- 使用的编辑器:jupyter notebook
第一章 深度学习的基本概念,发展历程介绍
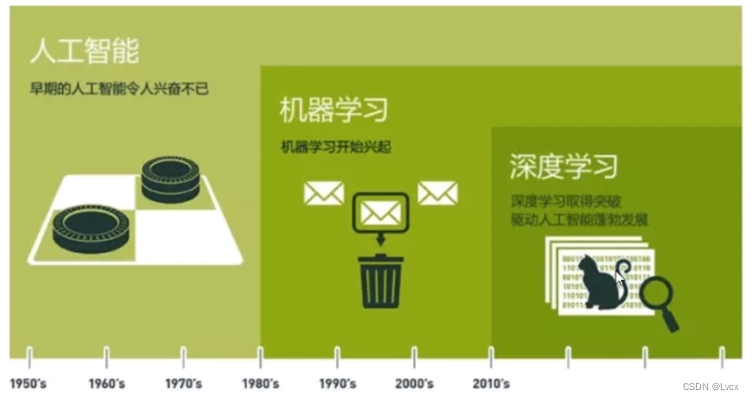
1-1 深度学习介绍
1-2 感知器
1. 介绍
- 感知器是最简单的神经网络,又称为感知机。
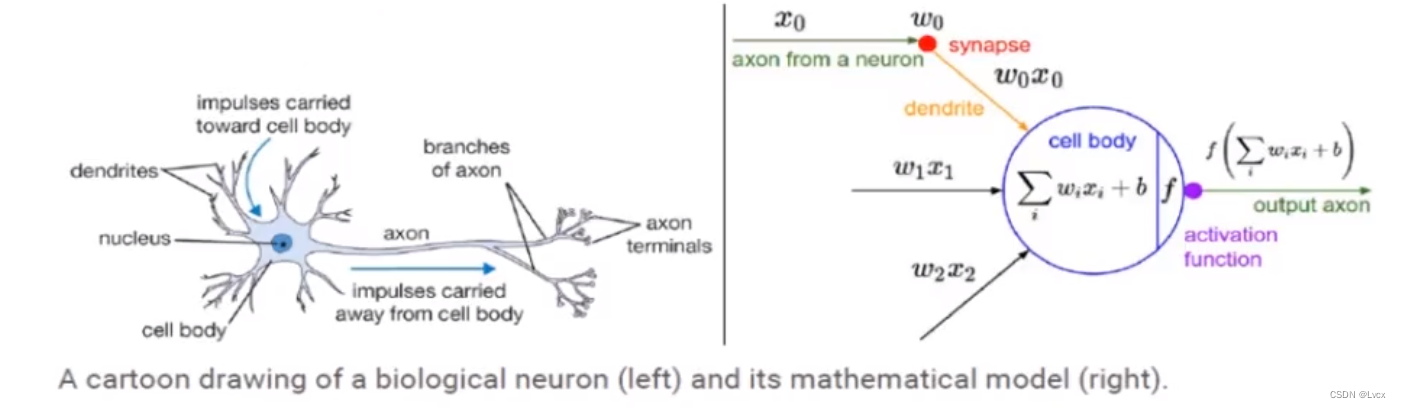
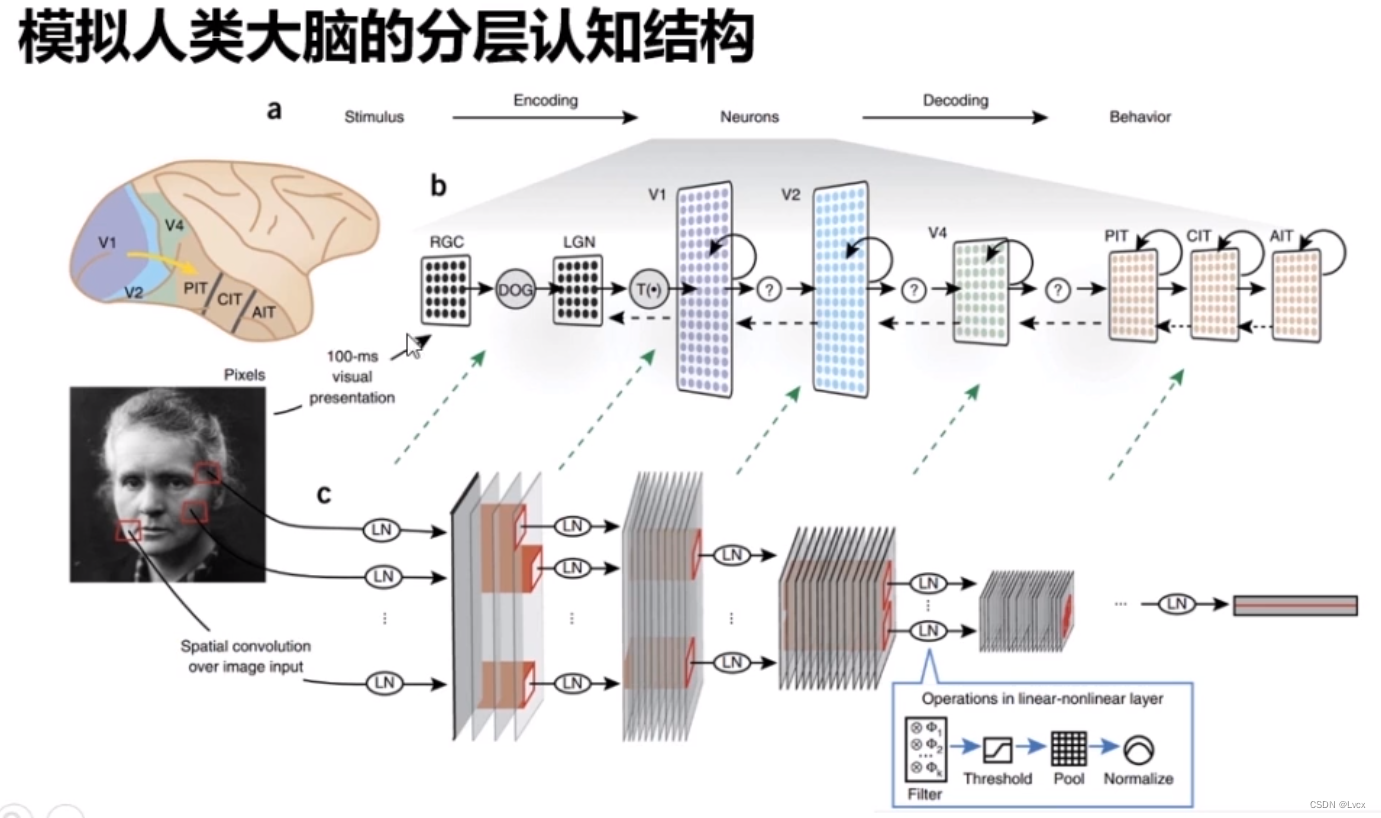
-每一个神经元都可以被认为是一个处理单元/神经核(Processing Unit/Nucleus),它含有许多输入/树突(Input/Dendrite),并且有一个输出/轴突(Output/Axon)。
- 神经网络是大量神经元相互链接并通过电脉冲来交流的一个网络。
2. 数学模型
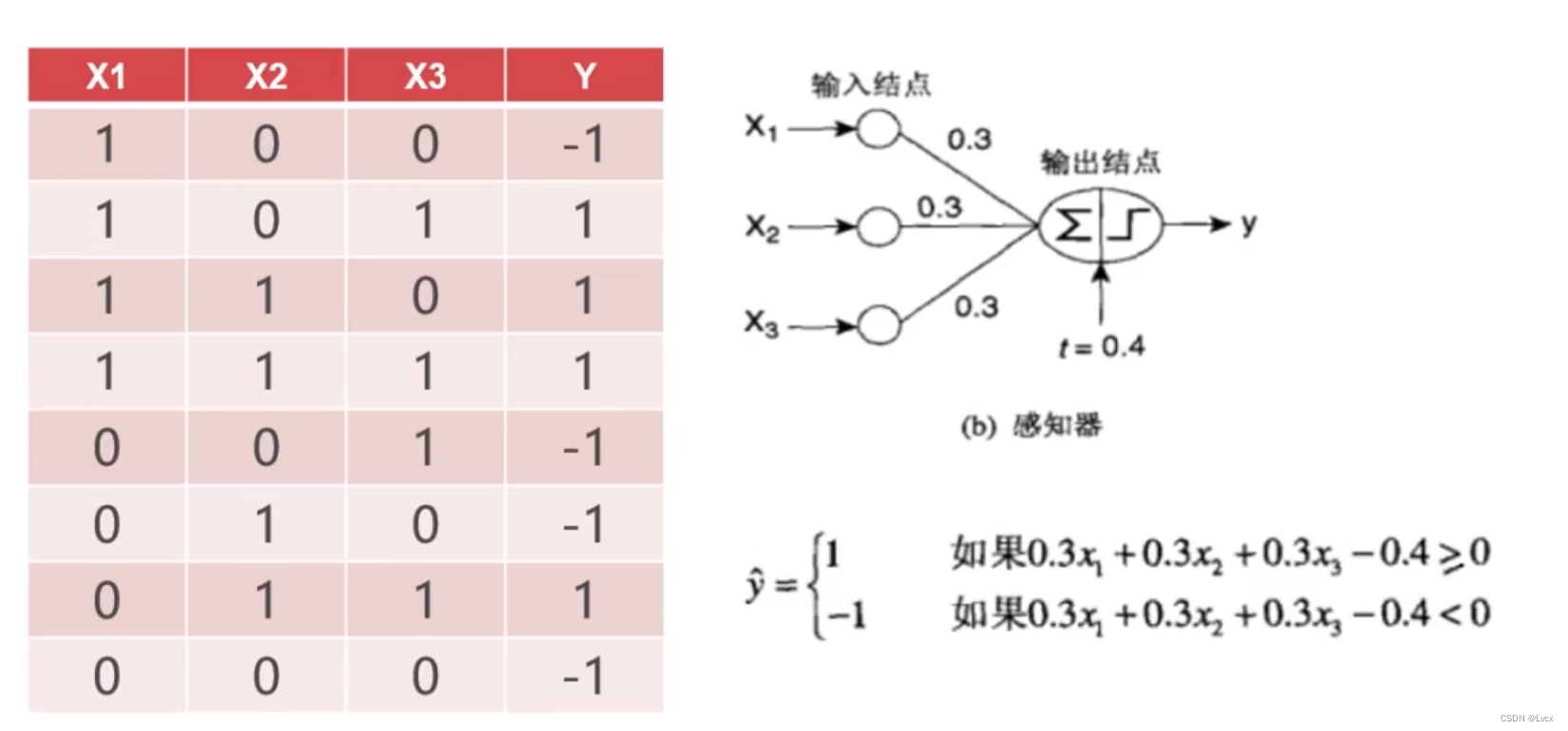
- 感知器模型很简单,但其作用很大。感知器对于神经网络,相当于砖块对于建造房屋的作用。
- 感知器发展空间很大,可以通过修改损失函数发展成支持向量机,也可以通过堆叠发展成神经网络。
- 神经网络的搭建,就是通过构造数学表达式,然后求解其权重系数和偏置值,来达成构建。
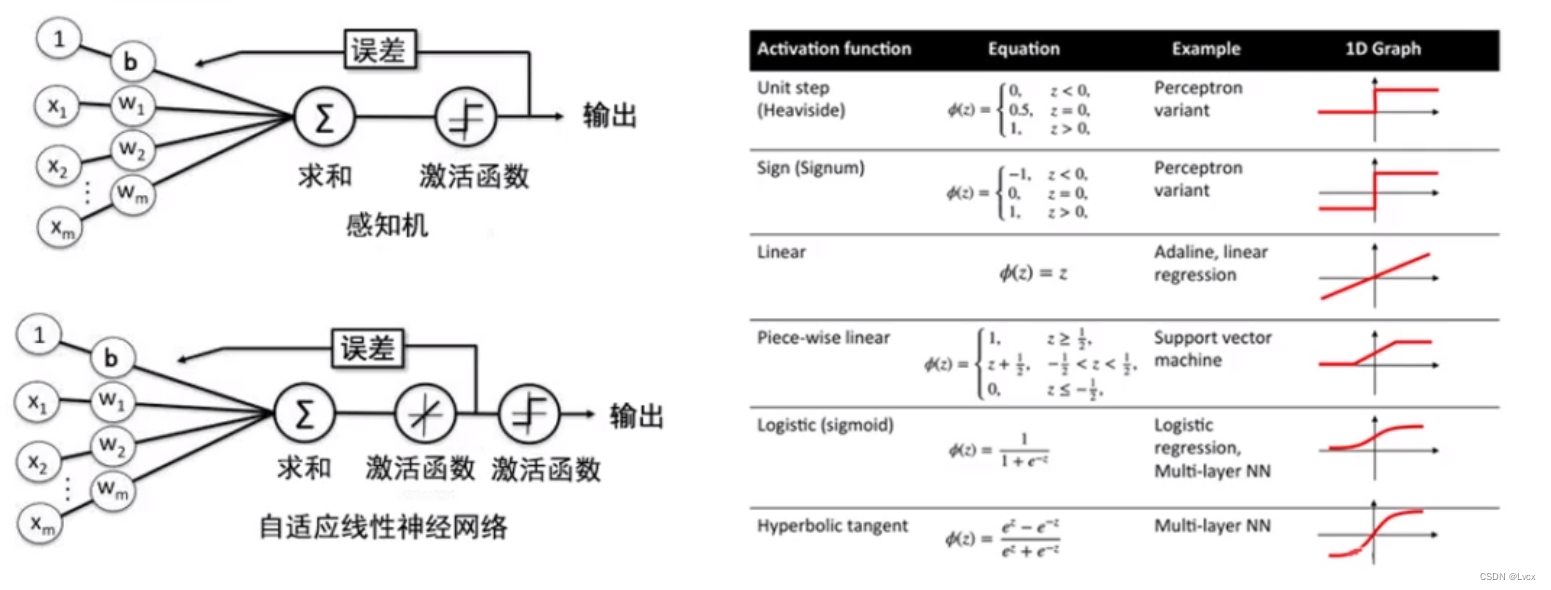
1-3 激活函数简介
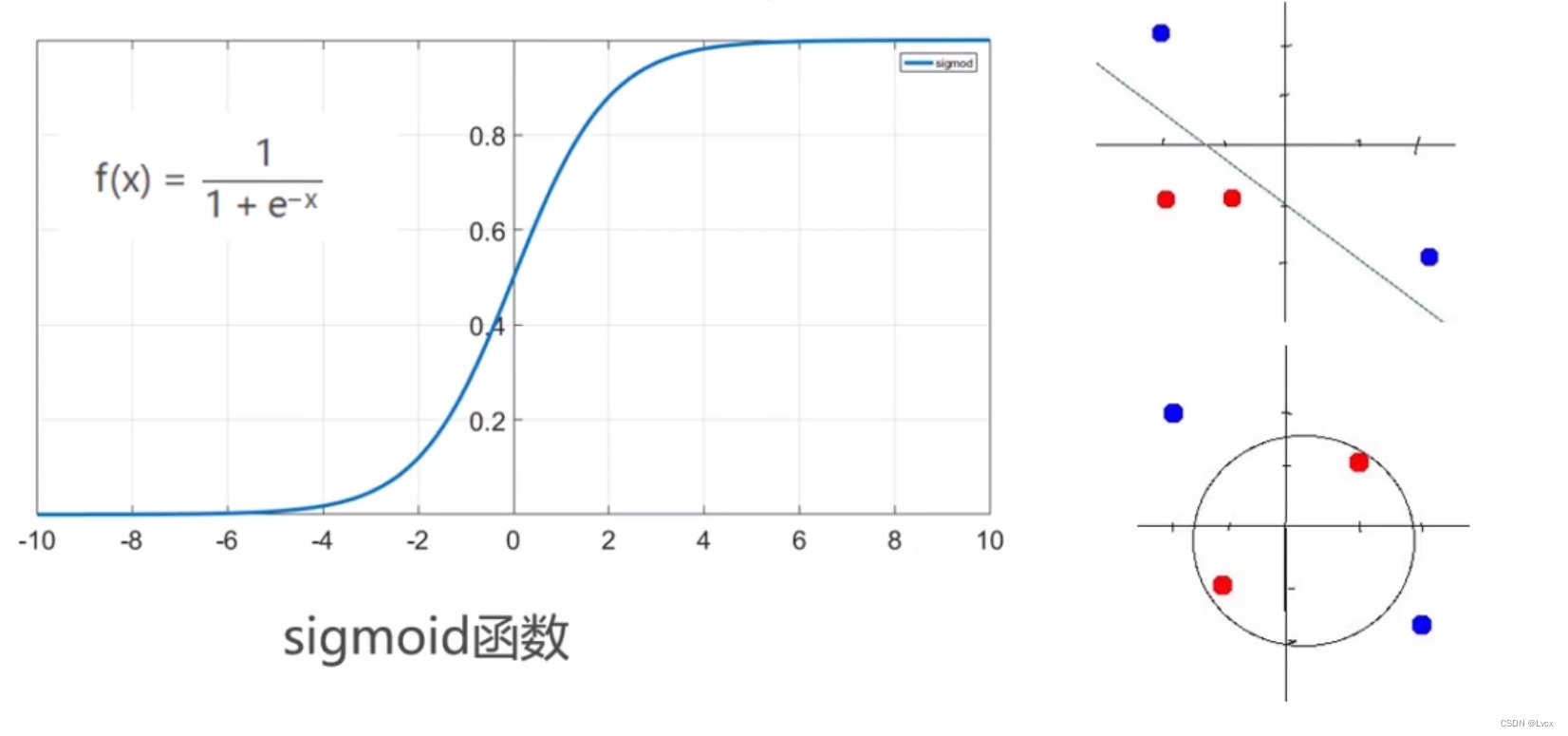
- 激活函数并不是真的要激活什么,在神经网络中,激活函数能够给神经网络加入一些非线性因素,使得神经网络能更好地解决较为复杂的问题。
- 如果没有激活函数,感知机以及感知机通过叠加形成的神经网络也没有办法产生非线性分类器。
- 在现实的复杂问题上,必须引入非线性因素来提高模型的表达能力。
- Sigmoid函数是常见的激活函数,通过它,线性网络能够组成逻辑回归或者多层神经网络。
- 通过组合人工神经网络及不同的激活函数,来组成神经网络,以解决线性及非线性问题。
1-4 深度神经网络简介
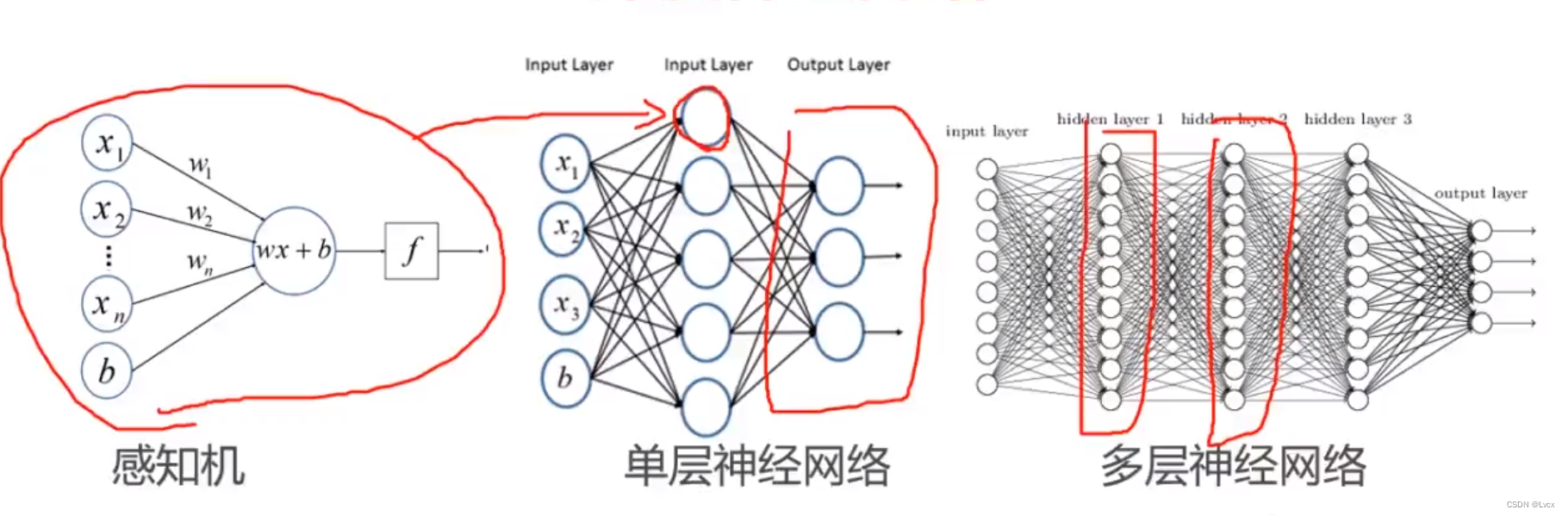
- 通过堆叠线性/非线性神经网络,来组成深层神经网络。以解决更复杂的问题。
第二章 Windows 及 Linux下的环境搭建
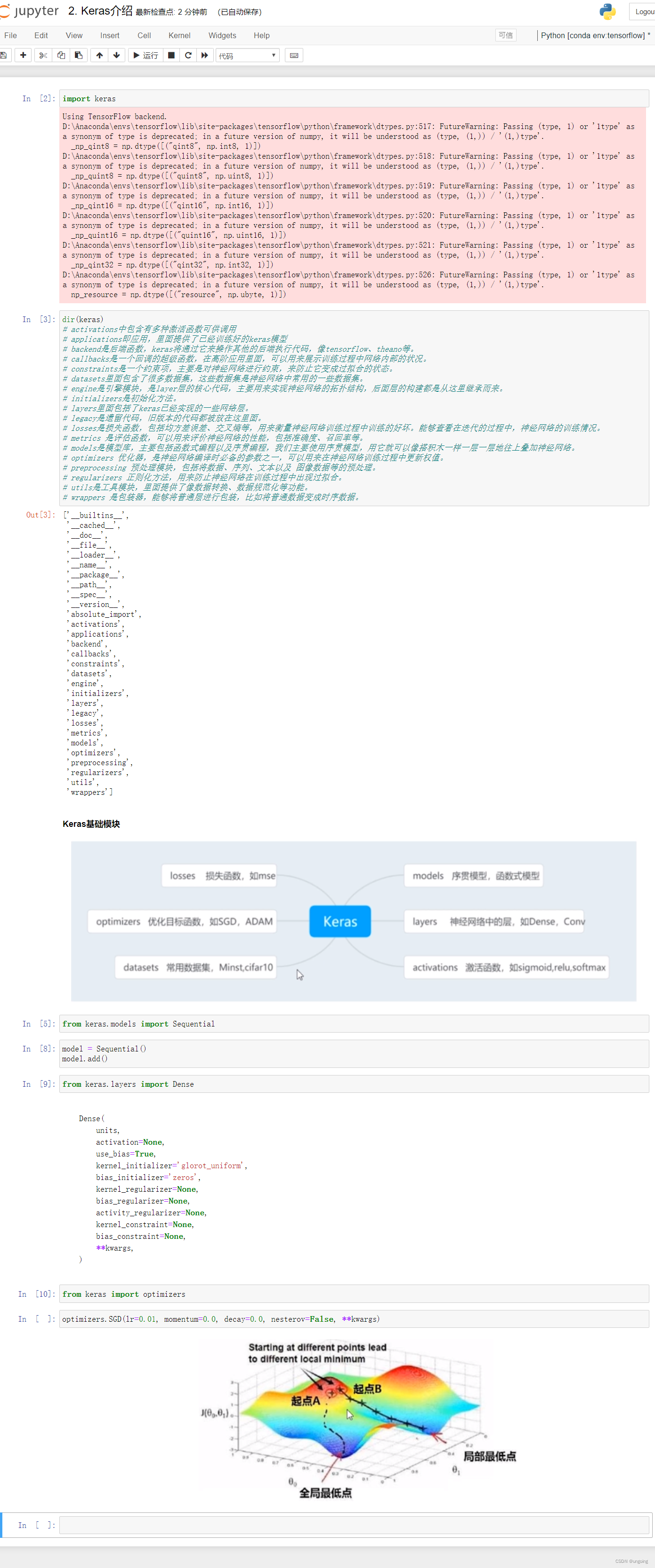
2-1 Keras基本介绍与特点
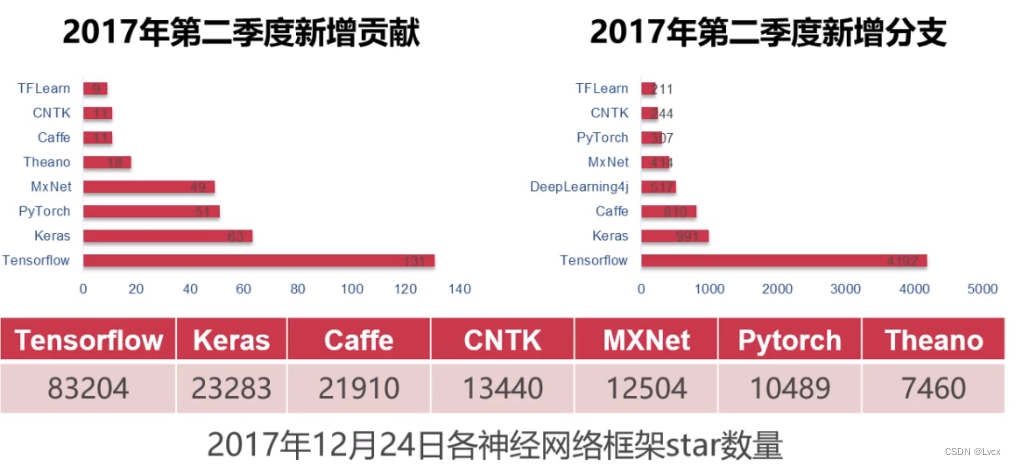
1. 高层API
- Keras由纯Python编写而成。
- 以Tensorflow、Theano、CNTK、DeepLearning4j为后端。
2. 用户友好
- Keras是为人类而不是天顶星人设计的API。
- Keras的作者在谷歌工作,Keras已经成为TensorFlow的官方API。
3. 模块性
- 网络层、损失函数、优化器、激活函数、正则化方法都封装在相应模块中,不同模块之间相互独立。
4. 默认参数
- 默认参数有研究支持。
5. 产品原型发布
可以轻松将模型转化为产品。
- iOS(苹果官方提供的Apple’s CoreML)
- Andriod(TensorFlow Android runtime)
- Python网页应用后端(Flask、Tornado、DJango)
- JVM(SkyMind提供的DL4J模型导入)
- 树莓派Raspberry Pi
2-2 Windows环境搭建
Anaconda安装
- Window,Mac OS、Linux都已支持TensorFlow。
- Windows用户只能使用python3.5+(64bit)。
- 有GPU可以安装GPU版本的,没有GPU就安装CPU版本的。
- 安装Anaconda,pip版本大于8.1。
使用的环境:python3.6 + keras 2.0 + tensorflow 1.6
视频地址:https://www.imooc.com/video/17900
Tensorflow安装
- CPU版本:conda install tensorflow
- GPU版本:conda install tensorflow-gpu

安装成功后,环境中含有的所有包:
第三章 Keras实战
3-1 jupyter介绍
- jupyter notebook 是一个在线编辑器,支持Python、R、Julia、JS、Scala、Go。
- 即Julia + Python +R。
开始深度学习前的准备工作
# ===================检查Python版本=======================
# 检查Python版本
!python --version
# ===================基础包导入检查=======================
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import sklearn
# 安装缺少的包
!pip install scipy
!pip install matplotlib
!pip install sklearn
# 检查深度学习包:
import tensorflow
import keras # FutureWarning是对版本低的警告,暂时对使用没有影响
# ===================检查版本=======================
import numpy
print("numpy:", numpy.__version__)
import scipy
print("scipy:", scipy.__version__)
import IPython
print("iPython:", IPython.__version__)
import matplotlib
print("matplotlib:", matplotlib.__version__)
import sklearn
print("sklearn:", sklearn.__version__)
import tensorflow as tf
print("tensorflow:", tf.__version__)
import keras
print("keras:", keras.__version__)
# ===================检查完毕=======================
3-2 感知机及Python简易实现
感知机
- 前向传播 反向传播 链式法则
感知机结构
- 前向传播顾名思义,就是通过输入层输入,并且一路向前,计算出输出的结果。
- 前向传播在下图中表现为xi 乘以权重wi 再加上偏置值bi ,将他们计算后求和,然后利用激活函数进行激活,这一整个过程被称为前向传播。
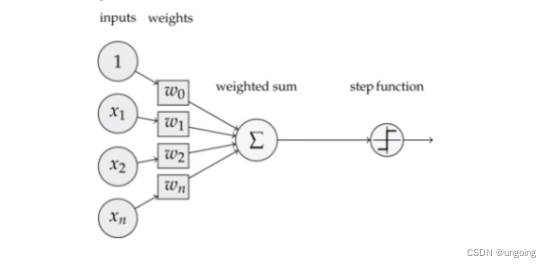
- 而反向传播顾名思义,就是通过输出来反向更新权重的过程。
超平面
