Kubernetes普罗米修斯技术栈
在为我们的客户部署Kubernetes基础设施时,在每个集群上部署监控技术栈是标准做法。这个堆栈通常由几个组件组成:
-
Prometheus:收集度量标准
-
告警管理器:根据指标查询向各种提供者发送警报
-
Grafana:可视化豪华仪表板
简化架构如下:

注意事项
这种架构有一些注意事项,当你想从其中获取指标的集群数量增加时,它的伸缩性以及可扩展性不太好。
多个Grafana
在这种设置中,每个集群都有自己的Grafana和自己的一组仪表板,维护起来很麻烦。
存储指标数据是昂贵的
Prometheus将指标数据存储在磁盘上,你必须在存储空间和指标保留时间之间做出选择。如果你想长时间存储数据并在云提供商上运行,那么如果存储TB的数据,块存储的成本可能会很高。同样,在生产环境中,Prometheus经常使用复制或分片或两者同时运行,这可能会使存储需求增加两倍甚至四倍。
解决方案
多个Grafana数据源
可以在外部网络上公开Prometheus的端点,并将它们作为数据源添加到单个Grafana中。你只需要在Prometheus外部端点上使用TLS或TLS和基本认证来实现安全性。此解决方案的缺点是不能基于不同的数据源进行计算。
Prometheus联邦
Prometheus联邦允许从Prometheus中抓取Prometheus,当你不抓取很多指标数据时,这个解决方案可以很好地工作。在规模上,如果你所有的Prometheus目标的抓取持续时间都比抓取间隔长,可能会遇到一些严重的问题。
Prometheus远程写
虽然远程写入是一种解决方案(也由Thanos receiver实现),但我们将不在本文中讨论“推送指标”部分。你可以在这里[1]阅读关于推送指标的利弊。建议在不信任多个集群或租户的情况下(例如在将Prometheus构建为服务提供时),将指标作为最后的手段。无论如何,这可能是以后文章的主题,但我们将在这里集中讨论抓取。
Thanos,它来了
Thanos是一个“开源的,高可用的Prometheus系统,具有长期存储能力”。很多知名公司都在使用Thanos,也是CNCF孵化项目的一部分。
Thanos的一个主要特点就是允许“无限”存储空间。通过使用对象存储(比如S3),几乎每个云提供商都提供对象存储。如果在前提环境下运行,对象存储可以通过rook或minio这样的解决方案提供。
它是如何工作的?
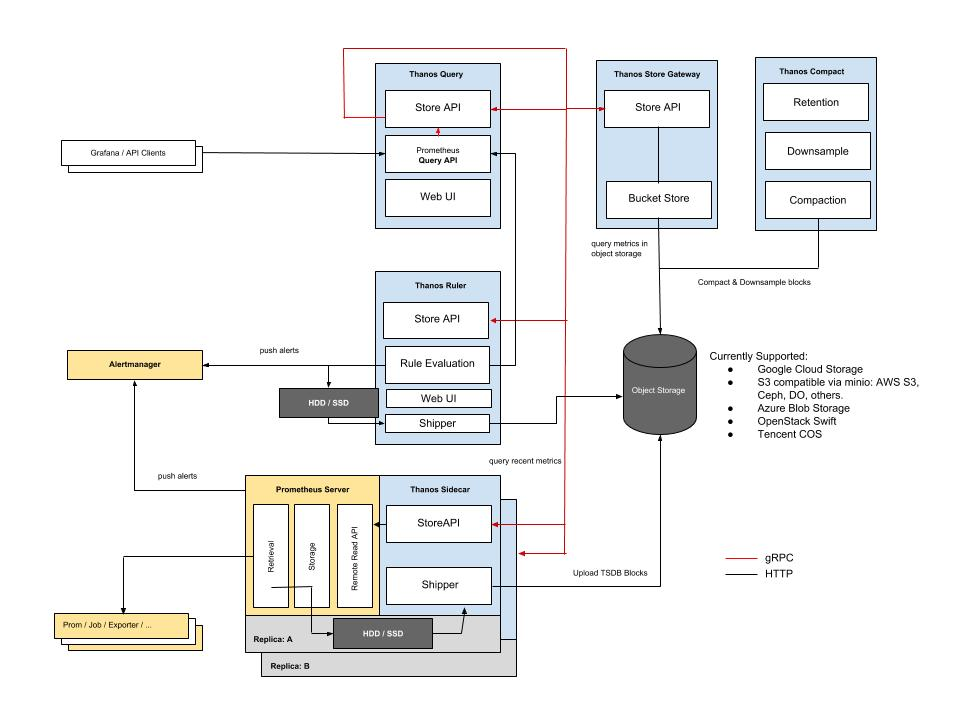
Thanos和Prometheus并肩作战,从Prometheus开始升级到Thanos是很常见的。Thanos被分成几个组件,每个组件都有一个目标(每个服务都应该这样:)),组件之间通过gRPC进行通信。
Thanos Sidecar

Thanos和Prometheus一起运行(有一个边车),每2小时向一个对象存储库输出Prometheus指标。这使得Prometheus几乎是无状态的。Prometheus仍然在内存中保存着2个小时的度量值,所以在发生宕机的情况下,你可能仍然会丢失2个小时的度量值(这个问题应该由你的Prometheus设置来处理,使用HA/分片,而不是Thanos)。
