Apache Kafka中的增量合作再平衡:当你可以改变世界时,为什么要停止世界?
负载平衡和调度是每个分布式系统的核心,Apache Kafka也不例外。 Kafka 客户端——特别是 Kafka 消费者、Kafka Connect 和 Kafka Streams,它们是本文的重点——从一开始就使用了一种复杂的、典型的资源平衡方式。阅读这篇博文后,您将了解负载平衡在 Kafka 客户端中的工作原理、现有负载平衡协议的挑战以及增量协作重新平衡的新方法如何允许大规模部署客户端。
所有再平衡协议都是围绕相同的简单原则构建的:每当需要在客户端之间分配负载时,就会开始新一轮的再平衡,在此期间所有进程都会释放它们的资源。在此阶段结束时,重申组成员身份并选举组领导,每个客户都被分配一组新的资源。简而言之,这也被称为 stop-the-world 再平衡。
停止世界重新平衡时的挑战,在每次重新平衡中停止世界的负载平衡算法存在一定的局限性:
- 放大和缩小:在重新平衡的同时停止世界的影响与参与进程之间平衡的资源数量有关。例如,在空的 Connect 集群中启动 10 个 Connect 任务与在运行 100 个现有 Connect 任务的集群中启动相同数量的任务是不同的。
- 异构负载下的多租户:这里的主要示例是 Kafka Connect。当另一个连接器(可能来自另一个用户)被添加到集群中时,停止连接器任务的副作用不仅是不可取的,而且还会大规模破坏。
- Kubernetes 进程死亡:无论是在云中还是在本地,故障都是不寻常的。当一个节点发生故障时,另一个节点会迅速替换它,尤其是在使用 Kubernetes 这样的编排器时。理想情况下,一组 Kafka 客户端能够在不执行完全重新平衡的情况下吸收这种暂时的资源损失。一旦节点返回,之前分配的资源将立即分配给它。
