CUDA技术体系分析
CUDA(Compute Unified Device Architecture)是一个新的基础架构,这个架构可以使用GPU来解决商业、工业以及科学方面的复杂计算问题。一个完整的GPU解决方案,提供了硬件的直接访问接口,而不必像传统方式一样必须依赖图形API接口来实现GPU的访问。在架构上采用了一种全新的计算体系结构来使用GPU提供的硬件资源,从而给大规模的数据计算应用提供了一种比CPU更加强大的计算能力。CUDA采用C语言作为编程语言提供大量的高性能计算指令开发能力,使开发者能够在GPU的强大计算能力的基础上建立起一种效率更高的密集数据计算解决方案。
从CUDA体系结构的组成来说,包含了三个部分:开发库、运行期环境和驱动。
开发库是基于CUDA技术所提供的应用开发库。CUDA的1.1版提供了两个标准的数学运算库——CUFFT(离散快速傅立叶变换)和CUBLAS(离散基本线性计算)的实现。这两个数学运算库所解决的是典型的大规模的并行计算问题,也是在密集数据计算中非常常见的计算类型。开发人员在开发库的基础上可以快速、方便的建立起自己的计算应用。此外,开发人员也可以在CUDA的技术基础上实现出更多的开发库。
参考文献链接
https://baike.baidu.com/item/CUDA/1186262?fr=aladdin
https://mp.weixin.qq.com/s/IZUt4kh8Cn1wcst958-7MA
https://mp.weixin.qq.com/s/hOb9rhZQpEmOCH8QOY8ubg
运行期环境提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。基于CUDA开发的程序代码在实际执行中分为两种,一种是运行在CPU上的宿主代码(Host Code),一种是运行在GPU上的设备代码(Device Code)。不同类型的代码由于其运行的物理位置不同,能够访问到的资源不同,因此对应的运行期组件也分为公共组件、宿主组件和设备组件三个部分,基本上囊括了所有在GPGPU开发中所需要的功能和能够使用到的资源接口,开发人员可以通过运行期环境的编程接口实现各种类型的计算。
由于存在着多种GPU版本的NVidia显卡,不同版本的GPU之间都有不同的差异,因此驱动部分基本上可以理解为是CUDA-enable的GPU的设备抽象层,提供硬件设备的抽象访问接口。CUDA提供运行期环境也是通过这一层来实现各种功能的。基于CUDA开发的应用必须有NVIDIA CUDA-enable的硬件支持,NVIDIA公司GPU运算事业部总经理Andy Keane在一次活动中表示:一个充满生命力的技术平台应该是开放的,CUDA未来也会向这个方向发展。由于CUDA的体系结构中有硬件抽象层的存在,因此今后也有可能发展成为一个通用的GPGPU标准接口,兼容不同厂商的GPU产品。
CUDA被移植,基于RISC-V的GPU有戏了?
RISC-V 一直是计算领域最热门的话题之一,因为这个指令集架构 (ISA) 允许进行广泛的定制并且易于理解,此外还有整个开源、免许可的好处。甚至还有一个基于 RISC-V ISA 设计通用 GPU 的项目,现在正在见证英伟达的 CUDA 软件库移植到 Vortex RISC-V GPGPU 平台。
Nvidia 的 CUDA(计算统一设备架构)代表了一个独特的计算平台和应用程序编程接口 (API),运行在 Nvidia 的显卡系列上。当为 CUDA 支持编写应用程序时,只要系统发现基于 CUDA 的 GPU,就会获得大量的代码 GPU 加速。
今天,研究人员研究了一种在名为 Vortex的RISC-V GPGPU 项目上启用 CUDA 软件工具包支持的方法。Vortex RISC-V GPGPU 旨在提供基于 RV32IMF ISA 的全系统 RISC-V GPU。这意味着 32 位内核可以从 1 核扩展到 32 核 GPU 设计。支持 OpenCL 1.2 图形 API,今天还支持一些 CUDA 操作。
研究人员解释说:“……在这个项目中,提出并构建了一个pipeline来支持端到端的 CUDA 迁移:pipeline接受 CUDA 源代码作为输入并在扩展的 RISC-V GPU 架构上执行。pipeline包括几个步骤:将CUDA源代码翻译成NVVM IR,将NVVM IR转换成SPIR-V IR,将SPIR-V IR转发成POCL得到RISC-V二进制文件,最后在扩展的RISC-V GPU上执行二进制文件架构。”
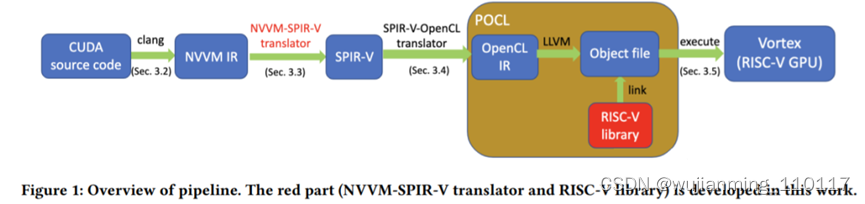
这个过程在上图中可视化,显示了工作的所有步骤。简单来说,CUDA 源代码以称为 NVVM IR 的中间表示 (IR) 格式表示,基于开源 LLVM IR。后来被转换为标准便携式中间表示 (SPIR-V) IR,然后将其转发到 OpenCL 标准的便携式开源实现中,称为 POCL。由于 Vortex 支持 OpenCL,因此提供了受支持的代码,并且可以毫无问题地执行。
有关此复杂过程的更多详细信息,请点击下方阅读原文。重要的是,您必须感谢这些研究人员为使 CUDA 能够在 RISC-V GPGPU 上运行所做的努力。虽然这只是目前的一小步,但可能是 RISC-V 用于加速计算应用程序时代的开始,这与 Nvidia 今天的 GPU 阵容非常相似。
RISC-V能改变GPU吗?
RISC-V能处理GPU的事务吗?这项工作正在进行中,可以通过创建一个具有自定义可编程性和可扩展性的小型区域高效设计来实现这一目标。
任何研究过GPU架构的人都知道这是矢量处理器的SIMD构造。一种超高效的并行处理器,已用于从运行模拟和出色的游戏到教导机器人如何获取AI以及帮助聪明的人操纵股票市场的所有事物。甚至在写这篇文章的时候检查语法。
但GPU领域已经成为一个私有领域,其内部工作是由AMD、Intel、Nvidia等开发者的IP和秘密武器所完成的。如果有一套新的图形指令设计为3D图形和媒体处理呢?嗯,可能有。
新的指令正在RISC-V基本向量指令集上构建。将根据核心RISC-V ISA的精神,添加对特定于图形的新数据类型的支持,作为分层扩展。支持向量,先验数学,像素和纹理以及Z / Frame缓冲区操作。可以是融合的CPU-GPU ISA。lilibrary -RISC 3D组称为RV64X (图1) ,因为指令将是64位长(32位将不足以支持一个健壮的ISA)。
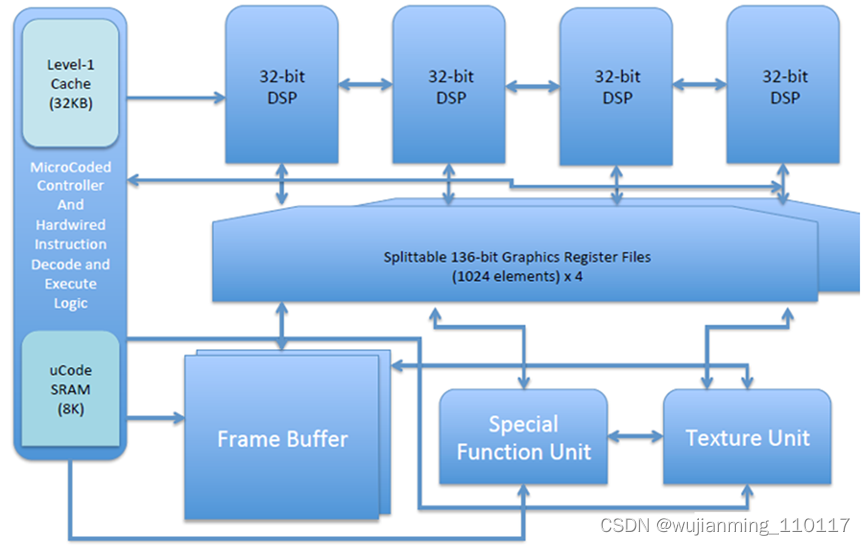
图1.RV64X图形处理器除了专用的纹理单元和功能块外,还包括多个DSP。
该组织表示,动机和目标是希望创造一个小型、高效的设计,具有自定义的可编程性和可扩展性。应该提供低成本的IP所有权和开发,而不是与商业产品竞争。可以在FPGA和ASIC目标上实现,并且是免费和开源的。最初的设计目标是低功耗微控制器,将兼容Khronos Vulkan,并支持其他api (OpenGL, DirectX等)。
GPU + RISC-V
目标硬件将有一个GPU功能单元和一个RISC-V核心。该组合以64位指令编码为标量指令的处理器的形式出现。关键在于编译器将从带前缀的标量操作码生成SIMD指令。其他功能包括可变问题、基于谓词的SIMD后端;分支跟踪;精确的异常;和矢量前端。设计将包括一个16位定点版本和一个32位浮点版本。前者适用于FPGA实现。
该团队说:“不需要使用RPC / IPC调用机制来将3D API调用发送到未使用的CPU内存空间或从未使用的CPU内存空间发送到GPU内存空间,反之亦然,”
“融合” CPU-GPU ISA方法的优势在于可以在微代码中使用标准图形管道,并且可以支持自定义着色器。甚至可以包括光线追踪扩展。
该设计将采用Vblock格式(来自Libre GPU的努力):
• 这有点像VLIW(但不是真的)。
• 指令块之前带有寄存器标记,这些标记为该块内的标量指令提供了额外的上下文。
• 子块包括向量长度,旋转,向量/宽度覆盖和预测。
• 所有这些都添加到标量操作码中!
• 没有矢量操作码(也不需要任何操作码)。
• 在矢量上下文中。如果标量操作码使用寄存器,并且该寄存器在矢量上下文中列出,则将激活矢量模式。
• 激活会导致硬件级别的for循环发出多个连续的标量运算(而不只是一个)。
• 实现者可以自由地以想要的任何方式来实现循环-SIMD,多问题,单执行;几乎任何东西。
RV32-V向量处理2到4个元素的8位,16位或32位/元素的向量操作。对于用于64位和128位固定和浮点XYZW点的常规3D图形渲染管线,还将有专门的指令。8、16、24和32位RGBA像素; 8位,每个组件16位UVW纹素;以及灯光和材质设置(Ia,ka,Id,kd,Is,ks等)。
