- yolov5在模型推理阶段,命令如下:
python detect.py --weights runs/exp1/weights/best.pt --source inference/images/ --device 0 --save-txt
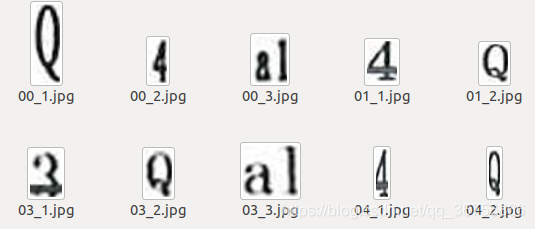
该命令中save_txt选项用于生成结果的txt标注文件,会生成每张图片对应文件名的txt检测框信息文件,每个txt会生成一行一个目标的信息,信息包括类别序号、xcenter ycenter w h,后面四个为bbox位置,均为归一化数值,如下图:
2. python根据yolov5检测得到的txt文件,截取目标框图片并保存(即从原图中裁剪出检测到的目标物小图),代码如下:
# -*- coding: utf-8 -*-
import os
import cv2
path = "jpg_txt" # jpg图片和对应的生成结果的txt标注文件,放在一起
path3 = "bboxcut" # 裁剪出来的小图保存的根目录
w = 100 # 原始图片resize
h = 100
img_total = []
txt_total = []
file = os.listdir(path)
for filename in file:
first,last = os.path.splitext(filename)
if last == ".jpg": # 图片的后缀名
img_total.append(first)
#print(img_total)
else:
txt_total.append(first)
for img_ in img_total:
if img_ in txt_total:
filename_img = img_+".jpg" # 图片的后缀名
# print('filename_img:', filename_img)
path1 = os.path.join(path,filename_img)
img = cv2.imread(path1)
img = cv2.resize(img,(w,h),interpolation = cv2.INTER_CUBIC) # resize 图像大小,否则roi区域可能会报错
filename_txt = img_+".txt"
# print('filename_txt:', filename_txt)
n = 1
with open(os.path.join(path,filename_txt),"r+",encoding="utf-8",errors="ignore") as f:
for line in f:
aa = line.split(" ")
x_center = w * float(aa[1]) # aa[1]左上点的x坐标
y_center = h * float(aa[2]) # aa[2]左上点的y坐标
width = int(w*float(aa[3])) # aa[3]图片width
height = int(h*float(aa[4])) # aa[4]图片height
lefttopx = int(x_center-width/2.0)
lefttopy = int(y_center-height/2.0)
roi = img[lefttopy+1:lefttopy+height+3,lefttopx+1:lefttopx+width+1] # [左上y:右下y,左上x:右下x] (y1:y2,x1:x2)需要调参,否则裁剪出来的小图可能不太好
print('roi:', roi) # 如果不resize图片统一大小,可能会得到有的roi为[]导致报错
filename_last = img_+"_"+str(n)+".jpg" # 裁剪出来的小图文件名
# print(filename_last)
path2 = os.path.join(path3,"roi") # 需要在path3路径下创建一个roi文件夹
print('path2:', path2) # 裁剪小图的保存位置
cv2.imwrite(os.path.join(path2,filename_last),roi)
n = n+1
else:
continue
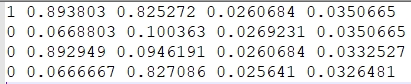
裁剪出来的小图如下: