【游戏客户端与服务器面试题干货】-- 2022年度最新游戏客户端面试干货(lua篇)
文章目录
- 一、Lua的8种数据类型
- 二、pairs和ipairs的区别
- 三、lua表常用方式(插入,删除,移动,排序)
- 四、如何实现继承关系(__index)
- 五、__newindex元方法
- 六、实现一个常量表
- 七、__call元方法
- 八、__tostring元方法
- 九、lua元方法
- 十 、lua闭包
- 十一、类使用:和.的区别
- 十二、require,loadfile和dofile的区别
- 十三、Lua的热更新原理
- 十四、Lua协同程序
- 十五、Lua垃圾回收机制
- 十六、Lua和C相互调用
- 十七、Lua的一些实例测试
- 十八、lua的命名规范以及注释方法
- 十九、lua条件与循环
- 二十、lua代码优化,别再依赖if..else了
- 二十一、lua数值型for和泛型for
- 二十二、lua模式匹配
- 二十三、lua模式匹配练习
- 二十四、lua之数据结构(多维数组,链表,队列)
- 二十五、rawset & rawget方法
- 二十六、lua环境ENV
一、Lua的8种数据类型
在Lua中有8种基本类型,分别是:nil–空,boolean–布尔,number–数值,string–字符串,userdata–用户数据,function–函数,thread–线程(注意这里的线程和操作系统的线程完全不同,lua和c/c++进行交互的lua_Stack就是一种llua的线程类型),和table–表。
我们可以通过调用print(type(变量))来查看变量的数据类型。
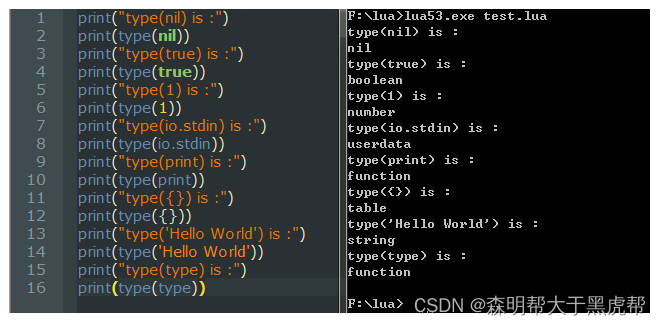
(1) nil 类型
nil是一种只有一个nil值的类型,它的主要作用是与其他所有值进行区分。Lua语言使用nil值来表示没有有用的值的情况。全局变量第一次被赋值前的默认值就是nil,将nil赋值给全局变量相当于将其删除。
(2) boolean类型
boolean类型具有两个值,true和false,他们分别代表了传统的布尔值。敲黑板:
不过在Lua中,任何值都能表示条件:Lua定义除了false和nil的值为假之外,所有的值都为真,包括0和空字符串。
提到布尔值就不得不提一下逻辑运算符:and,or,not 他们都遵循着短路求值。
举个栗子:
首先,对于and来说,如果第一个值为假,则返回第一个值,否则返回第二个值:
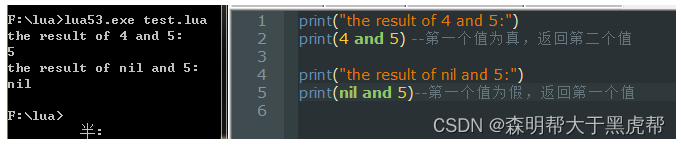
对于or来说,如果第一个值为真,则返回第一个值,否则返回第二个值:

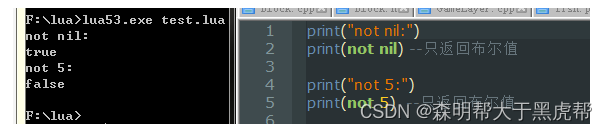
对于not来说,返回值永远为Boolean:
通过上述对逻辑运算符的理解,我们用这种写法来代替简单的if else,让代码变得更优雅
if a + b > 0 then
c = 1
else
c = 10
end
-------------- 等同于 ---------------
c = a + b > 0 and 1 or 10
(3) number类型
在Lua5.2之前所有的数值都是双精度的浮点型,在Lua5.3之后引入了整形integer。整形的引入是Lua5.3的一个重要标志。
整形与浮点型的区别:
整形:类似1,2,3,4,5…在其身后不带小数和指数。
浮点型:类似1.2,3.5555,4.57e-3…在其身后带小数点或指数符号(e)的数字。
我们使用type(3) 和type(3.5)返回的都是num。
但是如果我们调用math库里面的math.type(3)返回的是integer, math.type(3.5)返回的是float。
对于游戏开发,对num类型的使用无非是以下的状况, Lua语言还提供了除了加减乘除之外,向下取整除法(floor除法),取模和指数运算。
1.加+,减-,乘*:
int对int型进行运算,则得到的结果都是int型,但只要两个数字中有一个是float型,则得出来的结果都是float型。
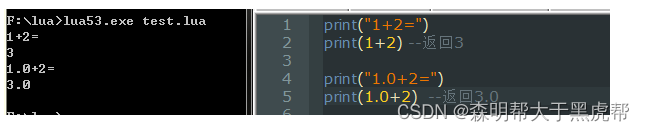
2.除/:
无论是什么数字,得到的结果永远都是float类型。
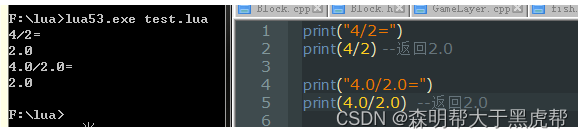
那如果我硬是想要直接一步到位,除出来的结果也要是整形怎么办?
3.双除法 // :
得到的是一个整值,若结果存在小数,则向负无穷截断。
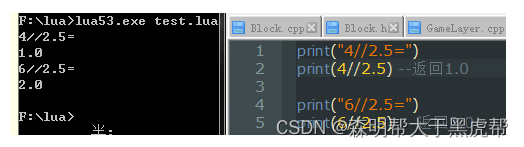
除了加减乘除之外,使用得最多的就是取整和取随机数了。
4.取整:
- floor()–向负无穷取整
- ceil() – 向正无穷取整
- modf()–向0取整
- floor(x+0.5)–四舍五入
number类型的取整,返回结果为整形值:
- (1)floor()–向负无穷取整:floor(1.5)=1
- (2)ceil() – 向正无穷取整:ceil(1.5)=2
- (3)modf()–向0取整:modf(1.5)=1.modf(-1.5)=-1
- (4)floor(x+0.5)–四舍五入
5.强制类型转换
number类型的取整以及强制转换。
- 整数类型转化成浮点型:+0.0
- 浮点类型转化成整形:math.tointeger()
6.取随机数:
产生随机数(math.random()):
- Lua中产生随机数的三种方式:
- math.random()-- 产生(0~1)的随机值
- math.random(n)-- 产生(1~n)的随机值
- math.random(m,n)-- 产生(m~n)的随机值
7.表示范围
最大值math.maxinteger和最小值math.mininteger。
lua中int型和float型都是使用8个字节来存储的,所以他们有最大值和最小值存在。
当对int最大值加整数1时,会发生回滚,如:
math.maxinteger+1=math.mininteger
math.mininteger-1=math.maxinteger
但是如果当他们加的是浮点型数字时,就不会发生回滚,而是取近似值。
math.maxinteger+1.0=math.maxinteger
math.mininteger-1.0=math.mininteger
(4) function类型
在Lua语言中,函数(Function)是对语句和表达式进行抽象的一种方式。函数调用时都需要使用一对圆括号把参数列表括起来。几时被调用的函数不需要参数,也需要一堆空括号()。唯一的例外是,当函数只有一个参数且该参数是字符串常量或表构造器{}时,括号是可选的。
print "Hello World" -- 相等于print(“Hello World”)
type {
} -- 相等于type({
})
正如我们已经在其他示例中看到的一样,Lua语言中的函数定义的常见语法格式如下,举个例子:
function add(a) -- 声明add这个函数
local sum = 0 -- 实现序列a的求和
for i=1, #a do -- 循环体
sum = sum + a[i]
end
return sum -- 返回值
end
在这种语法中,一个函数定义具有一个函数名(name,本例中的add),一个参数组成的列表和由一组语句组成的函数体。参数的行为与局部变量的行为完全一致,相当于一个用函数调用时进行初始化的局部变量。
调用函数时,使用的参数个数与定义函数时使用的参数不一致。Lua语言会通过抛弃多余的参数以及将不足的参数设为nil的方式来调整参数的个数。
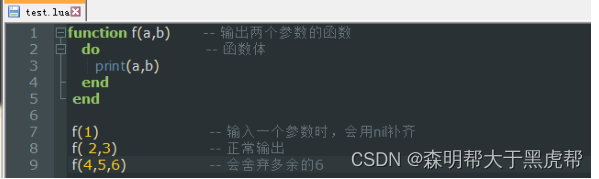
这是我们类C的写法,function 函数名 小括号 参数, 但其实我们还有另外一种写法,把函数当成一个对象去定义:
两种方式都可以声明一个函数,至于使用哪一种方式,就根据贵公司项目而定了。
lua的函数类型除了可以把它当成对象这样定义之外,还有两个特性:可变长参数,以及多返回值。
1.多返回值
- Lua语言中一种与众不同但又非常有用的特性是允许一个函数返回多个结果,只需要在return关键字后列出所有要返回的值即可。
- 例如一个用于查找序列中最大元素的函数可以同时返回最大值以及该元素的位置:

当函数作为 一条单独语句使用时,其所有值均会被抛弃。当函数被作为 表达式(例如加法操作数)调用时,将 只保留第一个返回值。
function foo ()
return "a","b"
end
x,y = foo() -- x="a",y="b"
x = foo() -- x="a"
x,y,z=foo() -- x="a",y="b",z=nil
2.可变长参数
- Lua语言中的函数可以是可变长参数函数(variadic),即可以支持数量可变的参数, 只需要在函数声明的时候参数项用…代替即可。
- 下面是一个简单的示例,该函数返回所有参数的总和:
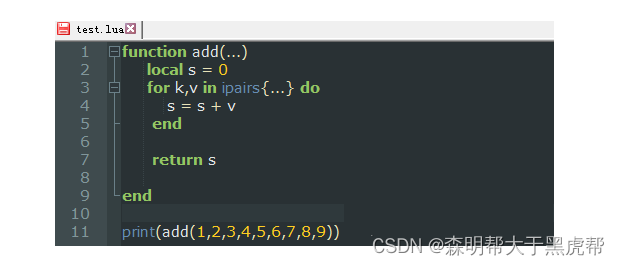
参数列表中的三个点表示该函数的参数是可变长的。当这个函数被调用时,Lua内容会把它的所有参数收集起来,三个点是作为一个表达式来使用的。在上例中,表达式{…}的结果是一个由所有可变长参数组成的列表,该函数会遍历该列表来累加。
-- 我们可以通过以下这几种方式进行对变化参数的调用
local Array{
...} -- 把它变成一个表
#{
...} -- 取得当前变化参数的个数
select{
i,...} -- 通过select方法取得第i个变化参数的值
(5) string类型
Lua中的字符串是不可变值(immutable value)。我们不可以像在C语言中那样直接改变某个字符串中的某个字符。但是我们可以创建另外一个新字符串的方式来达到修改的目的。

可以使用来获取字符串的长度。

我们也可以用连接操作符(…)来拼接两个字符串)。但是由于Lua的字符串是不可变的,所以得到的是一个新的字符串。

1.字符串常量
我们可以使用双引号或者单引号来声明字符串常量。
a = "a line"
b = ‘another line’
那么如果在字符串内容中出现双引号或者单引号怎么办呢?老司机们可能就会脱口而出:用转义字符’'啊。
没错使用转义字符确实能够解决问题,但是如果是在双引号定义的字符串中出现单引号,或者单引号字符串中出现双引号则不需要使用转义字符。
- 使用双引号声明的字符串中出现单引号时,不需要转义。
- 同理,使用单引号声明的字符串出现双引号时,不需要转义。

2.长字符串/多行字符串
为了方便缩进排版,所以Lua定义了用户可以使用一对方括号 [[]] 来声明长字符串。被方括号扩起来的内容可以由很多行,并且内容中的转义序列不会被转义。

同时,为了避免出现像这种情况:
array[b[10]] -- 出现了两个]]
我们还可以在声明长字符串时在两个中括号之间加入等量的=号,如:
array[==[
123456 -- 这样lua也会自动识别它是一个长的字符串
]==]
3.类型强制转换
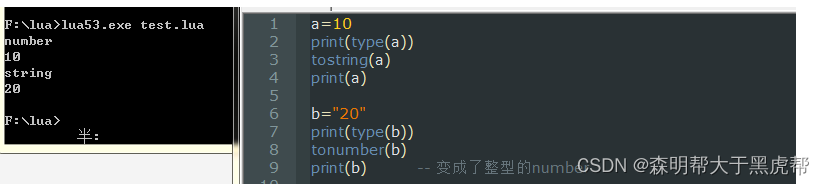
当Lua语言发现在需要字符串的地方出现数字时,它会自动把数值转换为字符串。

但是假如我们需要 1 … 2 想输出“12”的化话,那么数字和…连接符之间需要带空格,避免系统把它当成小数点。
当在算数运算中发现字符串时,它会转化为浮点型数值再进行计算,要注意在比较操作中不会默认转化。比如下图中的a和b是字符串,但是相加的时候则转化成数字:

当然我们也可以显式的把字符串和数值相互转换:tostring()-- 返回字符串/ tonumber () --返回整形或浮点型数值。
4.字符串常用操作
- (1) 字符串拼接: …(两个点)
a = “hello”
b = "world"
c = a..b -- 此时c等于hello world
- (2) 取字符串长度
c = “hello world”
print (#c) -- 此时输出11
5.字符串标准库
Lua本身对字符串的处理十分有限,仅能够创建,拼接,取长度和比较字符串。
所以Lua处理字符串的完整能力来自字符串的标准库。
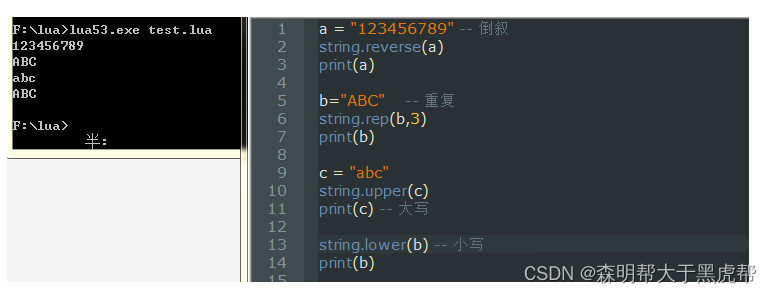
诶!怎么没有得到想要的结果呢?原来是忘记了Lua中字符串是不可变的这定义。所以我们要看到改变后的后果,可以用一个新的字符串接住它。
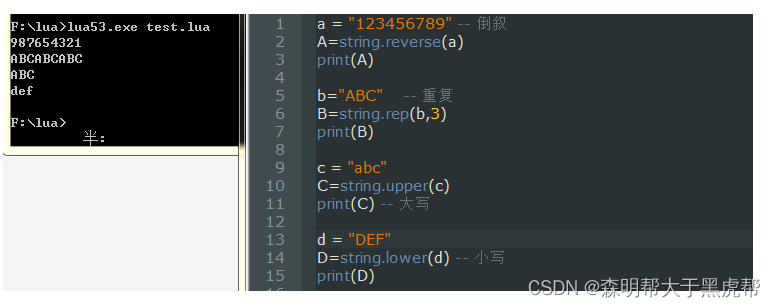
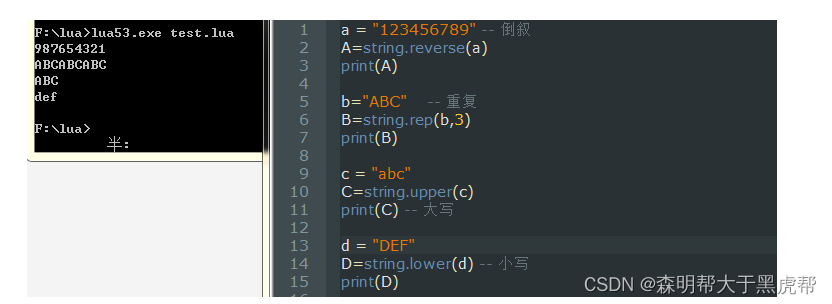
string.gsub(stringName,“字符串一”,“字符串二”)–把字符串一改成字符串二
string.sub(stringName,起始位置,终止位置) – 返回从起始位置到终止位置的字符串
string.char(num) – 把数字通过ascall译码转化为字符
string.byte(stringName) – 把字符通过ascall译码转化为数字
string.reverse(stringName) – 把字符串翻转
string.rep(stringName, 重复的次数) – 把字符串重复N遍
string.upper(stringName) – 字符串大写
string.lower(stringName) – 字符串小写
示例图:
最后要给大家介绍介绍string.format(),它适用于进行字符串格式化和将数值输出为字符串的强大工具。
有点类似C中的printf()。