属性向量表示为4×4矩阵。该系统将本地支持2×2和3×3矩阵。向量支持也可能适用于使用AI和机器学习应用程序中常见的8位整数数据类型的数值模拟。
设计中可以包含自定义光栅化器,例如样条线,SubDiv曲面和面片。该方法还允许包含自定义管线阶段,自定义几何/像素/帧缓冲阶段,自定义细分器和自定义实例化操作。
RV64X
RV64X参考实现包括:
• 指令/数据SRAM缓存(32 kB)
• 微码SRAM(8 kB)
• 双功能指令解码器(实现RV32V和X的硬连线;用于自定义ISA的微编码指令解码器)
• 四向量ALU(32位/ ALU-固定/浮动)
• 136位寄存器文件(1k个元素)
• 特殊功能单元
• 纹理单位
• 可配置的本地帧缓冲区
RV64X是可扩展的架构(图2)。融合方法是新的,对于自定义数据类型使用可配置寄存器也是如此。用户定义的基于SRAM的微代码可用于实现扩展,例如自定义光栅化器阶段,光线跟踪,机器视觉和机器学习。单一设计可以应用于独立的图形微控制器或具有可扩展着色器单元的多核解决方案。

图2.RV64X可以从简单的低端设计(左)扩展到多核解决方案(右)。
RISC-V的图形扩展可以解决可伸缩性和多语言问题。这可以实现更高级别的用例,从而带来更多的创新。
下一步是什么
RV64X规范仍在早期开发中,可能会发生变化。正在建立一个讨论论坛。近期目标是使用指令集模拟器构建示例实现。这将在使用开放源代码IP和设计为开放源代码项目的自定义IP的FPGA实现上运行。
CUDA的实践- GPU与AI学习系列7
十多年来,CUDA发展迅速。
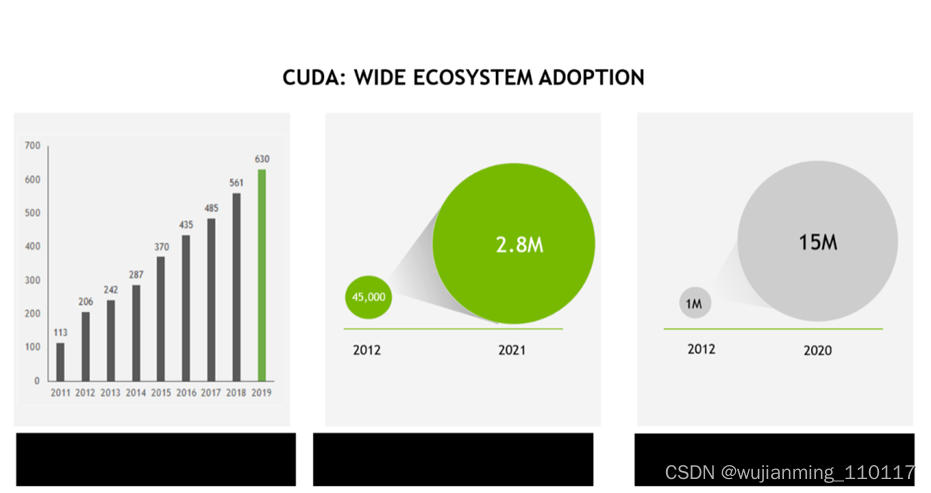
CUDA的下载地址:https://developer.nvidia.com/cuda-downloads
目前CUDA最新的版本是11.7。
CUDA11增加了对A100的支持、增加了对ARM的支持,增加了C++并行标准库。
NVC的数学库如下:



• cuSPARSE线性代数库,主要针对稀疏矩阵之类的。
• cuBLAS是CUDA标准的线代库,不过没有专门针对稀疏矩阵的操作。
• cuFFT傅里叶变换
• cuRAND随机数
https://www.cnblogs.com/developer.nvidia.com


