在这篇文章中,我们将比较不同的数据预处理技术(特别是处理缺失值和分类变量的不同方法)和机器学习模型应用于表格数据集的性能。我们将分别讨论所有的步骤,最后再把它们结合起来。
目录
- 简介
- 安装和设置
- 数据集加载和准备
- 处理缺失值
- 处理分类变量
- 不同的机器学习模型
- 测试、结果和结果的解释
- 总结
绪论
机器学习有几个步骤,包括各种预处理步骤和创建/训练一个模型。
机器学习工作流程的每个步骤都有多种方法。我们将讨论处理缺失值和分类变量的不同方法,同时我们也将讨论不同的机器学习模型。
我们将首先对不同的预处理技术和机器学习模型进行解释。然后,我们将实现并比较它们。
处理缺失值
在现实世界的数据集中,有缺失值是一个常见的问题。缺失值被定义为数据集中某些变量不存在的数据。
我们将使用的数据集(关于它的更多信息在后面)包含缺失值。下面的截图显示了两个缺失值的实例。
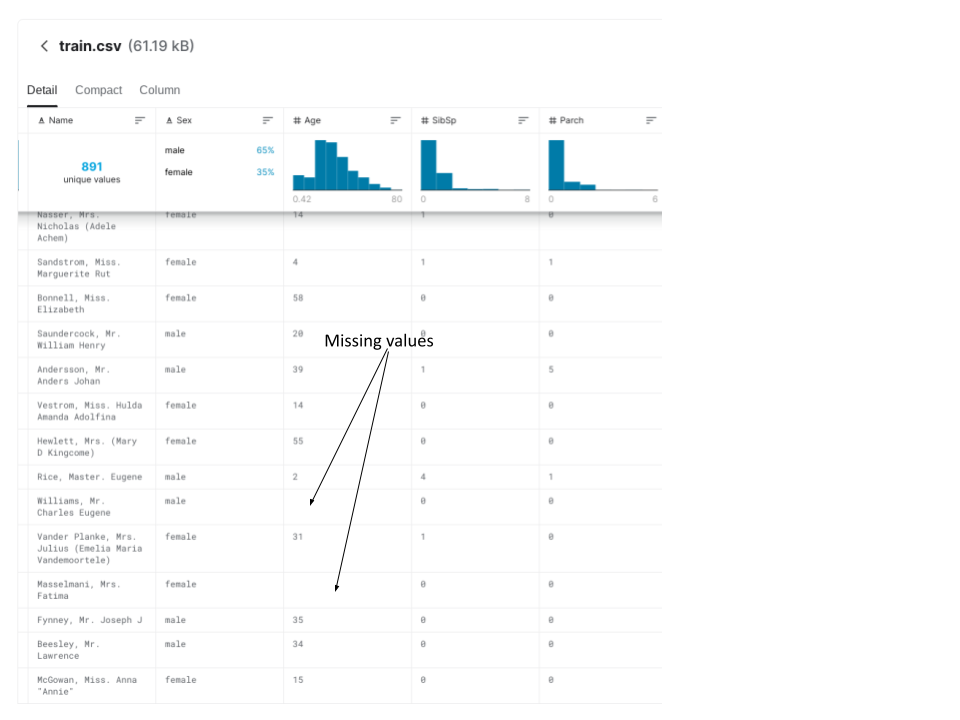
我们将讨论两种处理缺失值的技术。
- 删除有缺失值的列
- 归纳法。试图通过使用列的平均值(如果是数字特征)或使用最频繁的类(如果是分类特征)来填补特征的缺失值。
处理分类变量
数据集包含分类变量(从有限的几个可能的值中选择一个的变量),这些变量不能用整数表示。例如,我们将要使用的数据集包含一个名为 "性别 "的列,这是一个分类变量的例子。
如果我们试图输入分类变量而不对其进行预处理,Python中的大多数机器学习模型都会出现错误,所以处理分类变量是机器学习的一个重要步骤。
我们将看一下处理分类变量的三种方法。
- 删除分类变量
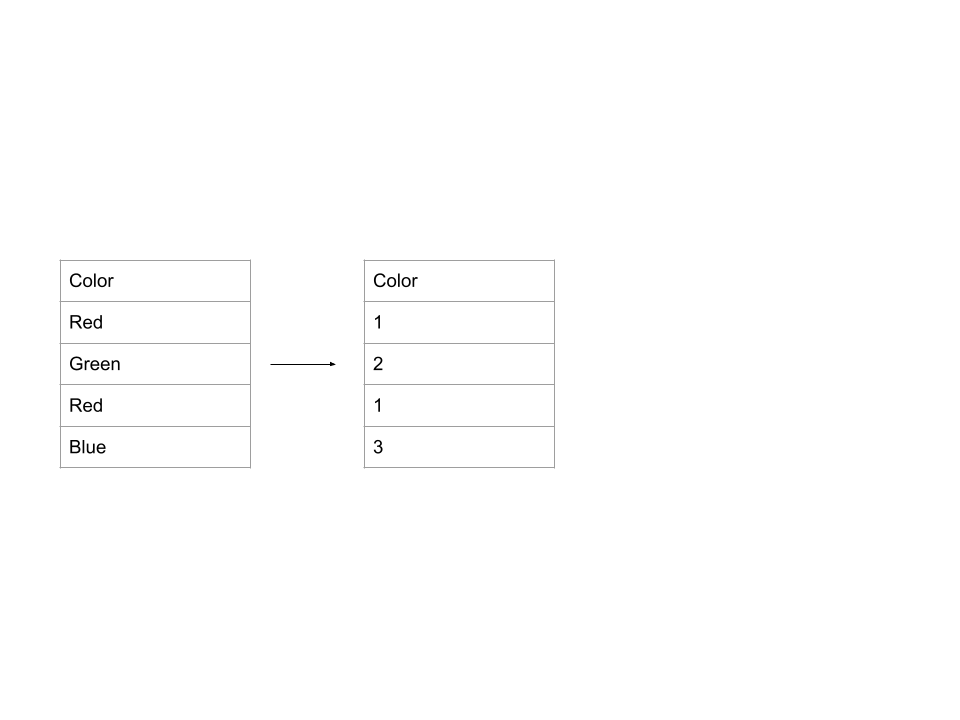
- 顺序编码:为每个可能的值分配一个唯一的数字。例如。
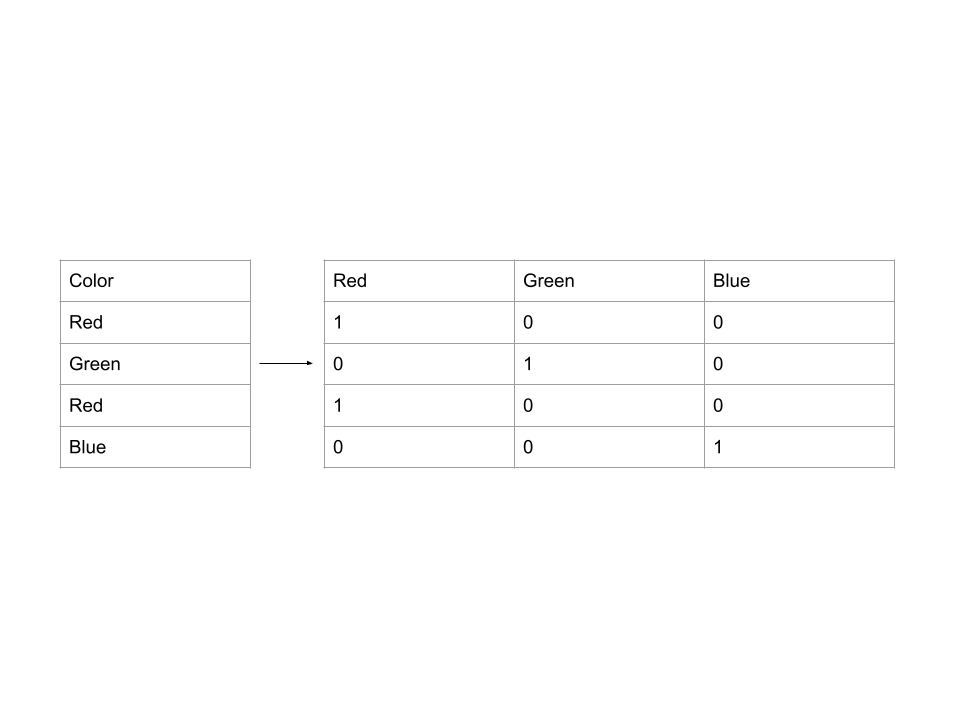
- 一热编码:创建新的列,表示原始数据中每个可能值的存在或不存在。例子。
不同的机器学习模型
有很多不同的机器学习模型,可以用于各种类型的问题。我们将对三种不同的模型进行研究。
- 支持向量机(SVM)。支持向量机(SVM)是一个用于分类和回归问题的线性模型,它创建了一条线或一个超平面,可以最好地将数据分成几类。SVM试图通过寻找最接近直线的点(称为支持向量)来找到最佳超平面,并计算直线和支持向量之间的欧几里得距离,这被称为边际,SVM的目标是使这个边际最大化。换句话说,SVM试图以这样的方式建立一个边界,使不同类别之间的分离尽可能地宽。
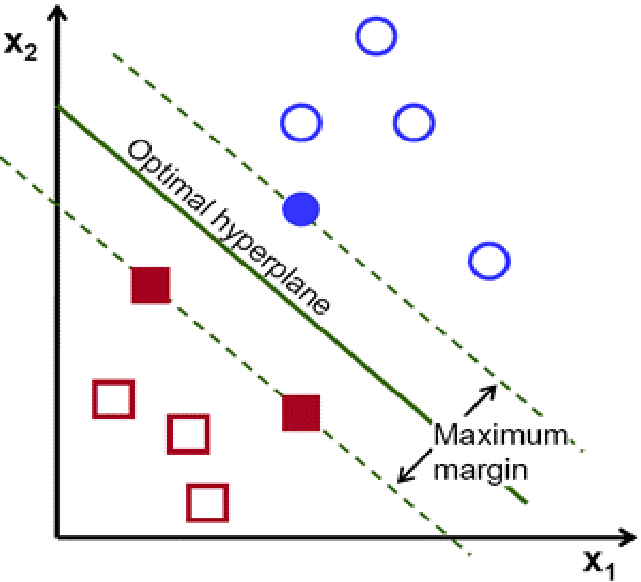
上图--SVM的最佳超平面和边际(Fidan等人,2020)*这张图显示了一个最佳的超平面,它能使边际(支持向量和超平面之间的距离)最大化。
-
Logistic回归。Logistic回归是一种有监督的机器学习算法,用于对某一类别或事件的概率进行建模。当数据是线性可分离的,通常用于二元分类任务。这种算法的核心是logistic函数(也称为sigmoid函数),它可以取任何实数并将其映射为0(排除)和1(排除)之间的值。由于这个原因,逻辑回归的预测y值在0和1之间,而线性回归的预测y值则可以超过这个范围。
-
随机森林。随机森林算法由大量单独的决策树组成,作为一个集合体运行。当对一个样本进行预测时,每棵树都输出一个类别,拥有最多 "选票 "的类别被输出为随机森林的预测值。随机森林的一个优点是它是一个非黑箱模型,这意味着它可以解释它为预测一个特定结果所采取的步骤。
安装和设置
在这篇文章中,我们将需要以下库。
- Pandas
- NumPy
- Scikit-Learn
- XGBoost
使用pip 安装上述库。
pip install pandas
pip install numpy
pip install scikit-learn
pip install xgboost
复制代码导入必要的库。
from warnings import filterwarnings
import numpy as np
import pandas as pd
from sklearn import svm
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder
from xgboost import XGBClassifier
复制代码数据集加载和准备
在这篇文章中,我们将使用来自泰坦尼克号的数据集*--从灾难中学习机器的*Kaggle竞赛。它可以通过这个链接找到。我们将使用 "train.csv "文件。
我们的目标是确定泰坦尼克号的乘客是否会在给定的一些信息中幸存下来。
读取数据
使用pd.read_csv 加载数据。
df = pd.read_csv("train.csv")
