提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
HashMap死循环的死循环问题只会在JDK1.7中出现,主要是HashMap自身的工作机制再加上并发操作,从而会导致死循环的出现,在JDK1.8之后,官方彻底解决了这个问题,但是1.8存在数据丢失的问题
一、JDK1.7 HashMap插入数据的原理
由于JDK1.7中,HashMap的底层存储结构是,数组加链表的方式,而HashMap在插入数据的时候,采用的是头插法,也就是说新插入的数据会从链表的头节点进行插入,因此HashMap正常情况下的扩容是这么一个过程:
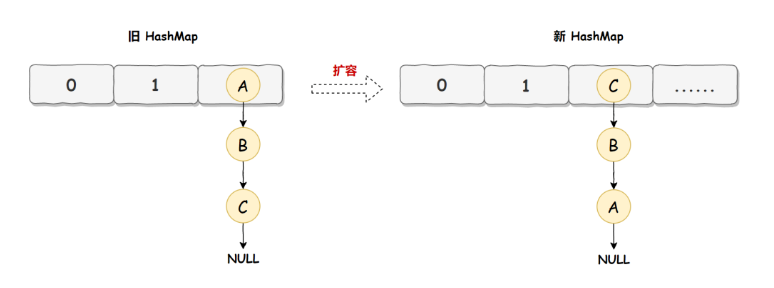
旧的HashMap会依次转移到新的HashMap中,转移的顺序是A、B、C
而HashMap使用的是头插法,因此,转移后就是C、B、A,如上图所示
二、JDK1.7 HashMap 核心代码
下面是1.7里,HashMap扩容后,把旧的HashMap的数据移动到新的HashMap的过程:
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
//获取新的table的长度(扩容后的table)
int newCapacity = newTable.length;
//遍历旧的table
for (Entry<K,V> e : table) {
while(null != e) {
// 重新计算原table中的数据在新数组的索引位置,并用头插法进行扩容
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
根据上述源码,我们按三个步骤,还原下并发场景下HashMap扩容导致的死循环问题。
第一步:线程启动
假设有线程T1和线程T2,都准备对HashMap进行扩容,此时T1和T2都指向链表的头节点A,而T1和T2的下一个节点分别是T1.next和T2.next,它们都指向B节点

第二步:开始扩容
这个时候,假设线程T2的时间片用完了,进入了休眠状态
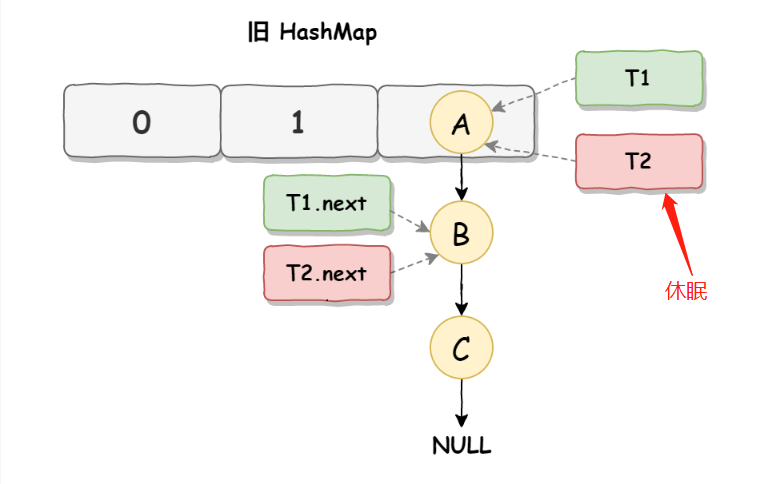
而线程T1开始执行上述源码的扩容操作,一直到线程T1扩容完成后,线程T2才被唤醒,线程T1完成扩容后的场景就变成了这样:
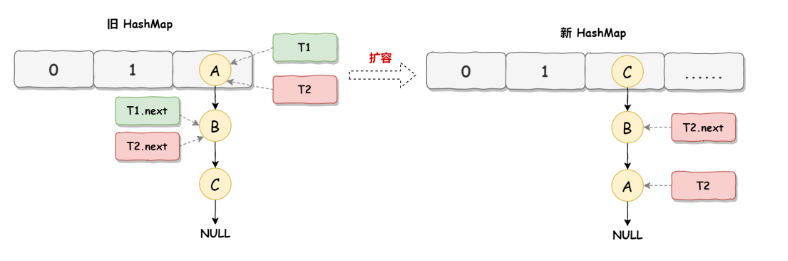
