前言
嗨喽!大家好呀,这里是魔王~**


模块安装问题:
如果安装python第三方模块:
- win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
- 在pycharm中点击Terminal(终端) 输入安装命令
如何配置pycharm里面的python解释器?
- 选择file(文件) >>> setting(设置) >>> Project(项目) >>> python interpreter(python解释器)
- 点击齿轮, 选择add
- 添加python安装路径
pycharm如何安装插件?
- 选择file(文件) >>> setting(设置) >>> Plugins(插件)
- 点击 Marketplace 输入想要安装的插件名字 比如:翻译插件 输入 translation / 汉化插件 输入 Chinese
- 选择相应的插件点击 install(安装) 即可
- 安装成功之后 是会弹出 重启pycharm的选项 点击确定, 重启即可生效
如何配置 ffmpeg
一. 左侧主页加我领取相应的安装包
二. 解压文件, 放到某一个文件夹(随意)
三. 配置环境变量
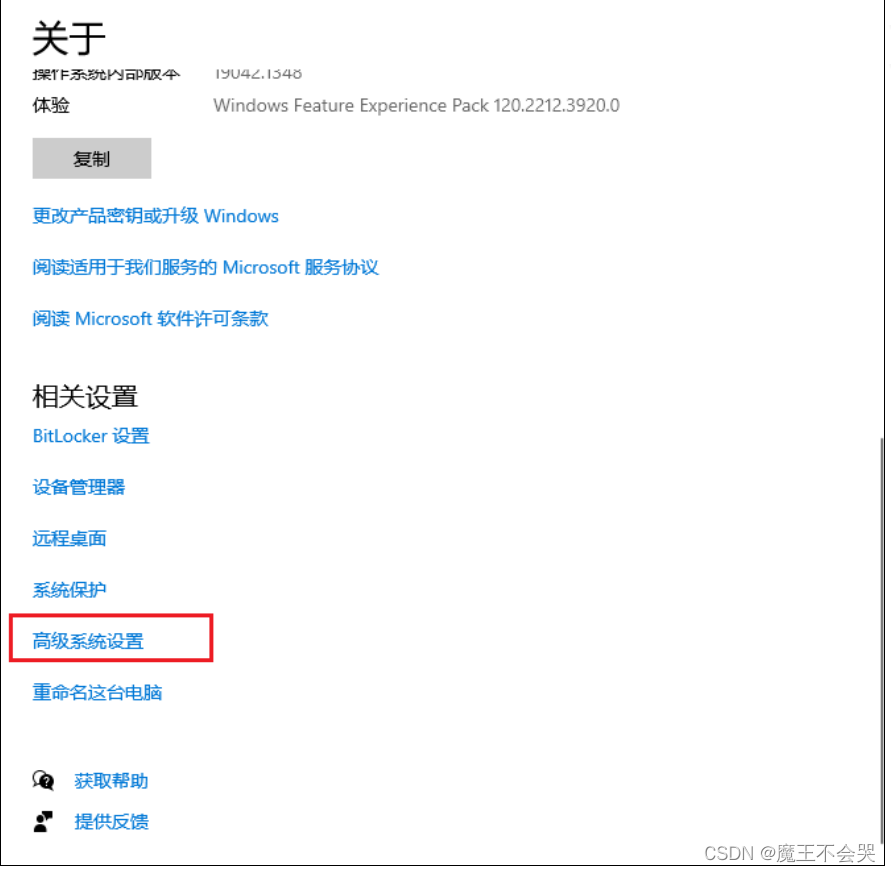
我的电脑(此电脑) 右键选择属性

选择高级系统设置
选择环境变量

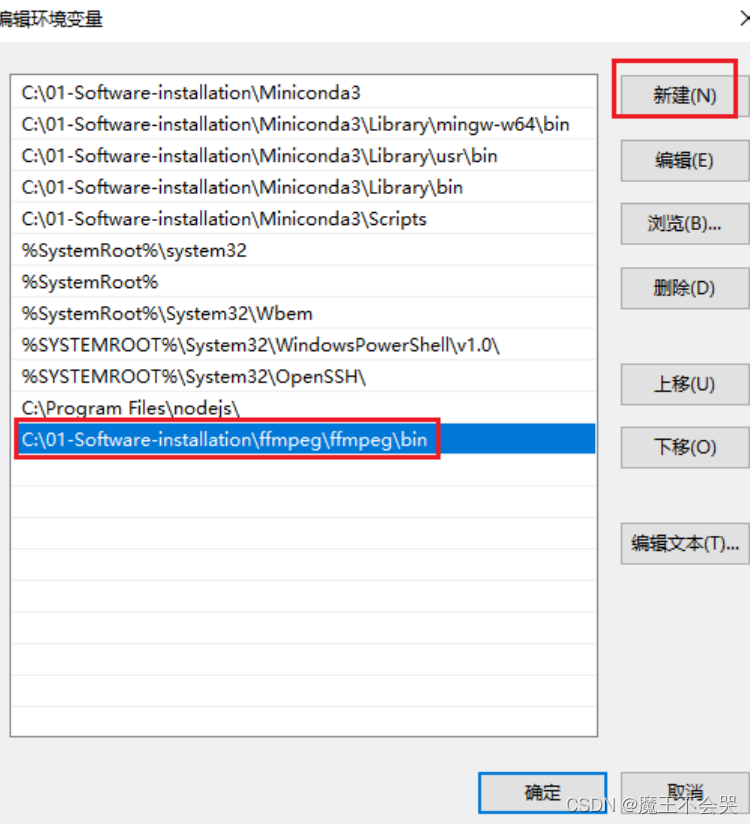
复制你解压之后的ffmpeg路径
比如我的 C:\01-Software-installation\ffmpeg\ffmpeg\bin

