延迟消息如何实现?
延迟消息就是字面上的意思:当接收到消息之后,我需要隔一段时间进行处理(相对于立马处理,它隔了一段时间,所以他叫延迟消息)。
在原生的 Java 有 DelayQueue 供我们去使用,在使用的时候,我们 add 进去的队列的元素需要实现 Delayed 接口(同时该接口继承了 Comparable 接口,所以我们 DelayQueue 是有序的)
public interface Delayed extends Comparable<Delayed> {
long getDelay(TimeUnit unit);
}
复制代码
从 poll 的源码上可以清晰地发现本质上就是在取数的时候判断了下时间
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
return q.poll();
复制代码
有的人就反驳到:这不是废话吗?肯定要判断时间啊,不判断时间怎么知道我要延迟的消息什么时候执行。
明白了这点之后,我们再来别的方案。因为在生产环境中是不太可能使用 JDK 原生延迟队列的,它是没有持久化的,重启就会导致数据丢失。

当 austin 项目使用内存队列去解耦处理数据已经有人提出服务器重启的时候该怎么办,我的解决思路就是通过优雅关闭服务器这种手段去尽量避免数据丢失,而延迟队列这种就不能这么干了,我们等不了这么久的。
稍微想想还有什么存储适合当队列且有持久化机制的呢?
答案显而易见:Redis 和消息队列 (Kafka/RocketMQ/RabbmitMQ 等)
