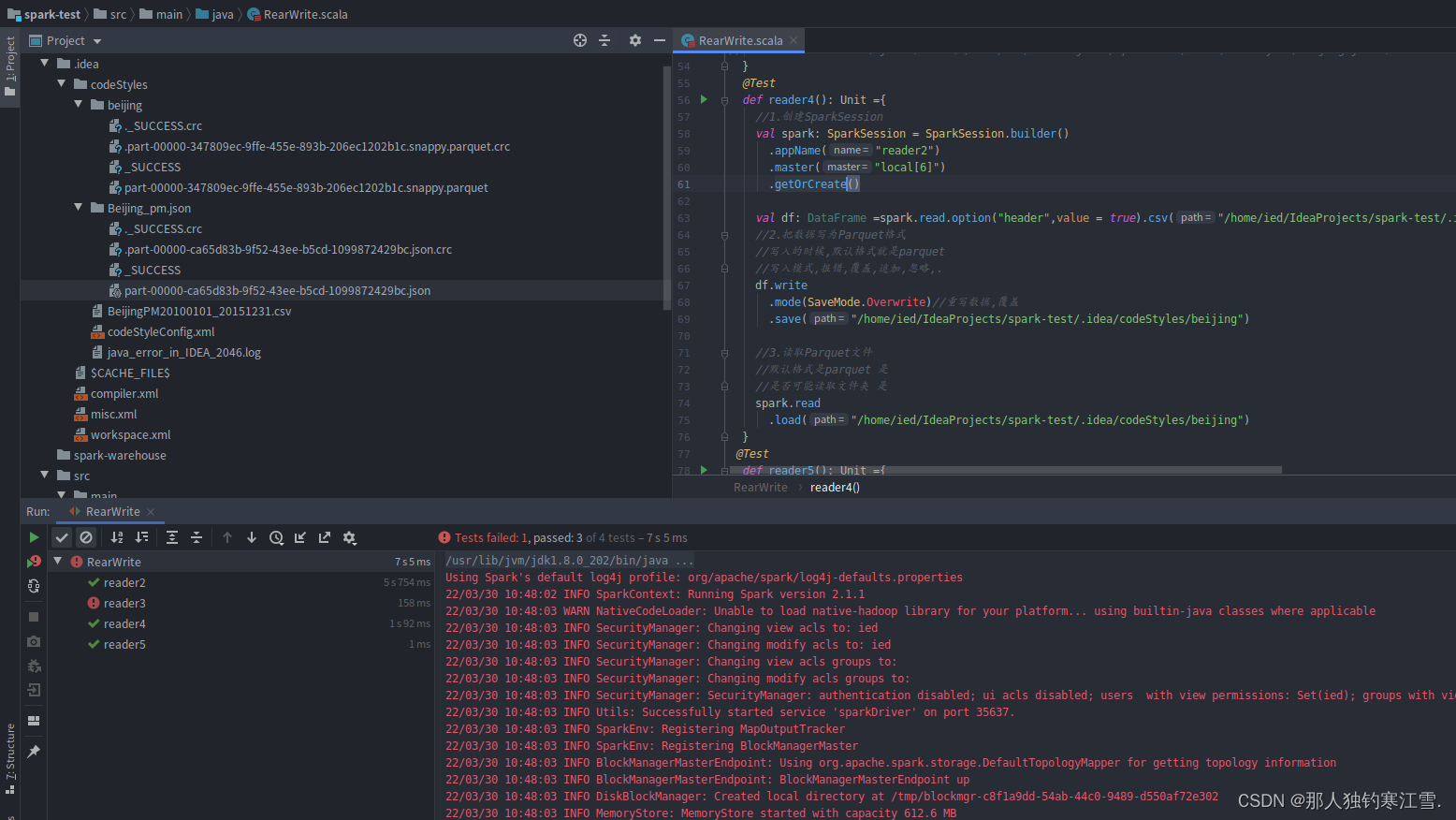
import org.apache.spark.sql.{
DataFrame, DataFrameReader, SaveMode, SparkSession}
import org.junit.Test
class RearWrite {
// @Test
// def reader1(): Unit ={
// //1.创建SparkSession
// val spark: SparkSession =SparkSession.builder()
// .appName("reader1")
// .master("local[6]")
// .getOrCreate()
//
// //2.框架在哪
// val reader: DataFrameReader =spark.read
// }
@Test
def reader2(): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName("reader2")
.master("local[6]")
.getOrCreate()
//2.第一种形式
spark.read
.format("csv")
.option("header",value = true)//排除头部第一个数据
.option("inferSchema",value = true)//包含了很多类型
.load("/home/ied/IdeaProjects/spark-test/.idea/codeStyles/BeijingPM20100101_20151231.csv")//加载路径
.show(10)//读取十条数据
//第二种形式
spark.read
.option("header",value = true)//头部数据
.option("inferSchema",value=true)
.csv("/home/ied/IdeaProjects/spark-test/.idea/codeStyles/BeijingPM20100101_20151231.csv")
.show()
}
@Test
def reader3(): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName("reader2")
.master("local[6]")
.getOrCreate()
//2.读取数据集
val df: DataFrame =spark.read.option("header",true).csv("/home/ied/IdeaProjects/spark-test/.idea/codeStyles/BeijingPM20100101_20151231.csv")
//3.写入数据集
df.write.json("/home/ied/IdeaProjects/spark-test/.idea/codeStyles/Beijing_pm.json")//修改文件类型
//第二种写法
// df.write.format("json").save("/home/ied/IdeaProjects/spark-test/.idea/codeStyles/Beijing.json")
}
@Test
def reader4(): Unit ={
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName("reader2")
.master("local[6]")
.getOrCreate()
val df: DataFrame =spark.read.option("header",value = true).csv("/home/ied/IdeaProjects/spark-test/.idea/codeStyles/BeijingPM20100101_20151231.csv")
//2.把数据写为Parquet格式
//写入的时候,默认格式就是parquet
//写入模式,报错,覆盖,追加,忽略,.
df.write
.mode(SaveMode.Overwrite)//重写数据,覆盖
.save("/home/ied/IdeaProjects/spark-test/.idea/codeStyles/beijing")
//3.读取Parquet文件
//默认格式是parquet 是
//是否可能读取文件夹 是
spark.read
.load("/home/ied/IdeaProjects/spark-test/.idea/codeStyles/beijing")
}
@Test
def reader5(): Unit ={
val spark: SparkSession =new sql.SparkSession.Builder()
.master("local[6]")
.appName("reader5")
.getOrCreate()
}
}