点击选择path

选择新建, 粘贴ffmpeg路径

分析得到数据
一. 打开网页源代码
对视频详情页 鼠标右键选择网页源代码

二. 搜索关键词 playinfo

代码实现步骤

代码
# import time
#
# import requests # 数据请求模块
# import re
# import json
# import pprint
# import subprocess
# import os
#
# for page in range(1, 12):
# list_url = f'https://api.bilibili.com/x/space/arc/search?mid=1305006386&ps=30&tid=0&pn={
page}&keyword=&order=pubdate&jsonp=jsonp'
# headers = {
# 'cookie': 'buvid3=505115A6-48EA-0919-3209-465409AA992981053infoc; _uuid=636B74D9-E84A-F2104-1229-78C910BC64F5179787infoc; blackside_state=1; rpdid=|(kmJY|k))Ru0J\'uYR|mJYlY~; buvid4=5C79A8B4-7F25-78C9-2243-297FC69BBF1379004-022021019-1pW1w45e5faCG5mZBS0QBA%3D%3D; buvid_fp_plain=undefined; LIVE_BUVID=AUTO2716444930253540; i-wanna-go-back=-1; CURRENT_QUALITY=0; CURRENT_BLACKGAP=0; sid=642j26r0; fingerprint3=1d3f8d535d23a20df3fe7382671d115b; DedeUserID=523606542; DedeUserID__ckMd5=909861ec223d26d8; SESSDATA=4480157b%2C1661674553%2Cda993*31; bili_jct=4308a518638c20ee6db87b115cbe8609; fingerprint=d1e5f057d9a8561c03c59637ef5c6253; buvid_fp=d1e5f057d9a8561c03c59637ef5c6253; b_ut=5; nostalgia_conf=-1; innersign=1; PVID=2; b_lsid=44E1073DA_18065EFA270; bp_video_offset_523606542=653426892676792300; CURRENT_FNVAL=80',
# 'referer': 'https://www.bilibili.com/',
# 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'
# }
# bv_list = requests.get(url=list_url, headers=headers).json()['data']['list']['vlist']
# for index in bv_list:
# # time.sleep(1)
# bv_id = index['bvid']
# title = index['title']
# print(title, bv_id)
# """
# 1. 发送请求, 对于视频详情页url地址发送请求 https://www.bilibili.com/video/BV11b4y1S7Jq
# 确定请求网址
# 确定请求方式
# 请求头伪装
# 爬虫是模拟浏览器对于url地址发送请求, 然后再获取服务器返回响应数据
# """
# url = f'https://www.bilibili.com/video/{
bv_id}'
# # 请求头伪装代码, 为了防止被服务器识别出来是爬虫程序 user-agent 用户代理, 浏览器最基本身份信息
# # 你得不到你想要数据, 服务器没有给你返回数据, 或者返回的数据不是你想要的
# # referer 防盗链, 告诉服务器, 我们请求url地址是从哪里跳转过来的
# # 通过requests这个模块里面get请求方法, 对于url地址发送请求 并且携带上headers请求头伪装, 最后用自定义变量response接收返回数据
# response = requests.get(url=url, headers=headers)
# # print(response) # <Response [200]> 得到响应对象 200表示请求成功
# """
# 2. 获取数据, 获取响应体的文本数据 response.text 网页源代码
# response.json() 获取json字典数据
# response.content 获取二进制数据
# """
# # print(response.text)
# """
# 3. 解析数据, 提取我们想要的 视频标题/音频url/视频画面url
# 用re正则表达...
# 如何简单的使用正则
# 1. 导入模块
# 2. 去复制, 我们想要数据内容 <h1 id="video-title" title="每天一遍,防止早恋!" class="video-title">
# 3. 使用re.findall() 方法 从什么地方, 去找什么数据 (.*?) 想要的数据, 就用括号.*?
# ['每天一遍,防止早恋!'] 列表 文本在python一般字符串数据
# ["每天一遍,防止早恋!"] 字符串
# 正则匹配出来的数据, 返回是列表
# """
# title = re.findall('<h1 id="video-title" title="(.*?)" class="video-title">', response.text)[0].replace(' ', '')
# play_info = re.findall('<script>window.__playinfo__=(.*?)</script>', response.text)[0]
# json_data = json.loads(play_info)
# # json 数据存储格式, 在python字典数据类型
# # print(title)
# # print(play_info)
# # print(type(play_info))
# # json_data = json.loads(play_info)
# # print(json_data)
# # print(type(json_data))
# # pprint.pprint(json_data) # 格式化输出
# # 取值, 键值对取值, 根据冒号左边的内容[键], 提取冒号右边的内容[值]
# audio_url = json_data['data']['dash']['audio'][0]['baseUrl']
# video_url = json_data['data']['dash']['video'][0]['baseUrl']
# # 403 Forbidden 你没有访问权限, 403 加防盗链
# print(title)
# print(audio_url)
# print(video_url)
#
# audio_content = requests.get(url=audio_url, headers=headers).content # 音频二进制数据
# video_content = requests.get(url=video_url, headers=headers).content # 视频画面二进制数据
# with open('video\\' + title + '.mp3', mode='wb') as f:
# f.write(audio_content)
# with open('video\\' + title + '.mp4', mode='wb') as f:
# f.write(video_content)
#
#
# COMMAND = f'ffmpeg -i video\\{
title}.mp4 -i video\\{
title}.mp3 -c:v copy -c:a aac -strict experimental video\\{
title}output.mp4'
# subprocess.run(COMMAND, shell=True)
# os.remove(f'video\\{
title}.mp3')
# os.remove(f'video\\{
title}.mp4')
#
# 简单m3u8 复杂 m3u8 + AES加密 [JS逆向内容]
import re
import requests
for page in range(1, 30):
url = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=138393844&date=2022-04-{
page}'
headers = {
'cookie': 'buvid3=505115A6-48EA-0919-3209-465409AA992981053infoc; _uuid=636B74D9-E84A-F2104-1229-78C910BC64F5179787infoc; blackside_state=1; rpdid=|(kmJY|k))Ru0J\'uYR|mJYlY~; buvid4=5C79A8B4-7F25-78C9-2243-297FC69BBF1379004-022021019-1pW1w45e5faCG5mZBS0QBA%3D%3D; buvid_fp_plain=undefined; LIVE_BUVID=AUTO2716444930253540; i-wanna-go-back=-1; CURRENT_QUALITY=0; CURRENT_BLACKGAP=0; sid=642j26r0; fingerprint3=1d3f8d535d23a20df3fe7382671d115b; DedeUserID=523606542; DedeUserID__ckMd5=909861ec223d26d8; SESSDATA=4480157b%2C1661674553%2Cda993*31; bili_jct=4308a518638c20ee6db87b115cbe8609; fingerprint=d1e5f057d9a8561c03c59637ef5c6253; buvid_fp=d1e5f057d9a8561c03c59637ef5c6253; b_ut=5; nostalgia_conf=-1; innersign=1; PVID=2; b_lsid=44E1073DA_18065EFA270; bp_video_offset_523606542=653426892676792300; CURRENT_FNVAL=80',
'referer': 'https://www.bilibili.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# print(response.text)
content_list = re.findall(':(.*?)@', response.text)
for content in content_list:
print(content[1:])
with open('弹幕.txt', mode='a', encoding='utf-8') as f:
f.write(content[1:])
f.write('\n')
尾语
好了,我的这篇文章写到这里就结束啦!
有更多建议或问题可以评论区或私信我哦!一起加油努力叭(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!