因为1.7HashMap扩容采用的是头插法,线程T1扩容后,列表中的节点顺序发生了变化,但是线程T2,对于发生的一切还是不可知的,所以T2的节点引用依旧没有发生改变,如上图所示,T2指向的是A节点,T2.next指向的是B节点。
table是线程T1和T2共享的
第三步:T2恢复运行
当线程T1执行结束后,线程T2恢复执行,死循环这时候就发生了:因为T1完成扩容之后,B节点的下一个节点是A;而T2线程指向的首节点是A,第二个节点是B,这个时候顺序刚好与T1扩容之前的顺序是相反的
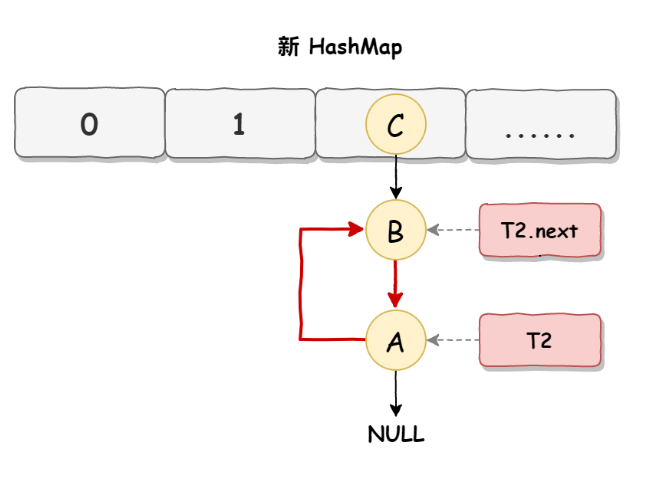
结果:T1执行完的顺序是A→B,T执行完的顺序是B→A,这样就在新的HashMap中形成了死循环
三、JDK1.8 HashMap
尾插法
JDK1.8中HashMap的扩容采用了尾插法,还是上述的例子:线程T1在扩容完成后,T2才恢复。尾插法可以保证扩容完成后,ABC的顺序不发生改变,因为即使T2再启动,执行完后,也不会出现A→B、B→A的情况。
根据上面JDK1.7出现的问题,在JDK1.8中已经得到了很好的解决,如果你去阅读1.8的源码会发现找不到transfer函数,因为JDK1.8直接在resize函数中完成了数据迁移
数据丢失(数据覆盖)
为什么说JDK1.8会出现数据覆盖的情况喃,我们来看一下下面这段JDK1.8中的put操作代码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有hash碰撞则直接插入元素
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
// existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
其中第六行代码是判断是否出现hash碰撞,假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
四、解决方案
避免HashMap发生死循环的常用解决方案:
1、使用线程安全的ConcurrentHashMap替代HashMap,推荐
2、使用线程安全的Hashtable替代,性能低,不推荐
3、使用synchronized或者Lock加锁,会影响性能,不推荐
五、总结
HashMap的死循环只发生在JDK1.7版本中
主要原因:头插法+链表+多线程并发+扩容,累加到一起就会形成死循环
多线程下:建议采用ConcurrentHashMap替代
JDK1.8,HashMap改用尾插法,解决了链表死循环问题,但是可能会丢失数据