JVM体系结构

7.1.2JVM体系结构详解
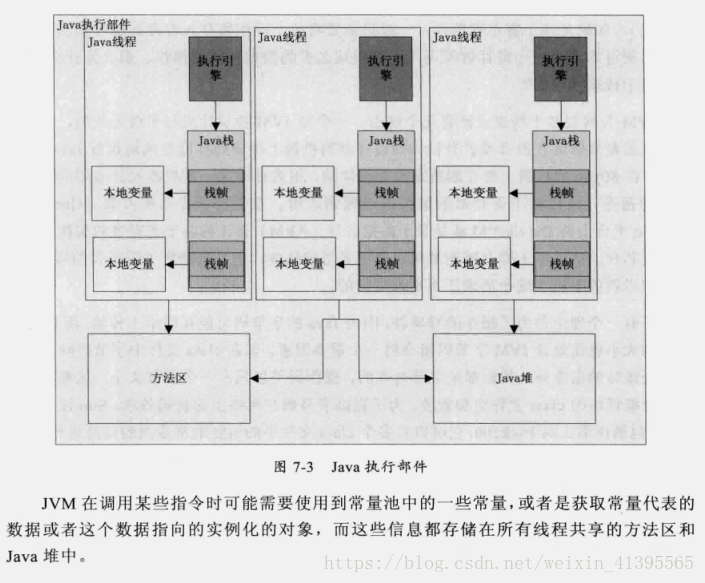
我们再看看除了指令集之外,JVM还需要那些组成部分。如图7-2所示,JVM的结构基本上由4部分组成。
- 类加载器,在JVM启动时或者在类运行时将需要的class加载到JVM中。
- 执行引擎,执行引擎的任务是负责执行class文件中包含的字节码指令,相当于实际机器上的CPU。
- 内存区,将内存划分成若干个区以模拟实际机器上的存储、记录和调度功能模块,如实际机器上的各种功能的寄存器或者PC指针的记录器等。

JVM内存结构
在Java虚拟机规范中将Java运行时数据划分为6种
-
PC寄存器数据
-
Java栈
-
堆
-
方法区
方法区这个存储区域也属于Java堆中的一部分(永久区) -
本地方法栈
本地方法栈是为了JVM运行Native方法准备的空间,由于很多Native方法都是用C语言实现的,所以它通常又叫C栈。 -
方法区与本地方法栈
-
方法区:
1.又叫静态区,跟堆一样,被所有的线程共享。方法区包含所有的class和static变量。2.方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
-
运行时常量池
在用户空间Java堆上的方法区中。
7.2.2JVM为何选择基于栈的结构
指令集都会有对应的架构实现,如基于寄存器的架构实现或者基于栈的架构实现,这里的基于寄存器或者栈都是指在一个指令中的操作数是如何存取的。
JVM执行字节码指令是基于栈的架构,也就是所有的操作数必须先入栈,然后根据指令中的操作码选择从栈顶弹出若干个元素进行计算后再将结果压入栈中。在JVM中操作数可以可以存放在每一个栈桢中的一个本地变量集中,即在每个方法调用时就胡igei这个方法分配一个本地变量集,这个本地变量集在编译时就已经确定,所以操作数入栈可以直接是常量入栈或者从本地变量集中取一个变量压入栈中。这和一般的基于寄存器的操作有所不同,一个操作需要频繁地入栈和出栈,如进行一个加法运算,如果连个操作数都在本地变量中,那么一个加法操作就要有5次栈操作,分别是将两个操作数从本地变量入栈(2次入栈操作),再将两个操作数出栈用于加法运算(2次出栈),再将加法结果压入栈顶(1次入栈)。如果是基于寄存器的话,一般只需要将两个操作数存入寄存器进行加法运算后再将结果存入其中一个寄存器即可,不需要那么多的数据移动的操作。那么为什么JVM还要基于栈来设计呢?
JVM为何要基于栈来设计有几个理由。一个是JVM要设计成与平台无关的,而平台无关性就是要保证在没有或者有很少的寄存器的机器上也要同样能正确地执行Java代码。例如,在80X86的机器上寄存器就是没有规律的,很难针对某一款机器设计通用的基于寄存器的指令,所以基于寄存器的架构很难做到通用。在收集操作系统方面,Google的Android平台上的Dalvik VM就是基于特定芯片(ARM)设计的基于寄存器的架构,这样在特定芯片上实现基于寄存器的架构可能更多考虑性能,但是也牺牲了跨平台的移植性,当然在当前的手机上这个需求还不是最迫切的。
还有一个理由是为了指令的紧凑性,因为Java的字节码可能在网络上传输,所以class文件的大小也是设计JVM字节码指令的一个重要因素,如在class文件中字节码除了处理两个表跳转的指令外,其他都是字节对齐的,操作码可以只占一个字节大小,这都是为了尽量让编译后的class文件更加紧凑。
-
7.2.3执行引擎的架构设计
每当创建一个新的线程时,JVM会为这个线程创建一个Java栈,同时会为这个线程分配一个PC寄存器,并且这个PC寄存器会指向这个线程的第一行可执行代码。每当调用一个新方法时会在这个栈上创建一个新的栈帧数据结构,这个栈帧会保留这个方法的一些元信息,如在这个方法中定义的局部变量、一些用来支持常量池的解析、正常方法返回及异常处理机制等。
-