- 滚动反弹:间歇性中断不仅是由于环境因素而偶然发生的。作为计划升级的一部分,它们也可以被有意安排。但是,应避免完全重新分配资源,因为缩减只是暂时的。
尽管有适应这些用例的变通方法,例如将客户端分成更小的组或增加与再平衡相关的超时,这些往往不太灵活,但很明显,需要用破坏性较小的方法来取代停止的再平衡。
增量合作再平衡
在 Kafka 社区中获得关注并旨在减轻当前 Eager Rebalancing 协议在大型 Kafka 客户端集群中展示的再平衡影响的提议是增量协作式再平衡。
这种新的再平衡算法的关键思想是:
- 完全和全局的负载均衡不需要在单轮重新均衡中完成。相反,如果客户端在连续几次重新平衡后很快收敛到平衡负载状态就足够了
这些原则本身就是 Kafka 客户端中改进的再平衡协议背后的命题名称。新的再平衡是:
- 增量是因为分阶段达到最终所需的再平衡状态。不必在每轮再平衡结束时达到全球平衡的最终状态。可以使用少量连续的再平衡轮次,以使 Kafka 客户端组收敛到所需的平衡资源状态。此外,您可以配置宽限期以允许离职成员返回并重新获得其先前分配的资源。
- 合作是因为要求组中的每个进程自愿释放需要重新分配的资源。鉴于被要求释放它们的客户按时释放这些资源,这些资源随后可用于重新安排。
Kafka Connect 中的实现——连接任务是新线程:
- 第一个提供增量协作再平衡协议的 Kafka 客户端是 Kafka Connect,添加到 Apache Kafka 2.3 和 Confluent Platform 5.3 中。在 Kafka Connect 中,worker 之间平衡的资源是连接器及其任务。连接器是一个特殊的组件,主要与外部数据系统进行协调和记账,并充当 Kafka 记录的源或接收器。连接任务是执行实际数据传输的结构。
- 尽管 Connect 任务通常不会在本地存储状态,并且可以在从 Kafka 恢复状态后快速停止和恢复执行,但在每次重新平衡时停止世界可能会导致严重的延迟。在某些情况下(也称为重新平衡风暴),它可能会使集群进入连续重新平衡状态,并且 Connect 集群可能需要几分钟才能稳定。在增量协作重新平衡之前,由于重新平衡延迟,集群可以托管的 Connect 任务的数量通常被限制在实际容量以下,给人一种错误的印象,即 Connect 任务是开箱即用的重量级实体。
- 使用增量协作重新平衡,Connect 任务可以是它一直以来的用途:一个轻量级的运行时执行线程,可以在 Connect 集群中的任何位置在全球范围内快速调度。
- 调度这些轻量级实体(可能基于特定于 Kafka Connect 的信息,例如连接器类型、所有者或任务大小等)为 Connect 提供了理想的灵活性,而不会过度扩展其职责。作为 Connect 集群的主要工具,供应和部署工作人员仍然是使用中的编排器的责任——它是 Kubernetes 或类似的基础设施。
现在让我们看看当我们需要重新平衡 Apache Kafka 2.3 及更高版本的 Kafka Connect 集群中的连接器和任务时会发生什么。
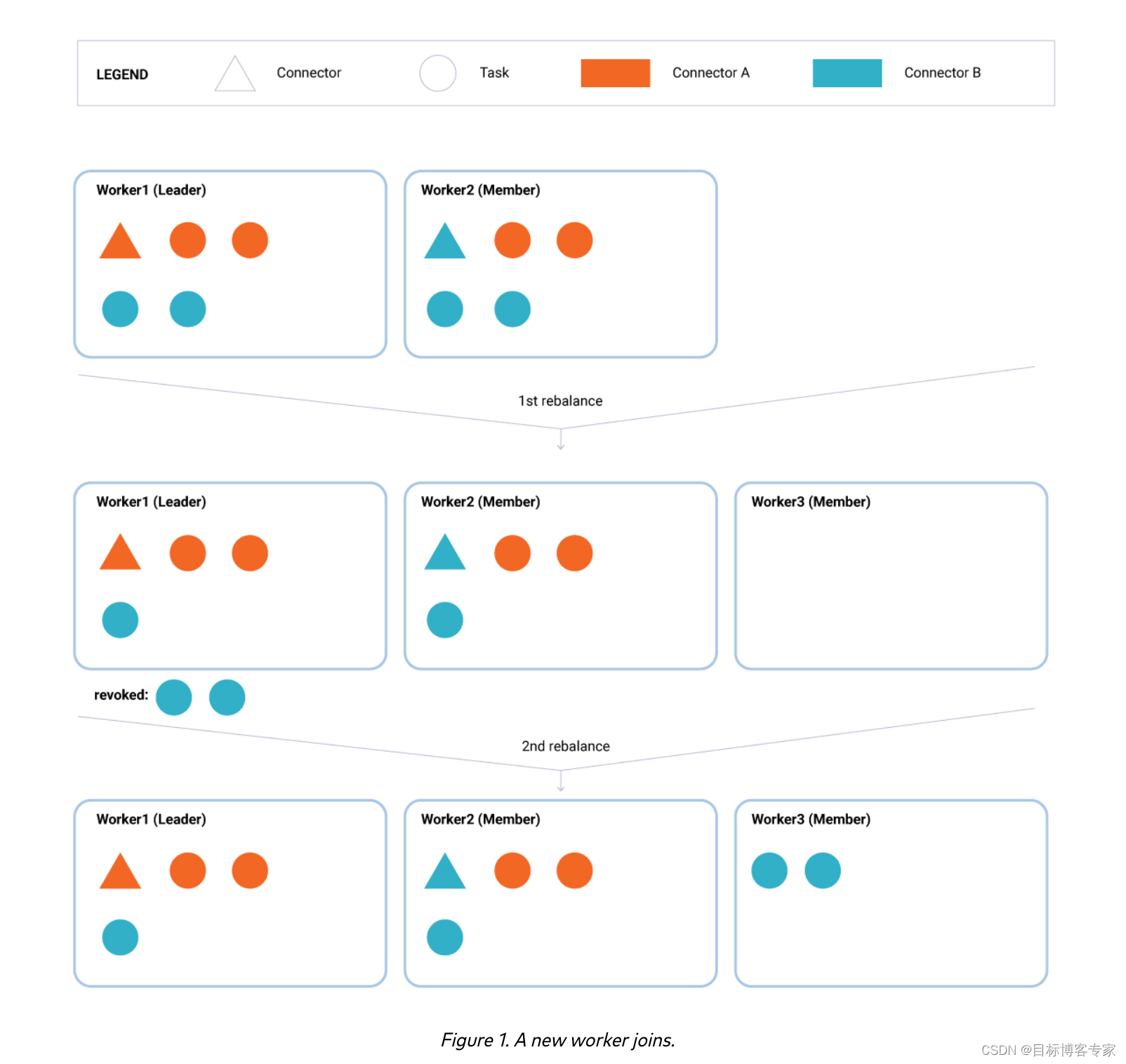
- 一个新的工人加入(图 1)。在第一次重新平衡期间,领导者 (Worker1) 会计算一个新的全局分配,这会导致从每个现有的工作人员 (Worker1 和 Worker2) 中撤销一个任务。因为这第一轮重新平衡包括任务撤销,所以第一次重新平衡之后立即进行第二次重新平衡,在此期间,被撤销的任务被分配给组的新成员 (Worker3)。在两次重新平衡期间,未受影响的任务将继续运行而不会中断。
2. 现有工人跳出(图 2)。在这种情况下,工人 (Worker2) 离开了该组。它的离开触发了重新平衡。在此重新平衡轮中,领导者 (Worker1) 检测到与之前的分配相比,缺少一个连接器和三个任务。这将启用计划的重新平衡延迟,由配置属性 schedule.rebalance.max.delay.ms 控制(默认情况下,它等于五分钟)。
只要此延迟处于活动状态,丢失的任务就会保持未分配状态。这给了离开的工人(或其替代者)一些时间回到小组。一旦发生这种情况,将触发第二次重新平衡,但丢失的任务仍然未分配,直到计划的重新平衡延迟到期。然后,所有工作人员重新加入该组,触发第三次重新平衡。此时leader(Worker1)检测到有一组未分配的任务,一个新的worker使该组保持负载均衡的状态。结果,领导者决定将之前未计入的任务(一个连接器和三个任务)分配给在组中反弹回来的工人(工人2)。
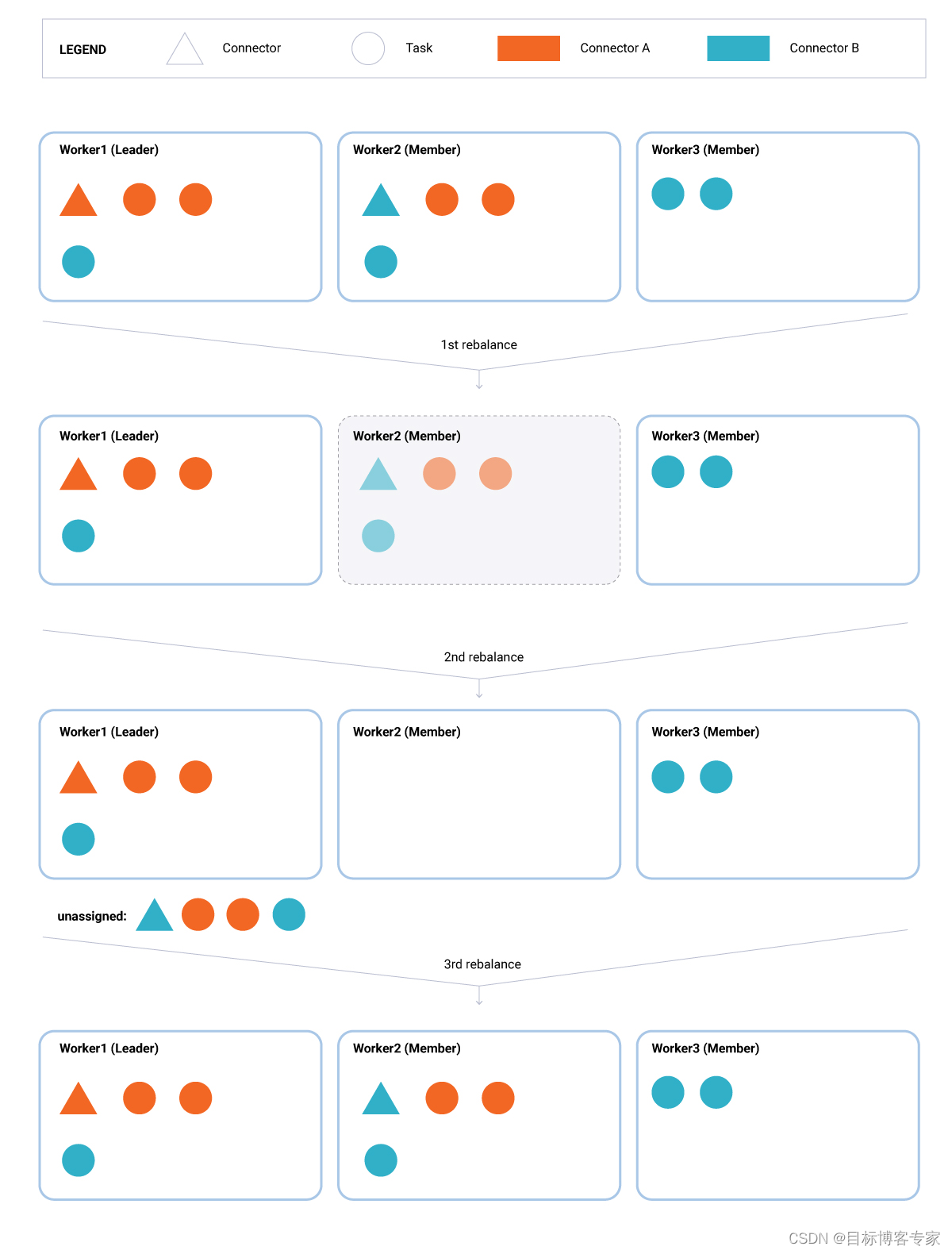
3. 现有工人永久离职(图 3)。这种情况与前一种情况相同,只是在这里,离开的工人 (Worker2) 没有及时重新加入该组。在这种情况下,它的任务(一个连接器和三个任务)在 schedule.rebalance.max.delay.ms 的时间内保持未分配状态。之后,剩下的两个工人(工人 1 和工人 3)重新加入该组,领导者将在计划的重新平衡延迟期间下落不明的任务重新分配给现有的一组活动工人(工人 1 和工人 3)。

新的再平衡行动
使用新的负载均衡有哪些可量化的改进?对 Connect 集群上运行的各个连接器的实际影响是什么,它的扩展特性是什么?新的再平衡算法提出了这些问题以及更多问题。
为了回答这些重要问题,我进行了一些测试。这些结果可以帮助量化增量合作再平衡为 Kafka Connect 带来的改进,并突出这些改进对 Kafka Connect 部署的意义。
第一组测试在成本和扩展方面评估了重新平衡本身作为一个过程。图 4 显示了当大量连接器和任务在由三个工作人员组成的 Kafka Connect 集群上运行时,Eager Rebalancing 与 Incremental Cooperative Rebalancing 的对比情况。所有连接器都是 Kafka Connect S3 连接器。共有 90 个连接器,每个连接器运行 10 个任务,总共有 900 个任务。该测试使用 m4.2xlarge 实例类型在 AWS 上运行以运行工作程序。为了反映更真实的场景,数据记录来自 Confluent Cloud 中的 Kafka 集群,该集群与 Kafka Connect 集群位于同一区域。
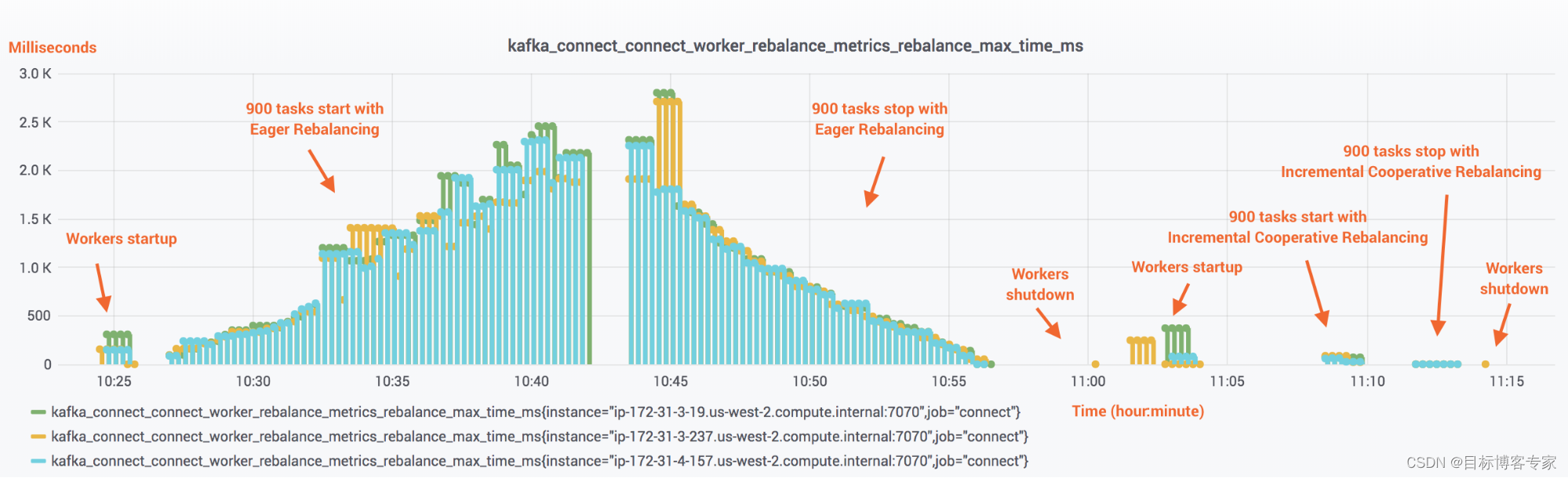
图 4. 使用 Eager Rebalancing 和 Incremental Cooperative Rebalancing 的 900 个 S3 sink 连接器任务的启动和关闭成本(y 轴)和时间线(x 轴)
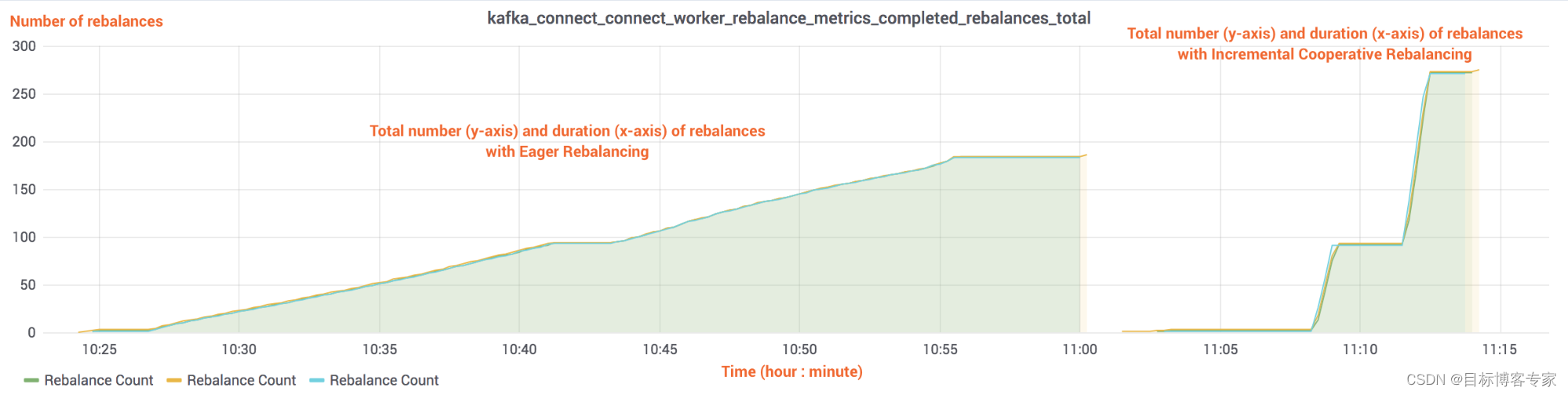