复制代码让我们查看一下数据集的前几行。
df.head()
复制代码
让我们把df 分成X ,它存储的是特征,而y ,它存储的是标签("幸存的 "列)。我们不会使用 "PassengerId "和 "Name "来训练我们的模型,所以我们也会放弃这些列。
y = df["Survived"]
X = df.drop(["Survived", "PassengerId", "Name"], axis=1) #drops all the columns we don't need in X
复制代码分割数据
我们将把数据集分成80%的训练和20%的验证。我们训练的模型将在验证数据上进行评估。
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0)
复制代码处理缺失值
为了确定数据集中的哪些列有缺失值,我们可以运行以下代码。
cols_with_missing = [col for col in X_train.columns if X_train[col].isnull().any()]
print(cols_with_missing)
复制代码['Age', 'Cabin', 'Embarked']
复制代码我们可以看到,"年龄"、"舱位 "和 "登船 "这几列包含缺失值。
我们有多种方法可以处理缺失值,我们将介绍其中的两种方法:删除缺失值的列,以及使用归因法。
方法1:删除缺失值
处理缺失值的最容易和最简单的方法是简单地删除缺失值的列。
cols_with_missing = [col for col in X_train.columns if X_train[col].isnull().any()]
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
复制代码然而,这可能会删除一些重要的信息。
选项2:归因法
我们可以根据数字特征的平均值和分类特征的最频繁类别来填补缺失值。我们通过创建两个SimpleImputer 对象来实现这一目的,其中一个采用 "平均值 "策略,用于数字列,另一个采用 "最频繁 "策略,用于分类数据。
# create a list of numerical columns
numerical_cols = X_train.select_dtypes(include=np.number).columns.tolist()
# create a list of categorical columns
s = (X_train.dtypes == 'object')
categorical_cols = list(s[s].index)
# create a copy of the original data so that none of the original data is changed
imputed_X_train = X_train.copy()
imputed_X_valid = X_valid.copy()
# create two imputers - one for the numerical columns, and the other for the categorical columns
numerical_imputer = SimpleImputer(strategy="mean")
categorical_imputer = SimpleImputer(strategy="most_frequent")
# use the imputer and update the training data
imputed_X_train[numerical_cols] = numerical_imputer.fit_transform(imputed_X_train[numerical_cols])
imputed_X_train[categorical_cols] = categorical_imputer.fit_transform(imputed_X_train[categorical_cols])
# use the imputer and update the validation data
imputed_X_valid[numerical_cols] = numerical_imputer.transform(imputed_X_valid[numerical_cols])
imputed_X_valid[categorical_cols] = categorical_imputer.transform(imputed_X_valid[categorical_cols])
复制代码处理分类变量
数据集的一些列是分类变量(从有限的几个可能的值中选择一个的变量),并不由整数表示。
为了确定哪些特征是分类的,我们要检查数据类型,或者dtype 。在这个数据集中,带有文本的列表示分类变量。
# Get list of categorical variables
s = (imputed_X_train.dtypes == 'object')
categorical_cols = list(s[s].index)
print("Categorical variables:")
print(categorical_cols)
复制代码Categorical variables:
['Sex', 'Ticket', 'Cabin', 'Embarked']
复制代码让我们检查一下这些分类变量,看一下独特的类的数量。
for feature in categorical_cols:
print(f"{feature}: {len(imputed_X_train[feature].unique())}")
复制代码Sex: 2
Ticket: 569
Cabin: 127
Embarked: 3
复制代码我们可以看到,"机票 "和 "机舱 "这两列有许多不同的值。为了简单起见,我们将不考虑这些列。
# delete the "Ticket" and "Cabin" columns from both the training and validation data
imputed_X_train.drop(["Ticket", "Cabin"], axis=1, inplace=True)
imputed_X_valid.drop(["Ticket", "Cabin"], axis=1, inplace=True)
reduced_X_train.drop("Ticket", axis=1, inplace=True) # cabin was already dropped when missing values were dropped
reduced_X_valid.drop("Ticket", axis=1, inplace=True) # cabin was already dropped when missing values were dropped
复制代码注意:inplace=True 直接更新数据框架,而不是返回一个副本。
有各种方法来处理分类特征。我们将看看其中的三种方法:放弃分类特征、序数编码和单热编码。
对于每一种不同的技术,我们将创建函数,以便在测试最终模型时可以轻松使用。
丢弃分类特征
处理分类特征的最简单方法是放弃它们。这种方法只有在这些列不包含有用信息的情况下才能很好地发挥作用。
def drop_categorical_variables(train_df, valid_df):
drop_train = train_df.select_dtypes(exclude=['object'])
drop_valid = valid_df.select_dtypes(exclude=['object'])
return drop_train, drop_valid
复制代码drop_X_train, drop_X_valid = drop_categorical_variables(imputed_X_train, imputed_X_valid)
复制代码上面的代码创建了两个新的数据框架:drop_X_train 和drop_X_valid 。这两个数据框架排除了所有类型为object 的列。
我们可以通过输出drop_X_train 包含的列的列表来确认分类变量已经被删除。
print(list(drop_X_train.columns))
复制代码['Pclass', 'Age', 'SibSp', 'Parch', 'Fare']
复制代码顺序编码
顺序编码为每个独特的值分配一个不同的整数。
例如,让我们看一下 "Embarked "列的不同值。
print(list(imputed_X_train["Embarked"].unique()))
复制代码['C', 'S', 'Q']
复制代码让我们对每个分类变量进行编码。
def ordinal_encode(train_df, val_df):
s = (train_df.dtypes == 'object')
categorical_cols = list(s[s].index)
# Apply ordinal encoder to each column with categorical data
ordinal_encoded_X_train = train_df.copy()
ordinal_encoded_X_valid = val_df.copy()