(6) table类型
表是Lua语言中最强大也是唯一的数据结构。使用表,Lua语言可以以一种简单,统一且高效的方式表示数组,集合,记录和其他很多的数据结构。
Lua语言中的表本质是一种辅助数组,这种数组不仅可以通过数字下标作为索引,也可以通过使用字符串或其他任意类型的值来映射相对应的值(键值对)。
在我看来,当lua是使用连续的数字下标作为索引的时候,它就是c++中的数组,当是使用键值对方式映射,用字符串作为索引的时候,因为其无序且键值唯一,它就很像c++中的unorder_map。
我们使用构造器表达式创建表,其最简单的形式是{}
构造:
a = {
} -- 创建了一个空表
a[“x”] = 10 -- 这句话的键是“x”,值是10,此时我们可以通过a.x和a["x"]访问到10
a[10] = "Hello Table" --这句话的意思是,索引是10,值是字符串“Hello Table”
a = {
} -- 创建了一个空表
k = “x”
a[k] = 10 -- 这句话的意思是a["x"]=10,键是“x”,值是10,此时我们可以通过a.x和a["x"]访问到10
a[10] = "Hello Table" --这句话的意思是,索引是10,值是字符串“Hello Table”
表永远是匿名的,表本身和保存表的变量之间没有固定的关系。当没有变量指向表的时候,Lua会对其进行自动回收。
a = {
} -- a指向一个空表
a["x"] = 10 -- a的"x"键赋值为10
b = a -- b指向a这个表
print(b["x"]) -- 此时答案为10
b["x"] = 20
print(a["x"]) -- 此时答案为20
-- 说明a和b指向的是同一张表,并没有进行深拷贝
a=nil -- 只剩下b指向这张表
b=nil -- Lua自动回收
解释一下上面的b = a,此时a和b其实是同一张表,b只不过是a表的一个别名,这有点像c++中的引用&,大家是同一个内存地址,所以修改b的时候,a也会被修改。这是浅拷贝,若想完全复制一个互相不影响的表,我们需要使用clone()函数,比如b = a:clone()。
1.lua中深拷贝与浅拷贝
lua中我们使用 = 来进行浅拷贝,使用函数clone() 来进行深拷贝。
如果拷贝的对象里的元素只有值(string、number、boolean等基础类型 ),那浅拷贝和深拷贝没有差别,都会将原有对象复制一份,产生一个新对象。
如果是一个表 的话,则浅拷贝拷贝出来的对象和拷贝前的实际上是同一个对象,占同一个内存,而深拷贝才创建出一个新的内存,一个新的对象。
2.lua中深拷贝与浅拷贝源码
function clone(object)
local lookup_table = {
}
local function _copy(object)
if type(object) ~= "table" then
return object
elseif lookup_table[object] then
return lookup_table[object]
end
local new_table = {
}
lookup_table[object] = new_table
for key, value in pairs(object) do
new_table[_copy(key)] = _copy(value)
end
return setmetatable(new_table, getmetatable(object))
end
return _copy(object) -- 返回clone出来的object表指针/地址
end
lua中clone的源代码十分简短,但是如果第一次看的话还是比较容易看懵。
我们如果传进去的对象不是表类型的话,那么我们就会直接把这个值return出去,然后再利用=号进行一次浅拷贝,上文提过如果是数值类型的话,浅拷贝也会生成一个对象。那么如果如果传的object是一个表类型的话,则递归去把object中的key, value复制到一个新创建的表中,最后再把object的元表设置成新表的元表。这样就完成了整个深克隆的过程了。
3.表索引
同一个表中存储的值可以有不同的类型索引:既不同类型的键。未经初始化的表元素为nil。
当把表当做结构体使用时,可以把索引当做成员名称使用。
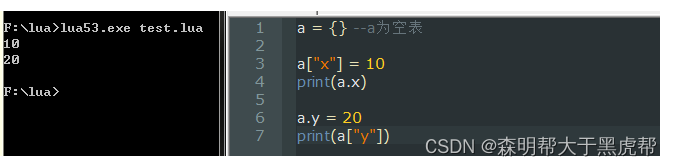
对于Lua语言而言,这两种形式是等价的。但是对于阅读程序的人而言,这两种形式分别代表了两种意图:当你用a.name来赋值时,清晰地说明了把表当做结构体使用,此时的标识由预先定义的键组成的集合。而使用a【“name”】来赋值,则说明了表可以使用任意字符串当做键。
4.表构造器
除了使用空构造器{}构造表之外我们还可以这样做:
注意:Lua中默认值是从1开始。
days = {
“Monday”,“Tuesday”,“Wednesday”,“Thursday”,“Friday”,“Saturday”,“Sunday”}
--[[ 此时days[1]到days[7]被默认定义为“Monday”~“Sunday” ]]
Lua语言还提供了一种初始化记录式表的特殊语法:
a = {
x = 10 , y = 20}
-- 上面的写法等价于 a["x"]=10,a["y"]=20
在同一个构造器中,可以混用记录式和列表式写法。
polyLine = {
color = "blue",
thickness = 2,
npoints = 4,
{
x=0,y=0}, --[[ 类似二维数组,此时polyLine[1]={
x=0,y=0}
{
x=-10,y=1}, polyLine[2]={
x=-10,y=1}
{
x=0,y=1} polyLine[3]={
x=0,y=1] ]]
}
5.数组,列表和序列
如果想表示常见的数组或者列表,那么只需要使用整形作为索引的表即可。当该表不存在空洞,既表中的所有数据都不为nil时,则成这个表为序列(sequence)。
Lua语言提供了获取序列长度的操作符#。正如我们之前所看到,对于字符串而言,该操作符会统计字符串的字节数。对于表而言,则会返回序列的大小。
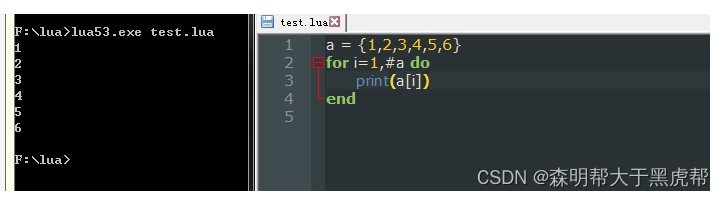
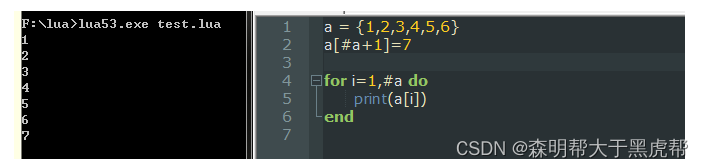
因而,当我们想在序列后增加元素时则可以使用语句 a[#a+1]=new
6.遍历表
我们可以使用pairs迭代器遍历表中的键值对。遍历过程中元素出现的顺序可能是随机的,相同的程序在每次运行时也可能产生不同的顺序。唯一可以确定的是,在遍历的过程中每个元素会且只会出现一次。
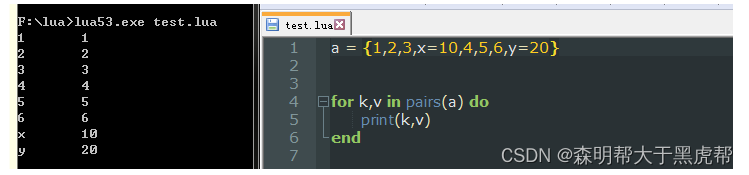
对于序列而言我们可以使用ipairs迭代器:此时Lua确保是按顺序进行的。
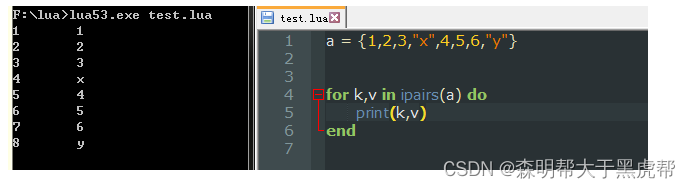
7.表标准库
表标准库提供了操作列表和序列的一些常用函数。
今天简单介绍增加(table.insert),删除(table.remove),移动(table.move)以及排序(table.sort)。
- table.insert ()
- insert()有两种格式,一种是两个参数,insert(tableName,元素),这种情况下就会默认插到末尾。
- 另一种是三个参数(tableName,位置,元素),则可以按照自己的想法插入元素。

- table.remove ()
- 删除指定位置的元素,并把后面的元素往前移动填充删除所造成的空缺。。
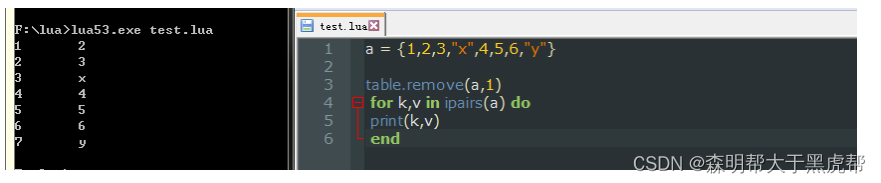
- table.move(tableA,起始索引,终止索引,tableB)
- 它的作用时把表A中从起始索引到终止索引的值移动到表B中。
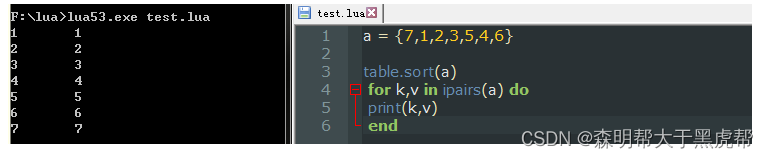
- table.sort()
- 这个就是单纯的排序方法。
(7) userdata类型
userdata是用户自定义的数据类型,lua只提供了一块原始的内存区域,用于存储任何东西, 在Lua中userdata没有任何预定义操作。
因为lua只是一个两三万行代码的一个脚本语言,有很多功能都是依靠c给它提供,所以userdata在实际中它代指了那些使用c/c++语言给lua提供的函数模块。

1.实例lua调用capi
今天是要和大家分享关于luaDebug库的一些内容,但是我在研究luaDebug库的时候,发现它调用了许多的luaAPI,对于没有研究过lua与c/c++交互的我可以说是看到满头大汉,一脸懵逼。所以我就决定从最原始入手,研究lua和c/c++是如何相互调用。今天分享的流程主要是通过举两个c++和lua相互调用的栗子,然后研究底层的实现,紧接着对我们的lua_debug库进行介绍,最后再尝试打印一些堆栈信息。
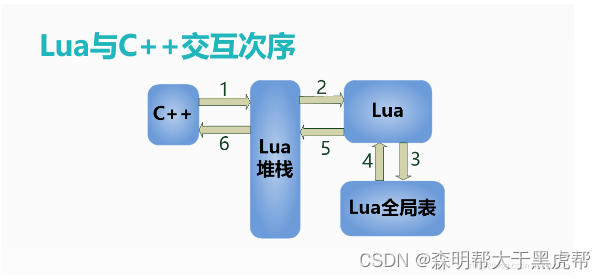
大家都知道,lua和c/c++之间是通过一个lua_Stack进行交互的,关于lua_Stack,网上对它的叫法有很多,有的说它是一个lua的堆栈,有的说它是lua状态机,也有的将它叫做lua的线程(注意这里的thread是lua的一种数据类型,与操作系统的线程需要区分开),我们可以简单的把lua_Stack当作一个翻译官,负责在c/c++与lua之间翻译,把正确的信息保存并传达给对方。
1.看两个小栗子
要让lua文件与c/c++文件进行交互有两种方式:
- 其一是把我们的CAPI给打包成一个动态链接库dll,然后在运行的时候再加载这些函数。
- 其二是把CAPI给编译到exe文件中。为了方便,以下是测试例子使用的是编译成一个exe文件的方式,准备步骤分三步:
- 新建一个c++控制台项目。
- 下载lua源码,把src目录下的所有文件拷贝到新建的c++目录下。
- include需要用到的lua库函数,生成解决方案即可。
extern "C" {
#include "lua.h"
#include "lualib.h"
#include "lauxlib.h"
}
需要注意的是,因为我们创建的是c++的程序(cocos,u3d,ue4的底层都是c++代码),但是lua的库函数中使用的是纯c的接口,所以我们要extern "C"让编译器帮我们修改一下函数的编译和连接规约。
extern关键字:
my.cpp文件
//
#include "my.h"
CMyWinApp theApp; // 声明和定义了一个全局变量
//------------------------------------------------------------------
// main
//------------------------------------------------------------------
int main()
{
CWinApp* pApp = AfxGetApp();
return 0;
}
//------------------------------------------------------------------
MFC.cpp
#include "my.h" // it should be mfc.h, but for CMyWinApp definition, so...
extern CMyWinApp theApp; // 提示编译器此变量定义在其他文件中,遇到这个变量时到其他模块中去寻找
CWinApp* AfxGetApp()
{
return theApp.m_pCurrentWinApp;
}
extern可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义。
extern C用法:
典型的,一个C++程序包含其它语言编写的部分代码。类似的,C++编写的代码片段可能被使用在其它语言编写的代码中。不同语言编写的代码互相调用是困难的,甚至是同一种编写的代码但不同的编译器编译的代码。例如,不同语言和同种语言的不同实现可能会在注册变量保持参数和参数在栈上的布局,这个方面不一样。
为了使它们遵守统一规则,可以使用extern指定一个编译和连接规约。例如,声明C和C++标准库函数strcyp(),并指定它应该根据C的编译和连接规约来链接:
extern "C" char* strcpy(char*,const char*);
extern "C"指令中的C,表示的一种编译和连接规约,而不是一种语言。C表示符合C语言的编译和连接规约的任何语言,如Fortran、assembler等。
还有要说明的是,extern "C"指令仅指定编译和连接规约,但不影响语义。例如在函数声明中,指定了extern “C”,仍然要遵守C++的类型检测、参数转换规则。
如果你有很多语言要加上extern “C”,你可以将它们放到extern “C”{ }中。
extern "C"{
typedef int (*CFT) (const void*,const void*);//style of C
void qsort(void* p,size_t n,size_t sz,CFT cmp);//style of C
}
extern "C"的真实目的是实现类C和C++的混合编程。在C++源文件中的语句前面加上extern “C”,表明它按照类C的编译和连接规约来编译和连接,而不是C++的编译的连接规约。这样在类C的代码中就可以调用C++的函数or变量等。(注:我在这里所说的类C,代表的是跟C语言的编译和连接方式一致的所有语言)
1.创建lua_Stack
前文提及lua_Stack是c/c++与lua的翻译官,所以在它们交互之前我们首先需要生成一个lua_Stack:
lua_State *L = luaL_newstate();
然后我们需要打开lua给我们提供的标准库:
luaL_openlibs(L);

其实lua早已经在我们不经意间调用了c的api。
2.第一个栗子:c++调用lua的函数
我们首先需要新建一个lua文件,名称随意我这里使用的是luafile.lua。然后我们在lua文件中定义一个function,举一个最简单的减法吧。

然后就是使用luaL_dofile方法让我们的lua_Stack编译并执行这个文件,我们在打lua引用其他文件的时候知道loadfile是只编译,dofile是编译且每次执行,require是在package.loaded中查找此模块是否存在,不存在才执行,否则返回该模块。luaL_dofile和luaL_loadfile和上述原理相似,luaL_loadfile是仅编译,luaL_dofile是编译且执行。
然后通过lua_getglobal方法可以通过lua的全局表拿到lua的全局函数,并将它压入栈底(我们可以把lua_Stack的存储结构理解为下图的样子,实际上肯定没有那么简单,我们往下看)。
lua数据栈的抽象图:
我们可以通过两种索引来获取lua_Stack的调用栈所指向的数据:
static TValue *index2addr (lua_State *L, int idx) {
CallInfo *ci = L->ci;
if (idx > 0) {
TValue *o = ci->func + idx;
api_check(L, idx <= ci->top - (ci->func + 1), "unacceptable index");
if (o >= L->top) return NONVALIDVALUE;
else return o;
}
else if (!ispseudo(idx)) {
/* negative index */
api_check(L, idx != 0 && -idx <= L->top - (ci->func + 1), "invalid index");
return L->top + idx;
}
else if (idx == LUA_REGISTRYINDEX)
return &G(L)->l_registry;
else {
/* upvalues */
idx = LUA_REGISTRYINDEX - idx;
api_check(L, idx <= MAXUPVAL + 1, "upvalue index too large");
if (ttislcf(ci->func)) /* light C function? */
return NONVALIDVALUE; /* it has no upvalues */
else {
CClosure *func = clCvalue(ci->func);
return (idx <= func->nupvalues) ? &func->upvalue[idx-1] : NONVALIDVALUE;
}
}
}

然后把两个参数按顺序压入栈中(不同类型压栈的函数接口大家可以查阅文档),然后调用pcall函数执行即可:
/* c++调用lua函数 */
luaL_dofile(L, "luafile.lua");
lua_getglobal(L, "l_sub");
lua_pushnumber(L, 1);
lua_pushnumber(L, 2);
lua_pcall(L, 2, 1, 0);
cout << lua_tostring(L, 1) << endl;
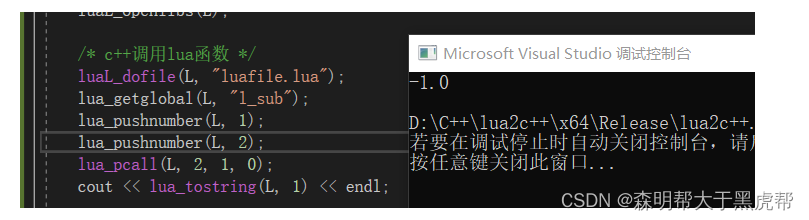
为了更方便看出栈中的数据,我写了个函数,遍历输出栈中所有的数据。
static int stackDump(lua_State *L)
{
int i = 0;
int top = lua_gettop(L); // 获取栈中元素个数。
cout << "当前栈的数量:" << top << endl;
for (i = 1; i <= top; ++i) // 遍历栈中每个元素。
{
int t = lua_type(L, i); // 获取元素的类型。
switch (t)
{
case LUA_TSTRING: // strings
cout << "参数" << i << " :" << lua_tostring(L, i);
break;
case LUA_TBOOLEAN: // bool
cout << "参数" << i << " :" << lua_toboolean(L, i) ? "true" : "false";
break;
case LUA_TNUMBER: // number
cout << "参数" << i << " :" << lua_tonumber(L, i);
break;
default: // other values
cout << "参数" << i << " :" << lua_typename(L, t);
break;
}
cout << " ";
}
cout << endl;
return 1;
}
然后我们再看看输出的结果:
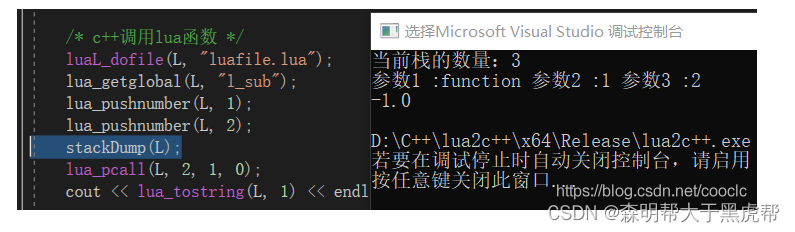
因为c++比起lua更接近底层语言,编译速度更快,所以一般来讲c++调用lua的接口只是配置一些全局数据,传递一些触摸,点击事件给lua而已。
3.第二个栗子:lua调用c++的函数
来到今天关键的部分,就是lua调用c/c++的API。上一个栗子我们有提及,我们是通过全局表拿到lua的函数,那么我们要给lua传递一个函数,同样要通过这个全局表进行注册,然后才被lua进行调用。
void lua_register (lua_State *L, const char *name, lua_CFunction f);

- 流程分三步:
- 在c/c++中定义函数
- 注册在lua全局表中
- lua文件中调用
我们举一个简单加法的栗子:
static int c_add(lua_State *L)
{
stackDump(L);
double arg1 = luaL_checknumber(L, 1);
double arg2 = luaL_checknumber(L, 2);
lua_pushnumber(L, arg1 + arg2);
return 1;
}
...
int main() {
...
lua_register(L, "c_add", c_add);
}
注意这里的返回值并不是直接return答案,答案我们需要同样压入栈中,给lua_Stack这个翻译官"翻译",return的是答案的个数(lua支持多返回值)。
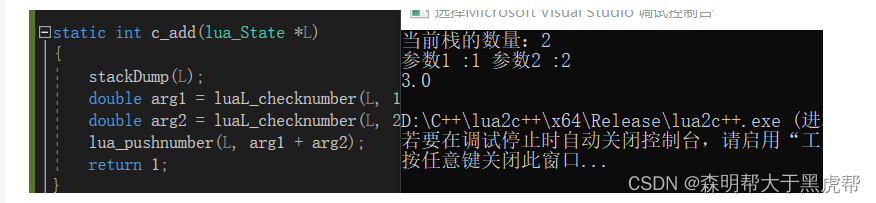
1.分析这两个栗子
我们回顾刚才的代码,一切的一切是从创建一个lua_Stack,也就是调用luaL_newstate()开始的。
LUALIB_API lua_State *luaL_newstate (void) {
lua_State *L = lua_newstate(l_alloc, NULL);
if (L) lua_atpanic(L, &panic);
return L;
}
可以看到luaL_newstate除了生成一个lua_Stack之外,还包装了一层错误预警,处理lua保护环境以外的报错,我们可以查阅以下文档lua_atpanic的作用。

我们继续往下看lua_newstate方法。
LUA_API lua_State *lua_newstate (lua_Alloc f, void *ud) {
int i;
lua_State *L;
global_State *g;
/* 分配一块lua_State结构的内容块 */
LG *l = cast(LG *, (*f)(ud, NULL, LUA_TTHREAD, sizeof(LG)));
if (l == NULL) return NULL;
L = &l->l.l;
g = &l->g;
L->next = NULL;
L->tt = LUA_TTHREAD;
g->currentwhite = bitmask(WHITE0BIT);
L->marked = luaC_white(g);
/* 初始化一个线程的栈结构数据 */
preinit_thread(L, g);
g->frealloc = f;
g->ud = ud;
g->mainthread = L;
g->seed = makeseed(L);
g->gcrunning = 0; /* no GC while building state */
g->GCestimate = 0;
g->strt.size = g->strt.nuse = 0;
g->strt.hash = NULL;
setnilvalue(&g->l_registry);
g->panic = NULL;
g->version = NULL;
g->gcstate = GCSpause;
g->gckind = KGC_NORMAL;
g->allgc = g->finobj = g->tobefnz = g->fixedgc = NULL;
g->sweepgc = NULL;
g->gray = g->grayagain = NULL;
g->weak = g->ephemeron = g->allweak = NULL;
g->twups = NULL;
g->totalbytes = sizeof(LG);
g->GCdebt = 0;
g->gcfinnum = 0;
g->gcpause = LUAI_GCPAUSE;
g->gcstepmul = LUAI_GCMUL;
for (i=0; i < LUA_NUMTAGS; i++) g->mt[i] = NULL;
if (luaD_rawrunprotected(L, f_luaopen, NULL) != LUA_OK) {
//f_luaopen函数中调用了 stack_init 函数
/* memory allocation error: free partial state */
close_state(L);
L = NULL;
}
return L;
}
- lua_newstate主要做了3件事情:
- 新建一个global_state和一个lua_State。
- 初始化默认值,创建全局表等。
- 调用f_luaopen函数,初始化栈、字符串结构、元方法、保留字、注册表等重要部件。
- 全局状态机global_state:
- global_State 里面有对主线程的引用,有注册表管理所有全局数据,有全局字符串表,有内存管理函数,有GC 需要的把所有对象串联起来的相关信息,以及一切 lua 在工作时需要的工作内存。我们以为的是c/c++ 和 lua之间只通过一个翻译官lua_Stack,但其实还有一个负责数据存放,回收的翻译公司global_State,客户只需要直接和翻译官打交道,但是一些翻译档案还是要翻译公司存放管理。
- lua线程lua_State:
- lua_State是暴露给用户的数据类型,是一个lua程序的执行状态,也是lua的一个线程thread。大致分为4个主要模块,分别是独立的数据栈StkId,数据调用栈CallInfo ,独立的调试钩子以及错误处理机制。而在调用栈中我们就可以通过func域获得所在函数的源文件名,行号等诸多调试信息。
- f_luaopen函数:
- f_luaopen函数,非常重要,主要作用:初始化栈、初始化字符串结构、初始化原方法、初始化保留字实现、初始化注册表等。
static void f_luaopen (lua_State *L, void *ud) {
global_State *g = G(L);
UNUSED(ud);
stack_init(L, L); /* init stack */
init_registry(L, g); //初始化注册表
luaS_init(L); //字符串结构初始化
luaT_init(L); //元方法初始化
luaX_init(L); //保留字实现
g->gcrunning = 1; /* allow gc */
g->version = lua_version(NULL);
luai_userstateopen(L);
可以先看看注册表是怎么样初始化的:会把当前的线程设置为注册表的第一个元素,全局表设置位第二个元素。
static void init_registry (lua_State *L, global_State *g) {
TValue temp;
/*创建注册表,初始化注册表数组部分大小为LUA_RIDX_LAST*/
Table *registry = luaH_new(L);
sethvalue(L, &g->l_registry, registry);
luaH_resize(L, registry, LUA_RIDX_LAST, 0);
/*把这个注册表的数组部分的第一个元素赋值为主线程的状态机L*/
setthvalue(L, &temp, L); /* temp = L */
luaH_setint(L, registry, LUA_RIDX_MAINTHREAD, &temp);
/*把注册表的数组部分的第二个元素赋值为全局表,即registry[LUA_RIDX_GLOBALS] = table of globals */
sethvalue(L, &temp, luaH_new(L)); /* temp = new table (global table) */
luaH_setint(L, registry, LUA_RIDX_GLOBALS, &temp);
}
在得到一个初始化后的lua_Stack之后,要想lua能拿到CAPI,我们会对c/c++的函数进行注册。
lua_register(L, "c_add", c_add);
那么我们继续往下看看究竟这个函数做了什么。
#define lua_register(L,n,f) (lua_pushcfunction(L, (f)), lua_setglobal(L, (n)))
分成两部分:首先把c/c++的函数弄成一个闭包push到lua_Stack数据栈中,判断是否溢出并对栈顶元素自增,然后就是把这个函数给注册在注册表中。
LUA_API void lua_setglobal (lua_State *L, const char *name) {
Table *reg = hvalue(&G(L)->l_registry);
lua_lock(L); /* unlock done in 'auxsetstr' */
// LUA_RIDX_GLOBALS是全局环境在注册表中的索引
auxsetstr(L, luaH_getint(reg, LUA_RIDX_GLOBALS), name);
}
我们知道lua把所有的全局表里存放在一个_G的表中,而LUA_RIDX_GLOBALS就是全局环境在注册表中的索引。至此我们就把我们的c/c++的API注册在lua的全局表中,所以lua文件中就能访问到该函数了。
(8) thread类型
再三强调,lua的线程并不是操作系统中的线程!!!它是lua和c/c++进行交互的一个数据结构lua_stack,lua通过这个数据结构和c进行交互,来调用上文中的那些库函数。
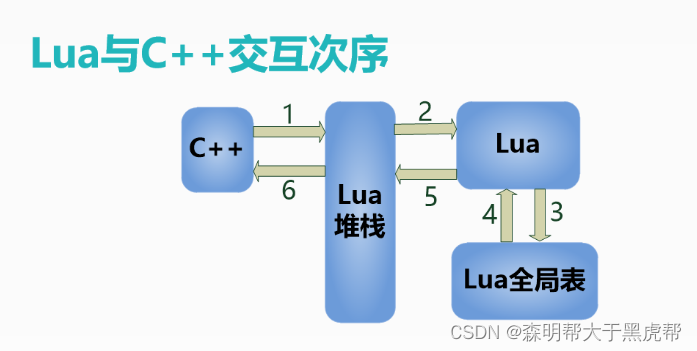
1.C/C++与lua的交互方式
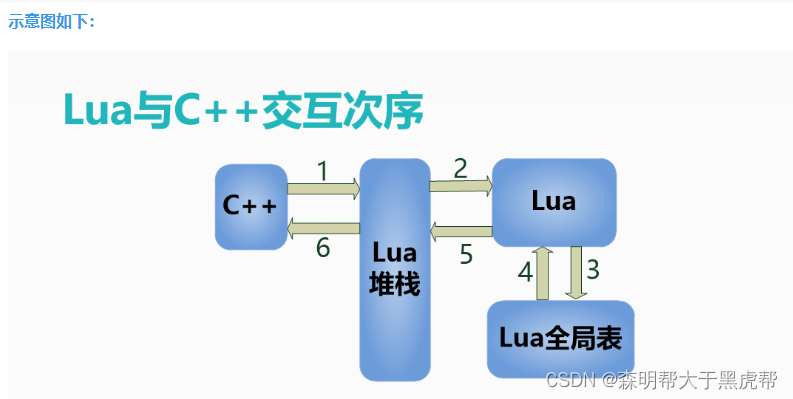
讲的是如何在lua中如何实现与C/C++的交互:
谜底直接告诉大家,它们是通过一个虚拟,强大的栈来进行交互。
这个栈是由lua实现的。C方面只是通过取栈得到想要的数据,然后再通过往这个栈中压入元素,从而实现向Lua那边更新数据。这个强大的栈长这样:

TValue结构对应于lua中的所有数据类型, 是一个{值, 类型} 结构, 这就lua中动态类型的实现, 它把值和类型绑在一起, 用tt记录value的类型, value是一个联合结构, 由Value定义, 可以看到这个联合有四个域, 先说明简单的:
- p – 可以存一个指针, 实际上是lua中的light userdata结构。
- n – 所有的数值存在这里, 不过是int , 还是float。
- b – Boolean值存在这里, 注意, lua_pushinteger不是存在这里, 而是存在n中, b只存布尔。
- gc – 其他诸如table, thread, closure, string需要内存管理垃圾回收的类型都存在这里。
- gc是一个指针, 它可以指向的类型由联合体GCObject定义, 从图中可以看出, 有string, userdata, closure, table, proto, upvalue, thread。
- 从上面的图可以的得出如下结论:
- 1. lua中, number, boolean, nil, light userdata四种类型的值是直接存在栈上元素里的, 和垃圾回收无关。
- 2. lua中, string, table, closure, userdata, thread存在栈上元素里的只是指针, 他们都会在生命周期结束后被垃圾回收。
好,当我们有了这个强大的栈之后,究竟要如何使用他呢?假设我们有一个lua的文件如下:
str = "I am so cool"
tbl = {
name = "shun", id = 20114442}
function add(a,b)
return a + b
end
现在向大家展示怎么去调用它:
#include <iostream>
#include <string.h>
using namespace std;
extern "C"
{
#include "lua.h"
#include "lauxlib.h" // externC语言与lua交互的方式
#include "lualib.h"
}
void main()
{
//1.创建Lua状态
lua_State *L = luaL_newstate(); // L是一个强大的struct,里面封装了lua的八种数据类型
if (L == NULL)
{
return ;
}
//2.加载Lua文件
int bRet = luaL_loadfile(L,"hello.lua"); // L加载了“hello。lua”这个文件
if(bRet)
{
cout<<"load file error"<<endl;
return ;
}
//3.运行Lua文件
bRet = lua_pcall(L,0,0,0); /*第一次调用是相当于 把一整个lua文件的内容 当成一个function来执行
你可以试一下 lua 设置个全局变量a为100 先把整个文件load一次
读下看看 a为多少 再pcall一次 看看a为多少就知道了
第一次调用a 得到的是nil 但是第2次调用就可以获得100了*/
if(bRet)
{
cout<<"pcall error"<<endl;
return ;
}
//4.读取变量
lua_getglobal(L,"str"); // 把str置于栈顶
string str = lua_tostring(L,-1); // 把L转化tostring为C++类的str
cout<<"str = "<<str.c_str()<<endl; //str = I am so cool~
//5.读取table
lua_getglobal(L,"tbl"); // 把tbl置在栈顶
lua_getfield(L,-1,"name"); // 访问L中第一个元素(表)的name属性置于栈顶
str = lua_tostring(L,-1);
cout<<"tbl:name = "<<str.c_str()<<endl; //tbl:name = shun
//6.读取函数
lua_getglobal(L, "add"); // 函数压入栈顶
lua_pushnumber(L, 10); // 压入第一个参数
lua_pushnumber(L, 20); // 压入第二个参数
int iRet= lua_pcall(L, 2, 1, 0);// 调用函数,调用完成以后,会将返回值压入栈中,2表示参数个数,1表示返回结果个数。
if (iRet) // 调用出错
{
const char *pErrorMsg = lua_tostring(L, -1);
cout << pErrorMsg << endl;
lua_close(L);
return ;
}
if (lua_isnumber(L, -1)) //取值输出
{
double fValue = lua_tonumber(L, -1);
cout << "Result is " << fValue << endl;
}
//至此,栈中的情况是:
//=================== 栈顶 ===================
// 索引 类型 值
// 4 int: 30
// 3 string: shun
// 2 table: tbl
// 1 string: I am so cool~
//=================== 栈底 ===================
//7.关闭state
lua_close(L);
return ;
}
2.lua_Stack究竟由什么组成
对于lua_Stack的研究同样太长,只需要记住它是c和lua之间交互的堆栈即可。
c与lua之间交互离不开lua堆栈,那么lua堆栈究竟是什么东西,由什么组成?
对于这个问题,我感觉没有比看源代码更有说服力的答案了(以下是lua5.4最新版代码)。
直接定位到lua_State定义的文件“lstate.h”中,我们发现了以下结构体还有一堆英文注释,我们现在来一个个分析着看。
struct lua_State {
CommonHeader;
unsigned short nci; /* 存储一共多少个CallInfo number of items in 'ci' list */
lu_byte status;
StkId top; /* 指向栈的顶部,压入数据,都通过移动栈顶指针来实现。 first free slot in the stack */
global_State *l_G;
CallInfo *ci; /* 当前运行函数信息 call info for current function */
const Instruction *oldpc; /* last pc traced */
StkId stack_last; /* 指向栈的底部,但是会预留空间作宝物处理 last free slot in the stack */
StkId stack; /* 指向栈的底部 stack base */
UpVal *openupval; /* list of open upvalues in this stack */
GCObject *gclist;
struct lua_State *twups; /* list of threads with open upvalues */
struct lua_longjmp *errorJmp; /* current error recover point */
CallInfo base_ci; /* 调用栈的头部指针 CallInfo for first level (C calling Lua) */
volatile lua_Hook hook;
ptrdiff_t errfunc; /* current error handling function (stack index) */
int stacksize; /* 栈的大小 */
int basehookcount;
int hookcount;
unsigned short nny; /* number of non-yieldable calls in stack */
unsigned short nCcalls; /* number of nested C calls */
l_signalT hookmask;
lu_byte allowhook;
};
1.CommonHeader – GC的通用头
#define CommonHeader GCObject *next; lu_byte tt; lu_byte marked
- CommonHeader 是使用引用计数机制进行垃圾回收的通用头。如果可以正确的遵从gc的使用规则,也就是说你可以正确无误的使用智能指针,那么理论上bai说,就不可能存在内存泄漏。
2. nci – 记录调用栈item个数的变量
- nci是16位unsigned short类型的一个变量,用于记录有多少个item在调用栈(ci)中。
- status – 表示当前这个lua_Stack线程的状态:
- 注意这里的线程类型不要与操作系统线程混淆,Lua的线程类型是Lua虚拟机实现一种数据类型,简单来说也就是代表这个lua_Stack的状态。
- 我们看看lua线程的所有状态(存放在“lua.h”文件中)。
- LUA_OK – 正常运行,LUA_YIELD – 挂起, LUA_ERRRUN – 运行时错误。
- LUA_ERRSYNTAX – 编译错误 ,LUA_ERRMEM – 内存分配错误。
- LUA_ERRGCMM – GC内存回收错误,LUA_ERRERR –在运行错误处理函数时发生的错误。
/* thread status */
#define LUA_OK 0
#define LUA_YIELD 1
#define LUA_ERRRUN 2
#define LUA_ERRSYNTAX 3
#define LUA_ERRMEM 4
#define LUA_ERRGCMM 5
#define LUA_ERRERR 6
3.l_G – 全局状态机,维护全局字符串表、内存管理函数、gc等信息
- 在5.4之前l_G并不是global_State全局状态机类型,它是一个把lua_Stack和global_State关联起来的一个结构体变量,不过很明显5.4之后lua底层直接把这个global_State暴露出来了,不过变量名还没有改(还是l_G)。
- 我们不是在讲lua_State吗?为啥又来一个global_State呢?
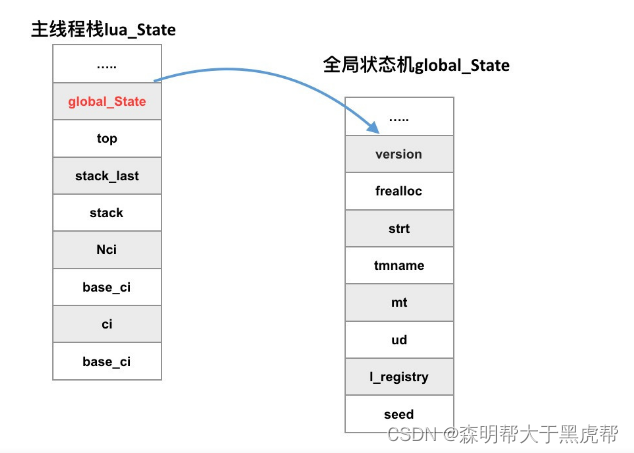
1.什么是全局状态机global_State
- global_State 里面有对主线程的引用,有注册表管理所有全局数据,有全局字符串表,有内存管理函数,有GC 需要的把所有对象串联起来的相关信息,以及一切 lua 在工作时需要的工作内存。
2.全局状态机global_State的组成
typedef struct global_State {
/* 版本号 */
const lua_Number *version; /* pointer to version number */
/* 内存管理 */
lua_Alloc frealloc; /* Lua的全局内存分配器,用户可以替换成自己的 - function to reallocate memory */
void *ud; /* 分配器的userdata - auxiliary data to 'frealloc' */
/* 线程管理 */
struct lua_State *mainthread; /* 主线程 */
struct lua_State *twups; /* 闭包了当前线程变量的其他线程列表 - list of threads with open upvalues */
/* 字符串管理 */
stringtable strt; /* 字符串table Lua的字符串分短字符串和长字符串 - hash table for strings */
TString *strcache[STRCACHE_N][STRCACHE_M]; /* 字符串缓存 - cache for strings in API */
/* 虚函数表 */
TString *tmname[TM_N]; /* 预定义方法名字数组 - array with tag-method names */
struct Table *mt[LUA_NUMTAGS]; /* 每个基本类型一个metatable(整个Lua最重要的Hook机制) - metatables for basic types */
/* 错误处理 */
lua_CFunction panic; /* to be called in unprotected errors */
TString *memerrmsg; /* memory-error message */
/* GC管理 */
unsigned int gcfinnum; /* number of finalizers to call in each GC step */
int gcpause; /* size of pause between successive GCs */
int gcstepmul; /* GC 'granularity' */
l_mem totalbytes; /* number of bytes currently allocated - GCdebt */
l_mem GCdebt; /* bytes allocated not yet compensated by the collector */
lu_mem GCmemtrav; /* memory traversed by the GC */
lu_mem GCestimate; /* an estimate of the non-garbage memory in use */
TValue l_registry;
unsigned int seed; /* randomized seed for hashes */
lu_byte currentwhite;
lu_byte gcstate; /* state of garbage collector */
lu_byte gckind; /* kind of GC running */
lu_byte gcrunning; /* true if GC is running */
GCObject *allgc; /* list of all collectable objects */
GCObject **sweepgc; /* current position of sweep in list */
GCObject *finobj; /* list of collectable objects with finalizers */
GCObject *gray; /* list of gray objects */
GCObject *grayagain; /* list of objects to be traversed atomically */
GCObject *weak; /* list of tables with weak values */
GCObject *ephemeron; /* list of ephemeron tables (weak keys) */
GCObject *allweak; /* list of all-weak tables */
GCObject *tobefnz; /* list of userdata to be GC */
GCObject *fixedgc; /* list of objects not to be collected */
} global_State;
简单来说,全局状态机由一下几部分组成:
1. version : 版本号
2. panic : 全局错误处理
3. stringtable : 全局字符串表, 字符串池化,buff 在 字符串>处理过程中的临时缓存区(编译过程中的parse也需要使用这块buff)。
4. l_registry : 注册表(管理全局数据)
5. seed : 字符串 Hash 随机化
6. Meta table :tmname (tag method name) 预定义了元方法名字数组;mt 每一个Lua 的基本数据类型都有一个元表。
7. Thread Info:mainthread 指向主线程(协程);twups 闭包了当前线程(协程)变量的其他线程列表。
8. Memory Allocator:frealloc 指向 Lua的全局内存分配器;ud 指向内存分配器的data。
9. GC 相关信息
3.全局状态机global_State初始化过程
通过 lua_newstate 创建一个新的 lua 虚拟机时,第一块申请的内存将用来保存主线程和这个全局状态机,并初始化了global_State 中需要引用的数据。
g->mainthread = L; 同时将G 中的 L 指针指向刚分配的内存的lua_Stack ,到这里 L 与 G 互相持有
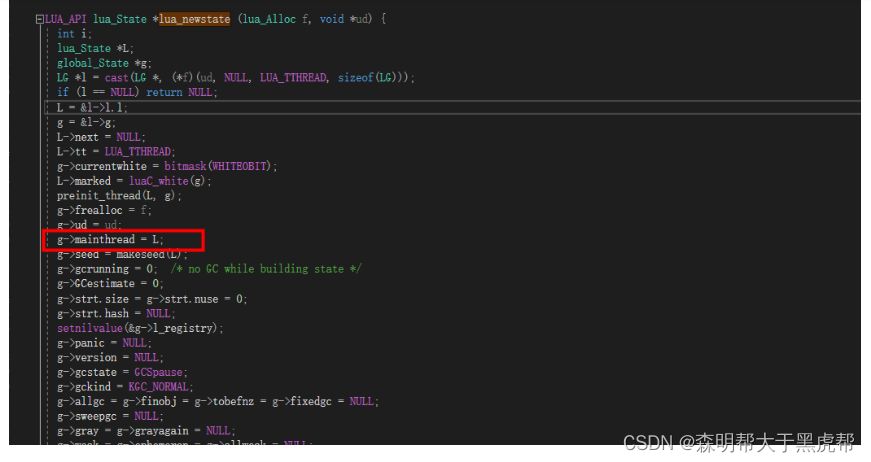
- 简而言之lua_state是是暴露给用户的数据类型(线程)用户通过它来调用C_API,global_State维护全局字符串表、内存管理函数、gc等信息。
两者大体上的区别如下:
执行状态机 – lua_state(暴露给用户调用)
lua_state 是暴露给用户的数据类型,既表示一个 lua 程序的执行状态,也指代 lua 的一个线程(在官方文档中)。
每个线程拥有独立的数据栈以及函数调用栈,还有独立的调试钩子和错误处理设置。
lua_state是一个lua 线程的执行状态。所有的lua C API 都是围绕这个状态机。
lua_State是围绕程序如何执行来设计的,数据栈和调用栈都在其中。
全局状态机 – 同一虚拟机中的所有执行线程(实际的虚拟机,一个全局状态机的数据多个lua_Stack共享)
global_state 里面有对主线程的引用,有注册表管理所有全局数据,有全局字符串表,有内存管理函数,有GC 需要的把所有对象串联起来的相关信息,以及一切 lua 在工作时需要的工作内存。
通过 lua_newstate 创建一个新的 lua 虚拟机时,第一块申请的内存将用来保存主线程和这个全局状态机。
结构示意图:

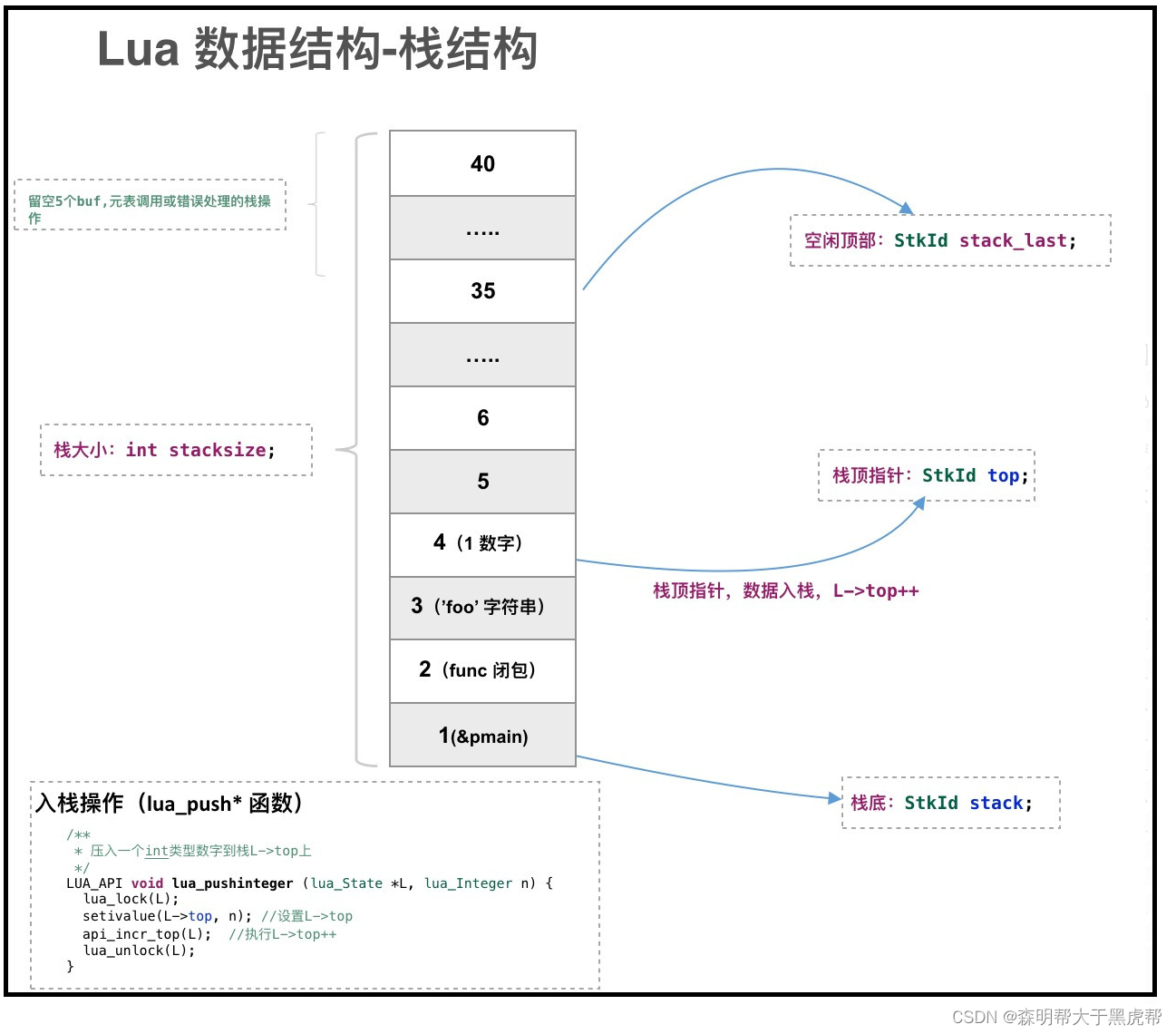
4.StkId – 数据栈:
StkId top; /* first free slot in the stack */
StkId stack_last; /* last free slot in the stack */
StkId stack; /* stack base */
前面提及在ua和C/C++是通过这个lua_State进行交互的,而lua_State就是利用StkId这个数据栈对数据进行暂存的。
下面我们看看这个StkId的代码定义:

我们可以看出,StkId其实是TValue的数组,那么TValue又是什么结构呢?
typedef union Value {
GCObject *gc; /* collectable objects */
void *p; /* light userdata */
int b; /* booleans */
lua_CFunction f; /* light C functions */
lua_Integer i; /* integer numbers */
lua_Number n; /* float numbers */
} Value;
#define TValuefields Value value_; int tt_
typedef struct lua_TValue {
TValuefields;
} TValue;
通过上述代码关系我们可以看出,实际存储数据的数据结构是Value,而TValue是为了区分联合中存放的数据类型(使用tt字段),再额外绑定一个类型字段。
lua 中的数据可以这样分为两类:值类型和引用类型。值类型可以被任意复制,而引用类型共享一份数据。
Value存放了gc和几个属性值,属性值分别对应了lua的值类型数据,而gc则管理lua中的引用数据的生命周期。

从上面的图可以的得出如下结论:
- lua中, number, boolean, nil, light userdata四种类型的值是直接存在栈上元素里的, 和垃圾回收无关.
- lua中, string, table, closure, userdata, thread存在栈上元素里的只是指针, 他们都会在生命周期结束后被垃圾回收.
- lua_state 的数据栈,就是一个 TValue 的数组。代码中用 StkId 类型来指代对 TValue 的引用。
5. CallInfo – 调用栈
CallInfo base_ci; /* CallInfo for first level (C calling Lua) */
CallInfo *ci; /* call info for current function */
- 主要由一个CallInfo的结构组成。 CallInfo是一个双向链表结构。通过双向链表结构来管理每一个Lua的函数调用栈信息。
- Lua一共有三种类型的函数:C语言闭包函数(例如pmain)、Lua的C函数库(例如str字符串函数)和LUA语言。
- 每一个函数的调用,都会新生产一个CallInfo的调用栈结构,用于管理函数调用的栈指针信息。当一个函数调用结束后,会返回CallInfo链表的前一个调用栈,直到所有的调用栈结束回到L->base_ci。
- 调用栈最终都会指向数据栈上,通过一个个调用栈,用于管理不同的函数调用。
typedef struct CallInfo {
StkId func; /* ci->func:指向正在调用操作的栈底位置。 function index in the stack */
StkId top; /* 指向调用栈的栈顶部分 top for this function */
struct CallInfo *previous, *next; /* previous和next是双向链表指针,用于连接各个调用栈。当执行完一个函数,通过previous回滚到上一个调用栈
CI dynamic call link */
union {
struct {
/* only for Lua functions */
StkId base; /* base for this function */
const Instruction *savedpc;
} l;
struct {
/* only for C functions */
lua_KFunction k; /* continuation in case of yields */
ptrdiff_t old_errfunc;
lua_KContext ctx; /* context info. in case of yields */
} c;
} u;
ptrdiff_t extra;
short nresults; /* expected number of results from this function */
unsigned short callstatus;
} CallInfo;
这里可以举一个栗子,就是函数A调用函数B,函数b也调用函数C,那么此时base_ci的next就是函数A的callinfo,ci就是函数c的callinfo。
实际上,遍历 L 中的 base_ci域指向的 CallInfo双向链表可以获得完整的 lua 调用栈。而每一级的 CallInfo 中,都可以进一步的通过 func 域取得所在函数的更详细信息。
当 func 为一个 lua 函数时,根据它的函数原型可以获得源文件名、行号等诸多调试信息。
6. HOOK 相关-- 服务于debug模块
int basehookcount;
int hookcount;
volatile lua_Hook hook;
l_signalT hookmask;
lu_byte allowhook;
- volatile lua_Hook hook 存放了debug调用的钩子函数
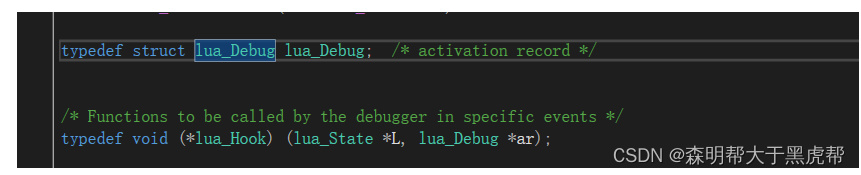
struct lua_Debug {
int event;
const char *name; /* (n) */
const char *namewhat; /* (n) 'global', 'local', 'field', 'method' */
const char *what; /* (S) 'Lua', 'C', 'main', 'tail' */
const char *source; /* (S) */
int currentline; /* (l) */
int linedefined; /* (S) */
int lastlinedefined; /* (S) */
unsigned char nups; /* (u) number of upvalues */
unsigned char nparams;/* (u) number of parameters */
char isvararg; /* (u) */
char istailcall; /* (t) */
char short_src[LUA_IDSIZE]; /* (S) */
/* private part */
struct CallInfo *i_ci; /* active function */
};
1.首先什么是debug库
Lua 本身并未有内置的调试器,但是它提供了 debug 库用于提供创建我们自定义调试器的功能,debug库并不给你一个可用的Lua 调试器,而是给你提供一些为Lua写一个调试器的方便。 简而言之,debug库给我们开发者提供了构建调试器的工具。
2.自省(introspective)函数
debug库由两种函数组成:自省(introspective)函数和hooks。
- 自省函数使得我们可以检查运行程序的某些方面,比如活动函数栈、当前执行代码的行号、本地变量的名和值。
- Hooks钩子可以跟踪程序的执行情况。
3.introspective自省debug.getinfo函数
调试库中主要的自省函数是debug.getinfo和debug.getlocal函数。它的第一个参数可以是一个函数或者一个栈层。当为某函数foo调用debug.getinfo(foo)时,就会得到一个table,其中包含了一些与该函数相关的信息。这个table中的字段有以下几种:
- source,标明函数被定义的地方。如果函数在一个字符串内被定义(通过 loadstring),source 就是那个字符串。如果函数在一个文件中定义,source 是@加上文件名
- short_src,source 的简短版本(最多 60 个字符),记录一些有用的错误信息。
- linedefined,source中函数被定义之处的行号。
- lastlinedefined:该函数定义的源代码中最后一行的行号
- what:函数的类型。如果foo是一个普通的Lua函数,则为“Lua”;如果是一个C函数,则为“C”;如果是一个Lua程序块(chunk)的主程序部分,则为main
- name:该函数的一个适当的名称
- namewhat:上一个字段的含义。它可能是global、local、method、field或空字符串。空字符串表示Lua没有找到该函数的名称
- nups:该函数的upvalue的数量
- avtivelines:一个table,包含了该函数的所有活动行的集合。所谓活动行就是含有代码的行,这是相对于空行和注释行而言的
- func:函数本身
当foo是一个C函数的时候,Lua无法知道很多相关的信息,所以对这种函数,只有what、name、namewhat这几个域的值可用。
3.1.栈级别(stack level)