Thanos sidecar与Prometheus运营者和Kube Prometheus栈一起,可以轻松部署。这个组件充当Thanos查询的存储。
Thanos存储
Thanos存储充当一个网关,将查询转换为远程对象存储。它还可以在本地存储上缓存一些信息。基本上,这个组件允许你查询对象存储以获取指标。这个组件充当Thanos查询的存储。
Thanos Compactor
Thanos Compactor是一个单例(它是不可扩展的),它负责压缩和降低存储在对象存储中的指标。下采样是随着时间的推移对指标粒度的宽松。例如,你可能想将你的指标保持2年或3年,但你不需要像昨天的指标那么多数据点。这就是压缩器的作用,它可以在对象存储上节省字节,从而节省成本。
Thanos Query
Thanos查询是Thanos的主要组件,它是向其发送PromQL查询的中心点。Thanos查询暴露了一个与Prometheus兼容的端点。然后它将查询分派给所有的“stores”。记住,Store可能是任何其他提供指标的Thanos组件。Thanos查询可以发送查询到另一个Thanos查询(他们可以堆叠)。
-
Thanos Store
-
Thanos Sidecar
-
Thanos Query
还负责对来自不同Store或Prometheus的相同指标进行重复数据删除。例如,如果你有一个度量值在Prometheus中,同时也在对象存储中,Thanos Query可以对该指标值进行重复数据删除。在Prometheus HA设置的情况下,重复数据删除也基于Prometheus副本和分片。
Thanos Query Frontend
正如它的名字所暗示的,Thanos查询前端是Thanos查询的前端,它的目标是将大型查询拆分为多个较小的查询,并缓存查询结果(在内存或memcached中)。
还有其他组件,比如在远程写的情况下接收Thanos,但这仍然不是本文的主题。
Thanos
Thanos![]() https://thanos.io/ 是一个基于 Prometheus 实现的监控方案,其主要设计目的是解决原生 Prometheus 上的痛点,并且做进一步的提升,主要的特性有:全局查询,高可用,动态拓展,长期存储。下图是 Thanos 官方的架构图:
https://thanos.io/ 是一个基于 Prometheus 实现的监控方案,其主要设计目的是解决原生 Prometheus 上的痛点,并且做进一步的提升,主要的特性有:全局查询,高可用,动态拓展,长期存储。下图是 Thanos 官方的架构图:
Thanos 主要由如下几个特定功能的组件组成:(相当于微服务的模式,里面有比较多的组件)
- 边车组件(Sidecar):连接 Prometheus,并把 Prometheus 暴露给查询网关(Querier/Query),以供实时查询,并且可以上传 Prometheus 数据给云存储,以供长期保存
- 查询网关(Querier/Query):实现了 Prometheus API,与汇集底层组件(如边车组件 Sidecar,或是存储网关 Store Gateway)的数据
- 存储网关(Store Gateway):将云存储中的数据内容暴露出来
- 压缩器(Compactor):将云存储中的数据进行压缩和下采样
- 接收器(Receiver):从 Prometheus 的 remote-write WAL(Prometheus 远程预写式日志)获取数据,暴露出去或者上传到云存储
- 规则组件(Ruler):针对监控数据进行评估和报警
- Bucket:主要用于展示对象存储中历史数据的存储情况,查看每个指标源中数据块的压缩级别,解析度,存储时段和时间长度等信息。
从使用角度来看有两种方式去使用 Thanos,sidecar模式和 receiver 模式。
sidecar架构模式
Thanos Sidecar 组件需要和 Pormetheus 实例一起部署,用于代理 Thanos Querier 组件对本地 Prometheus 的数据读取,允许 Querier 使用通用、高效的StoreAPI 查询 Prometheus 数据。
第二是将 Prometheus 本地监控数据通过对象存储接口上传到对象存储中,这个上传是实时的,只要发现有新的监控数据保存到磁盘,会将这些监控数据上传至对象存储。下面是Sidecar模式架构图。
可以看到普罗米修斯有多个副本A,B,需要部署一个sidecar和Prometheus部署在一起,有多少个Prometheus副本就需要部署多少个sidecar。
当客户端去查询数据的时候,会根据query来查询结果,如果数据还在本地,因为比较新的数据,实时数据还是在本地的,sidecar是要等到Prometheus的数据存盘,两个小时之后才能够识别到,然后将两个小时之后的数据上传到远程存储上面,查询的数据如果是两个小时之后的话,会代理到store gateway这边,数据从对象存储当中拿就行了。
如果是两个小时之前,实时最新的数据,那么从sidecar中获取。
Thanos Sidecar 组件在 Prometheus的远程读 API 之上实现了 Thanos 的Store API,这使得 Querier 可以将 Prometheus 服务器视为时间序列数据的另一个来源,而无需直接与它的 API 进行交互。(query的数据来源可以是来源于存储网关 thanos store gateway,从对象存储中获取,最新的实时的热数据就从sidecar这边获取,sidecar和Prometheus对接一下就行了)
因为 Prometheus 每 2 小时生成一个时序数据块,Thanos Sidecar 会每隔 2 小时将这个块上传到一个对象存储桶中。这样 Prometheus 服务器就可以以相对较低的存储空间运行,同时通过对象存储提供历史数据,使得监控数据具有持久性和可查询性。但是这样并不意味着 Prometheus 可以完全无状态,因为如果 Prometheus 崩溃并重新启动,我们将失去大约 2 个小时的指标数据,所以 Prometheus 在实际运行中还是需要持久性磁盘的。
receiver 架构模式