ordinal_encoder = OrdinalEncoder()
ordinal_encoded_X_train[categorical_cols] = ordinal_encoder.fit_transform(train_df[categorical_cols])
ordinal_encoded_X_valid[categorical_cols] = ordinal_encoder.transform(val_df[categorical_cols])
return ordinal_encoded_X_train, ordinal_encoded_X_valid
复制代码ordinal_encoded_X_train, ordinal_encoded_X_valid = ordinal_encode(imputed_X_train, imputed_X_valid)
复制代码现在,让我们看看 "Embarked "列的数值如何变化。
print(list(ordinal_encoded_X_train["Embarked"].unique()))
复制代码[0.0, 2.0, 1.0]
复制代码一热编码
一热编码产生新的列,表示原始数据中每个可能的值的存在或不存在。
例如,当一热编码应用于 "登船 "列时,它将产生 "C"、"S "和 "Q "列。这些列中的每一列都将包含1或0,其中1代表原始数据包含该值。
def one_hot_encode(train_df, validation_df):
s = (train_df.dtypes == 'object')
categorical_cols = list(s[s].index)
# handle_unknown='ignore' helps avoid errors when the validation data contains classes that are not in the training data
# sparse = false makes sure that it returns a numpy array instead of a sparse matrix
encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
# create new dataframes for the one-hot encoded features
OH_cols_train = pd.DataFrame(encoder.fit_transform(train_df[categorical_cols]))
OH_cols_valid = pd.DataFrame(encoder.transform(validation_df[categorical_cols]))
# One-hot encoding removed the index, so we put it back here.
# This is used for combining the one-hot encoded columns with the numerical columns, otherwise alignment issues arise
OH_cols_train.index = train_df.index
OH_cols_valid.index = validation_df.index
# fix the column names
OH_cols_train.columns = encoder.get_feature_names_out()
OH_cols_valid.columns = encoder.get_feature_names_out()
# remove the original categorical columns
num_X_train = train_df.drop(categorical_cols, axis=1)
num_X_valid = validation_df.drop(categorical_cols, axis=1)
# combine the encoded features to the numerical features
OH_X_train = pd.concat([num_X_train, OH_cols_train], axis=1)
OH_X_valid = pd.concat([num_X_valid, OH_cols_valid], axis=1)
return OH_X_train, OH_X_valid
复制代码OH_X_train, OH_X_valid = one_hot_encode(imputed_X_train, imputed_X_valid)