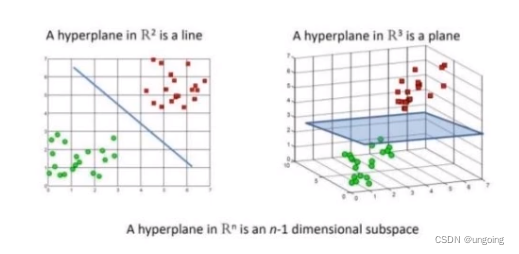
- 超平面是比n维空间小一维的空间。在二维平面中,超平面是一条线;在三维空间上,超平面是一个二维的平面。
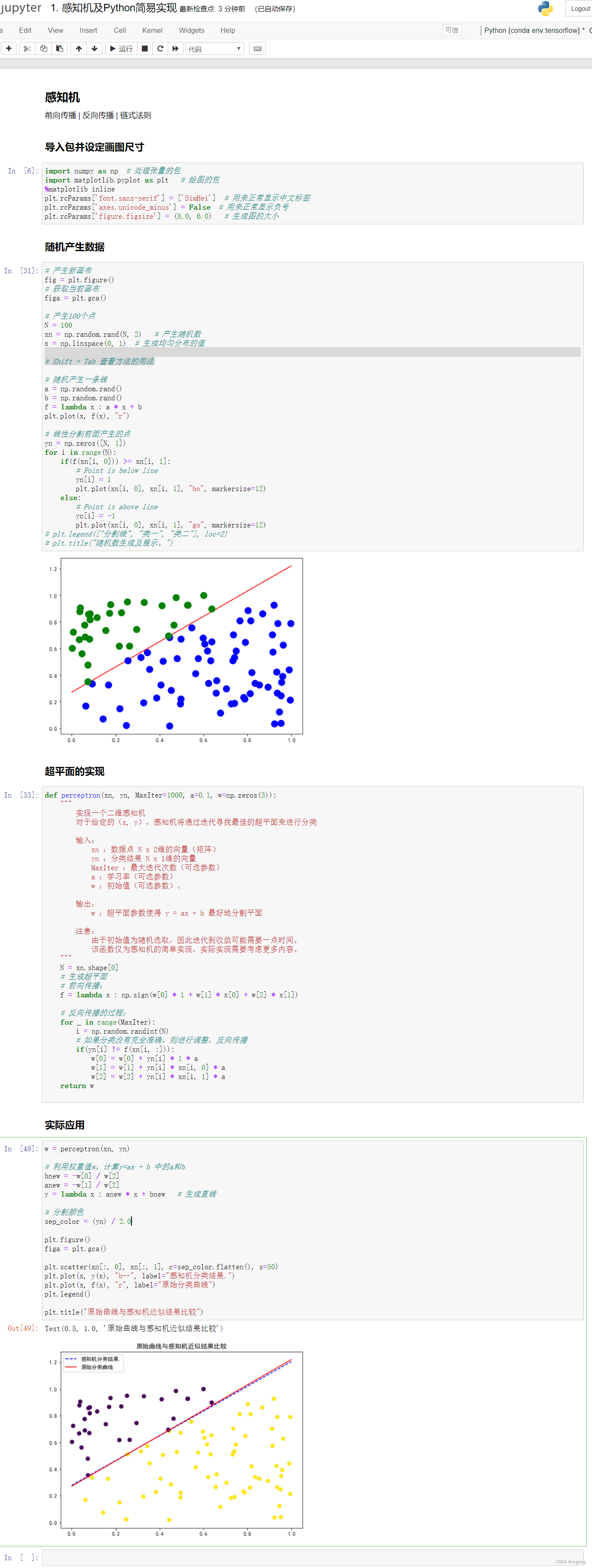
# ==================导入包并设定画图尺寸==========================
import numpy as np # 处理张量的包
import matplotlib.pyplot as plt # 绘图的包
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.figsize'] = (8.0, 6.0) # 生成图的大小
# ===================产生随机数据================================
# 产生新画布
fig = plt.figure()
# 获取当前画布
figa = plt.gca()
# 产生100个点
N = 100
xn = np.random.rand(N, 2) # 产生随机数
x = np.linspace(0, 1) # 生成均匀分布的值
# Shift + Tab 查看方法的用法
# 随机产生一条线
a = np.random.rand()
b = np.random.rand()
f = lambda x : a * x + b
plt.plot(x, f(x), "r")
# 线性分割前面产生的点
yn = np.zeros([N, 1])
for i in range(N):
if(f(xn[i, 0])) >= xn[i, 1]:
# Point is below line
yn[i] = 1
plt.plot(xn[i, 0], xn[i, 1], "bo", markersize=12)
else:
# Point is above line
yn[i] = -1
plt.plot(xn[i, 0], xn[i, 1], "go", markersize=12)