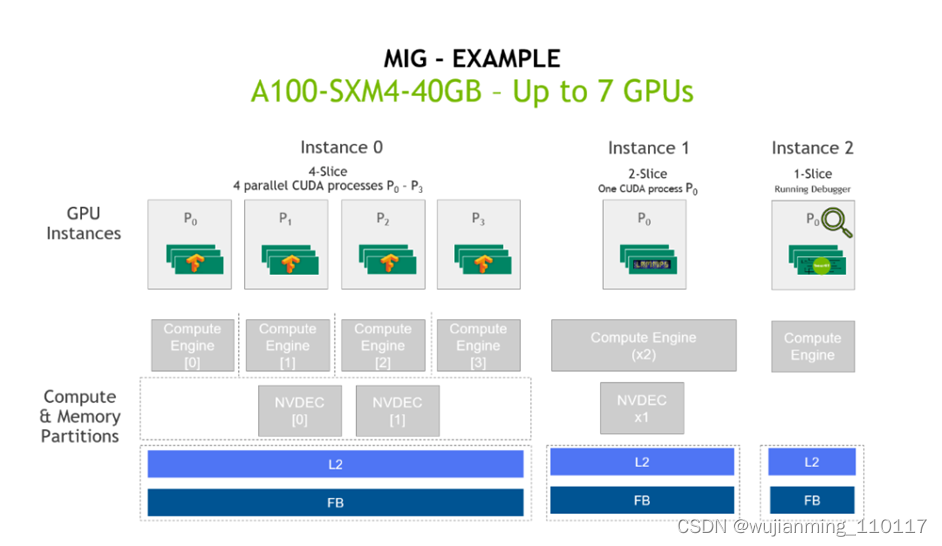
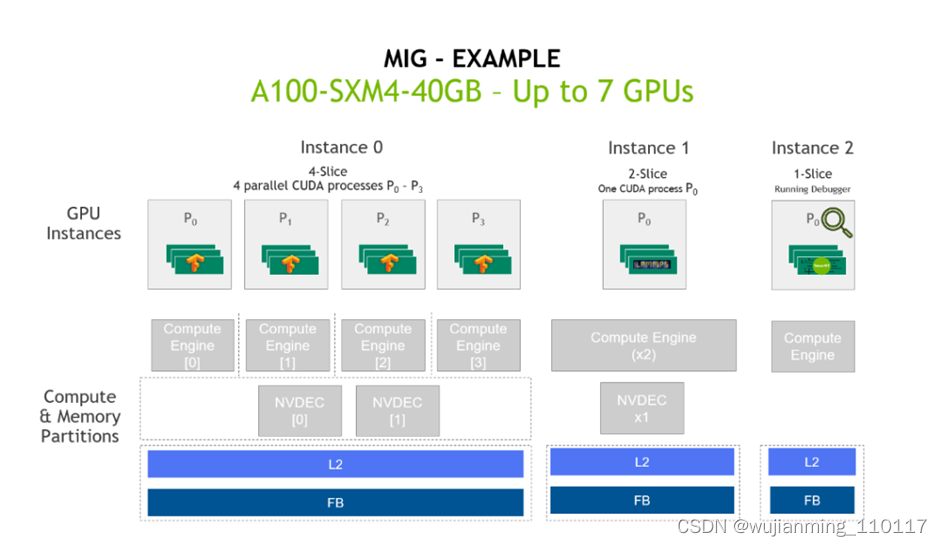
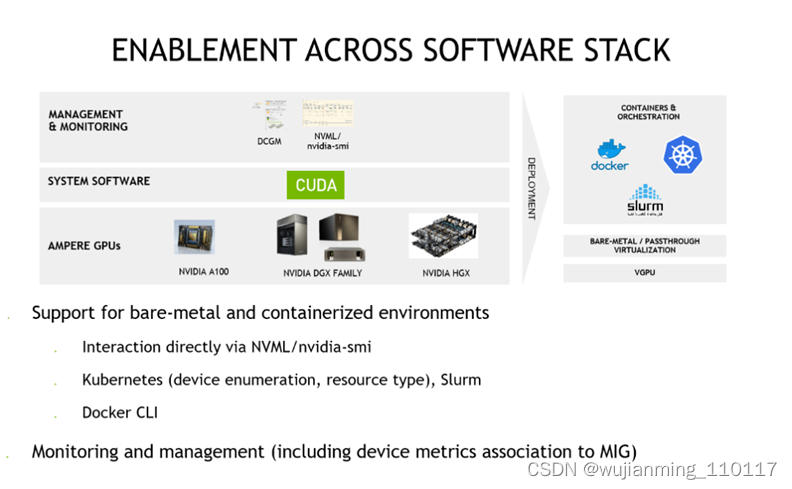
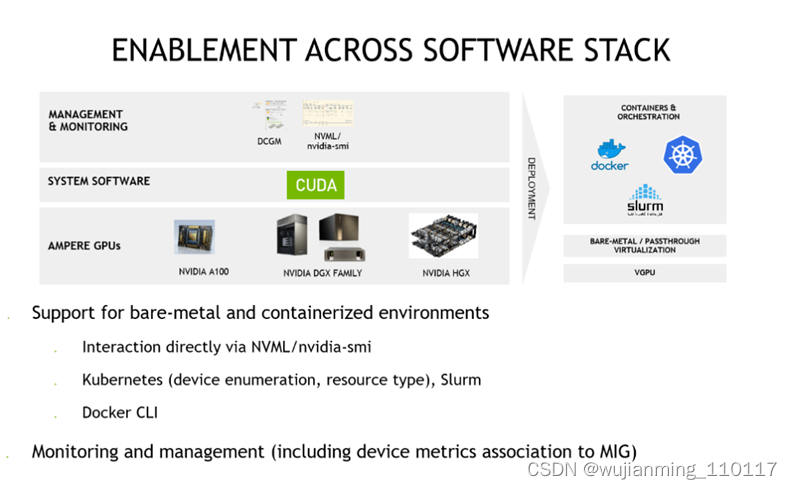
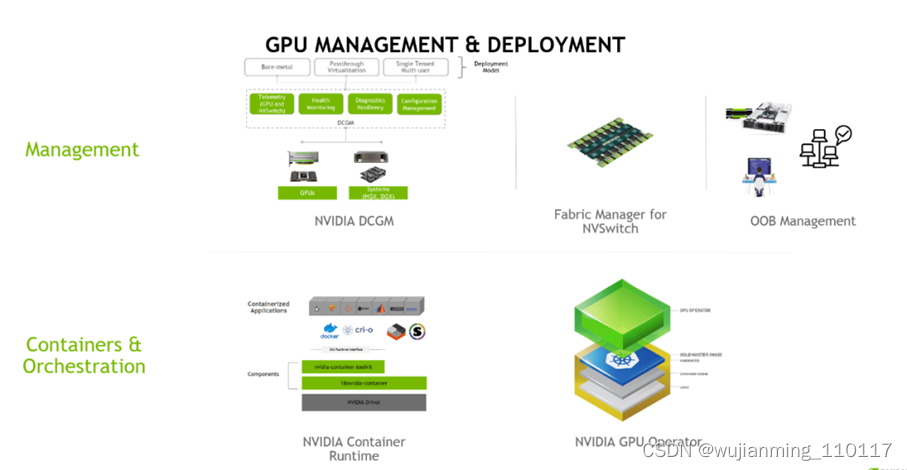
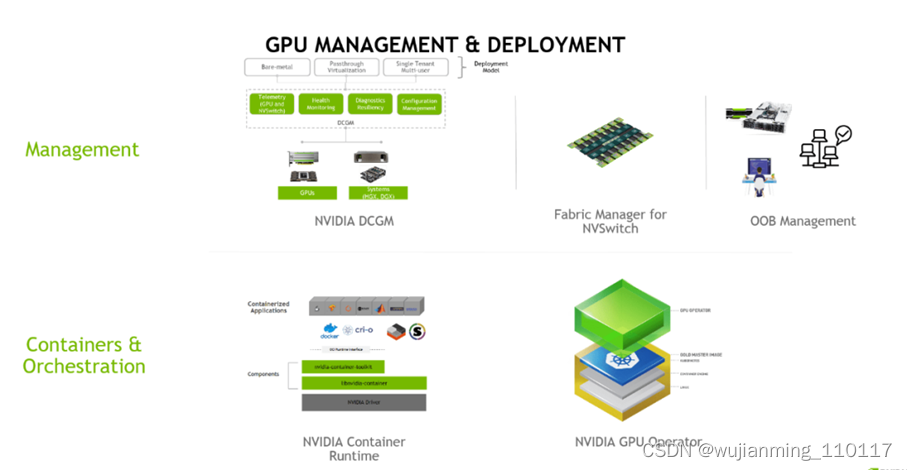
接下来,展示如何在CentOS 8上安装CUDA。
在安装CUDA之前,首先要为GPU安装启动。虽然CUDA中也包含驱动,但一般生产环境都要进行版本控制。
第一步要禁掉nouveau。一个第三方开源的Nvidia驱动,一般Linux安装的时候默认会安装这个驱动。这个驱动会与Nvidia官方的驱动冲突,在安装Nvidia驱动和CUDA之前应先禁用nouveau。
#lsmod | grep nouveau
如果有显示内容,则进行以下的步骤进行禁用nouveau
vim /etc/modprobe.d/blacklist-nouveau.confblacklist nouveau options nouveau modeset=0sudo mv /boot/initramfs- ( u n a m e − r ) . i m g / b o o t / i n i t r a m f s − (uname -r).img /boot/initramfs- (uname−r).img/boot/initramfs−(uname -r).img.baksudo dracut /boot/initramfs-$(uname -r).img ( u n a m e − r ) s u d o r e b o o t l s m o d ∣ g r e p n o u v e a u 接 下 来 , 安 装 显 卡 驱 动 : g c c − V y u m i n s t a l l g c c y u m i n s t a l l g