我们先来看 Redis 里提供了一种数据结构叫做 zset,它是可排序的集合并且 Redis 原生就支持持久化。有赞的延迟队列就是基于通过 zset 进行设计和存储的。整体架构如下图:
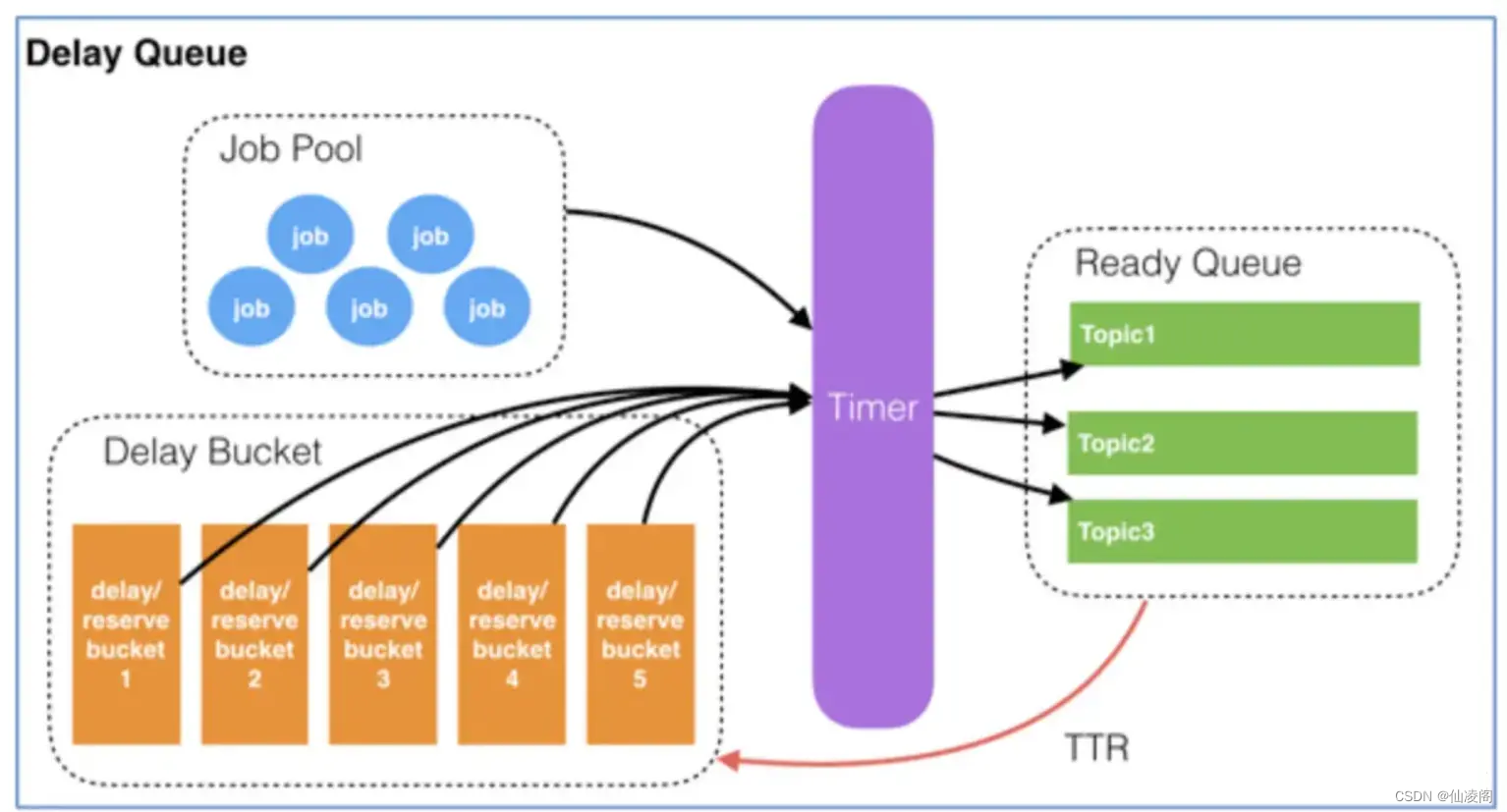
简单理解这张图就是:将需要延迟的消息放置 Redis,通过 Timer 轮询得到可执行的消息,将可执行的消息放置不同的 Topic 供业务方自行消费。
通过 timer 去轮询 zset 查看是否有可执行的消息是一种思路,也有人通过 Redis 的过期回调的姿势也能达到延迟消息的效果(把消息执行的时间定义为 key 过期的时间,当 key 触发了过期回调,那说明该消息可执行了)。

说完 Redis,我们再来看看消息队列。在 austin 项目上使用消息队列是 Kafka,而 Kafka 在官方是没有提供延迟队列这种机制的。不过 RabbmitMQ 和 RocketMQ 都有对应的机制,我们可以简单看看窥探下它们的实现思路。
RabbmitMQ 它的延迟队列机制本质上也是通过 TTL(Time To Live 消息存活的时间)所实现的,当队列里的元素触发了过期时,会被送往到 Dead Letter Exchanges(死信队列中)。我们可以将死信队列的元素再次转发,对其进行消费,从而达到延迟队列的效果。
毕竟 RabbmitMQ 是专门做消息队列的,所以它对消息的可靠性会比 Redis 更加高(消息投递的可靠性、至少处理一次的消费语义)

