文章目录
2020 BiSeNetV2
论文题目:
Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation
1. 简介
1.1 简介
BiseNet又称双边分割网络,一般架构是,一边是一个较为粗糙的特征提取网络作为一边,而另一边可以由经典的特征提取网络(EfficientNet,resNet,xception)组成,
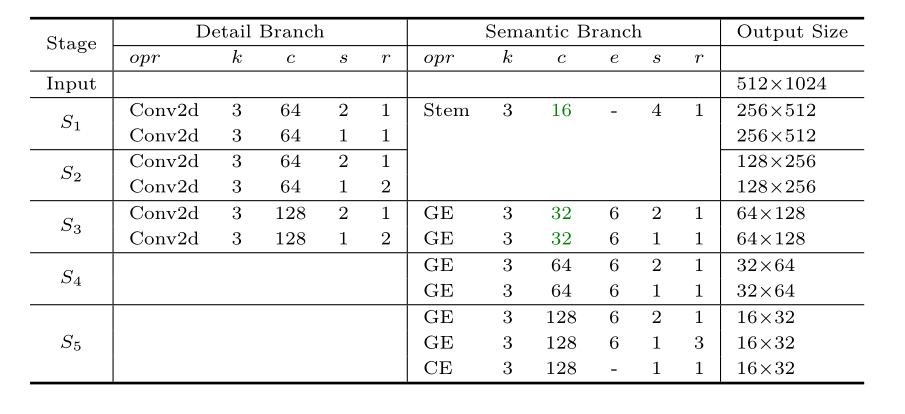
而我们今天的主角BiseNetv2,也类似该架构,在上面(也就是DetailBranch)是一个较为简单的特征提取网络,我们先从他开始构造,他在作者提供的架构图中是这样的(k是卷积核大小,c是输出单元数,s是步长,r是该层重复次数)
1.2 结果

与几种最新的实时语义分割方法相比,BiSeNet V2具有良好的性能。具体来说,对于2048x1,024的输入,BiseNet2在Cityscapes测试集中的平均IoU达到72.6%,在一张NVIDIA GeForce GTX 1080 Ti卡上的速度为156 FPS,这比现有方法要快得多,而且可以实现更好的分割精度。
低层次的细节和高层次的语义是语义分割的基础。然而,为了加快模型推理的速度,目前的方法几乎总是牺牲低层次的细节,这导致了相当大的精度下降。
2. 网络
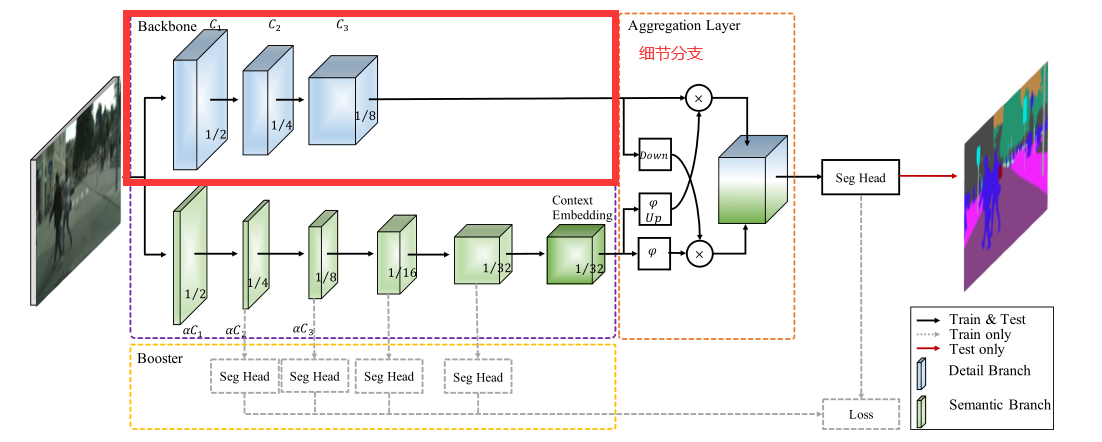
这幅图是BiSeNetV2的总体架构图

- Detail Branch: Detail分支的任务是保存低级特征的空间细节信息,所以该分支的设计理念就是通道多,层数少,下采样比率低。为了防止模型速度降低,没有采用residual connection。
- Semantic Branch:Semantic分支的目标是捕获高级的语义信息,所示他的设计理念是通道少,层数多,下采样比率大(增加感受野)。该分支可替换为其他的backbone。
模型的具体设计如下图(Conv2d后都接BatchNormalization和relu层),k表示卷积核的大小,c表示该层输出的通道数,s表示步长,r表示改层重复次数,e表示卷积的膨胀系数,Stem是Stem Block,GE是Gather and Expansion Layer,CE是Context Embedding Layer。
2.1 细节分支(DetailBranch)
细节分支负责空间细节,这是低级的信息。因此,该分支需要丰富的信道容量来编码丰富的空间细节信息。同时,因为细节分支只关注底层细节,所以我们可以为这个分支设计一个小跨度的浅层结构。总体而言,细节分支的关键概念是使用宽通道和浅层来处理空间细节。此外,该分支的特征表示具有较大的空间尺寸和较宽的信道。因此,最好不要采用残差连接,这样会增加内存访问成本,降低速度。
代码如下
class ConvBNReLU(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1,
dilation=1, groups=1, bias=False):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(
in_chan, out_chan, kernel_size=ks, stride=stride,
padding=padding, dilation=dilation,
groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_chan)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv(x)
feat = self.bn(feat)
feat = self.relu(feat)
return feat
class DetailBranch(nn.Module):
def __init__(self):
super(DetailBranch, self).__init__()
self.S1 = nn.Sequential(
ConvBNReLU(3, 64, 3, stride=2),
ConvBNReLU(64, 64, 3, stride=1),
)
self.S2 = nn.Sequential(
ConvBNReLU(64, 64, 3, stride=2),
ConvBNReLU(64, 64, 3, stride=1),
ConvBNReLU(64, 64, 3, stride=1),
)
self.S3 = nn.Sequential(
ConvBNReLU(64, 128, 3, stride=2),
ConvBNReLU(128, 128, 3, stride=1),
ConvBNReLU(128, 128, 3, stride=1),
)
def forward(self, x):
feat = self.S1(x)
feat = self.S2(feat)
feat = self.S3(feat)
return feat
2.2 语义分支
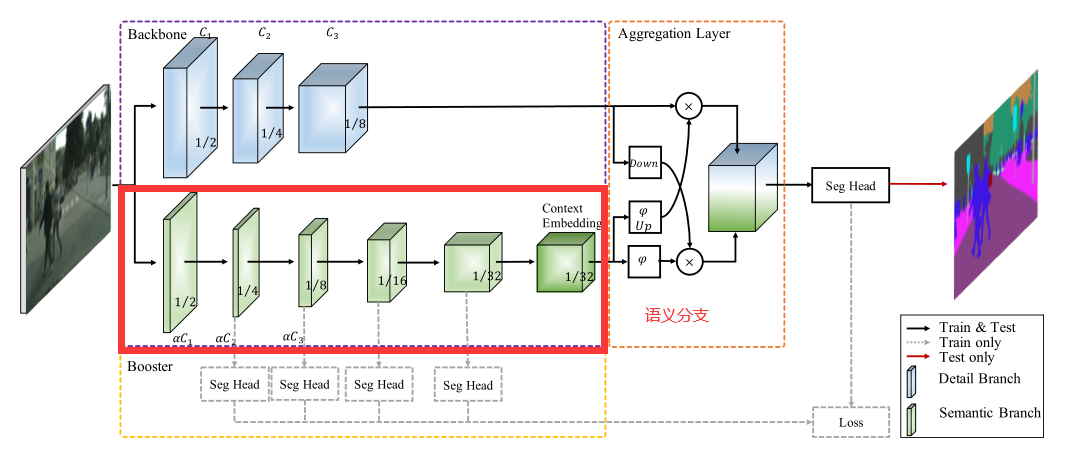
与细节分支并行,语义分支旨在捕获高级语义。该分支的信道容量较低,而空间细节可以由细节分支提供。相反,在我们的实验中,语义分支占比λ(λ<1)细节分支的通道,这使得这个分支是轻量级的。实际上,语义分支可以是任何轻量级的卷积模型。同时,语义分支采用快速下采样策略提高了特征表示的层次,快速扩大了接受域。高级语义需要大量的接受域。因此,语义分支使用全局平均池嵌入全局上下文响应。
考虑到接受域大,计算效率高,设计语义分支,其灵感来自轻量级图像分类模型的理念,如Xception、MobileNet、ShuffleNet 。
语义分支的一些关键特性如下:
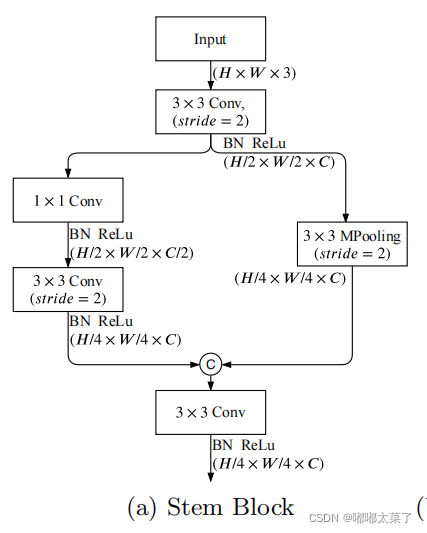
1) Stem Block
Stem Block:采用Stem Block作为语义分支的第一阶段,如图(a)所示。它使用两种不同的下采样方式来缩小特征表示。然后将两个分支的输出特性串联起来作为输出。该结构具有高效的计算成本和有效的特征表达能力。
class StemBlock(nn.Module):
def __init__(self):
super(StemBlock, self).__init__()
self.conv = ConvBNReLU(3, 16, 3, stride=2)
self.left = nn.Sequential(
ConvBNReLU(16, 8, 1, stride=1, padding=0),
ConvBNReLU(8, 16, 3, stride=2),
)
self.right = nn.MaxPool2d(
kernel_size=3, stride=2, padding=1, ceil_mode=False)
self.fuse = ConvBNReLU(32, 16, 3, stride=1)
def forward(self, x):
feat = self.conv(x)
feat_left = self.left(feat)
feat_right = self.right(feat)
feat = torch.cat([feat_left, feat_right], dim=1)
feat = self.fuse(feat)
return feat
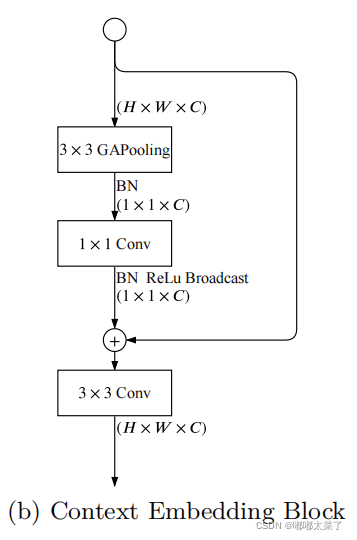
2) Context Embedding Block
该模块使用全局池化和残差连接,在特征图中加入全局上下文信息。
Context Embedding Block:语义分支需要大的接受域来捕获高级语义。所以设计了Context Embedding Block。该块使用全局平均池和残差连接有效地嵌入全局上下文信息,如图(b)所示。
class CEBlock(nn.Module):
def __init__(self):
super(CEBlock, self).__init__()
self.bn = nn.BatchNorm2d(128)
self.conv_gap = ConvBNReLU(128, 128, 1, stride=1, padding=0)
#TODO: in paper here is naive conv2d, no bn-relu
self.conv_last = ConvBNReLU(128, 128, 3, stride=1)
def forward(self, x):
feat = torch.mean(x, dim=(2, 3), keepdim=True)
feat = self.bn(feat)
feat = self.conv_gap(feat)
feat = feat + x
feat = self.conv_last(feat)
return feat
3) Gather and Expansion Layer
下图a是MobileNetV2的逆瓶颈结构,b和c是Gather and expansion layer, b和c的区别在于输出特征图大小不同,当需要降低输入特征图的分辨率时,使用c结构,如果分辨率不变,使用b结构。
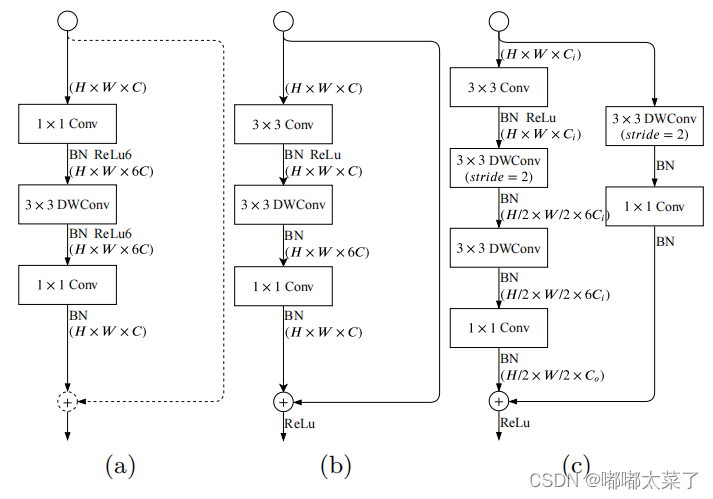
gather and expansion layer代码,上图b的代码:
class GELayerS1(nn.Module):
def __init__(self, in_chan, out_chan, exp_ratio=6):
super(GELayerS1, self).__init__()
mid_chan = in_chan * exp_ratio
self.conv1 = ConvBNReLU(in_chan, in_chan, 3, stride=1)
self.dwconv = nn.Sequential(
nn.Conv2d(
in_chan, mid_chan, kernel_size=3, stride=1,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(mid_chan),
nn.ReLU(inplace=True), # not shown in paper
)
self.conv2 = nn.Sequential(
nn.Conv2d(
mid_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.conv2[1].last_bn = True
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv1(x)
feat = self.dwconv(feat)
feat = self.conv2(feat)
feat = feat + x
feat = self.relu(feat)
return feat
图c的代码:
class GELayerS2(nn.Module):
def __init__(self, in_chan, out_chan, exp_ratio=6):
super(GELayerS2, self).__init__()
mid_chan = in_chan * exp_ratio
self.conv1 = ConvBNReLU(in_chan, in_chan, 3, stride=1)
self.dwconv1 = nn.Sequential(
nn.Conv2d(
in_chan, mid_chan, kernel_size=3, stride=2,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(mid_chan),
)
self.dwconv2 = nn.Sequential(
nn.Conv2d(
mid_chan, mid_chan, kernel_size=3, stride=1,
padding=1, groups=mid_chan, bias=False),
nn.BatchNorm2d(mid_chan),
nn.ReLU(inplace=True), # not shown in paper
)
self.conv2 = nn.Sequential(
nn.Conv2d(
mid_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.conv2[1].last_bn = True
self.shortcut = nn.Sequential(
nn.Conv2d(
in_chan, in_chan, kernel_size=3, stride=2,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(in_chan),
nn.Conv2d(
in_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv1(x)
feat = self.dwconv1(feat)
feat = self.dwconv2(feat)
feat = self.conv2(feat)
shortcut = self.shortcut(x)
feat = feat + shortcut
feat = self.relu(feat)
return feat
2.3 特征融合
Detail分支和Semantic分支的特征图通过Guided Aggregation Layer进行融合,利用Semantic分支得到的上下文信息来指导Detail分支的特征图输出,并且左右2个分支特征图尺度不同,这样可以得到多尺度信息。需要注意的是图中右下角,1/4尺度的输出在求和前有个上采样4倍的操作使得左右分支输出分辨率相同。
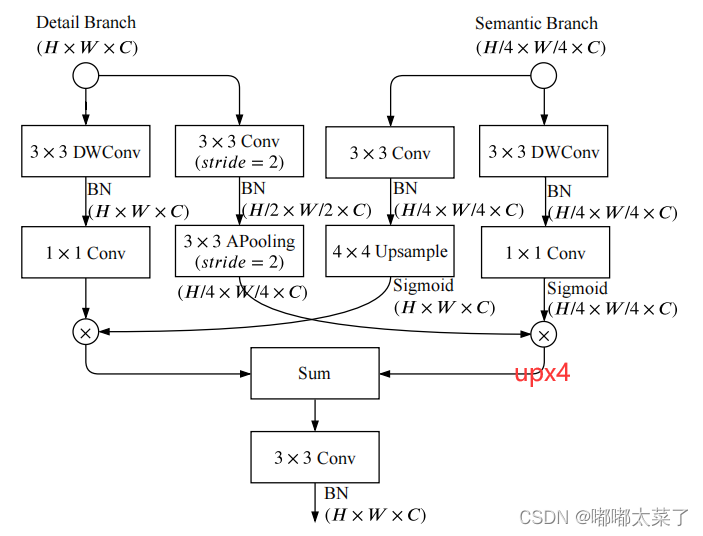
该模块代码如下
class BGALayer(nn.Module):
def __init__(self):
super(BGALayer, self).__init__()
self.left1 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.Conv2d(
128, 128, kernel_size=1, stride=1,
padding=0, bias=False),
)
self.left2 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=2,
padding=1, bias=False),
nn.BatchNorm2d(128),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False)
)
self.right1 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, bias=False),
nn.BatchNorm2d(128),
)
self.right2 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.Conv2d(
128, 128, kernel_size=1, stride=1,
padding=0, bias=False),
)
self.up1 = nn.Upsample(scale_factor=4)
self.up2 = nn.Upsample(scale_factor=4)
##TODO: does this really has no relu?
self.conv = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True), # not shown in paper
)
def forward(self, x_d, x_s):
dsize = x_d.size()[2:]
left1 = self.left1(x_d)
left2 = self.left2(x_d)
right1 = self.right1(x_s)
right2 = self.right2(x_s)
right1 = self.up1(right1)
left = left1 * torch.sigmoid(right1)
right = left2 * torch.sigmoid(right2)
right = self.up2(right)
out = self.conv(left + right)
return out
2.4 分割头
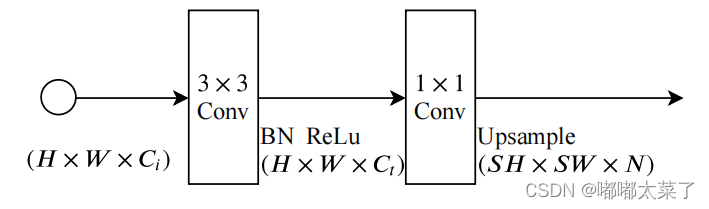
分割头的结构如下,其中S是上采样倍率。
class SegmentHead(nn.Module):
def __init__(self, in_chan, mid_chan, n_classes, up_factor=8, aux=True):
super(SegmentHead, self).__init__()
self.conv = ConvBNReLU(in_chan, mid_chan, 3, stride=1)
self.drop = nn.Dropout(0.1)
self.up_factor = up_factor
out_chan = n_classes
mid_chan2 = up_factor * up_factor if aux else mid_chan
up_factor = up_factor // 2 if aux else up_factor
self.conv_out = nn.Sequential(
nn.Sequential(
nn.Upsample(scale_factor=2),
ConvBNReLU(mid_chan, mid_chan2, 3, stride=1)
) if aux else nn.Identity(),
nn.Conv2d(mid_chan2, out_chan, 1, 1, 0, bias=True),
nn.Upsample(scale_factor=up_factor, mode='bilinear', align_corners=False)
)
def forward(self, x):
feat = self.conv(x)
feat = self.drop(feat)
feat = self.conv_out(feat)
return feat
需要注意,上采样是通过PixelShuffle实现的,代码如下:
class UpSample(nn.Module):
def __init__(self, n_chan, factor=2):
super(UpSample, self).__init__()
out_chan = n_chan * factor * factor
self.proj = nn.Conv2d(n_chan, out_chan, 1, 1, 0)
self.up = nn.PixelShuffle(factor)
self.init_weight()
def forward(self, x):
feat = self.proj(x)
feat = self.up(feat)
return feat
3. 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvBNReLU(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1,
dilation=1, groups=1, bias=False):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(
in_chan, out_chan, kernel_size=ks, stride=stride,
padding=padding, dilation=dilation,
groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_chan)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv(x)
feat = self.bn(feat)
feat = self.relu(feat)
return feat
class DetailBranch(nn.Module):
def __init__(self):
super(DetailBranch, self).__init__()
self.S1 = nn.Sequential(
ConvBNReLU(3, 64, 3, stride=2),
ConvBNReLU(64, 64, 3, stride=1),
)
self.S2 = nn.Sequential(
ConvBNReLU(64, 64, 3, stride=2),
ConvBNReLU(64, 64, 3, stride=1),
ConvBNReLU(64, 64, 3, stride=1),
)
self.S3 = nn.Sequential(
ConvBNReLU(64, 128, 3, stride=2),
ConvBNReLU(128, 128, 3, stride=1),
ConvBNReLU(128, 128, 3, stride=1),
)
def forward(self, x):
feat = self.S1(x)
feat = self.S2(feat)
feat = self.S3(feat)
return feat
class StemBlock(nn.Module):
def __init__(self):
super(StemBlock, self).__init__()
self.conv = ConvBNReLU(3, 16, 3, stride=2)
self.left = nn.Sequential(
ConvBNReLU(16, 8, 1, stride=1, padding=0),
ConvBNReLU(8, 16, 3, stride=2),
)
self.right = nn.MaxPool2d(
kernel_size=3, stride=2, padding=1, ceil_mode=False)
self.fuse = ConvBNReLU(32, 16, 3, stride=1)
def forward(self, x):
feat = self.conv(x)
feat_left = self.left(feat)
feat_right = self.right(feat)
feat = torch.cat([feat_left, feat_right], dim=1)
feat = self.fuse(feat)
return feat
class CEBlock(nn.Module):
def __init__(self):
super(CEBlock, self).__init__()
self.bn = nn.BatchNorm2d(128)
self.conv_gap = ConvBNReLU(128, 128, 1, stride=1, padding=0)