c c − c + + s u d o y u m i n s t a l l k e r n e l − d e v e l − (uname -r)sudo rebootlsmod | grep nouveau 接下来,安装显卡驱动: gcc -V %如没有安装,需重新安装 yum install gcc yum install gcc-c++sudo yum install kernel-devel- (uname−r)sudorebootlsmod∣grepnouveau接下来,安装显卡驱动:gcc−Vyuminstallgccyuminstallgcc−c++sudoyuminstallkernel−devel−(uname -r) kernel-headers-$(uname -r)
查看GPU类型:
lspci | grep -i nvidia

下载驱动。
在下面的链接中,选择GPU的类型、配套的CUDA版本、操作系统版本:
https://www.nvidia.com/download/index.aspx


chmod u+x NVIDIA-Linux-x86_64-450.57.run%执行安装脚本sudo ./NVIDIA-Linux-x86_64-450.57.run --kernel-source-path=/usr/src/kernels/4.18.0-193.el8.x86_64
确认驱动安装成功:
nvidia-smi
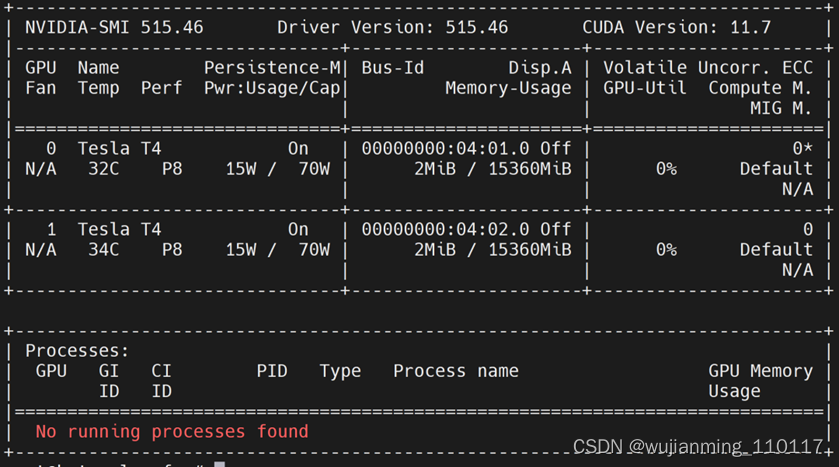
驱动安装成功后,在系统中就能看到GPU了。
接下来,安装CUDA。
如果是离线环境,需要手工下载CUDA。如果是在线环境,并且网速够快,那就不用单独下载。最新的cuda版本是11.7,查看CUDA 11.7对环境要求。
https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#system-requirements
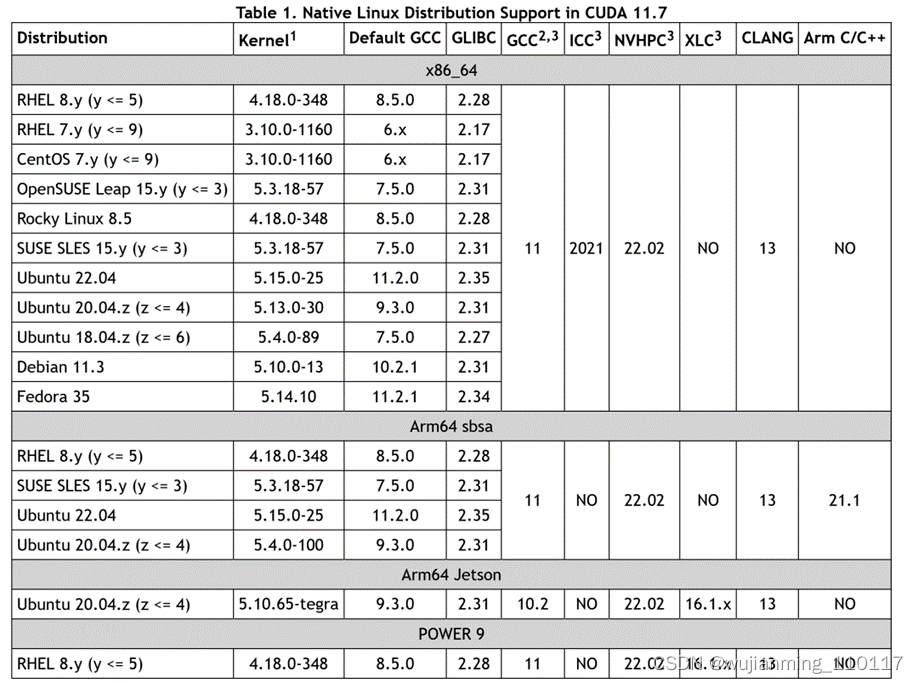
如果下载的话,地址如下:
https://developer.nvidia.com/cuda-downloads?target_os=Linux
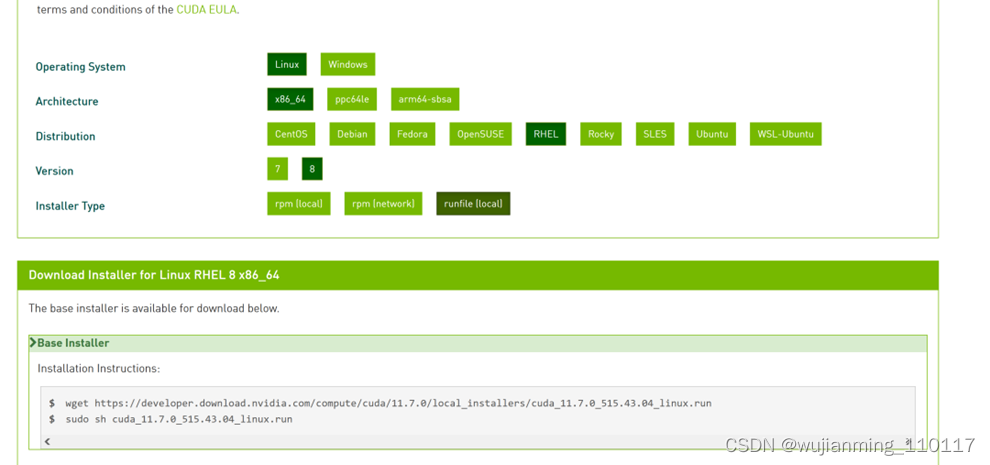
#wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda_11.7.0_515.43.04_linux.run#sudo sh cuda_11.7.0_515.43.04_linux.run

因为此前已经安装了驱动,此处反勾选驱动。
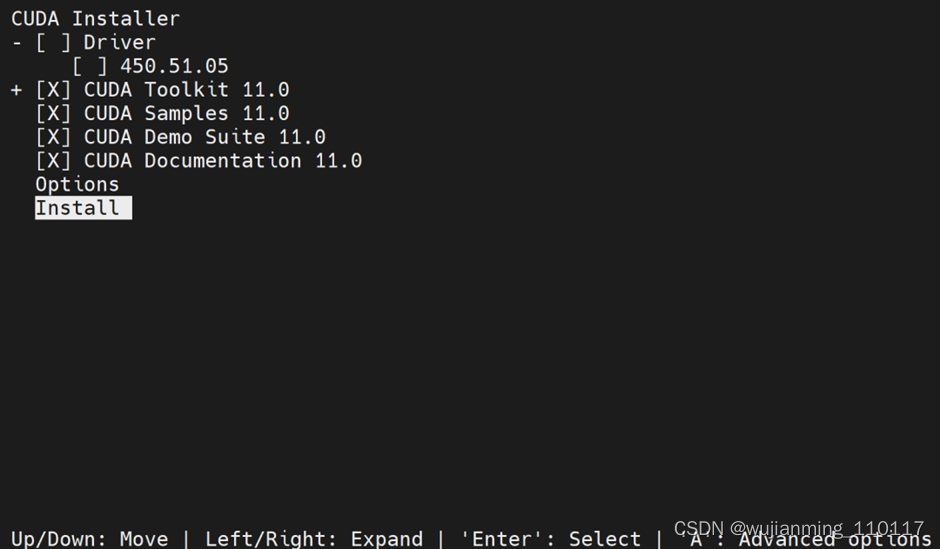
配置环境变量:
sudo vim /etc/profileexport PATH=/usr/local/cuda-11.0/binKaTeX parse error: Expected '}', got 'EOF' at end of input: {PATH:+:{PATH}} export LD_LIBRARY_PATH=/usr/local/cuda-%11.0/lib64KaTeX parse error: Expected '}', got 'EOF' at end of input: …LIBRARY_PATH:+:{LD_LIBRARY_PATH}}sudo reboot
确认cuda安装成功:
nvcc -V
nvcc: NVIDIA ® Cuda compiler driver
Copyright © 2005-2020 NVIDIA Corporation
Built on Thu_Jun_11_22:26:38_PDT_2020
Cuda compilation tools, release 11.0, V11.0.194
Build cuda_11.0_bu.TC445_37.28540450_0
参考文献链接
https://baike.baidu.com/item/CUDA/1186262?fr=aladdin
https://mp.weixin.qq.com/s/IZUt4kh8Cn1wcst958-7MA
https://mp.weixin.qq.com/s/hOb9rhZQpEmOCH8QOY8ubg