# plt.legend(["分割线", "类一", "类二"], loc=2)
# plt.title("随机数生成及展示。")
# ===================超平面的实现================================
def perceptron(xn, yn, MaxIter=1000, a=0.1, w=np.zeros(3)):
"""
实现一个二维感知机
对于给定的(x, y),感知机将通过迭代寻找最佳的超平面来进行分类
输入:
xn :数据点 N x 2维的向量(矩阵)
yn :分类结果 N x 1维的向量
MaxIter :最大迭代次数(可选参数)
a :学习率(可选参数)
w :初始值(可选参数)。
输出:
w :超平面参数使得 y = ax + b 最好地分割平面
注意:
由于初始值为随机选取,因此迭代到收敛可能需要一点时间。
该函数仅为感知机的简单实现,实际实现需要考虑更多内容。
"""
N = xn.shape[0]
# 生成超平面
# 前向传播:
f = lambda x : np.sign(w[0] * 1 + w[1] * x[0] + w[2] * x[1])
# 反向传播的过程:
for _ in range(MaxIter):
i = np.random.randint(N)
# 如果分类没有完全准确,则进行调整,反向传播
if(yn[i] != f(xn[i, :])):
w[0] = w[0] + yn[i] * 1 * a
w[1] = w[1] + yn[i] * xn[i, 0] * a
w[2] = w[2] + yn[i] * xn[i, 1] * a
return w
# ==========================实际应用=======================
w = perceptron(xn, yn)
# 利用权重值w,计算y=ax + b 中的a和b
bnew = -w[0] / w[2]
anew = -w[1] / w[2]
y = lambda x : anew * x + bnew # 生成直线
# 分割颜色
sep_color = (yn) / 2.0
plt.figure()
figa = plt.gca()
plt.scatter(xn[:, 0], xn[:, 1], c=sep_color.flatten(), s=50)
plt.plot(x, y(x), "b--", label="感知机分类结果.")
