充由降采样带来的细节损失。
但是本任务中的头部器官小而多,所以在进行 CT扫描的时候只能接受比较小的剂量。因此在数据上承接的分辨率通常只能达到三毫米左右,这导致了一些小器官只在相邻的1~3个slice当中出现。如果做过多的下采样,就会导致小器官的空间细节损失,这一点对于小器官是有灾难性的影响的。
因此我们只做两次的 down sample ,以此来减小小器官的细节的损失,但是这样会带来新的问题:网络的感受野也大大减小了,这会导致网络学不到 global 的信息。为了解决这个问题,我们在 encoder 和 decoder 之间加入了 DenseASPP 模块,用来扩大网络的感受野,同时加入了 ResBlock、SE module 等组件进一步提升性能。
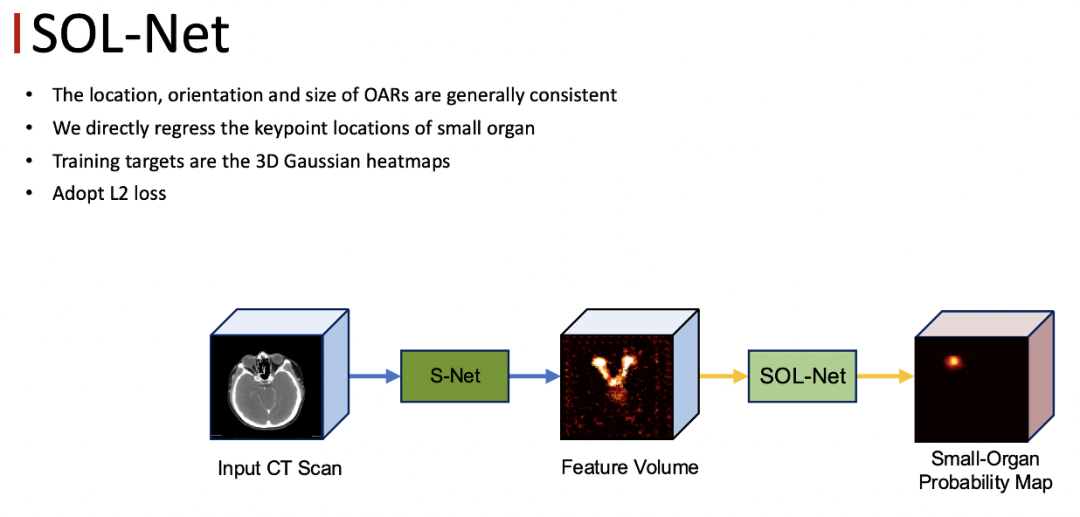
使用了上述网络的设计方法后,大小器官之间的不平衡问题依然没有被解决。我们观察到医生的 zoom in 的操作,和物体检测中的 ROI Pooling 操作是非常一致的,所以我们通过小器官的定位网络以及分割网络来模拟医生的操作。
首先由定位网络来确定每一个小器官的位置,然后单独把每一个小器官裁切出来,在分割网络里面做二类的分割。与自然图像不同,不同人的同一个器官位置大小以及形状等比较一致,所以采用 keypoint 回归的方式来做定位是一种合理的方式。