Thanos Receiver 实现了 Prometheus 远程写 API,它构建在现有的 Prometheus TSDB 之上,并保持其实用性,同时通过长期存储、水平可伸缩性和下采样扩展其功能。Prometheus 实例被配置为连续地向它写入指标,然后 Thanos Receiver 默认每 2 小时将时间序列格式的监控数据块上传到-个对象存储的桶中。ThanoS Receiver 同样暴露了 Store API,以便 Thanos Querier 可以实时查询接收到的指标。
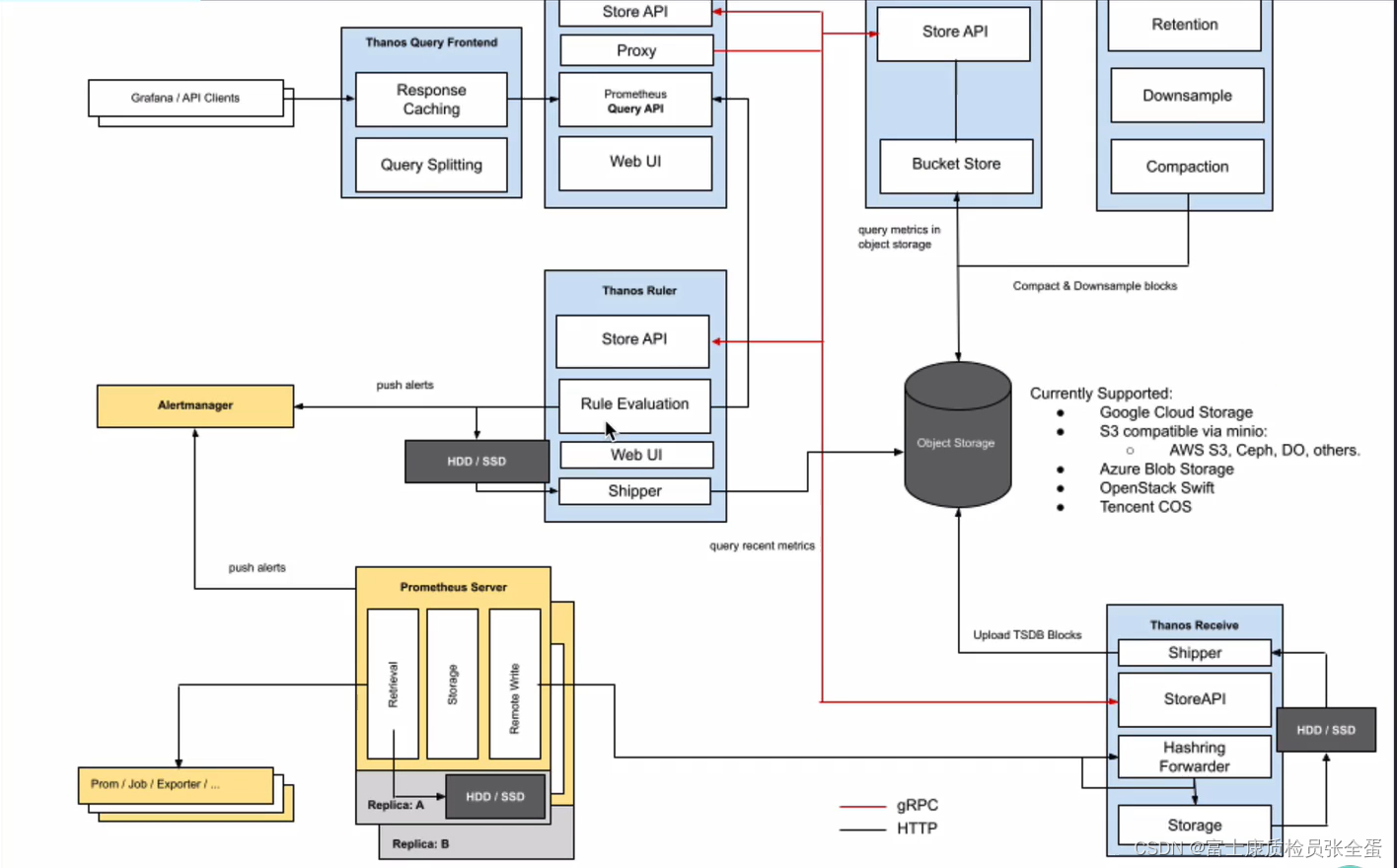
之前是sidecar模式和Prometheus对接,然后将数据上传到对象存储上面去,而现在没有一个组件直接上传到对象存储,而是通过thanos receive,Prometheus有个远程写,可以将数据远程写入到thanos receive里面去,然后这个组件每隔两个小时将数据上传到对象存储里面。
查询也是一样,如果是两个小时之前,也就是热数据,那么查询到的也是receive里面的数据,这里没有sidecar,所以最新的数据实在receive里面了。
这种方式相对于之前更加轻量级一些,因为每个Prometheus server都得跟着sidecar,现在只需要有个receive,看起来就压力比较大了。
这两种模式有各种的优缺点,具体使用哪种模式需要结合生产环境综合考虑。
工作流程 sidecar模式
Thanos 是同时支持 Prometheus 读和写的远程存储方案,首先我们先看下指标写入的整个流程:
- 首先 Prometheus 从所采集服务的 metrics 接口抓取指标数据,同时根据自身所配置的
recording rules定期对抓取到的指标数据进行评估,将结果以 TSDB 格式分块存储到本地,每个数据块的存储时长为 2 小时,且默认禁用了压缩功能。 - 然后
sidecar嗅探到 Prometheus 的数据存储目录生成了新的只读数据块时,会将该数据块上传到对象存储桶中做为长期历史数据保存,在上传时会将数据块中的meta.json进行修改添加 thanos 相关的字段,如external_labels。 rule根据所配置的recording rules定期地向query发起查询获取评估所需的指标值,并将结果以 TSDB 格式分块存储到本地。每个数据块的存储时长为 2 小时,且默认禁用了压缩功能,每个数据块的meta.json也附带了 thanos 拓展的external_lables字段。当本地生成了新的只读数据块时,其自身会将该数据块上传到远端对象存储桶中做为长期历史数据保存。compact定期将对象存储中地数据块进行压缩和降准采样,进行压缩时数据块中的 truck 会进行合并,对应的meta.json中的 level 也会一同增长,每次压缩累加 1,初始值为 1。在进行降准采样时会创建新的数据块,根据采样步长从原有的数据块中抽取值存储到新的数据块中,在meta.json中记录resolution为采样步长。
读取指标的流程为:
- 首先客户端通过