plt.plot(x, f(x), "r", label="原始分类曲线")
plt.legend()
plt.title("原始曲线与感知机近似结果比较")
3-3 Keras介绍
3-4 Minst手写体识别(分类问题)
- 手写体识别是深度学习中使用最广,也是最简单的一个数据集。可以简单认为是深度学习里的hello world。
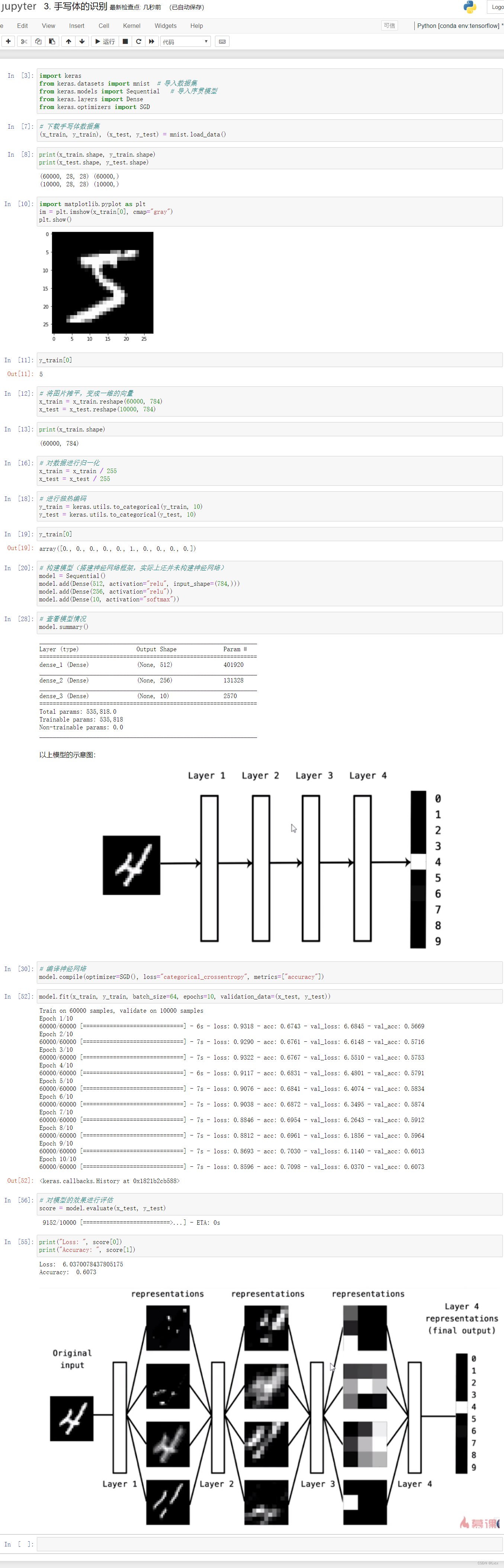
import keras
from keras.datasets import mnist # 导入数据集
from keras.models import Sequential # 导入序贯模型
from keras.layers import Dense
from keras.optimizers import SGD
# 下载手写体数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
import matplotlib.pyplot as plt
im = plt.imshow(x_train[0], cmap="gray")
plt.show()
y_train[0]
# 将图片摊平,变成一维的向量
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
print(x_train.shape)
# 对数据进行归一化
x_train = x_train / 255
x_test = x_test / 255
# 进行独热编码
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
y_train[0]
# 构建模型(搭建神经网络框架,实际上还并未构建神经网络)
model = Sequential()
model.add(Dense(512, activation="relu", input_shape=(784,)))
model.add(Dense(256, activation="relu"))
model.add(Dense(10, activation="softmax"))
# 查看模型情况
model.summary()
# 编译神经网络
model.compile(optimizer=SGD(), loss="categorical_crossentropy", metrics=["accuracy"])
# 训练模型
model.fit(x_train, y_train, batch_size=64, epochs=10, validation_data=(x_test, y_test))
# 对模型的效果进行评估
score = model.evaluate(x_test, y_test)
print("Loss: ", score[0])
print("Accuracy: ", score[1])
3-5 猫咪分类器(分类问题)

# 部分需要的代码来源:https://github.com/twfb/keras-imooc
# 导入所需要的包
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
# from datasets.dataloader import cat_data_loader
from data_loader import load_data
# !pip install scikit-image # 这是skimage所需要的安装包
from data_loader import load_data
(x_train, y_train), (x_test, y_test) = load_data()
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
# 查看一张图片
import matplotlib.pyplot as plt
index = 27
plt.imshow(x_train[index])
# 数据拉伸
# x_train_flatten = x_train.reshape(402, 64 * 64 * 3) # 已知情况下可以这样写
x_train_flatten = x_train.reshape(x_train.shape[0], -1) # (未知情况下)这里的-1就是shape中的四个数相乘除以第一个数
x_test_flatten = x_test.reshape(x_test.shape[0], -1)
print(x_train_flatten.shape)
print(x_test_flatten.shape)
# 由于数据已经是标准化了的,所以无需再标准化(值均在0-1的范围内)
x_train = x_train_flatten
x_test = x_test_flatten
# 开始搭建神经网络(本次采用五层的多层感知机)
cat_model = Sequential()
cat_model.add(Dense(256, activation="relu", input_shape=(12288,)))
cat_model.add(Dense(128, activation="relu"))
cat_model.add(Dense(64, activation="relu"))
cat_model.add(Dense(32, activation="relu"))
cat_model.add(Dense(1, activation="sigmoid"))
cat_model.summary()
# 编译模型
# binary_crossentropy是二分类交叉熵损失函数
cat_model.compile(optimizer=SGD(), loss="binary_crossentropy",matrics=["accuracy"])
cat_model.fit(x_train, y_train, epochs=20, validation_data=(x_test, y_test))
# 使用训练好的模型
from skimage.transform import resize
import numpy as np
my_image = "./4. images/mycat0.jpg"
my_label_y = [1]
# 读入图片
my_image = np.array(plt.imread(my_image))
plt.imshow(my_image)