- Debug库中的一个重要的思想是栈级别(stack level)。
- 一个栈级别就是一个指向当前时刻正在活动的特殊函数的数字在,也就是说,这个函数正在被调用但还没有返回。调用debug库的函数级别为 1,调用他(他指调用debug库的函数)的函数级别为2,以此类推。以数字 n调用debug.getinfo(n)时,返回在n级栈的活动函数的信息数据。
- 比如,如果n=1,返回的是正在进行调用的那个函数的信息。(n=0表示 C函数getinfo本身)如果n比栈中活动函数的个数大的话,debug.getinfo返回nil。当你使用数字n调用debug.getinfo查 询活动函数的信息的时候,返回的结果table中有一个额外的域:currentline,即在那个时刻函数所在的行号。另外,func表示指定n级的活动函数。
3.2.提高调用getInfo的效率
函数getinfo 的效率并不高。Lua以不消弱程序执行的方式保存debug信息(Lua keeps debug information in a form that does not impair program execution),效率被放在第二位。为了获取比较好地执行性能,getinfo可选的第二个参数可以用来指定选取哪些信息。指定了这个参数之后,程序不会浪费时间去收集那些用户不关心的信息。这个参数的格式是一个字符串,每一个字母代表一种类型的信息,可用的字母的含义如下:
‘n’: 得到name和namewhat字段 (selects fields name and namewhat)
‘f’ : 输出函数本身(selects field func)
‘s’ : 输出标明函数被定义的地方,函数所在的行号(selects fields source, short_src, what, and linedefined)
‘l’ : 输出在那个时刻函数所在的行号(selects field currentline)
‘u’ :输出该函数的upvalue的数量 (selects field nup)
function traceback ()
local level = 1
while true do
local info = debug.getinfo(level, "Sl")
if not info then break end
if info.what == "C" then -- is a C function?
print(level, "C function")
else -- a Lua function
print(string.format("[%s]:%d",info.short_src, info.currentline))
end
level = level + 1
end
end
不难改进这个函数,使得getinfo获取更多的数据,实际上debug库提供了一个改善的版本debug.traceback,与我们上面的函数不同的是,debug.traceback并不打印结果,而是返回一个字符串。
4.introspective自省debug.getlocal函数

调用debug库的getlocal函数可以访问任何活动状态的局部变量。这个函数由两个参数:将要查询的函数的栈级别和变量的索引。函数有两个返回值: 变量名和变量当前值。如果指定的变量的索引大于活动变量个数,getlocal返回nil。如果指定的栈级别无效,函数会抛出错误。(你可以使用 debug.getinfo检查栈级别的有效性),Lua对函数中所出现的所有局部变量依次计数,只有在当前函数的范围内是有效的局部变量才会被计数。
5.Hooks钩子
debug库的hook是这样一种机制:注册一个函数,用来在程序运行中某一事件到达时被调用。有四种可以触发一个hook的事件:
- 当Lua调用一个函数的时候call事件发生;
- 每次函数返回的时候return事件发生;
- Lua开始执行函数的新行时候line事件发生;
- 运行指定数目的指令之 后,count事件发生。
Lua使用单个参数调用hooks,参数为一个描述产生调用的事件:“call”、“return”、“line” 或 “count”。另外,对于line事件,还可以传递第二个参数:新行号。我们在一个hook内总是可以使用debug.getinfo获取更多的信息。
使用带有两个或者三个参数的debug.sethook 函数来注册一个hook:
- 第一个参数是hook函数;
- 第二个参数是一个描述我们打算监控的事件的字符串;
- 可选的第三个参数是一个数字,描述我们打算获取 count事件的频率。为了监控call、return和line事件,可以将他们的第一个字母(‘c’、‘r’ 或 ‘l’)组合成一个mask字符串即可。要想关掉hooks,只需要不带参数地调用sethook即可。
例如:最简单的trace,仅仅打印每条执行语句的行号:
debug.sethook(print, "l")
显示结果如下:
line 136
line 113
line 76
line 77
line 113
line 118
我们也可以自定义一个handler,传入第一个参数,通过debug库的getinfo获取正在执行的代码文件路径:
显示结果如下:
/usr/local/share/xmake/core/base/path.lua:46
/usr/local/share/xmake/core/base/path.lua:47
/usr/local/share/xmake/core/base/path.lua:56
/usr/local/share/xmake/core/base/string.lua:32
/usr/local/share/xmake/core/base/string.lua:33
/usr/local/share/xmake/core/base/string.lua:34
/usr/local/share/xmake/core/base/string.lua:35
/usr/local/share/xmake/core/base/string.lua:36
/usr/local/share/xmake/core/base/string.lua:38
/usr/local/share/xmake/core/base/string.lua:33
如果需要禁用之前的hook,只需要调用:
debug.sethook()
7.GC 垃圾回收
- GCObject *gclist。
二、pairs和ipairs的区别
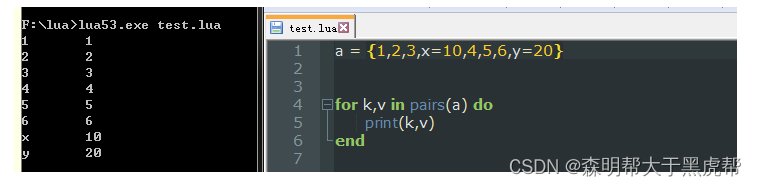
在项目的研发中,我们经常需要遍历表中的所有元素,此时我们就可以通过pairs和ipairs进行遍历
pairs迭代映射+数组,能返回表中所有的键值对但是无序,上文中说lua中存放键值对的表像c++中的无需图unorder_map也是基于这个原因,因为普通的map是用红黑树做底层,使用迭代器输出所有的键值都是有序的。
Ipairs迭代的是数组,遇到空值会停止,但是输出的是有序的。
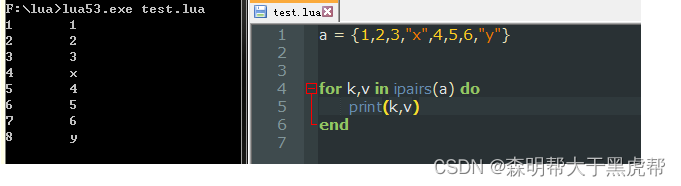
对于上述序列例子我们可以用for循环方式来代替。
for i = 1, #a do
print(a[i])
end
顺便说一下上面的for循环例子,i = 1, i < #a其实它是隐藏了一个参数,默认i = i + 1,如果我们不想加1,想要加2怎么办?那么只需要加上这个参数即可
三、lua表常用方式(插入,删除,移动,排序)
表标准库提供了操作列表和序列的一些常用函数。
今天简单介绍增加(table.insert),删除(table.remove),移动(table.move)以及排序(table.sort)。
- table.insert ()
- insert()有两种格式,一种是两个参数,insert(tableName,元素),这种情况下就会默认插到末尾。
- 另一种是三个参数(tableName,位置,元素),则可以按照自己的想法插入元素。
- table.remove ()
- 删除指定位置的元素,并把后面的元素往前移动填充删除所造成的空缺。。
- table.move(tableA,起始索引,终止索引,tableB)
- 它的作用时把表A中从起始索引到终止索引的值移动到表B中。
- table.sort()
- 这个就是单纯的排序方法。
如果我们仅仅想把它们的值给排序一遍,则只需要table.sort(表名)即可。
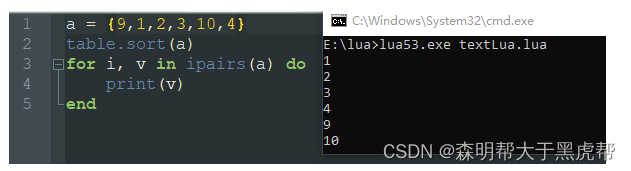
但是假如我们的值不是单纯的数字,而是一个表。也就是说我们的数组是存放了一个个表,我们想要根据表中的某一个元素作为标准进行排序,我们可以再sort参数中放入一个函数。比如下图中,我想对cnt字段大的排在前面
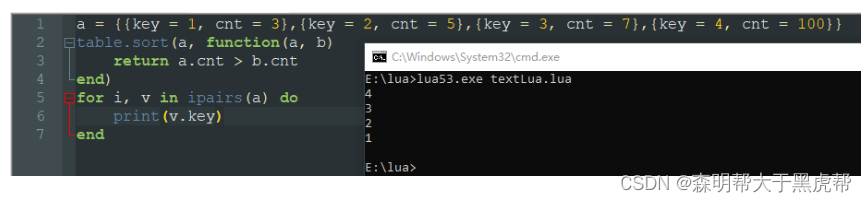
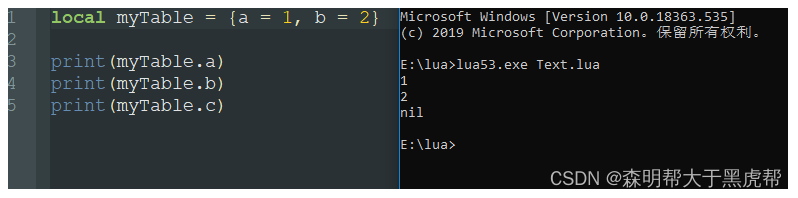
四、如何实现继承关系(__index)
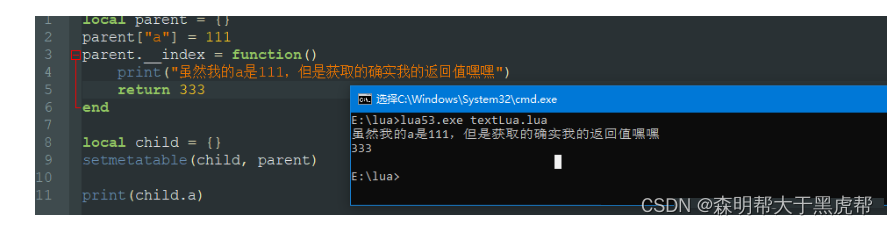
从c++,java这些高级语言走过来的我们,肯定对类的继承十分熟悉,甚至没了它还十分不习惯。其实lua也是可以实现继承的,这要利用到它的元方法_index:
local parent = {
}
parent["a"] = 111
parent.__index = parent // 把parent表的__index字段仍然设置为parent
local child = {
}
setmetatable(child, parent) // 把parent表设置为child表的原表
print(child.a)
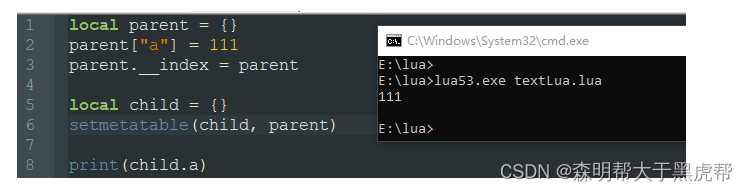
这时候我就出现了疑惑: 既然说把parent设置为child的原表,那child没有的属性就可以在parent中寻找了呀,设置parent.__index是什么东西?
而这个理解是完全错误的,实际上,即使将child的元表设置为parent,而且parent中也确实有这个成员,但是parent的__index元方法没有赋值为本身,返回结果仍然会是nil!!!
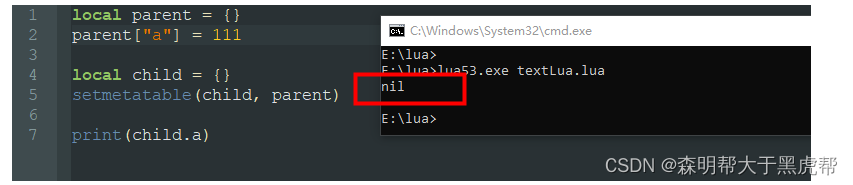
实际上拥有了元表等于告诉了Lua:在A表找不到数据时,我们有解决方法;而元表中的__index则是告诉Lua:你从我的__index中找去吧。所以说parent的__index字段设置成本身相当于告诉lua,没有的话就从parent表中查找吧。
元表的__index字段不一定为自身的表,也可以指向其他表效果一样。
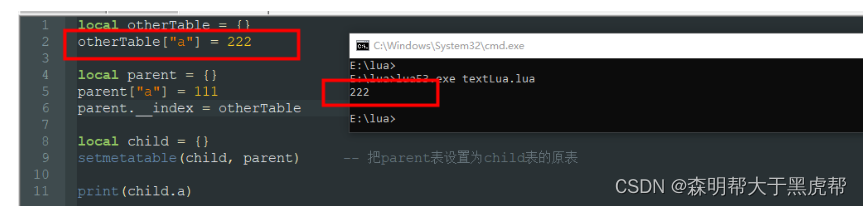
元表的__index字段还可以是一个函数,当在表中找不到这个值时,会调用元表中的__index函数,然后拿去返回值(若无返回值则为nil)。
1.面向对象编程–语法糖
语法糖:
从很多意义上讲,Lua语言中的一张表就是一个对象。 它们都拥有一个与其值无关的标识(self)-- 类似this的指针。例如,我们现在创建一张表:
Account = {
balance = 0 }
-- 余额为0的账户
function Account.withdraw( v )
balance = balance - v
end
-- 取款
function Account.deposit( v )
balance = balance + v
end
-- 存款
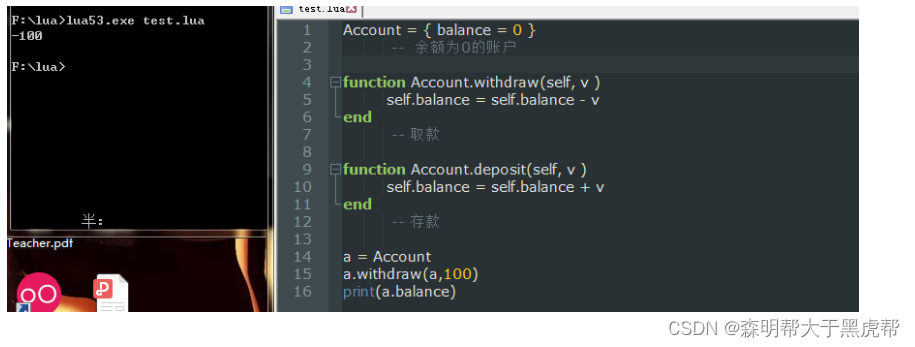
此时我们可以把它看成一张含有两个方法, 一个数值的表, 同时也可以把它当作是 一个银行账户的类。
为了使接受者(receiver)方便进行操作,我们要用一个额外的参数(self)来表示接受者:
Account = {
balance = 0 }
-- 余额为0的账户
function Account.withdraw( self, v )
self.balance = self.balance - v
end
-- 取款
function Account.deposit(self, v )
self.balance = self.balance + v
end
-- 存款
这样我们就可以用一张新表来作为Account的对象了:
但是这个时候,我们广大的程序员又不满意了:什么鬼,还要输入两个参数又难看又麻烦。
于是Lua创始人听到了我们的声音,给我们设置了 一个语法糖 : ( 冒号 )。
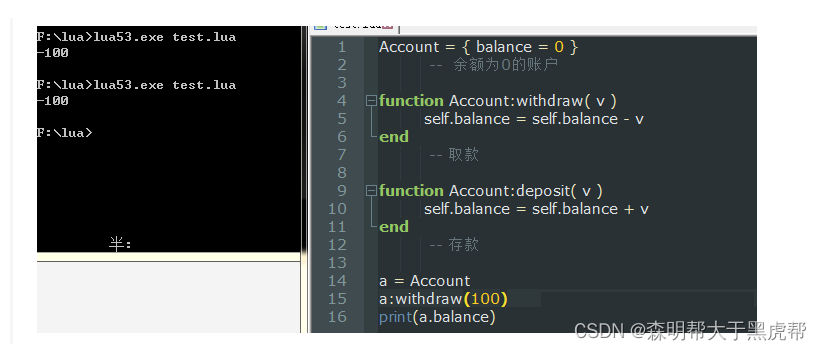
结果是一模一样的,但是看起来就顺眼了很多。
所以说使用:就可以在参数项中少些一个self参数,它和使用 . 后接self参数一样的。
2.面向对象编程–类的实现与继承
1.定义一个类:
类在面向对象语言中就好象一个模板,通过模板所创建的实例就具有模板中规定的特性。Lua中没有类的概念,每一个对象规定自己的行为,每一个对象就是自己的实例。不过在Lua中模拟“类”并不难,我们可以用继承的概念,使用两个对象,让其中一个对象作为另一个对象的“类”。
在Lua语言中,我们如果有两个对象A和B,要让B成为A的一个原型,只需要:
B.__index = B // 把B表的__index字段仍然设置为B
setmetatable(A,B) // 把B表设置为A表的原表
这时候我就出现了疑惑:既然说把B设置为A的原表,那A没有的属性就可以在B中寻找了呀,设置B.__index是什么东西?
而这个理解是完全错误的,实际上,即使将A的元表设置为B,而且B中也确实有这个成员,返回结果仍然会是nil,原因就是B的__index元方法没有赋值。拥有了元表等于告诉了Lua:在A表找不到数据时,我们有解决方法;而元表中的__index则是告诉Lua:你从我的__index中找去吧。
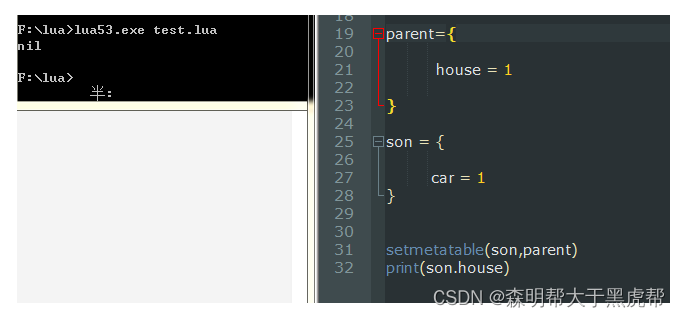
这个时候son想访问父亲的house变量还是返回一个nil的,所以为了实现功能,我们应该这样改:
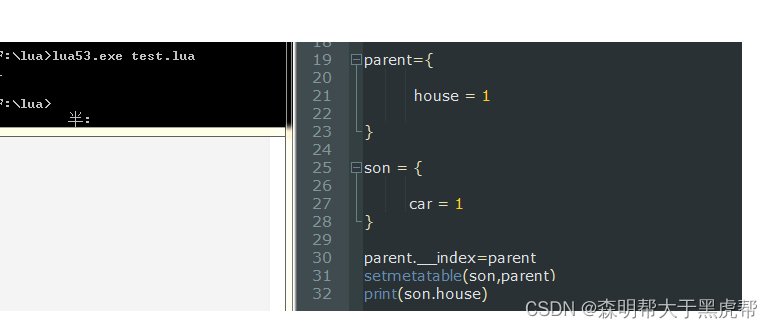
OK,这个时候我们就可以实现以B类作为原型的A类对象的实现啦 。可是这又是setmetatable又是要设置__index,弄得很不美观,我们是用java,C++的时候不就是new来new去的吗?
所以我们就可以把它用一个new封装起来:
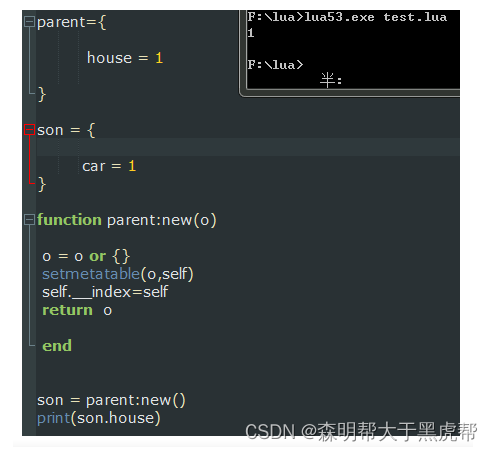
2.继承
在上文中我们已经可以使类的对象进行实现了,那么对于 继承来说只不过是把B当做父类,并且在A中增加或修改新增的函数罢了。当我们使用函数时,Lua会先在 A(子类)中寻找,遇到重名或者仅在A中存在的函数,会优先调用。若 查不到才会走元表,从父类中寻找这一流程。
Account = {
balance = 0 }
-- 余额为0的账户
function Account:withdraw( v )
if self.balance > v then
self.balance = self.balance - v
else print("balance is not enough!")
end
end
-- 取款
function Account:new(o)
o = o or {
}
setmetatable(o,self)
self.__index = self
return o
end
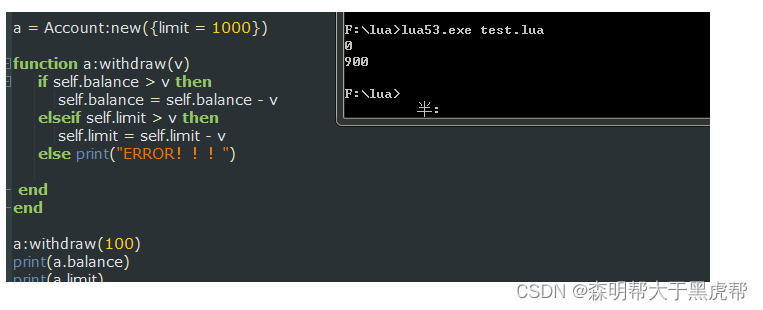
普通的银行账户不允许透支取款,那么如果我们定义一个信用卡账户继承它,并且获得透支额度则可以这样做:
3.__index元方法
从c++,java这些高级语言走过来的我们,肯定对类的继承十分熟悉,甚至没了它还十分不习惯。其实lua也是可以实现继承的,这要利用到它的元方法_index:
local parent = {
}
parent["a"] = 111
parent.__index = parent // 把parent表的__index字段仍然设置为parent
local child = {
}
setmetatable(child, parent) // 把parent表设置为child表的原表
print(child.a)
这时候我就出现了疑惑: 既然说把parent设置为child的原表,那child没有的属性就可以在parent中寻找了呀,设置parent.__index是什么东西?
而这个理解是完全错误的,实际上,即使将child的元表设置为parent,而且parent中也确实有这个成员,但是parent的__index元方法没有赋值为本身,返回结果仍然会是nil!!!
实际上拥有了元表等于告诉了Lua:在A表找不到数据时,我们有解决方法;而元表中的__index则是告诉Lua:你从我的__index中找去吧。所以说parent的__index字段设置成本身相当于告诉lua,没有的话就从parent表中查找吧。
元表的__index字段不一定为自身的表,也可以指向其他表效果一样。
元表的__index字段还可以是一个函数,当在表中找不到这个值时,会调用元表中的__index函数,然后拿去返回值(若无返回值则为nil)。
五、__newindex元方法
如果说 __index字段是在访问表中不存在的值(get)是执行的操作的话。
那么__nexindex字段则是在对表中不存在的值进行赋值(set)时候执行的操作(记住i是小写)。
在这个时候可能有人吐槽:纳尼!!我天天给表创建新字段,咋不见得有执行什么__newindex呢?。
确实,如果没有元表,或者元表中没有__newindex字段,那给表新建一个字段则不会执行其他多余的操作。
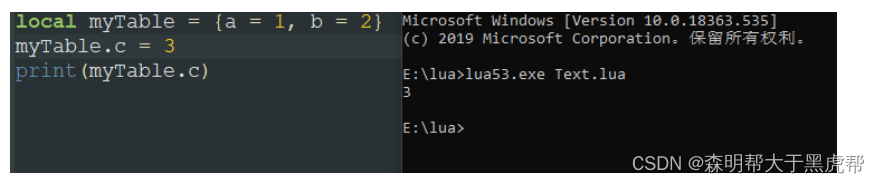
若存在元表且元表中存在着__newindex字段,那么和__index一样,会存在两种情况:
1.__nexindex指向一个函数
如果__newindex字段指向一个函数,则给表创建一个新字段的时候,则会执行该函数,且对本表创建不成功。

