一、单机部署
单机部署步骤
- elasticsearch 是不允许root用户直接运行的,需要创建新的用户,并且把elasticsearch 下所有的文件更改所属用户
1.从官网下载压缩包
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
- 可根据需要的版本进行下载:


2.压缩包解压缩

解压软件包
tar zxvf elasticsearch-7.17.0-linux-x86_64.tar.gz

3.创建用户,并授权:
- elasticsearch 是不允许root用户直接运行的,需要创建新的用户
useradd es
passwd es

chown -R es:es /opt/elasticsearch-7.17.0

递归创建日志路径:
mkdir -p /data/apps/elasticsearch-7.17.0/logs
mkdir -p /data/apps/elasticsearch-7.17.0/data

给es用户授权:
chown -R es:es /data/apps/elasticsearch-7.17.0/


4.修改elasticsearch配置文件
vim /opt/elasticsearch-7.17.0/config/elasticsearch.yml




http.cors.enabled: true
开启跨域
http.cors.allow-origin: "*"
开启所有
node.master: false
node.data: true
node.ingest: false
http.cors.enabled: true
http.cors.allow-origin: "*"
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
#xpack.security.enabled: true
#xpack.security.transport.ssl.enabled: true
#xpack.security.transport.ssl.verification_mode: certificate
#xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
#xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
cluster.max_shards_per_node: 500000
修改jvm空间分配
- 调整JVM内存为物理机内存大小的50%


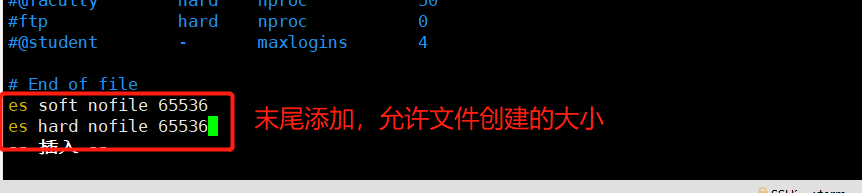
修改文件创建数量的大小
修改文件创建数量的大小:
vim /etc/security/limits.conf

es soft nofile 65536
es hard nofile 65536
设置文件的大小参数
vim /etc/security/limits.d/20-nproc.conf
末尾添加:
es soft nofile 65536
es hard nofile 65536
* hard nproc 4096

设置最大内存的分配
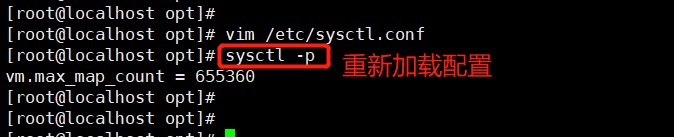
vim /etc/sysctl.conf
末尾添加:
vm.max_map_count=655360

重新加载配置
sysctl -p
5.切换用户,启动服务
su es
cd /opt/elasticsearch-7.17.0/bin/
./elasticsearch
 此刻正在运行中:
此刻正在运行中:

6.验证
- 验证端口是否打开:
netstat -natp | grep 9200

curl命令验证:
curl 'http://192.168.133.10:9200/?pretty'


二、多台部署(举例2台)
按照上面的部署方式部署:
其中node1节点的配置文件需要修改:
vim /opt/elasticsearch-7.17.0/config/elasticsearch.yml

其中node2节点要注意:
- 节点名称:

- 本机端口
 其他相同安装
其他相同安装
验证
curl 'http://192.168.133.20:9200/?pretty'