# 预处理图片,将图片缩放到64 * 64
num_px = 64
my_image = resize(my_image, (num_px, num_px))
my_image.shape
my_image = my_image.reshape(1, -1)
print(my_image)
# 将该图片传入模型中
result = cat_model.predict(my_image)
result
# 设置 置信度
if result >= 0.5:
print("猫")
else:
print("非猫")
# data_loader.py文件
from skimage.transform import resize
import matplotlib.pyplot as plt
import numpy as np
path = "./"
def get_train_data(cat_or_dog, start, end):
x = np.zeros([1, 64, 64, 3])
y = np.zeros([1, 1])
for i in range(start, end + 1):
image = "{}images/train/{}.{}.jpg".format(path, cat_or_dog, i)
label = [1]
if cat_or_dog == "dog":
label = [0]
image = np.array(plt.imread(image))
num_px = 64
image = resize(image, (num_px, num_px))
x = np.insert(x, 0, values=image, axis=0)
y = np.insert(y, 0, values=label, axis=0)
x = np.delete(x, -1, axis = 0)
y = np.delete(y, -1, axis = 0)
return x, y
def save_data(cat_or_dog, train_num, test_num):
x__train, y_train = get_train_data(cat_or_dog, 0, train_num)
x_test, y_test = get_train_data(cat_or_dog, 10000, 10000 - 1 + test_num)
np.savez('{}{}'.format(path, cat_or_dog), x_train=x_train, x_test=x_test, y_train=y_train, y_test=y_test)
def load_cat_or_dog_data(cat_or_dog):
data = np.load('{}.npz'.format(cat_or_dog))
x_train = data['x_train']
y_train = data['y_train']
x_test = data['x_test']
y_test = data['y_test']
return (x_train, y_train), (x_test, y_test)
def load_data():
(x_train_cat, y_train_cat), (x_test_cat, y_test_cat) = load_cat_or_dog_data('cat')
(x_train_dog, y_train_dog), (x_test_dog, y_test_dog) = load_cat_or_dog_data('dog')
x_train = np.append(x_train_cat, x_train_dog, axis=0)
y_train = np.append(y_train_cat, y_train_dog, axis=0)
x_test = np.append(x_test_cat, x_test_dog, axis=0)
y_test = np.append(y_test_cat, y_test_dog, axis=0)
permutation_train = np.random.permutation(y_train.shape[0])
permutation_test = np.random.permutation(y_test.shape[0])
x_train = x_train[permutation_train, :, :]
y_train = y_train[permutation_train]
x_test = x_train[permutation_test, :, :]
y_test = y_train[permutation_test]
return (x_train, y_train), (x_test, y_test)
3-6 线性及非线性回归(回归问题)
- 回归:回归分析是统计学上的一种常见的分析方法。通俗来说,就是我们拥有几个变量,几个变量之间有一定的相关性,然后我们希望通过几个变量的值去预测其中另外一个变量的变化关系。比如说,我们用时间、城市、房屋大小来预测房价,或者是通过股票已有的一些值来预测未来几天股价的走势等。
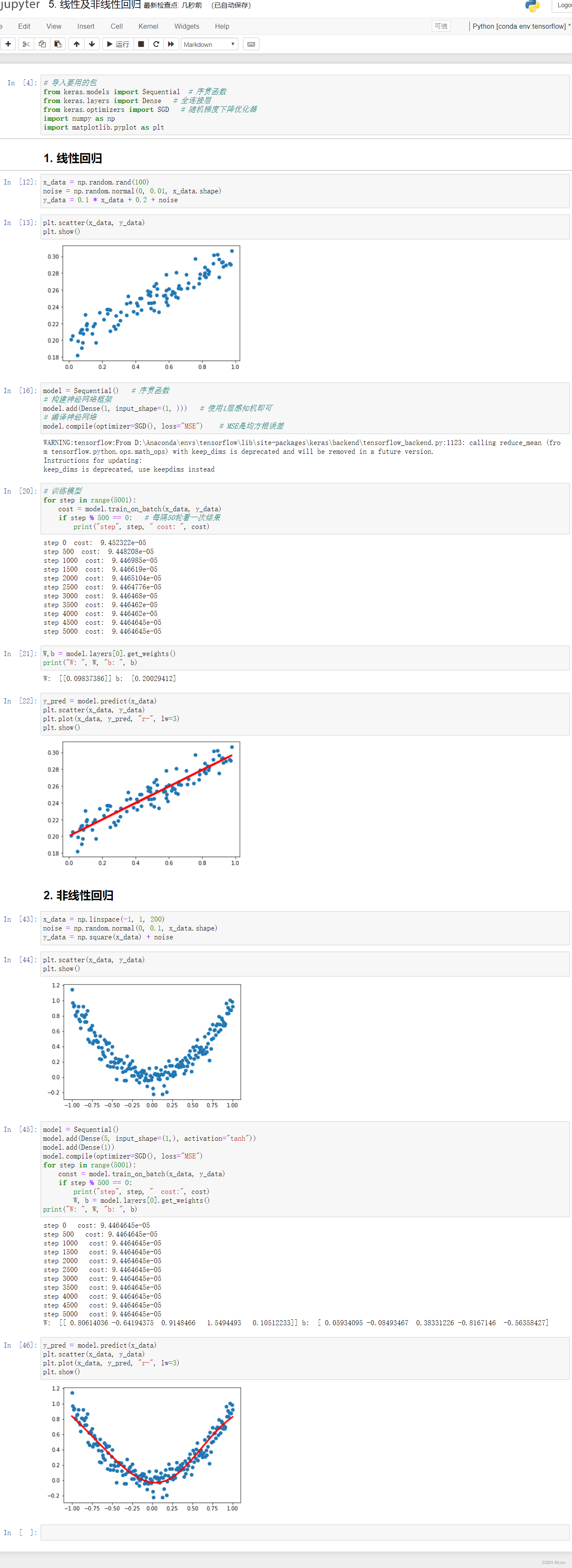
# 导入要用的包
from keras.models import Sequential # 序贯函数
from keras.layers import Dense # 全连接层
from keras.optimizers import SGD # 随机梯度下降优化器
import numpy as np
import matplotlib.pyplot as plt
# ==========================线性回归======================
x_data = np.random.rand(100)
noise = np.random.normal(0, 0.01, x_data.shape)
y_data = 0.1 * x_data + 0.2 + noise
plt.scatter(x_data, y_data)
plt.show()
model = Sequential() # 序贯函数
# 构建神经网络框架
model.add(Dense(1, input_shape=(1, ))) # 使用1层感知机即可
# 编译神经网络
model.compile(optimizer=SGD(), loss="MSE") # MSE是均方根误差