#TODO: in paper here is naive conv2d, no bn-relu
self.conv_last = ConvBNReLU(128, 128, 3, stride=1)
def forward(self, x):
feat = torch.mean(x, dim=(2, 3), keepdim=True)
feat = self.bn(feat)
feat = self.conv_gap(feat)
feat = feat + x
feat = self.conv_last(feat)
return feat
class GELayerS1(nn.Module):
def __init__(self, in_chan, out_chan, exp_ratio=6):
super(GELayerS1, self).__init__()
mid_chan = in_chan * exp_ratio
self.conv1 = ConvBNReLU(in_chan, in_chan, 3, stride=1)
self.dwconv = nn.Sequential(
nn.Conv2d(
in_chan, mid_chan, kernel_size=3, stride=1,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(mid_chan),
nn.ReLU(inplace=True), # not shown in paper
)
self.conv2 = nn.Sequential(
nn.Conv2d(
mid_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.conv2[1].last_bn = True
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv1(x)
feat = self.dwconv(feat)
feat = self.conv2(feat)
feat = feat + x
feat = self.relu(feat)
return feat
class GELayerS2(nn.Module):
def __init__(self, in_chan, out_chan, exp_ratio=6):
super(GELayerS2, self).__init__()
mid_chan = in_chan * exp_ratio
self.conv1 = ConvBNReLU(in_chan, in_chan, 3, stride=1)
self.dwconv1 = nn.Sequential(
nn.Conv2d(
in_chan, mid_chan, kernel_size=3, stride=2,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(mid_chan),
)
self.dwconv2 = nn.Sequential(
nn.Conv2d(
mid_chan, mid_chan, kernel_size=3, stride=1,
padding=1, groups=mid_chan, bias=False),
nn.BatchNorm2d(mid_chan),
nn.ReLU(inplace=True), # not shown in paper
)
self.conv2 = nn.Sequential(
nn.Conv2d(
mid_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.conv2[1].last_bn = True
self.shortcut = nn.Sequential(
nn.Conv2d(
in_chan, in_chan, kernel_size=3, stride=2,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(in_chan),
nn.Conv2d(
in_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv1(x)
feat = self.dwconv1(feat)
feat = self.dwconv2(feat)
feat = self.conv2(feat)
shortcut = self.shortcut(x)
feat = feat + shortcut
feat = self.relu(feat)
return feat
class SegmentBranch(nn.Module):
def __init__(self):
super(SegmentBranch, self).__init__()
self.S1S2 = StemBlock()
self.S3 = nn.Sequential(
GELayerS2(16, 32),
GELayerS1(32, 32),
)
self.S4 = nn.Sequential(
GELayerS2(32, 64),
GELayerS1(64, 64),
)
self.S5_4 = nn.Sequential(
GELayerS2(64, 128),
GELayerS1(128, 128),
GELayerS1(128, 128),
GELayerS1(128, 128),
)
self.S5_5 = CEBlock()
def forward(self, x):
feat2 = self.S1S2(x)
feat3 = self.S3(feat2)
feat4 = self.S4(feat3)
feat5_4 = self.S5_4(feat4)
feat5_5 = self.S5_5(feat5_4)
return feat2, feat3, feat4, feat5_4, feat5_5
class BGALayer(nn.Module):
def __init__(self):
super(BGALayer, self).__init__()
self.left1 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.Conv2d(
128, 128, kernel_size=1, stride=1,
padding=0, bias=False),
)
self.left2 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=2,
padding=1, bias=False),
nn.BatchNorm2d(128),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False)
)
self.right1 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, bias=False),
nn.BatchNorm2d(128),
)
self.right2 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.Conv2d(
128, 128, kernel_size=1, stride=1,
padding=0, bias=False),
)
##TODO: does this really has no relu?