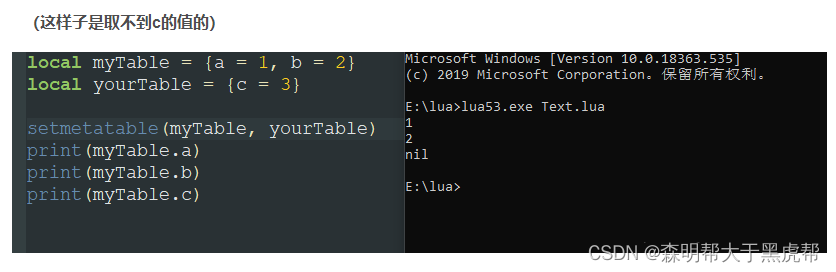
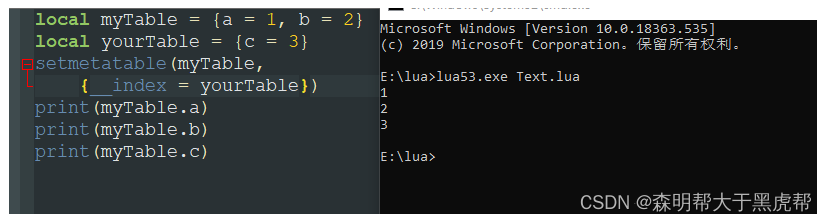
2.__nexindex指向一个表
如果__newindex字段指向一个表,那么就会对该表创建这个字段,且对本表创建不成功。
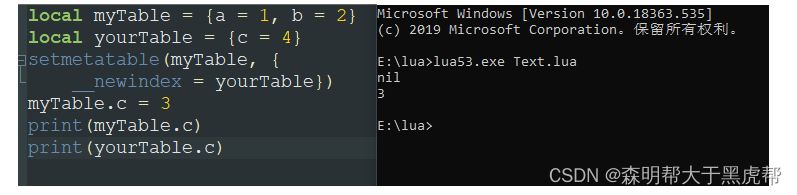
我们可以看到,当我们输出myTable.c时,lua是找不到这个值的,因为实际上是给__nexindex指向的yourTable给赋值。那为什么还是nil呢?从结果我们可以看到,其实这个3我们是赋值给了yourTable.c, 虽然yourTbale已经被赋值,但是访问是__index字段的事,myTable并不能访问得到yourTable的值。
总结来说,就是只要存在__nexindex字段,那么就不会对本表新建值。
那么这个__newindex字段有何作用呢?其实它可以起到一个很好的限制筛选作用。可以防止表被赋值,加入些杂七杂八的元素。有时候一表多用可能会导致些lua中的垃圾回收相关的问题。
六、实现一个常量表
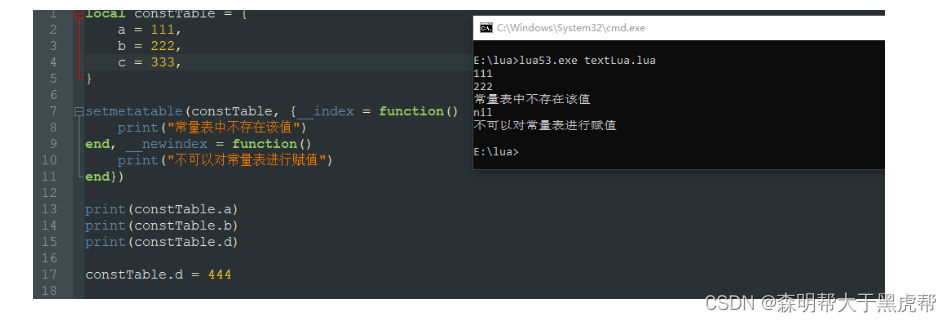
我们可以通过对表设置__index和__newindex字段来把一个表定义成常量表:
七、__call元方法
__call元方法比较好玩,比如说我们上述例子中的myTable是外部引用的一个表。那如果我把它当成一个函数使用会怎么样呢?
print(myTable(1, 2))
毫无疑问是会报错的哈,但是__call方法能够帮助我们实现解决这个问题。
比如说我们的myTable和yourTable都是一个序列(num类型的),我想求出这两个序列的总和。
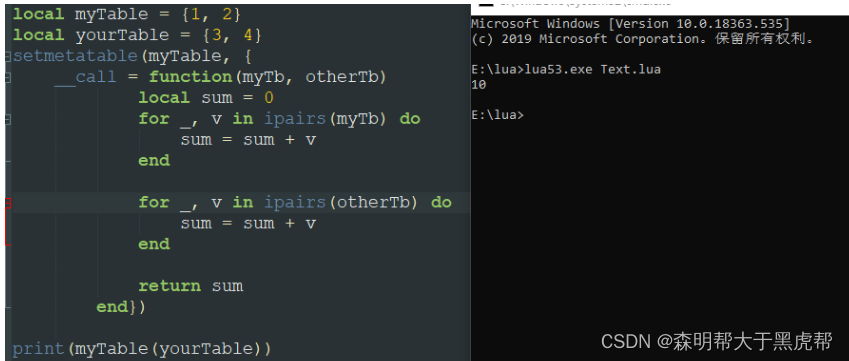
这个时候可能有同学会问:搞那么复杂干嘛咧,我们直接先遍历一遍myTable,再遍历一遍yourTable不就好了吗?或者说我直接在myTable中添加一个新的函数字段,实现同样的功能不也一样吗?
诚然功能确实是一样的,但是如果我们需要频繁的利用这个外表(myTable)去生成或取得某一些内容时,利用__call方法会简便许多你说是myTable(XX)方便还是myTable.函数名(XX)方便?
八、__tostring元方法
__tostring 元方法用于修改表的输出行为 ,如果我们直接print()一个表,那么我们返回得到的是一个地址。
而如果我们通过设置其元表的__tostring字段,那么返回的就是__tostring指向的结果。
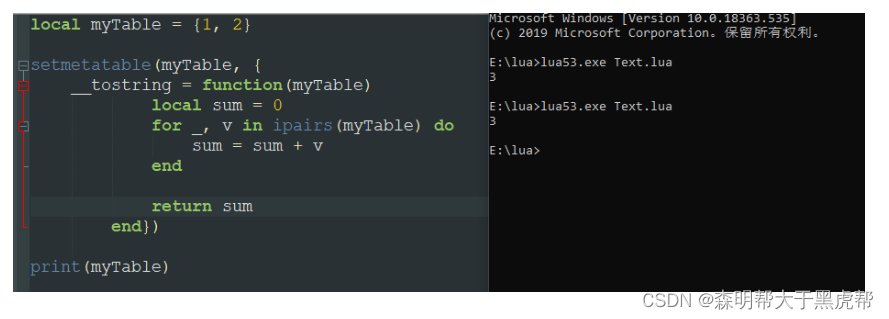
比如上面的例子就是输出自己的序列和,记住__tostring返回的是一个字符串,不然会报错。
眼尖的同学可能立刻就发现了,阿西,你这里的sum不就是一个num吗?
但是lua在print一个num的时候会自动把它转化为string类型, 但是不是所有的类型都会自动转换的。
九、lua元方法
说起lua那么就不得不提其元表,lua通过元表的设置实现了高级语言中的“继承”的功能。
1.__index元方法
- 当我们访问一个表中不存在的元素时,会执行以下三个步骤:
- lua会判断这个表是否有元表,若无则返回nil。
- 若存在着元表,则会判断元表是否存在__index字段,若无则返回nil。
- 若存在着元表,且元表中存在着__index字段,若__index对应的值是一个函数则得到函数的返回值。
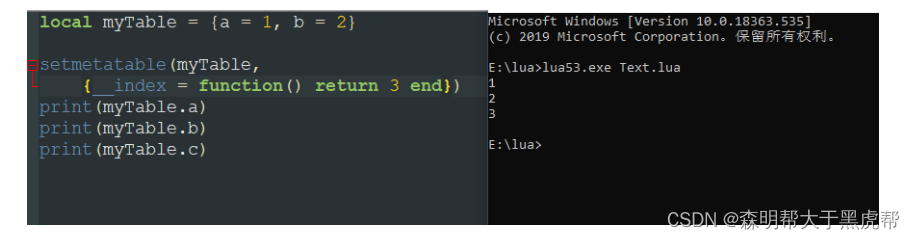
若对应的是一个表则在该表中寻找想要的值,若有则返回,若无则重复123。
2.__newindex元方法
如果说 __index字段是在访问表中不存在的值(get)是执行的操作的话。
那么__nexindex字段则是在对表中不存在的值进行赋值(set)时候执行的操作(记住i是小写)。
在这个时候可能有人吐槽:纳尼!!我天天给表创建新字段,咋不见得有执行什么__newindex呢?。
确实,如果没有元表,或者元表中没有__newindex字段,那给表新建一个字段则不会执行其他多余的操作。
若存在元表且元表中存在着__newindex字段,那么和__index一样,会存在两种情况:
1.__nexindex指向一个函数
如果__newindex字段指向一个函数,则给表创建一个新字段的时候,则会执行该函数,且对本表创建不成功。
2.__nexindex指向一个表
如果__newindex字段指向一个表,那么就会对该表创建这个字段,且对本表创建不成功。
我们可以看到,当我们输出myTable.c时,lua是找不到这个值的,因为实际上是给__nexindex指向的yourTable给赋值。那为什么还是nil呢?从结果我们可以看到,其实这个3我们是赋值给了yourTable.c, 虽然yourTbale已经被赋值,但是访问是__index字段的事,myTable并不能访问得到yourTable的值。
总结来说,就是只要存在__nexindex字段,那么就不会对本表新建值。
那么这个__newindex字段有何作用呢?其实它可以起到一个很好的限制筛选作用。可以防止表被赋值,加入些杂七杂八的元素。有时候一表多用可能会导致些lua中的垃圾回收相关的问题。
3.__call元方法
__call元方法比较好玩,比如说我们上述例子中的myTable是外部引用的一个表。那如果我把它当成一个函数使用会怎么样呢?
print(myTable(1, 2))
毫无疑问是会报错的哈,但是__call方法能够帮助我们实现解决这个问题。
比如说我们的myTable和yourTable都是一个序列(num类型的),我想求出这两个序列的总和。
这个时候可能有同学会问:搞那么复杂干嘛咧,我们直接先遍历一遍myTable,再遍历一遍yourTable不就好了吗?或者说我直接在myTable中添加一个新的函数字段,实现同样的功能不也一样吗?
诚然功能确实是一样的,但是如果我们需要频繁的利用这个外表(myTable)去生成或取得某一些内容时,利用__call方法会简便许多你说是myTable(XX)方便还是myTable.函数名(XX)方便?
4.__tostring元方法
__tostring 元方法用于修改表的输出行为 ,如果我们直接print()一个表,那么我们返回得到的是一个地址。
而如果我们通过设置其元表的__tostring字段,那么返回的就是__tostring指向的结果。
比如上面的例子就是输出自己的序列和,记住__tostring返回的是一个字符串,不然会报错。
眼尖的同学可能立刻就发现了,阿西,你这里的sum不就是一个num吗?
但是lua在print一个num的时候会自动把它转化为string类型, 但是不是所有的类型都会自动转换的。
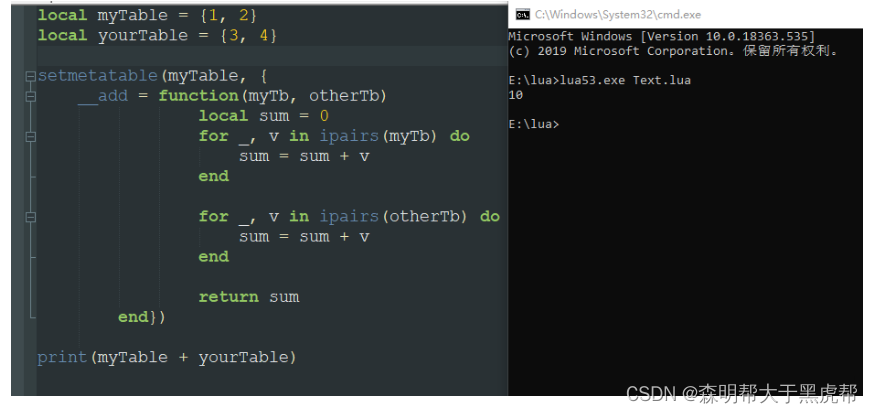
5.__le,__eq, __lt,__add, __pow,__mod
这六个元方法分别对应:小于等于,等于,小于,加法,乘幂,取模等。
当我们对两个表进行大小比较,或者加减乘除乘幂取模的时候。
lua会查看元表中是否有对应的字段,若有则执行相关的函数,没有则会报错。
十 、lua闭包
简单来说就是:对于一个函数,能够访问到外部函数的非全局变量的一种机制。
什么是闭包?说起来很绕,我们看一个栗子:
function func1 ()
local x = 1
-- 定义一个内部函数
function func2 ()
print(x)
end
-- 执行这个内部函数
func2()
end
func1()
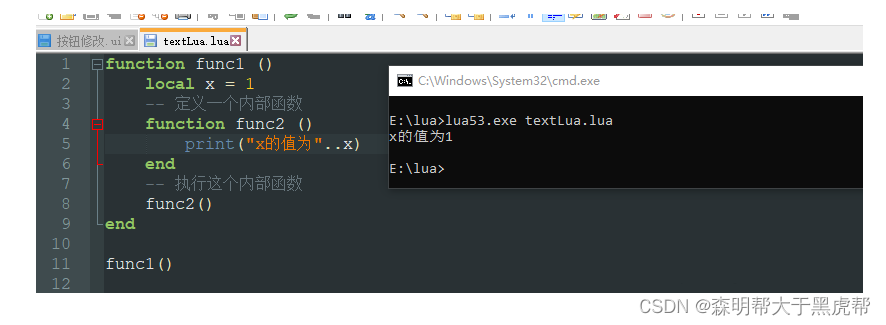
这个例子就是在外部调用了func1函数,而func1中定义了一个func2函数并调用了它。我们可以看到,func2访问了属于func1的local变量x,并且访问成功了。按道理来讲,x并不是全局变量,也不是func2的局部变量,应该是访问不到的。而lua却做到了,lua把实现这个功能的方式定义为闭包。
所以从理论上来讲,lua只有闭包没有函数,函数只是不需要调用外部变量的一个闭包的特例
那么lua是怎么实现闭包的呢?
闭包的实现方式:
1.当Lua编译一个函数时,它会生成一个原型(prototype),原型中包括函数的虚拟机指令、函数中的常量(数值和字符串等)和一些调试信息。
2.每个闭包都有一个相应函数原型的引用以及一个数组,数组中每个元素都是一个对upvalue的引用,可以通过该数组来访问外部的局部变量。
上文提到函数是闭包的一部分,那么简而言之,如果访问到外部的非全局变量,那么数组则不为空。若没有访问到非全局变量(普通函数),那么闭包中的数组就为空。而且该数组对于这些非全局变量会复制在upValue中,因此闭包与闭包之间是的非全局遍历不会相互影响。
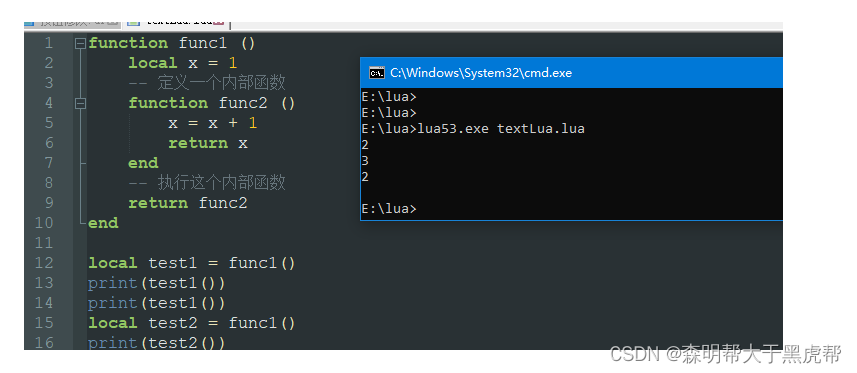
举个例子:
1.闭包的概念
在Lua中,闭包(closure)是由一个函数和该函数会访问到的非局部变量(或者是upvalue)组成的,其中非局部变量(non-local variable)是指不是在局部作用范围内定义的一个变量,但同时又不是一个全局变量,主要应用在嵌套函数和匿名函数里,因此若一个闭包没有会访问的非局部变量,那么它就是通常说的函数。也就是说,在Lua中,函数是闭包一种特殊情况。另外在Lua的C API中,所有关于Lua中的函数的核心API都是以closure来命名的,也可视为这一观点的延续。在Lua中,函数是一种第一类型值(First-Class Value),它们具有特定的词法域(Lexical Scoping)。
第一类型值表示函数与其他传统类型的值(例如数字和字符串类型)具有相同的权利。即函数可以存储在变量或table中,可以作为实参传递给其他函数,还可以作为其他函数的返回值,可以在运行期间被创建。在Lua中,函数与所有其他的值是一样都是匿名的,即他们没有名称。当讨论一个函数时(例如print),实质上在讨论一个持有某个函数的变量。比如:
function foo(x) print(x) end
实质是等价于:
foo = function (x) print(x) end
因此一个函数定义实质就是一条赋值语句,这条语句创建了一种类型为“函数”的值,并赋值给一个变量。可以将表达式function (x) end视为一种函数构造式,就像table的构造式{}一样。
值得一提的是,C语言里面函数不能在运行期被创建,因此不是第一类值,不过有时他们被称为第二类值,原因是他们可以通过函数指针实现某些特性,比如常常显现的回调函数的影子。
词法域是指一个函数可以嵌套在另一个函数中,内部的函数可以访问外部函数的变量。比如:
function f1(n)
--函数参数n也是局部变量
local function f2()
print(n) --引用外部函数的局部变量
end
return f2
end
g1 = f1(2015)
g1() -- 打印:2015
g2 = f1(2016)
g2() -- 打印:2016
注意这里的g1和g2的函数体相同(都是f1的内嵌函数f2的函数体),但打印值不同。这是因为创建这两个闭包时,他们都拥有局部变量n的独立实例。事实上,Lua编译一个函数时,会为他生成一个原型(prototype),其中包含了函数体对应的虚拟机指令、函数用到的常量值(数,文本字符串等等)和一些调试信息。在运行时,每当Lua执行一个形如function…end 这样的表达式时,他就会创建一个新的数据对象,其中包含了相应函数原型的引用及一个由所有upvalue引用组成的数组,而这个数据对象就称为闭包。由此可见,函数是编译期概念,是静态的,而闭包是运行期概念,是动态的。g1和g2的值严格来说不是函数而是闭包,并且是两个不相同的闭包,而每个闭包能保有自己的upvalue值,所以g1和g2打印出的结果当然就不相同了。