query API向query发起查询,query将请求转换成StoreAPI发送到其他的query、sidecar、rule和store上。 sidecar接收到来自于query发起的查询请求后将其转换成query API请求,发送给其绑定的 Prometheus,由 Prometheus 从本地读取数据并响应,返回短期的本地采集和评估数据。rule接收到来自于query发起的查询请求后直接从本地读取数据并响应,返回短期的本地评估数据。store接收到来自于query发起的查询请求后首先从对象存储桶中遍历数据块的meta.json,根据其中记录的时间范围和标签先进行一次过滤。接下来从对象存储桶中读取数据块的index和chunks进行查询,部分查询频率较高的index会被缓存下来,下次查询使用到时可以直接读取。最终返回长期的历史采集和评估指标。
对于发送报警的流程如下所示:
- Prometheus 根据自身配置的
alerting规则定期地对自身采集的指标进行评估,当告警条件满足的情况下发起告警到 Alertmanager 上。 rule根据自身配置的alerting规则定期的向query发起查询请求获取评估所需的指标,当告警条件满足的情况下发起告警到 Alertmanager 上。- Alertmanager 接收到来自于 Prometheus 和
rule的告警消息后进行分组合并后发出告警通知。
特性
Thanos 相比起原生的 Prometheus 具有以下的一些优势:
- 统一查询入口——以
Querier作为统一的查询入口,其自身实现了 Prometheus 的查询接口和StoreAPI,可为其他的Querier提供查询服务,在查询时会从每个 Prometheus 实例的Sidecar和Store Gateway获取到指标数据。 - 查询去重——每个数据块都会带有特定的集群标签,
Querier在做查询时会去除集群标签,将指标名称和标签一致的序列根据时间排序合并。虽然指标数据来自不同的采集源,但是只会响应一份结果而不是多份重复的结果。(如果是Prometheus多个实例,同时去对指标数据进行采集,这样就需要对数据去重,只保留一份数据就行了) - 高空间利用率——每个 Prometheus 本身不存储长时间的数据,
Sidecar会将 Prometheus 已经持久化的数据块上传到对象存储中。Compactor会定时将远端对象存储中的长期数据进行压缩,并且根据采样时长做清理,节约存储空间。(使用sidecar模式就需要保留很多数据,只需要本地保留2个小时的数据,其余的数据在对象存储当中) - 高可用——
Querier是无状态服务,天生支持水平拓展和高可用。Store、Rule和Sidecar是有状态服务,在多副本部署的情况下也支持高可用,不过会产生数据冗余,需要牺牲存储空间。 - 存储长期数据——Prometheus 实例的
Sidecar会将本地数据上传到远端对象存储中作为长期数据 - 横向拓展——当 Prometheus 的指标采集压力过大时,可以创建新的 Prometheus 实例,将
scrape job拆分给多个 Prometheus,Querier从多个 Prometheus 查询汇聚结果,降低单个 Prometheus 的压力 - 跨集群查询——需要合并多个集群的查询结果时,仅需要在每个集群的
Querier之上再添加一层Querier即可,这样的层层嵌套,可以使得集群规模无限制拓展。(可以将当前的query作为另外一个query的数据源)