定位网络的输入是 S-Net 最后一程输出的 feature ,回归的 target 是每一个小器官的中心位置的 Probability Map,可以把它看作三维的高斯的 Heat Map ,我们用 MseLoss 来优化定位网络,得到了每一个小器官的位置之后,将小器官周围的区域作为我们感兴趣的区域,同时将 Feature Map、定位得到的Heat Map以及原始的CT图像contact起来作为 SOS-Net的输入,最终就可以得到每一个小器官的分割结果。这里面的每一个小器官都有一个单独的分割的网络,互不干扰。
此外,我们发现把原始的 CT 图像加入做 refine ,也可以在一定程度上提升性能。对于分割网络来说,我们采用了加权的 focal loss 以及 diceloss 作为损失函数。这两个 loss 对于解决不平衡问题能够起到一定的效果。
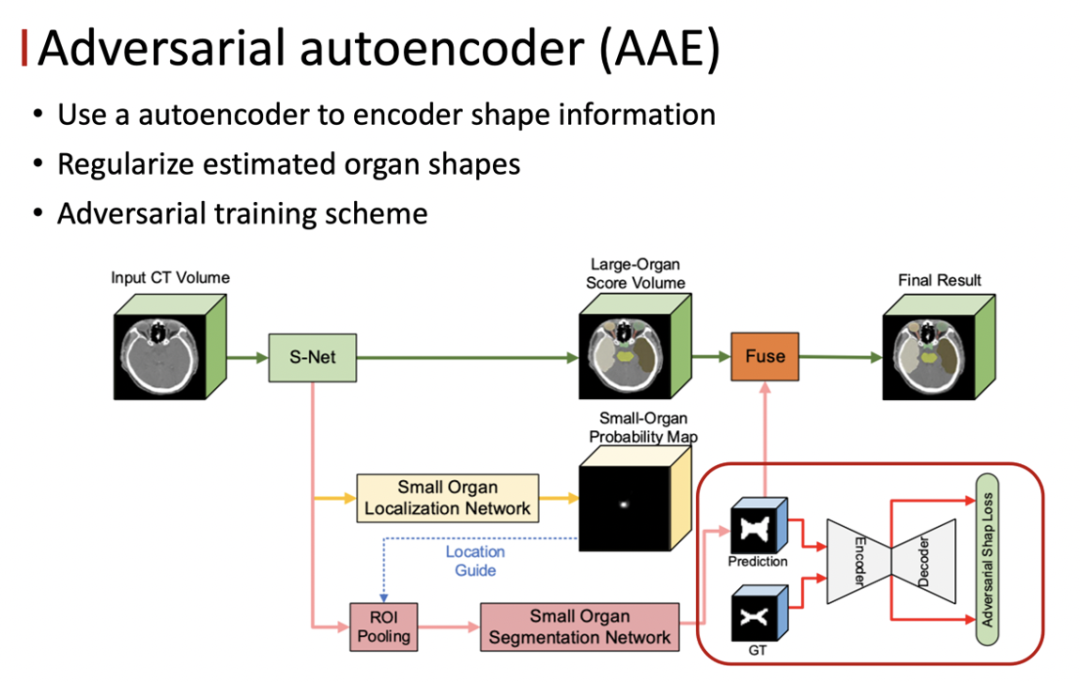
为了解决 CT 边界模糊的问题,需要设计一个比较好的形状约束,我们认为一个好的形状正则化项应该具备两点的特性:第一点,它应该能够以一种可导的方式表征形状信息,所以我们监督信号才能够 BP 回分割网络;第二点,它可以辨出不同形状之间的细微的差别,也就是说监督信息应该对于形状的变化尽可能地敏感。
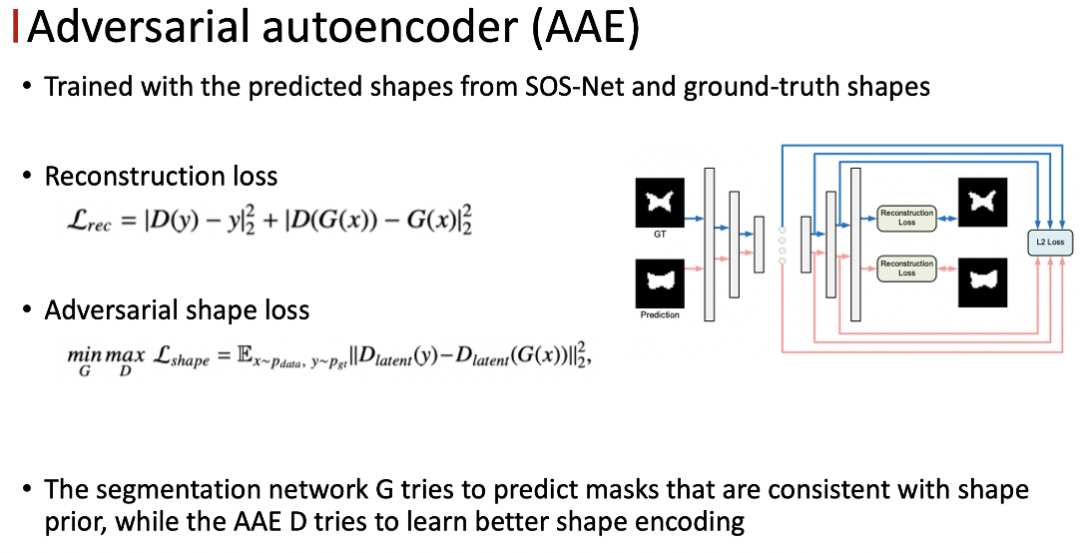
● 对抗的自编码器
我们采用 autoencoder 编码形状信息,通过最小化预测的形状,提供合适的正则化的监督。为了更好的去衡量形状的相似度,我们提出了对抗训练的策略训练 autoencoder 。
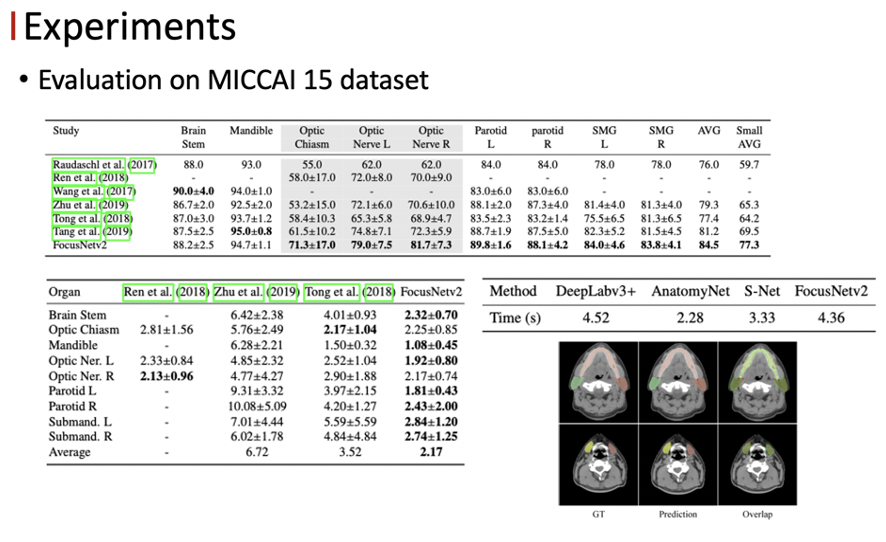
首先我们在内部收集的临床数据集上进行实验,这个数据集是包含了1100多例的头颈部 CT ,22个危及器官,可以看到我们的方法相比于其他的 state-of-the-art 的方法,在精度上有大幅度的提升。

以下可视化的结果中可以看到我们的方法对于视交叉的分割效果是最好的。
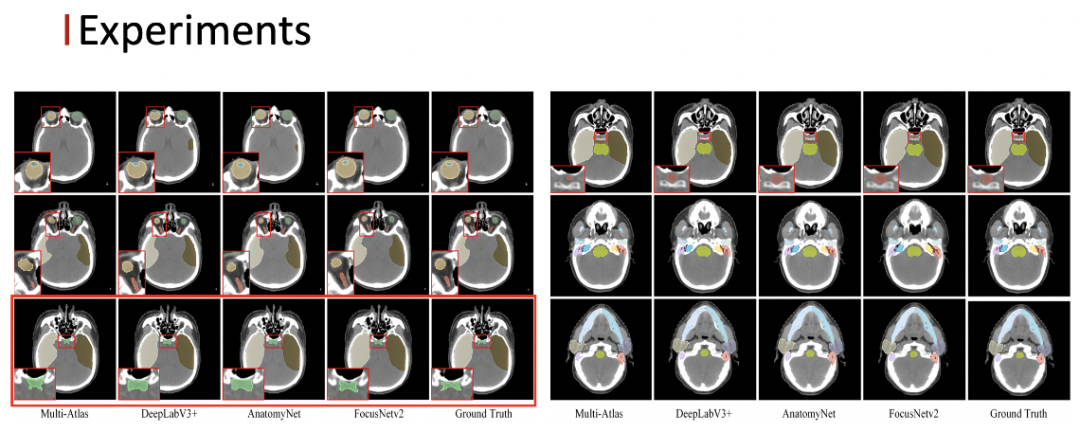
在公开数据集上,我们的方法也达到了目前最好的结果。

论文标题:
FocusNetv2: Imbalanced large and small organ segmentation with adversarial shape constraint for head and neck CT images
论文地址:
https://www.sciencedirect.com/science/article/pii/S136184152030195X
3. 基于协同训练和平均模型的多器官分割
本工作主要关注器官标注缺失的问题。医学图像的标注成本其实是非常高的,所以在大多数的场景下只有部分的器官被标注。
以LiTS数据集为例,只有肝脏器官被标注,其他器官其实被当成背景来对待。类似的, KiTS数据集只有肾脏被标注, Pancreas数据集就只有胰腺被标注了,我们把这种数据集定义为few-organ datasets。很多时候在临床上,我们需要将所有的器官分割出来去做综合的分析。
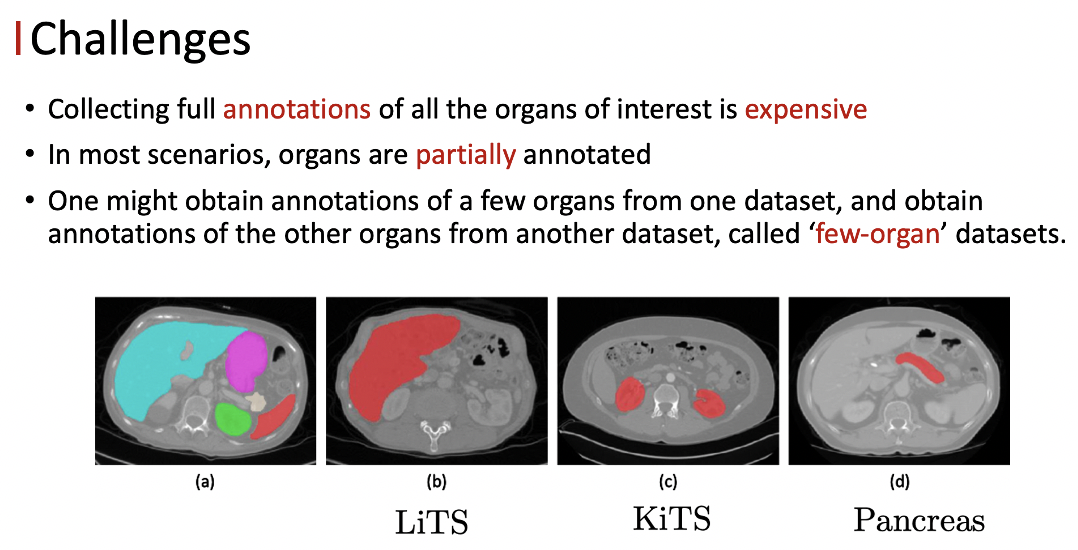
如何利用few-organ datasets学习统一的多器官的分割模型?
已有方法:
● Train and deploy a single model for each subset of organs