self.conv = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True), # not shown in paper
)
def forward(self, x_d, x_s):
dsize = x_d.size()[2:]
left1 = self.left1(x_d)
left2 = self.left2(x_d)
right1 = self.right1(x_s)
right2 = self.right2(x_s)
right1 = F.interpolate(
right1, size=dsize, mode='bilinear', align_corners=True)
left = left1 * torch.sigmoid(right1)
right = left2 * torch.sigmoid(right2)
right = F.interpolate(
right, size=dsize, mode='bilinear', align_corners=True)
out = self.conv(left + right)
return out
class SegmentHead(nn.Module):
def __init__(self, in_chan, mid_chan, n_classes):
super(SegmentHead, self).__init__()
self.conv = ConvBNReLU(in_chan, mid_chan, 3, stride=1)
self.drop = nn.Dropout(0.1)
self.conv_out = nn.Conv2d(
mid_chan, n_classes, kernel_size=1, stride=1,
padding=0, bias=True)
def forward(self, x, size=None):
feat = self.conv(x)
feat = self.drop(feat)
feat = self.conv_out(feat)
if not size is None:
feat = F.interpolate(feat, size=size,
mode='bilinear', align_corners=True)
return feat
class BiSeNetV2(nn.Module):
def __init__(self, n_classes):
super(BiSeNetV2, self).__init__()
self.detail = DetailBranch()
self.segment = SegmentBranch()
self.bga = BGALayer()
## TODO: what is the number of mid chan ?
self.head = SegmentHead(128, 1024, n_classes)
self.aux2 = SegmentHead(16, 128, n_classes)
self.aux3 = SegmentHead(32, 128, n_classes)
self.aux4 = SegmentHead(64, 128, n_classes)
self.aux5_4 = SegmentHead(128, 128, n_classes)
self.init_weights()
def forward(self, x):
size = x.size()[2:]
feat_d = self.detail(x)
feat2, feat3, feat4, feat5_4, feat_s = self.segment(x)
feat_head = self.bga(feat_d, feat_s)
logits = self.head(feat_head, size)
logits_aux2 = self.aux2(feat2, size)
logits_aux3 = self.aux3(feat3, size)
logits_aux4 = self.aux4(feat4, size)
logits_aux5_4 = self.aux5_4(feat5_4, size)
return logits, logits_aux2, logits_aux3, logits_aux4, logits_aux5_4
def init_weights(self):
for name, module in self.named_modules():
if isinstance(module, (nn.Conv2d, nn.Linear)):
nn.init.kaiming_normal_(module.weight, mode='fan_out')
if not module.bias is None: nn.init.constant_(module.bias, 0)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
if hasattr(module, 'last_bn') and module.last_bn:
nn.init.zeros_(module.weight)
else:
nn.init.ones_(module.weight)
nn.init.zeros_(module.bias)
if __name__ == "__main__":
# x = torch.randn(16, 3, 1024, 2048)
# detail = DetailBranch()
# feat = detail(x)
# print('detail', feat.size())
#
# x = torch.randn(16, 3, 1024, 2048)
# stem = StemBlock()
# feat = stem(x)
# print('stem', feat.size())
#
# x = torch.randn(16, 128, 16, 32)
# ceb = CEBlock()
# feat = ceb(x)
# print(feat.size())
#
# x = torch.randn(16, 32, 16, 32)
# ge1 = GELayerS1(32, 32)
# feat = ge1(x)
# print(feat.size())
#
# x = torch.randn(16, 16, 16, 32)
# ge2 = GELayerS2(16, 32)
# feat = ge2(x)
# print(feat.size())
#
# left = torch.randn(16, 128, 64, 128)
# right = torch.randn(16, 128, 16, 32)
# bga = BGALayer()
# feat = bga(left, right)
# print(feat.size())
#
# x = torch.randn(16, 128, 64, 128)
# head = SegmentHead(128, 128, 19)
# logits = head(x)
# print(logits.size())
#
# x = torch.randn(16, 3, 1024, 2048)
# segment = SegmentBranch()
# feat = segment(x)[0]
# print(feat.size())
#
x = torch.randn(16, 3, 512, 1024)
model = BiSeNetV2(n_classes=19)
logits = model(x)[0]
print(logits.size())
# for name, param in model.named_parameters():
# if len(param.size()) == 1:
# print(name)
参考资料