OH_X_valid.head()
复制代码
不同的机器学习模型
我们将训练和评估三种不同的模型--支持向量机(SVM)、逻辑回归和随机森林。
在下面的例子中,我们将对单次编码的数据进行训练。
支持向量机(SVM)
支持向量机是一种有监督的机器学习算法,它使用超平面或直线将数据分成不同的类别。
下面的代码创建并训练了一个支持向量机模型。
svm_clf = svm.LinearSVC()
svm_clf.fit(OH_X_train, y_train)
复制代码Logistic回归
Logistic回归通过将数据拟合到一个logit函数来预测输出类的概率。
lr=LogisticRegression()
lr.fit(OH_X_train, y_train)
复制代码随机森林
随机森林是一个由多个决策树组成的集合模型。
clf = RandomForestClassifier()
clf.fit(OH_X_train, y_train)
复制代码根据所使用的分类变量编码技术,我们会将不同的数据帧传入fit 。
测试、结果和对结果的解释
我们将创建一个所有训练和验证数据帧的列表,我们将使用这些数据帧训练模型。首先,我们将创建一个带有处理过的缺失值的数据帧的列表。对于每个数据框,都有一个描述以及训练和验证数据,用一个dict 。
# make sure none of the dataframes contains the "Ticket" or "Cabin" columns - if they do, uncomment the code below
# imputed_X_train.drop(["Ticket", "Cabin"], axis=1, inplace=True)
# imputed_X_valid.drop(["Ticket", "Cabin"], axis=1, inplace=True)
# reduced_X_train.drop(["Ticket", "Cabin"], axis=1, inplace=True)
# reduced_X_valid.drop(["Ticket", "Cabin"], axis=1, inplace=True)
missing_values_handled_dfs = [
{
"description" : "Dropped Missing Values",
"train" : reduced_X_train,
"validation" : reduced_X_valid
},
{
"description" : "Imputed",
"train" : imputed_X_train,
"validation" : imputed_X_valid
}
]
复制代码接下来,我们将使用应用不同的分类变量处理技术,并创建一个所有可能的数据帧对(训练和验证)的列表。换句话说,对于每一种缺失值处理技术,都有三对不同的数据框架,每一对都代表所使用的三种分类变量处理技术中的一种。这样一来,我们最终有6对数据框架。
dfs_to_be_used = [] #list of dictionaries - each dict will contain a description, the training dataframe, and the validation dataframe
for df_dict in missing_values_handled_dfs:
train_df = df_dict["train"]
validation_df = df_dict["validation"]
description = df_dict["description"]
# drop categorical features
drop_X_train, drop_X_valid = drop_categorical_variables(train_df, validation_df)
dfs_to_be_used.append({
"description" : description + ", dropped categorical features",
"train" : drop_X_train,
"validation" : drop_X_valid
})
# ordinal encoding
ordinal_encoded_X_train, ordinal_encoded_X_valid = ordinal_encode(train_df, validation_df)
dfs_to_be_used.append({
"description" : description + ", ordinal encoding ",
"train" : ordinal_encoded_X_train,
"validation" : ordinal_encoded_X_valid
})
#one-hot encoding
OH_X_train, OH_X_valid = one_hot_encode(train_df, validation_df)
dfs_to_be_used.append({
"description" : description + ", one-hot encoding ",
"train" : OH_X_train,
"validation" : OH_X_valid
})
复制代码接下来,我们将在这6个数据框中的每一个上测试所有不同的模型并记录结果。
在训练一些模型时,有时会有警告输出。我们可以通过运行以下代码来禁用这些警告。
filterwarnings('ignore')
复制代码这将使我们更容易阅读结果。
y_train 和y_valid ,下面使用的是在本文开始时创建的,当时我们将数据分成80%的训练和20%的验证,输出每个模型的结果。
for df in dfs_to_be_used:
print(df["description"] + ":")
svm_clf = svm.LinearSVC()
svm_clf.fit(df["train"], y_train)
print("\t" + "SVM: " + str(accuracy_score(y_valid, svm_clf.predict(df["validation"]))))
lr=LogisticRegression()
lr.fit(df["train"], y_train)
print("\t" + "Logistic Regression: " + str(accuracy_score(y_valid, lr.predict(df["validation"]))))
rf = RandomForestClassifier()
rf.fit(df["train"], y_train)
print("\t" + "Random Forest: " + str(accuracy_score(y_valid, rf.predict(df["validation"]))))
复制代码Dropped Missing Values, dropped categorical features:
SVM: 0.7262569832402235
Logistic Regression: 0.7150837988826816
Random Forest: 0.7150837988826816
Dropped Missing Values, ordinal encoding :
SVM: 0.776536312849162
Logistic Regression: 0.7988826815642458
Random Forest: 0.8324022346368715
Dropped Missing Values, one-hot encoding :
SVM: 0.6759776536312849
Logistic Regression: 0.7988826815642458
Random Forest: 0.8379888268156425
Imputed, dropped categorical features:
SVM: 0.6983240223463687
Logistic Regression: 0.7374301675977654
Random Forest: 0.6927374301675978
Imputed, ordinal encoding :
SVM: 0.664804469273743
Logistic Regression: 0.7988826815642458
Random Forest: 0.8324022346368715
Imputed, one-hot encoding :
SVM: 0.8100558659217877
Logistic Regression: 0.8044692737430168
Random Forest: 0.8435754189944135
复制代码正如我们所看到的,在这种情况下,性能最高的模型是随机森林模型,它是在归类和一热编码数据上训练的。
模型在使用编码的分类特征时,往往比删除的分类特征表现得更好。在这个实验中,单热编码与序数编码似乎没有太大的区别,尽管单热编码在大多数情况下通常表现得更好。另外,归纳法也没有什么不同,但归纳法通常比删除缺失值更好。
结论
在这篇文章中,我们看到了不同的机器学习模型和预处理技术在性能上的比较。本文概述了一些最常见的,但还有其他几种预处理技术和模型,可以用来实现不同的结果。
这篇文章就到这里,感谢您的阅读