RocketMQ 支持在我们投递消息的时候设置延迟等级
Message message = new Message("TestTopic", ("Hello scheduled message " + i).getBytes());
// This message will be delivered to consumer 10 seconds later.
message.setDelayTimeLevel(3);
// Send the message
producer.send(message);
复制代码
默认支持 18 个延迟等级,分别是:
messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
复制代码
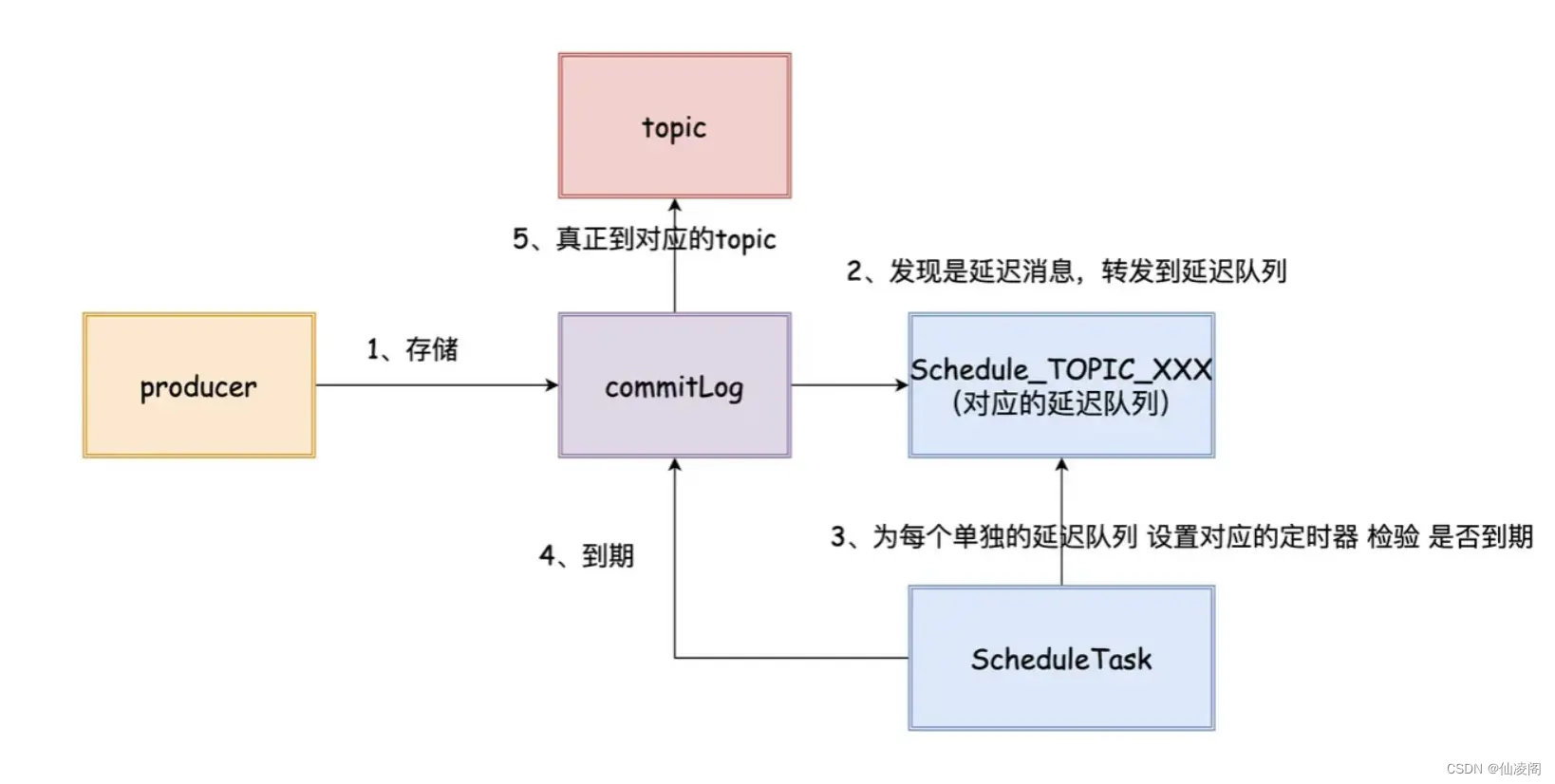
当我们设置了延迟等级的消息之后,RocketMQ 不会把消息直接投递到对应的 topic,而是转发到对应延迟等级的队列中。在 Broker 内部会为每个延迟队列起 TimerTask 来进行判断是否有消息到达了时间。
ScheduleMessageService#start
for (Map.Entry<Integer, Long> entry : this.delayLevelTable.entrySet()) {
this.deliverExecutorService.schedule(new DeliverDelayedMessageTimerTask(level, offset), FIRST_DELAY_TIME, TimeUnit.MILLISECONDS);