图 5. 使用 Eager Rebalancing 和 Incremental Cooperative Rebalancing 的 900 个 S3 sink 连接器任务的重新平衡总数(y 轴)和启动和关闭时间线(x 轴)
比较图 4 和图 5 可以说明问题。在这些图表的左侧,Eager Rebalancing(当连接器及其任务启动或停止时停止世界)的成本与集群中当前运行的任务数量成正比。连接器启动或停止时的成本相似,分别导致集群稳定的时间约为 14 分钟和 12 分钟。相比之下,在右侧,增量协作再平衡在一分钟内平衡了 900 个任务,并且每个单独的再平衡的成本显然与集群中当前的任务数量无关。图 6 中的条形图通过比较启动和停止 90 个连接器和 900 个任务所花费的时间清楚地表明了这一点。
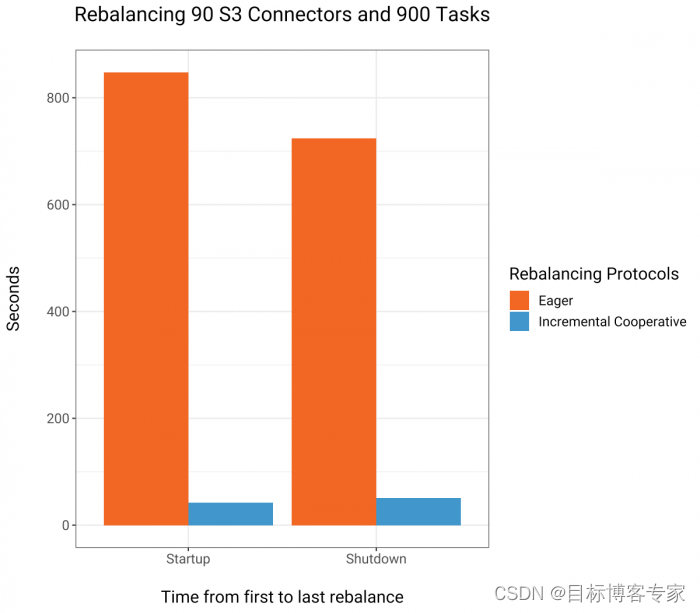
图 6. 通过 Connect 的 REST 接口顺序启动和关闭 900 个 S3 接收器连接器所需的时间比较
第二轮测试揭示了再平衡对特定 Connect 集群中任务整体吞吐量的影响。由于重新平衡可以随时发生,仅测量连接器传输到接收器的字节是不够的。为了捕捉重新平衡对一组活动连接器的实际影响,应将吞吐量视为整个端到端过程,包括记录传输和将消耗的偏移量委托回 Kafka。这是提交偏移量的最后一步,它告诉我们 S3 接收器连接器在存在重新平衡的情况下取得了实际进展。
由于托管 Kafka 服务不会公开消费者偏移量以进行重置,因此接下来的测试使用了一个自我管理的 Kafka 部署,其中五个 Kafka 代理在与 Connect 集群相同的区域中的 m4.2xlarge 实例类型上运行。 Kafka Connect 集群也由三个工作人员组成。吞吐量是根据消费者偏移量的时间戳以毫秒为单位测量的。分别使用 Eager Rebalancing 和 Incremental Cooperative Rebalancing 运行 900 个 S3 sink 连接器任务的结果如表 1 所示:
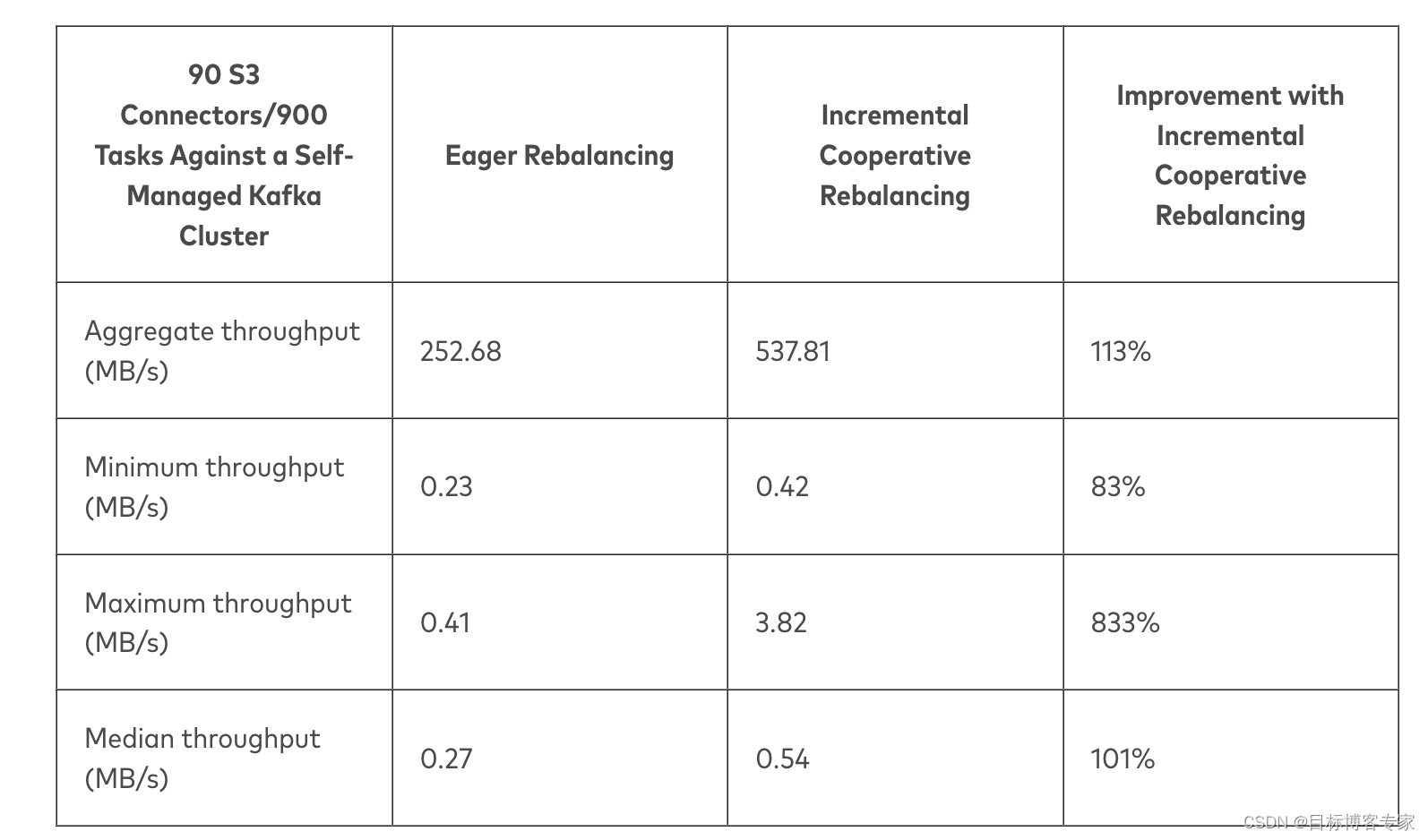
表 1. 在三个 Connect 工作线程上运行 900 个任务时,再平衡协议在测量吞吐量方面的比较:(a) 所有任务,(b) 达到最小吞吐量的任务,© 达到最大吞吐量的任务,以及 (d ) 达到中等吞吐量的任务
表 1 中的行显示了所有 900 个任务实现的总吞吐量,以及最慢、最快和中等任务的吞吐量是多少。在所有情况下,通过增量协作重新平衡都可以提高吞吐量。在大多数情况下,使用增量协作重新平衡时,吞吐量至少会增加一倍。
这些结果表明,增量协作重新平衡允许工作人员在不中断的情况下运行任务,与急切重新平衡相比,这可以显着提高他们的吞吐量。在比较使用两种协议中的任何一种实现最大吞吐量的任务时,在多次重新平衡中维持性能的能力尤其明显。对于增量协作再平衡,性能最高的任务比在急切再平衡下实现最大吞吐量的任务快 9 倍以上。
最后,虽然预计在 Connect 集群稳定后两种情况下的吞吐量都会收敛,但值得注意的是,不能保证长时间不进行再平衡,尤其是在大规模情况下。因此,可以认为这两种协议之间的总体吞吐量差异相当典型。
Kafka Connect 多年来一直在生产中使用,作为希望将其数据系统与 Apache Kafka 集成并创建流的企业的首选平台。通过增量协作重新平衡,连接器能够扩展超出电流限制。使 Connect 能够大规模运行允许更集中和更易于管理的连接器部署,否则这些连接器会被分割成难以操作的较小集群。