对每一个 subset的器官去学一个模型,用多个模型去做inference。缺点是计算效率低;不同器官之间的的空间关系也不能被很好的利用起来。
● self-training:在第一种方法的基础上,为每一个标注缺失的器官生成伪标签,得到一个混合了真实标签和伪标签的全标注的数据集,在此基础上再去学多器官的模型。缺点是每一个子模型的泛化能力是有限的,同时不同的数据集之间也存在一定的domain gap,得到的这些伪标签里包含有大量的噪声,损害到模型的训练。
● ConditionCNN:将类别的编码作为条件信息去嵌入到CNN当中,实现多器官的分割。缺点是influence的效率比较低,没有办法处理器官数比较多的情况。
我们的方法是对 self-training的拓展,抑制伪标签里包含的噪声。我们发现通过利用co-training的策略,以及滑动的平均模型,可以有效地缓解伪标签里包含的有噪声的监督。
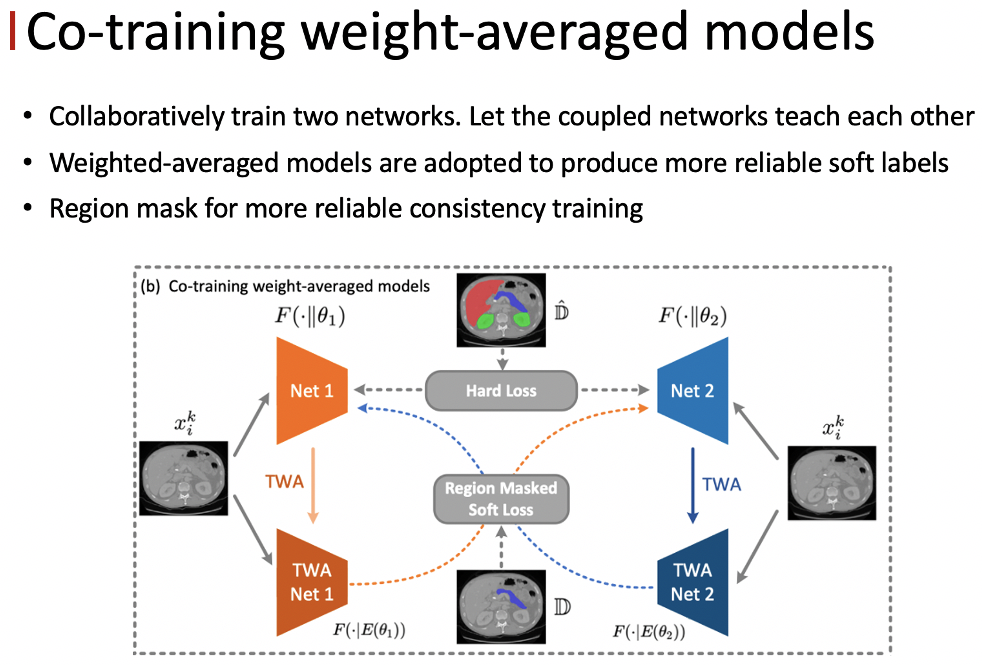
我们采用了一种co-training 的策略,同时去训练两个结构相同的网络,但它们具有不同的初始化的参数,让这两个网络互相学习,通过这种解耦的方式可以有效地防止误差的不断累积。为了生成更加鲁棒的 soft label ,我们会利用其中一个网络时序的平均模型产生的输出作为另一个网络的监督信号。
另外只有这些未标注的区域才是会包含噪声的,所以我们用 Region mask 将监督只作用在 unlabel 的区域上。

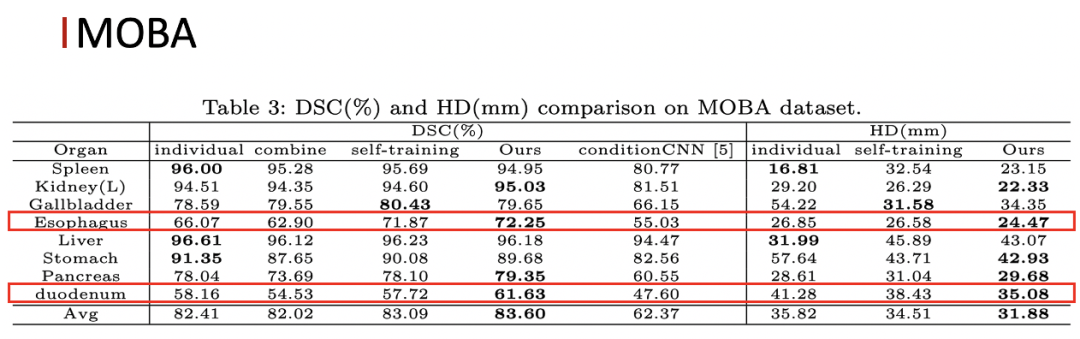
