在上一篇文章介绍了在不同节点之间通过相互共享地址和建立连接,最终形成一个去中心化的P2P网络,让所有的客户端都能提供资源,包括带宽,存储空间和计算能力。随着时间的推移,不断有新的节点加入到Bitcoin网络,结合原有的节点,本地的节点地址数据库也会不断增长。当分享地址,检查节点是否重复分享时,需要实现一个类似“元素是否在集合中”的算法。
布隆过滤器介绍
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为:
![]()
布隆过滤器的原理是,当一个元素被加入集合时,通过k个散列函数将这个元素映射成一个位数组中的k个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
先假设布隆过滤器由长度为 m =10的位向量(在c++位向量可使用vector来实现),位向量仅包含 0 或 1 ,最初所有的值均设置为 0,如下图所示。

为了将数据项添加到布隆过滤器中,我们会提供 k个不同的哈希函数,并将结果位置上对应位的值置为 “1”。使用k个不同函数的目的是将数据项分别使用k个哈希函数得出不同的索引值。在实际使用过程中,相当于是一个哈希函数使用k个不同的参数。
现假设IP地址为192.168.2.1经过三次哈希运算得出的索引值是2、4、6。我们把相应的位置1。假设另一个IP地址192.168.2.2,哈希函数输出 的索引值3、4 和 7。你可能已经注意到,索引位 4 已经被先前的 “192.168.2.1” 标记了。下表中,我们已经使用 192.168.2.1 和 192.168.2.2 两个输入值的哈希索引值填充了位向量。

接下来如果192.168.2.3的哈希运算结果是2、3、7,那么和上两个IP地址的哈希运算的结果位置合集重叠了。在实际搜索时,先计算哈希值索引值,然后去向量表中查找指定的位置是否为1来判断是否存在。实际上192.168.2.3是不存在的,但运算结果却相反,这显然是误报。产生的原因是由于哈希碰撞导致的巧合而将不同的元素存储在相同的比特位上。幸运的是,布隆过滤器有一个可预测的误判率(fp):

![]() 元素的数量;
元素的数量;
![]() 哈希的次数;
哈希的次数;
![]() 布隆过滤器的长度(比特数组的大小);
布隆过滤器的长度(比特数组的大小);
极端情况下,当布隆过滤器没有空闲空间时(满),每一次查询都会返回 true 。这也就意味着 m 的选择取决于期望预计添加元素的数量 n ,并且 m 需要远远大于 n 。
根据上述公式,我们可以推导计算布隆过滤器的长度m的计算公式:

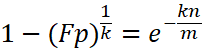
两边同时求自然对数:
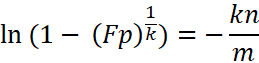
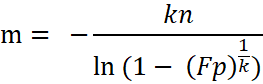
根据
![]()
得出:

相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数O(k)。另外,散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
循环布隆过滤器(Rolling Bloom Filter)
Bitcoin中P2P网络系统中,判断节点IP地址是否存在,避免重复发送,使用了循环布隆过滤器(Rolling Bloom Filter),它时布隆过滤算法的变种。在Bitcoin的应用场景中,布隆过滤器的向量个数不可能设置无限大,目标是使用合理的向量空间实现尽可能多的数据的判别,并在经过一个周期之后重置布隆过滤器中的数据,意味着之前已添加到布隆过滤器中的的数据项,在重置之后将清空。也就意味着节点IP地址可以重新发送。比如说我们设定元素的个数n=5000,每2500作为一轮,3轮之后重新进入一个新的循环。在哈希计算位置时,加入轮的参数,奇数轮和偶数轮使用不同的位置。这种循环的思路来判别“元素是否存在集合中“在Bitcoin系统中之所以是允许的,因为它不要求所有求节点的IP地址永远不重复。
Rollin Bloom Filter实现代码如下:
CRollingBloomFilter::CRollingBloomFilter(const unsigned int nElements, const double fpRate)
{
double logFpRate = log(fpRate);
/* The optimal number of hash functions is log(fpRate) / log(0.5), but
* restrict it to the range 1-50. */
nHashFuncs = std::max(1, std::min((int)round(logFpRate / log(0.5)), 50));
/* In this rolling bloom filter, we'll store between 2 and 3 generations of nElements / 2 entries. */
nEntriesPerGeneration = (nElements + 1) / 2;
uint32_t nMaxElements = nEntriesPerGeneration * 3;
/* The maximum fpRate = pow(1.0 - exp(-nHashFuncs * nMaxElements / nFilterBits), nHashFuncs)
* => pow(fpRate, 1.0 / nHashFuncs) = 1.0 - exp(-nHashFuncs * nMaxElements / nFilterBits)
* => 1.0 - pow(fpRate, 1.0 / nHashFuncs) = exp(-nHashFuncs * nMaxElements / nFilterBits)
* => log(1.0 - pow(fpRate, 1.0 / nHashFuncs)) = -nHashFuncs * nMaxElements / nFilterBits
* => nFilterBits = -nHashFuncs * nMaxElements / log(1.0 - pow(fpRate, 1.0 / nHashFuncs))
* => nFilterBits = -nHashFuncs * nMaxElements / log(1.0 - exp(logFpRate / nHashFuncs))
*/
uint32_t nFilterBits = (uint32_t)ceil(-1.0 * nHashFuncs * nMaxElements / log(1.0 - exp(logFpRate / nHashFuncs)));
data.clear();
/* For each data element we need to store 2 bits. If both bits are 0, the
* bit is treated as unset. If the bits are (01), (10), or (11), the bit is
* treated as set in generation 1, 2, or 3 respectively.
* These bits are stored in separate integers: position P corresponds to bit
* (P & 63) of the integers data[(P >> 6) * 2] and data[(P >> 6) * 2 + 1]. */
data.resize(((nFilterBits + 63) / 64) << 1);
reset();
}
/* Similar to CBloomFilter::Hash */
static inline uint32_t RollingBloomHash(unsigned int nHashNum, uint32_t nTweak, Span<const unsigned char> vDataToHash)
{
return MurmurHash3(nHashNum * 0xFBA4C795 + nTweak, vDataToHash);
}
void CRollingBloomFilter::insert(Span<const unsigned char> vKey)
{
if (nEntriesThisGeneration == nEntriesPerGeneration) {
nEntriesThisGeneration = 0;
nGeneration++;
if (nGeneration == 4) {
nGeneration = 1;
}
uint64_t nGenerationMask1 = 0 - (uint64_t)(nGeneration & 1);
uint64_t nGenerationMask2 = 0 - (uint64_t)(nGeneration >> 1);
/* Wipe old entries that used this generation number. */
for (uint32_t p = 0; p < data.size(); p += 2) {
uint64_t p1 = data[p], p2 = data[p + 1];
uint64_t mask = (p1 ^ nGenerationMask1) | (p2 ^ nGenerationMask2);
data[p] = p1 & mask;
data[p + 1] = p2 & mask;
}
}
nEntriesThisGeneration++;
for (int n = 0; n < nHashFuncs; n++) {
uint32_t h = RollingBloomHash(n, nTweak, vKey);
int bit = h & 0x3F;
/* FastMod works with the upper bits of h, so it is safe to ignore that the lower bits of h are already used for bit. */
uint32_t pos = FastRange32(h, data.size());
/* The lowest bit of pos is ignored, and set to zero for the first bit, and to one for the second. */
data[pos & ~1U] = (data[pos & ~1U] & ~(uint64_t{1} << bit)) | (uint64_t(nGeneration & 1)) << bit;
data[pos | 1] = (data[pos | 1] & ~(uint64_t{1} << bit)) | (uint64_t(nGeneration >> 1)) << bit;
}
}
bool CRollingBloomFilter::contains(Span<const unsigned char> vKey) const
{
for (int n = 0; n < nHashFuncs; n++) {
uint32_t h = RollingBloomHash(n, nTweak, vKey);
int bit = h & 0x3F;
uint32_t pos = FastRange32(h, data.size());
/* If the relevant bit is not set in either data[pos & ~1] or data[pos | 1], the filter does not contain vKey */
if (!(((data[pos & ~1U] | data[pos | 1]) >> bit) & 1)) {
return false;
}
}
return true;
}
void CRollingBloomFilter::reset()
{
nTweak = GetRand(std::numeric_limits<unsigned int>::max());
nEntriesThisGeneration = 0;
nGeneration = 1;
std::fill(data.begin(), data.end(), 0);
}
代码说明
哈希函数的次数在1到50次之间
nHashFuncs = std::max(1, std::min((int)round(logFpRate / log(0.5)), 50));
每一轮可添加的元素个数:
nEntriesPerGeneration = (nElements + 1) / 2;
最大可添加的元素个数:
uint32_t nMaxElements = nEntriesPerGeneration * 3;
布隆过滤器比特向量数组大小
uint32_t nFilterBits = (uint32_t)ceil(-1.0 * nHashFuncs * nMaxElements / log(1.0 - exp(logFpRate / nHashFuncs)));
根据比特向量大小换算成具体类型大小,本使用的是 uint64_t,换算的结果是unit64_t的个数。
data.resize(((nFilterBits + 63) / 64) << 1);
获取哈希值,n表示Hash函数的次数,nTweak是一个随机数,vKey是要添加的数据
uint32_t h = RollingBloomHash(n, nTweak, vKey);
将哈希值转换为向量中的比特位置,取哈希值的最低6位,故最大值为63。
int bit = h & 0x3F;
将哈希值转换为向量的位置
uint32_t pos = FastRange32(h, data.size());
pos & ~1U :获得pos的偶数,如 pos:1503则返回1502,1104则返回1104,如果pos是奇数-1
pos | 1 :获得pos的奇数,如 pos:3091则返回3091,1104则返回1105,如果pos是偶数+1
如果nGeneration是奇数,将(pos & ~1U)位置bit位置的值设置为1,如果是偶数设置为0;如果nGeneration是偶数,将(pos | 1)位置bit位置的值设置为1,如果是奇数设置为0
data[pos & ~1U] =
(data[pos & ~1U] & ~(uint64_t{1} << bit)) | (uint64_t(nGeneration & 1)) << bit;
data[pos | 1] =
(data[pos | 1] & ~(uint64_t{1} << bit)) | (uint64_t(nGeneration >> 1)) << bit;
存储示意图:

在使用c++实现布隆过滤器时,布隆过滤器的向量可以指定一个具体的数据类型,而不是一个二进制类型。比如Bitcoin使用的是一个64位无符号数(uint64_t)。那么按照前面的公式计算出来的布隆过滤器的长度m转换为实际数据类型的长度=(m+63)/64,每个位置可以存储64位,相当于有64个位置。因此在添加数据时,先计算数字的哈希值,根据哈希值确认在数量向量中的位置pos,再取哈希值的低6位(0x3c)获得一个不超过63的整数,该整数就是在向量中二进制位的位置bit。
在Bitcoin的循环布隆过滤器中,添加数据到布隆过滤器时,每个数据哈希10次,每次占用两个数据向量位置(pos)。因此数量向量的长度是((m+63)/64)<< 1,是为了获得该范围的差为2的等差数列的最大值。当pos为奇数时,占用pos-1和pos两个位置,当pos为偶数时,占用pos和pos+1两个位。bit位的位置置为1的时候跟nGeneration奇偶有关,具体如下表:

nGeneration在一个小轮结束后递增1,当超过三个小轮时nGeneration从头开计数,开始一个大轮。从而实现类似循环布隆过滤器的功能。该算法以较小的向量数量实现较多的数据位存储,避免向量空间无限扩张。同时Rolling Bloom Filter允许在经过一个大轮后将清除原有的位标记,这意味着在经过一个周期后,Bitcoin系统允许发送以前发送过的节点地址,这也有利于节点的重建。
哈希函数的选择
输入数据时必须通过哈希来生成一个无符号的整数,该整数作为布隆过滤器的向量的索引值。MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。由Austin Appleby在2008年发明,与其它流行的哈希函数相比,对于规律性较强的key,MurmurHash的随机分布特征表现更良好。该名称来自其内部循环中使用的两个基本运算,即乘法(MU)和旋转(R)。 与加密散列函数不同,它没有专门设计为很难被对手逆转,使其不适合加密目的。MurmurHash3,基于MurmurHash2 改进了一些小瑕疵,使得速度更快,实现了32位(低延时)、128 位 HashKey,尤其对大块的数据,具有较高的平衡性与低碰撞率。
MurmurHash3详见地址:
https://code.google.com/p/smhasher/source/browse/trunk/MurmurHash3.cpp
本篇文章主要相关代码:
https://github.com/bitcoin/bitcoin/blob/master/src/common/bloom.cpp