}
复制代码
如果到期了,则将消息重新存储到 CommitLog,转发到真正目标的 topic
实现需求
在前面提到我们可以利用 JDK 原生的延时队列,又或是 Redis 的 zset 数据结构或者其过期时间机制、又或是 RabbitMQ 使用 TTL+ 死信队列机制、又或是 RocketMQ 的延时等级队列机制来实现我们的需求(延时队列)
针对此次需求,上面所讲的延时队列,我都没用到…
austin 项目引入的是 Kafka,不太可能去为了延时队列去引入第二种消息队列(RabbitMQ 在互联网应该用得相对较少,RocketMQ 需要改动配置文件的延迟等级才能支持更丰富的延时需求)。
如果基于 Kafka 或者 Redis 去二次开发延时队列,开发成本还是有不少的,在 GitHub 也还没捞到我想要的轮子。
于是,我换了一种方案:万物皆扫表
针对这次需求(晚上发的消息,次日早上发送),就不需要上延时队列,因为 austin 已经接入了分布式定时任务框架了(对应的实现是 xxl-job)
只要把晚上的接收到的消息扔进 Redis list,然后启个定时任务(每天早上 9 点)轮询该 list 是否有数据,如果有再重新做处理就完事了。
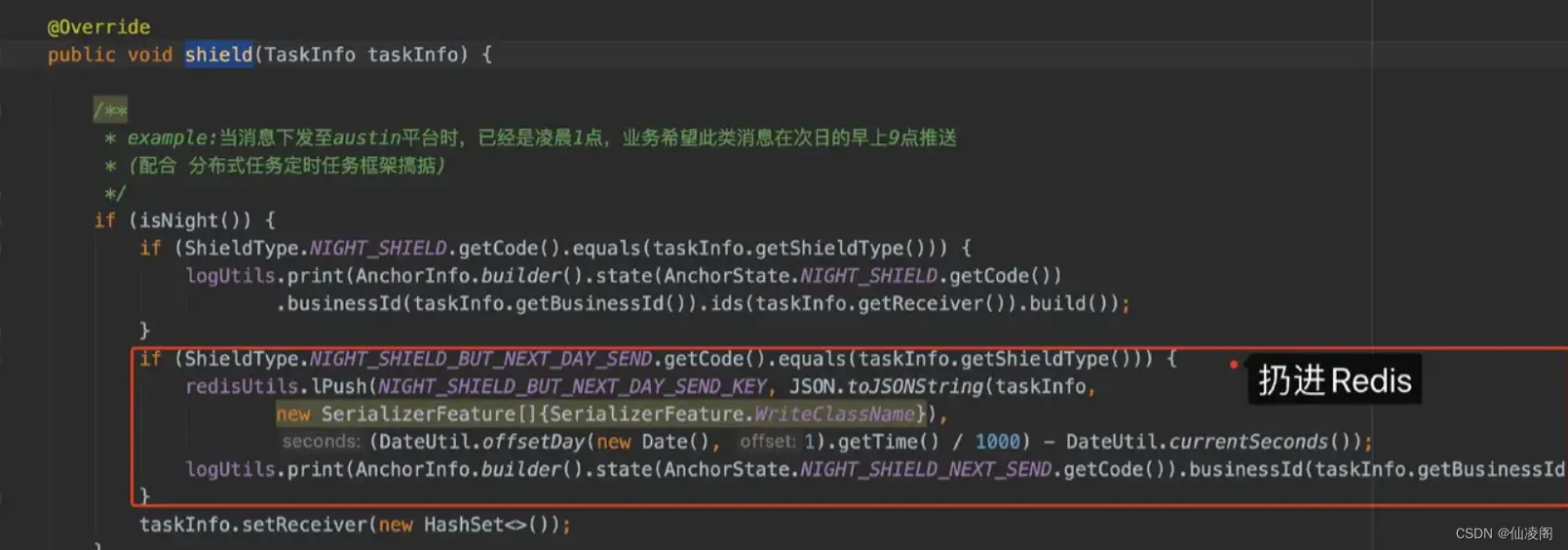
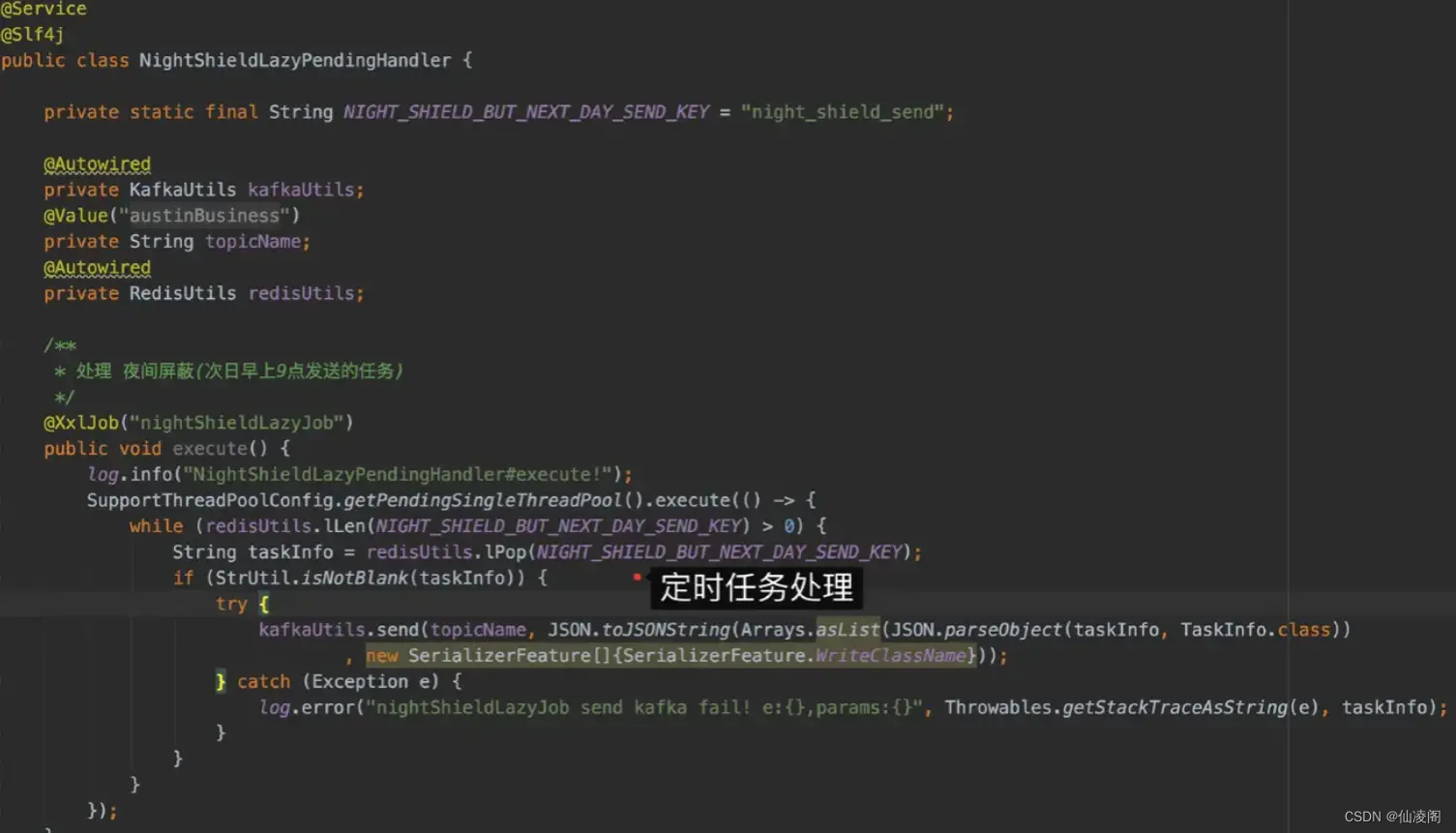