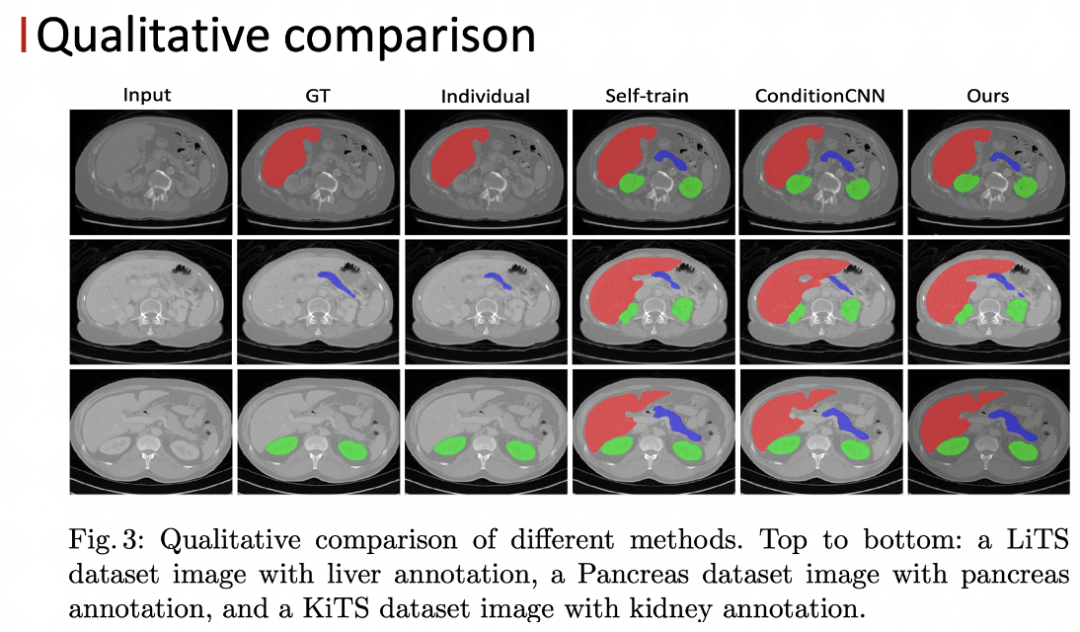
实验部分,在一个三器官的 few-organ 数据集上,我们的方法相比baselinne以及 self-training 都有一定的提升,特别是对于一些小器官的提升会更加明显。同时我们的方法也以更高的计算效率超过了 ConditionCNN 的结果。在更加 challenging 的八器官的 few-organ 数据集上,我们的方法也取得了比较好的结果。
论文标题:
Multi-organ Segmentation via Co-training Weight-averaged Models from Few-organ Datasets
论文地址:
https://arxiv.org/abs/2008.07149
4. What’s next
● Annotation-Efficient Learning:医学图像的标注成本昂贵,所以应该思考如何高效率的去利用已有的这些标注的信息。
● Incorporate prior knowledge:医学图像领域比较依赖先验知识,如何能够把更多的先验知识给融入到神经网络的学习过程中,使得模型的可解释性更强,是一个很值得研究的方向。
● Domain Adaptation:如何去提高模型的一个跨中心的泛化能力。
Q&A
Q: 额外使用GAN来引入形状先验做约束,GAN本身的训练比较难收敛,需要做预训练吗?