# 训练模型
for step in range(5001):
cost = model.train_on_batch(x_data, y_data)
if step % 500 == 0: # 每隔50轮看一次结果
print("step", step, " cost: ", cost)
W,b = model.layers[0].get_weights()
print("W: ", W, "b: ", b)
# 查看预测结果
y_pred = model.predict(x_data)
plt.scatter(x_data, y_data)
plt.plot(x_data, y_pred, "r-", lw=3)
plt.show()
# ======================非线性回归==================
x_data = np.linspace(-1, 1, 200)
noise = np.random.normal(0, 0.1, x_data.shape)
y_data = np.square(x_data) + noise
plt.scatter(x_data, y_data)
plt.show()
model = Sequential()
model.add(Dense(5, input_shape=(1,), activation="tanh"))
model.add(Dense(1))
model.compile(optimizer=SGD(), loss="MSE")
for step in range(5001):
const = model.train_on_batch(x_data, y_data)
if step % 500 == 0:
print("step", step, " cost:", cost)
W, b = model.layers[0].get_weights()
print("W: ", W, "b: ", b)
y_pred = model.predict(x_data)
plt.scatter(x_data, y_data)
plt.plot(x_data, y_pred, "r-", lw=3)
plt.show()
3-7 波斯顿房价预测(回归问题)
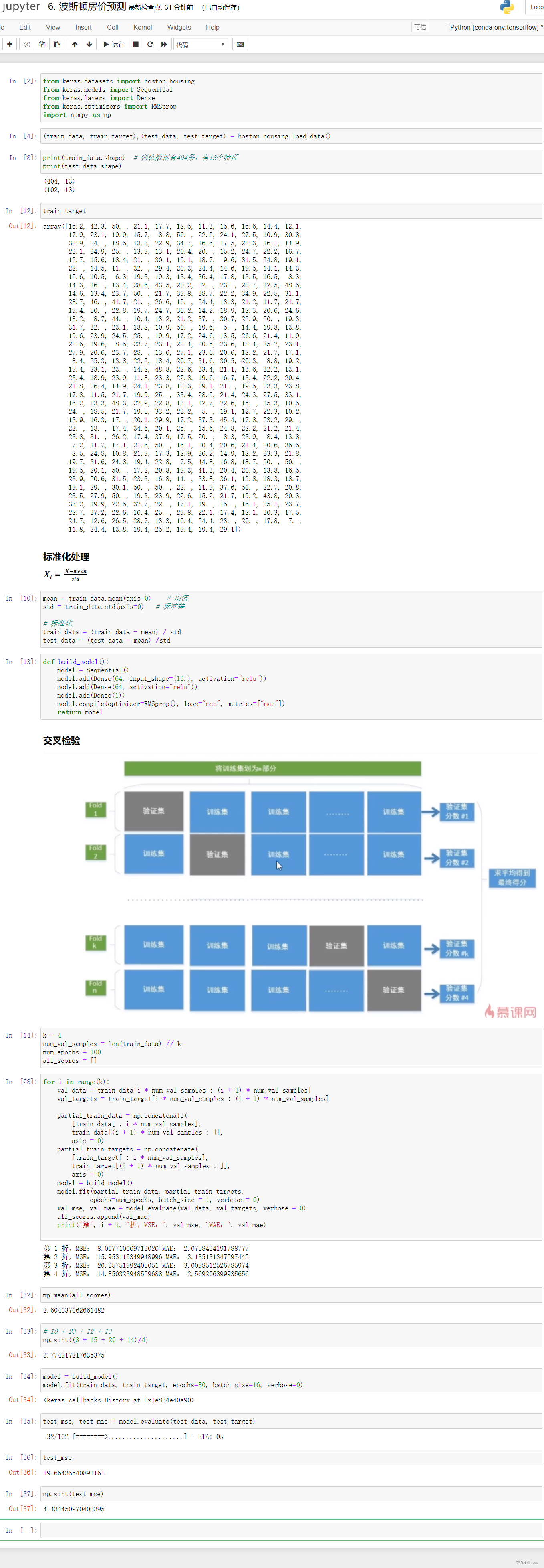
from keras.datasets import boston_housing
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import RMSprop
import numpy as np
# 下载数据集
(train_data, train_target),(test_data, test_target) = boston_housing.load_data()
print(train_data.shape) # 训练数据有404条,有13个特征
print(test_data.shape)
train_target
mean = train_data.mean(axis=0) # 均值
std = train_data.std(axis=0) # 标准差
# 标准化
train_data = (train_data - mean) / std
test_data = (test_data - mean) /std
def build_model():
model = Sequential()
model.add(Dense(64, input_shape=(13,), activation="relu"))
model.add(Dense(64, activation="relu"))
model.add(Dense(1))
model.compile(optimizer=RMSprop(), loss="mse", metrics=["mae"])
return model
k = 4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = []
for i in range(k):
val_data = train_data[i * num_val_samples : (i + 1) * num_val_samples]
val_targets = train_target[i * num_val_samples : (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
[train_data[ : i * num_val_samples],
train_data[(i + 1) * num_val_samples : ]],
axis = 0)
partial_train_targets = np.concatenate(
[train_target[ : i * num_val_samples],
train_target[(i + 1) * num_val_samples : ]],
axis = 0)
model = build_model()
model.fit(partial_train_data, partial_train_targets,
epochs=num_epochs, batch_size = 1, verbose = 0)
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose = 0)
all_scores.append(val_mae)
print("第", i + 1, "折,MSE:", val_mse, "MAE:", val_mae)
np.mean(all_scores)
# 10 + 23 + 12 + 13
np.sqrt((8 + 15 + 20 + 14)/4)
model = build_model()
model.fit(train_data, train_target, epochs=80, batch_size=16, verbose=0)
test_mse, test_mae = model.evaluate(test_data, test_target)
test_mse
np.sqrt(test_mse)
参考视频地址(慕课网):https://www.imooc.com/video/17901/0
keras中文文档:https://www.doc88.com/p-47647323891034.html