总结
这篇文章主要讲述了如果我们要使用延时队列,我们可以有什么方案,他们的设计是怎么样的。在需求侧上看,这个需求就是「延时队列」的场景,但基于现状的系统架构和开发成本考虑,我们是可以用另类(分布式定时任务框架)的方式去把需求给实现了。
很多时候,我们看到的系统很烂,技术栈很烂,发现好多场景都没有用到最佳实践而感到懊恼,在年轻的时候都想有重构的心。但实际上每引入一个中间件都是需要付出成本的,粗糙也有粗糙的好处。
只要业务能完美支持,那就是好的方案。想要搞自己想搞的技术,那就做开源,如果有一天我觉得分布式定时任务来实现此次需求不顺眼了,我再花时间来重构才干掉,现在就这么实现吧( // TODO)。
如果你实在是觉得看着糟心,欢迎提个 pull request,这样我就不得不把这种实现给干掉了(我对提过来的 pull request 都会谨慎且用心处理)
源码附件已经打包好上传到百度云了,大家自行下载即可~
链接: https://pan.baidu.com/s/14G-bpVthImHD4eosZUNSFA?pwd=yu27
提取码: yu27
百度云链接不稳定,随时可能会失效,大家抓紧保存哈。
如果百度云链接失效了的话,请留言告诉我,我看到后会及时更新~
开源地址
码云地址:
http://github.crmeb.net/u/defu
Github 地址:
http://github.crmeb.net/u/defu
开源不易,Star 以表尊重,感兴趣的朋友欢迎 Star,提交 PR,一起维护开源项目,造福更多人!