A: Autoencoder是需要做预训练的。简单介绍一下整个框架的训练流程:第一个阶段我们会先训 S-Net,然后把参数fix住,然后再去训 SOL-Net,然后把这两块的参数face,再去train SOS-net。之后就会把pretraining好的 autoencoder接进来进行训练。最终对这4个部分去做联合优化。分阶段的去训,才能够把每一个部分给训到比较好的状态。
Q: 与小器官的先检测再分割不同,为什么不需要对大器官做检测就可以直接分割?
A: 我们发现我们只用主分割网络时,大器官的分割精度已经能够达到比较好的效果了。即使用处理小器官的方式去处理大器官,精度也并不会有明显的提升。
Q: 能不能解释一下soft label loss?
A:Soft label loss中,我们可以先不看region mask,剩下这部分是cross entropy,其中外面的F可以看作是监督信号中TWA Net 1的输出;log里面的 F可以看作待优化的网络的输出,在这里就是TWA Net2的输出,这两项就构成了一个cross entropy,外面的tao是region mask。我们只会把没有标注的区域选择出来,只有这些位置是有loss的,有标注位置的loss都是被置零的。
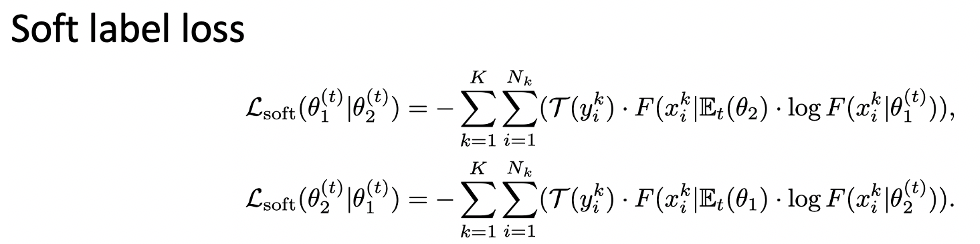
PPT下载
在本公众号【智东西公开课Pro】后台回复“ 医疗04 ”获取完整PPT。
直播回放
6月14日,智东西公开课联合新华三、英伟达策划推出的「AI/HPC加速医疗影像分析与药物研发在线研讨会」直播已完结。英伟达解决方案架构师张萌和新华三集团医疗行业解决方案架构师董兆辉主讲,主题分别为《基于NVIDIA Clara的医疗影像分析与药物研发》、《新华三高性能计算推动医疗行业科研探究》。感兴趣的朋友可以点击原文观看回放。