访问页面:192.168.133.20

集群健康状态:
http://192.168.133.20:9200/_cluster/health?pretty

查看集群状态
http://192.168.133.10:9200/_cluster/state?pretty

/opt/elasticsearch-7.17.0/config/elasticsearch.yml
cluster.name: my-application
node.name: node-1
path.data: /data/apps/elasticsearch-7.17.0/data
path.logs: /data/apps/elasticsearch-7.17.0/logs
network.host: 192.168.133.10
http.port: 9200
discovery.seed_hosts: ["192.168.133.10","192.168.133.20"]
discovery.zen.minimum_master_nodes: 2
cluster.initial_master_nodes: ["node-1","node-2"]
node.master: true
node.data: true
node.ingest: false
http.cors.enabled: true
http.cors.allow-origin: "*"
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
#xpack.security.enabled: true
#xpack.security.transport.ssl.enabled: true
#xpack.security.transport.ssl.verification_mode: certificate
#xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
#xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
cluster.max_shards_per_node: 500000
三、官方文档扩展
配置
1.指定名字
elasticsearch.yml 文件中修改:
集群名称
cluster.name: elasticsearch_production
节点名称
node.name: elasticsearch_005_data
2.路径
默认情况下,Elasticsearch 会把插件、日志以及你最重要的数据放在安装目录下。这会带来不幸的事故, 如果你重新安装 Elasticsearch 的时候不小心把安装目录覆盖了。如果你不小心,你就可能把你的全部数据删掉了。
path.data: /path/to/data1,/path/to/data2
# Path to log files:
path.logs: /path/to/logs
通过逗号分隔指定多个目录。
3.最小节点数
minimum_master_nodes:
这个配置就是告诉 Elasticsearch 当没有足够 master 候选节点的时候,
就不要进行 master 节点选举,等 master 候选节点足够了才进行选举。
最好至少保证有 3 个节点:
discovery.zen.minimum_master_nodes: 2
设定对你的集群的稳定 极其 重要。 当你的集群中有两个 masters(注:主节点)的时候,这个配置有助于防止 脑裂 ,
脑裂:一种两个主节点同时存在于一个集群的现象。
集群发生了脑裂,那么你的集群就会处在丢失数据的危险中
4.单播代替组播
Elasticsearch 默认被配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。
- 组播:会导致集群变的脆弱,一个节点意外的加入到了你的生产环境
- 单播,你可以为 Elasticsearch 提供一些它应该去尝试连接的节点列表。 当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系 master 节点,并加入集群。
这意味着你的单播列表不需要包含你的集群中的所有节点, 它只是需要足够的节点,当一个新节点联系上其中一个并且说上话就可以了。如果你使用 master 候选节点作为单播列表,你只要列出三个就可以了。 这个配置在 elasticsearch.yml 文件中:
discovery.zen.ping.unicast.hosts: ["host1", "host2:port"]
总结
1.cluster.name
集群名字,三台集群的集群名字都必须一致
2.node.name
节点名字,三台ES节点字都必须不一样
3.discovery.zen.minimum_master_nodes:2
表示集群最少的master数,如果集群的最少master数据少于指定的数,将无法启动,官方推荐node master数设置为集群数/2+1,我这里三台ES服务器,配置最少需要两台master,整个集群才可正常运行
4.node.master该节点是否有资格选举为master,如果上面设了两个master_node 2,也就是最少两个master节点,则集群中必须有两台es服务器的配置为node.master: true的配置,配置了2个节点的话,如果主服务器宕机,整个集群会不可用,所以三台服务器,需要配置3个node.master为true,这样三个master,宕了一个主节点的话,他又会选举新的master,还有两个节点可以用,只要配了node master为true的ES服务器数正在运行的数量不少于master_node的配置数,则整个集群继续可用
我这里则配置三台es node.master都为true,也就是三个master,master服务器主要管理集群状态,负责元数据处理,比如索引增加删除分片分配等,数据存储和查询都不会走主节点,压力较小,jvm内存可分配较低一点
5.node.data
存储索引数据,三台都设为true即可
6.bootstrap.memory_lock: true
锁住物理内存,不使用swap内存,有swap内存的可以开启此项
7.discovery.zen.ping_timeout: 3000s
自动发现拼其他节点超时时间
8.discovery.zen.ping.unicast.hosts: [“172.16.0.8:9300”,“172.16.0.6:9300”,“172.16.0.22:9300”]
设置集群的初始节点列表,集群互通端口为9300
9.discovery.seed_hosts:
discovery.seed_hosts:发现设置。有两种重要的发现和集群形成配置,以便集群中的节点能够彼此发现并且选择一个主节点。
discovery.seed_hosts 是组件集群时比较重要的配置,用于启动当前节点时,发现其他节点的初始列表。
如果要与其他主机上的节点组成集群,则必须设置 discovery.seed_hosts,用来提供集群中的其他主机列表(它们是符合主机资格要求的master-eligible并且可能处于活动状态的且可达的,以便寻址发现过程)。此设置应该是群集中所有符合主机资格的节点的地址的列表。 每个地址可以是 IP 地址,也可以是通过 DNS 解析为一个或多个 IP 地址的主机(hostname)。