这里的函数f2可以访问参数n,而n是外部函数f1的局部变量。在f2中,变量n即不是全局变量也不是局部变量,将其称为一个非局部变量(non-local variable)或upvalue。upvalue实际指的是变量而不是值,这些变量可以在内部函数之间共享,即upvalue提供一种闭包之间共享数据的方法,比如:
function Create(n)
local function foo1()
print(n)
end
local function foo2()
n = n + 10
end
return foo1,foo2
end
f1,f2 = Create(2015)
f1() -- 打印2015
f2()
f1() -- 打印2025
f2()
f1() -- 打印2035
注意上面的例子中,闭包f1和f2共享同一个upvalue了,这是因为当Lua发现两个闭包的upvalue指向的是当前堆栈上的相同变量时,会聪明地只生成一个拷贝,然后让这两个闭包共享该拷贝,这样任一个闭包对该upvalue进行修改都会被另一个探知。
闭包在创建之时其upvalue就已不在堆栈上的情况也有可能发生,这是因为内嵌函数能引用更外层外包函数的局部变量:
function Test(n)
local function foo()
local function inner1()
print(n)
end
local function inner2()
n = n + 10
end
return inner1,inner2
end
return foo
end
t = Test(2015)
f1,f2 = t()
f1() -- 打印:2015
f2()
f1() -- 打印:2025
g1,g2 = t()
g1() -- 打印:2025
g2()
g1() -- 打印:2035
f1() -- 打印:2035
注意上面的执行的结果表明了闭包f1、f2、g1和g2都共有同一个upvalue,这是因为在创建inner1,inner2这两个闭包被创建时堆栈上根本未找到n的踪影,而是直接使用闭包foo的upvalue。t = Test(2015)之后,t这个闭包一定已把n妥善保存好了,之后f1、f2如果在当前堆栈上未找到n就会自动到他们的外包闭包的upvalue引用数组中去找,并把找到的引用值拷贝到自己的upvalue引用数组中。所以f1、f2、g1和g2引用的upvalue实际也是同一个变量,而刚才描述的搜索机制则确保了最后他们的upvalue引用都会指向同一个地方。
2.闭包的应用
在许多场合中闭包都是一种很有价值的工具,主要有以下几个方面:
- 作为高阶函数的参数,比如像table.sort函数的参数。
- 创建其他的函数的函数,即函数返回一个闭包。
- 闭包对于回调函数也非常有用。典型的例子就是界面上按钮的回调函数,这些函数代码逻辑可能是一模一样,只是回调函数参数不一样而已,即upvalue的值不一样而已。
- 创建一个安全的运行环境,即所谓的沙盒(sandbox)。当执行一些未受信任的代码时就需要一个安全的运行环境。比如要限制一个程序访问文件的话,只需要使用闭包来重定义函数io.open就可以了:经过重新定义后,原来不安全的版本保存到闭包的私有变量中,从而使得外部再也无法直接访问到原来的版本了。
do
local oldOpen = io.open
local accessOk = function(filename, mode)
--<权限访问检查>
end
io.open = function (filename, mode)
if accessOk(filename, mode) then
return oldOpen(filename, mode)
else
return nil, "access denied"
end
end
end
- 实现迭代器。所谓迭代器就是一种可以遍历一种集合中所谓元素的机制。每个迭代器都需要在每次成功调用之间保持一些状态,这样才能知道它所在的位置及如何进到下一个位置。闭包刚好适合这种场景。比如:
function values(t)
local i = 0
return function () i = i + 1 return t[i] end
end
t = {
10, 20, 30}
iter = values(t)
while true do
local element = iter()
if element == nil then break end
print(element)
end
3.闭包的实现原理
当Lua编译一个函数时,它会生成一个原型(prototype),原型中包括函数的虚拟机指令、函数中的常量(数值和字符串等)和一些调试信息。在任何时候只要Lua执行一个function … end表达时,它都会创建一个新的闭包(closure)。每个闭包都有一个相应函数原型的引用以及一个数组,数组中每个元素都是一个对upvalue的引用,可以通过该数组来访问外部的局部变量(outer local variables)。值得注意的是,在Lua 5.2之前,闭包中还包括一个对环境(environment)的引用,环境实质就是一个table,函数可以在该表中索引全局变量,从Lua 5.2开始,取消了闭包中的环境,而引入一个变量_ENV来设置闭包环境。由此可见,函数是编译期概念,是静态的,而闭包是运行期概念,是动态的。
作用域(生成期)规则下的嵌套函数给如何实现内存函数存储外部函数的局部变量是一个众所周知的难题(The combination of lexical scoping with first-class functions creates a well-known difficulty for accessing outer local variables)。比如例子:
function add (x)
return function (y)
return x+y
end
end
add2 = add(2)
print(add2(5))
当add2被调用时,其函数体访问了外部的局部变量x(在Lua中,函数参数也是局部变量)。然而,当调用add2函数时,创建add2的add函数已经返回了,如果x在栈中创建,则当add返回时,x已经不存在了(即x的存储空间被回收了)。
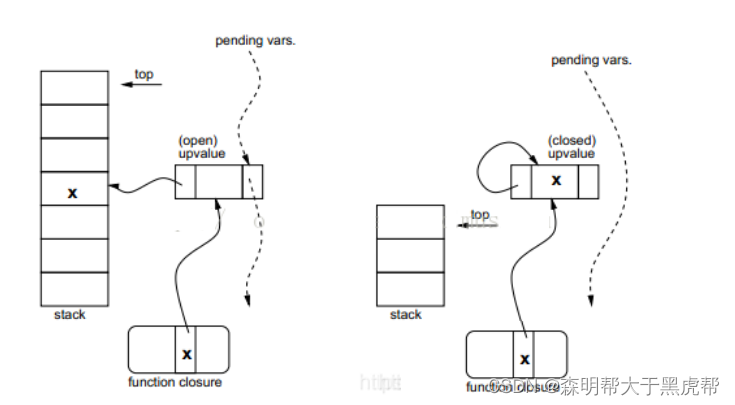
为了解决上面的问题,不同语言有不同的方法,比如python通过限定作用域、Pascal限制函数嵌套以及C语言则两者都不允许。在Lua中,使用一种称为upvalue结构来实现闭包。任何外部的局部变量都是通过upvalue来间接访问。upvalue初始值是指向栈中,即变量在栈中的位置。如下图左边。当运行时,离开变量作用域时(即超过变量生命周期),则会把变量复制到upvalue结构中(注意也只是在此刻才执行这个操作),如下图右边。由于对变量的访问都是通过upvalue结构中指针间接进行的,因此复制操作对任何读或写变量的代码来说都是没有影响的。与内部函数(inner functions)不同的是,声明该局部变量的函数都是直接在栈中操作它的。
通过为每个变量最多创建一个upvalue并按需要重复利用这个upvalue,保证了未决状态(未超过生命周期)的局部变量(pending vars)能够在闭包之间正确地共享。为了保证这种唯一性,Lua维护这一条链表,该链表中每个节点对应一个打开的upvalue(opend upvalue)结构,打开的upvalue是指当前正指向栈局部变量的upvalue,如上图的未决状态的局部变量链表(the pending vars list)。当Lua创建一个新的闭包时,Lua会遍历当前函数所有的外部的局部变量,对于每一个外部的局部变量,若在上面的链表中能找到该变量,则重复使用该打开的upvalue,否则,Lua会创建一个新的打开的upvalue,并把它插入链表中。当局部变量离开作用域时(即超过变量生命周期),这个打开的upvalue就会变成关闭的upvalue(closed upvalue),并把它从链表中删除,如上图右图所示意。一旦某个关闭的upvalue不再被任何闭包所引用,那么它的存储空间就会被回收。
一个函数有可能存取其更外层函数而非直接外层函数的局部变量。在这种情况下,当创建闭包时,这个局部变量可能不在栈中。Lua使用flat 闭包(flat closures)来处理这种情况。使用flat闭包,无论何时一个函数访问一个外部的局部变量并且该变量不在直接外部函数中,该变量也会进入直接外部函数的闭包中。当一个函数被实例化时,其对应闭包的所有变量要么在直接外部函数的栈中要么在直接外部函数的闭包中。第一部分举的最后一个例子就是这种情况。下一篇文章将分析Lua中闭包对应的源码实现以及调用的过程。
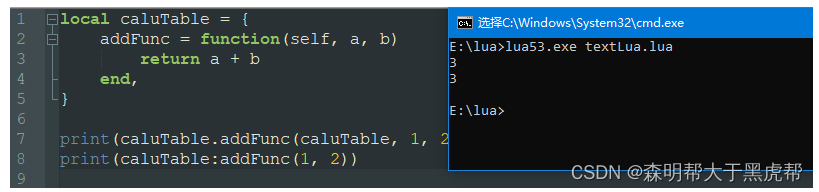
十一、类使用:和.的区别
一个类调用方法时,可以使用类名A.方法名(A, 参数),也可以使用语法糖,类名 A:方法名(参数)。
简而言之就是使用冒号符的时候默认把自身的table传进去函数中,举个例子:
十二、require,loadfile和dofile的区别
十三、Lua的热更新原理
1.什么是热更新
- 字面意思就是对lua的一些代码进行更新,在介绍热更新之前,我想要和大家分享一下lua的require的机制
- 我们知道lua加载一个文件的方式可以有:dofile,loadfile以及 require。其中loadfile是只编译不执行,dofile和require是同时编译和执行。而dofile和require的区别是dofile同一个文件每次都要加载,也就是说,dofile两次返回来的是两个不同的地址。而require同一个文件,不管多少次都是都返回同一个地址,其原因是lua的地址缓存在了package.load()中。所以效率比dofile要高许多,因而现在一般都是用require加载文件。
- 那么问题来了,如果我在lua文件中改变了一些数值(产生了新的地址),结果你却用之前的地址,那岂不是白给了吗?
2.热更新机制应运而生,两种实现方式
1.简单版但是有缺陷
package.load(“modelname”) = nil
-- 修改modelname.lua的数据
require(“modelname”)
- 既然你有缓存,我直接置为空不就好了吗?然后重新require一次把修改好的加进来。这样子做的话第二次require的数据可能是正确的,但是之前require过一次的数值却仍然错误,所以说程序除非在之前没有加载过这个文件,否则得到的结果不完善。
2.复杂版但是很有用
function reload_module(module_name)
local old_module = package.loaded[module_name] or {
}
package.loaded[module_name] = nil
require (module_name)
local new_module = package.loaded[module_name]
for k, v in pairs(new_module) do
old_module[k] = v
end
package.loaded[module_name] = old_module
return old_module
end
-
简单来说就是使用一个全局表存储了新修改后的所有数值,然后循环赋值给旧的值,这样就可以确保同一个旧地址也可以得到正确的数据。
-
最后贴一张热更新项目的流程图把:

2.hotfix 实现了Lua热更新,仅对函数作替换,保留旧数据
Lua 5.2/5.3 hotfix. Hot update functions and keep old data.
https://github.com/jinq0123/hotfix
- hotfix 实现了Lua热更新,仅对函数作替换,保留旧数据。
例如 test.lua:
local M = {
}
local a = "old"
function M.get_a() return a end
return M
- 更新到:
local M = {
}
local a = "new"
function M.get_a() return a .. "_x" end
return M
- 运行:
local hotfix = require("hotfix")
local test = hotfix.hotfix_module("test")
test.get_a() -- "old_x"
-
数据 a 作为函数的upvalue得到了保留,但是函数得到了更新。
-
可查看 test/main.lua 中的测试用例。
-
运行测试:
E:\Git\Lua\hotfix\test>d:\Tools\lua\lua53.exe
Lua 5.3.2 Copyright © 1994-2015 Lua.org, PUC-Rio
require("main").run()
Test OK!
3.热更新进一步介绍
1.原理
-
任何一款手游上线之后,我们都需要进行游戏Bug的修复或者是在遇到节日时发布一些活动,这些都需要进行游戏的更新,而且通常都会涉及到代码的更新。
-
热更新是指用户直接重启客户端就能实现的客户端资源代码更新操作。游戏热更新会减少游戏中的打包次数,提升程序调试效率,游戏运营时候减少大版本更新次数,可以有效防止用户流失。
-
lua语言在热更新中会被广泛使用,我们这里采取的是ulua,ulua是unity+lua+cstolua组成的,开发者已经为我们封装成SimpleFramework_UGUI和SimpleFramework_NGUI框架,让开发者在使用的时候更加快捷方便。
2.要点分析
1.Lua语言
-
再热更新功能开发过程中,我们需要用到一款新的语言:Lua语言。
-
Lua和C#对比:C#是编译型语言,Lua是解析型语言
-
Lua语言不可以单独完成一个项目的开发,Lua语言出现的目的是“嵌入式”,为其他语言开发出来的项目进行功能的扩展和补丁的更新。
2.Lua语言与C#语言交互
- Unity项目是使用C#开发的,后续热更新的功能需要使用Lua语言实现。而我们在最开始使用C#开发项目的时候,需要预留和Lua代码的“交互接口”,这就涉及到两门语言的代码相互调用访问。
3.AssetBundle
- AssetBundle是Unity内资源的一种打包格式,和电脑上的rar、zip压缩包比较类似,客户端热更新过程中,从服务器上下载下来的资源,都是AssetBundle打包过的资源。
4.ULua和XLua热更新框架
- ULua和XLua是两个热更新框架,专门用于Unity客户端项目热更新开发。其实就是两个“资源包”,导入到我们的项目中,在框架的基础之上,完成我们项目需要的热更新逻辑。
3.Lua热更新的实现
整理一下热更新的思路主要有两点:
- 1.将模块中旧的函数替换成新的函数,这个新的函数可以放到一个lua文件中,或者以字符串的形式给出。
- 2.将模块中旧的函数,当前用到的所有上值,(什么是上值,后面有讲到)保存到起来,用于新函数引用,保证新函数作为模块中的一部分能够正确运行。
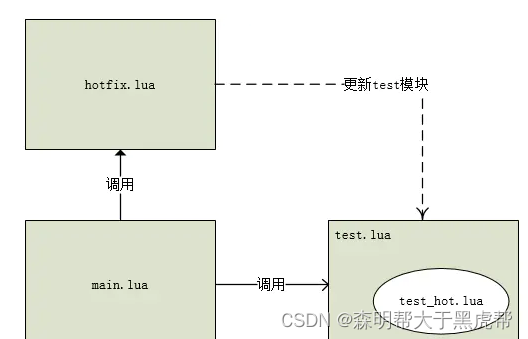
下面以一个demo为例,这也是抽取 snax 模块中热更新部分:
./main.lua 调用 test.lua,做为运行文件,显示最终运行效果
./test.lua 一个简单模块文件,用于提供热更新的来源
./test_hot.lua 用于更新替换 test 模块中的某些函数,更新文件
./hotfix.lua 实现热更新机制
-
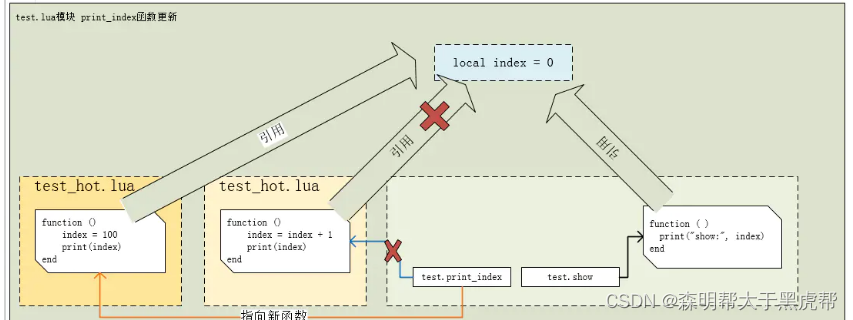
通过这幅关系图,可以了解到,test 模块和 test_hot 之间的关系,test_hot 负责更新 test 模块中的某些函数,但更新后的这些函数依然属于 test 模块中的一部分,并没有脱离 test 模块的掌控,而独立出来。
-
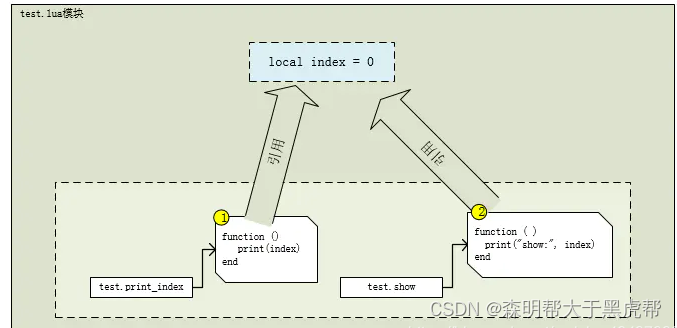
现在我们看看 test.lua 包含了哪些内容,分别有 一个局部变量 index,两个函数 print_index,show ,函数体分别是圆圈1和2,两个函数都引用到了这个局部变量 index。
-
假设当前,我们想更新替换掉 print_index 函数,让其 index 加1 操作,并打印 index 值,那么我们可以在 test_hot.lua 文件中这么写,见下图黄色框部分:
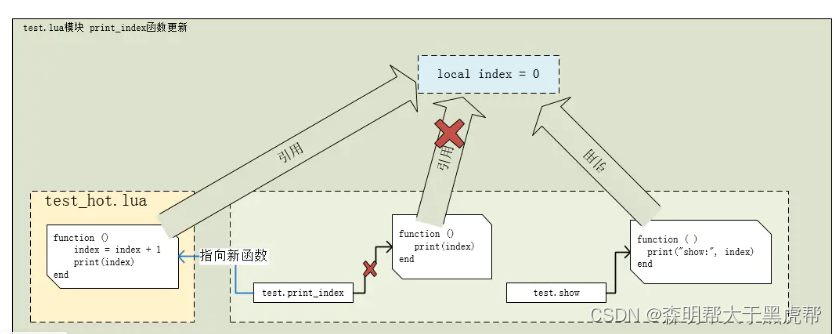
-
我们希望在 print_index 更新后, index 加 1 后,show 函数获取到的 index 值是 1,即把更新函数也看作是 test.lua 模块中的一部分。而不应该是 index 加 1 后,show 函数获取到的还是原值 0。
-
假设我们希望更新 print_index 后,再一次更新,把 index 值直接设置为 100,那么它又应该是这样子的,见下图最左侧黄色部分:
4._ENV 环境变量
- 在 lua 程序设计一书中有过这样的解释,lua 语言并没有全局变量,所谓的全局变量都是通过某种手段模拟出来的。
Lua 语言是在一个名为 _ENV 的预定义上值(一个外部的局部变量,upvalue)存在的情况下编译所有的代码段的。因此,所有的变量要么绑定到一个名称的局部变量,要么是 _ENV 中的一个字段,而 _ENV 本身是一个局部变量。
例如:
local z = 10
x = 0
y = 1
x = y + z
等价于
local z = 10
_ENV.x = 0
_ENV.y = 1
_ENV.x = _ENV.y + z
- x,y 都是不用 local 声明,z 是 local 声明。
- 所以,我们用到的全局变量其实是保存到 _ENV 变量中。lua 语言在内部维护了一个表来作用全局环境(_G),通常,我们在 load 一个代码段,一个模块时,lua 会用这个表(_G)来初始化 _ENV。如果上面的几行代码是写在一个文件中,那么当 load 调用它时,又会等价于:
-- xxx.lua 文件
local _ENV = the global environment (全局环境)
return function(...)
local z = 10
_ENV.x = 0
_ENV.y = 1
_ENV.x = _ENV.y +z
end
5.上值 upvalue
当一个局部变量被内层的函数中使用的时候, 它被内层函数称作上值,或是外部局部变量。引用 Lua 5.3 参考手册
例如:
local x = 10
function hello(a, b)
local c = a + b + x
print(c)
end
那么在这段代码中,hello 函数的上值有 变量 x,_ENV,而我们刚刚讲到,print 没有经过声明,就可以直接使用,那么它肯定是保存于 _ENV 表中,print(c) 等价于 _ENV.print(c),而变量 a、b、c 都是做为 hello 函数的局部变量。
6.热更新函数Lua的require函数
- Lua的require(modelname)把一个lua文件加载存放到package.loaded[modelname]中,重复require同一个模块实际还是沿用第一次加载的chunk。因此,很容易想到,第一个版本的热更新模块可以写成这样:
--强制重新载入module
function require_ex( _mname )
log( string.format("require_ex = %s", _mname) )
if package.loaded[_mname] then
log( string.format("require_ex module[%s] reload", _mname))
end
package.loaded[_mname] = nil
require( _mname )
end
- 可以看到,强制地require新的模块来更新新的代码,非常简单暴力。但是,显然问题很多,旧的引用住的模块无法得到更新,全局变量需要用"a = a or 0"这种约定来保留等等。这种程度的热更新显然不能满足现在的游戏开发需求。
7.热更新函数Lua的setenv函数
- setenv是Lua 5.1中可以改变作用域的函数,或者可以给函数的执行设置一个环境表,如果不调用setenv的话,一段lua chunk的环境表就是_G,即Lua State的全局表,print,pair,require这些函数实际上都存储在全局表里面。那么这个setenv有什么用呢?我们知道loadstring一段lua代码以后,会经过语法解析返回一个Proto,Lua加载任何代码chunk或function都会返回一个Proto,执行这个Proto就可以初始化我们的lua chunk。为了让更新的时候不污染_G的数据,我们可以给这个Proto设置一个空的环境表。同时,我们可以保留旧的环境表来保证之前的引用有效。
local Old = package.loaded[PathFile]
local func, err = loadfile(PathFile)
--先缓存原来的旧内容
local OldCache = {
}
for k,v in pairs(Old) do
OldCache[k] = v
Old[k] = nil
end
--使用原来的module作为fenv,可以保证之前的引用可以更新到
setfenv(func, Old)()
8.热更新函数Lua的debug库函数
- Lua的函数是带有词法定界的first-class value,即Lua的函数与其他值(数值、字符串)一样,可以作为变量、存放在表中、作为传参或返回。通过这样实现闭包的功能,内嵌的函数可以访问外部的局部变量。这一特性给Lua带来强大的编程能力同时,其函数也不再是单一无状态的函数,而是连同外部局部变量形成包含各种状态的闭包。如果热更新缺少了对这种闭包的更新,那么可用性就大打折扣。
下面讲一下热更新如何处理旧的数据,还有闭包的upvalue的有效性问题怎么解决。这时候强大的Lua debug api上场了,调用debug库的getlocal函数可以访问任何活动状态的局部变量,getupvalue函数可以访问Lua函数的upvalues,还有相对应的修改函数。
例如,这是查询和修改函数局部变量写的debug函数:
-- 查找函数的local变量
function get_local( func, name )
local i=1
local v_name, value
while true do
v_name, value = debug.getlocal(func,i)
if not v_name or v_name == name then
break
end
i = i+1
end
if v_name and v_name == name then
return value
end
return nil
end
-- 修改函数的local变量
function set_local( func, name, value )
local i=1
local v_name
while true do
v_name, _ = debug.getlocal(func,i)
if not v_name or v_name == name then
break
end
i = i+1
end
if not v_name then
return false
end
debug.setlocal(func,i,value)
return true
end
-
一个函数的局部变量的位置实际上在语法解析阶段就已经能确定下来了,这时候生成的opcode就是通过寄存器的索引来找到局部变量的,了解这一点应该很容易理解上面的代码。修改upvalue的我就不列举了,同样的道理,这时你一定已经看出来了,这种方式可以实现某种程度的数据更新。
-
明白了debug api操作后,还是对问题的解决毫无头绪,先看看skynet怎么对代码进行热更新的吧,上面的代码是我对skynet进行修改调试时候写的。skynet的热更新并不是对文件原地修改更新,而是先把将要修改的函数打成patch,再把patch inject进正在运行的服务完成更新,skynet里面有一个机制对patch文件中的upvalue与服务中的upvalue做了重新映射,实现原来的upvalue继续有效。可惜它并不打算对所有闭包upvalue做继承的支持,skynet只是把热更新用作不停机的bug修复机制,而不是系统的热升级。通过inject patch的方式热更新可以看出来,云风并不认为热更新所有的闭包是完全可靠的。对热更新的定位我比较赞同,但是我想通过另外方式完成热更新,毕竟管理各种patch的方式显得不够干净。
9.深度递归替换所有的upvalue
- 接下来要做的事情很清晰了,递归所有的upvalue,根据一定的替换规则替换就可以,注意新的upvalue需要设置回原来的环境表。
function UpdateUpvalue(OldFunction, NewFunction, Name, Deepth)
local OldUpvalueMap = {
}
local OldExistName = {
}
-- 记录旧的upvalue表
for i = 1, math.huge do
local name, value = debug.getupvalue(OldFunction, i)
if not name then break end
OldUpvalueMap[name] = value
OldExistName[name] = true
end
-- 新的upvalue表进行替换
for i = 1, math.huge do
local name, value = debug.getupvalue(NewFunction, i)
if not name then break end
if OldExistName[name] then
local OldValue = OldUpvalueMap[name]
if type(OldValue) ~= type(value) then -- 新的upvalue类型不一致时,用旧的upvalue
debug.setupvalue(NewFunction, i, OldValue)
elseif type(OldValue) == "function" then -- 替换单个函数
UpdateOneFunction(OldValue, value, name, nil, Deepth.." ")
elseif type(OldValue) == "table" then -- 对table里面的函数继续递归替换
UpdateAllFunction(OldValue, value, name, Deepth.." ")
debug.setupvalue(NewFunction, i, OldValue)
else
debug.setupvalue(NewFunction, i, OldValue) -- 其他类型数据有改变,也要用旧的
end
else
ResetENV(value, name, "UpdateUpvalue", Deepth.." ") -- 对新添加的upvalue设置正确的环境表
end
end
end
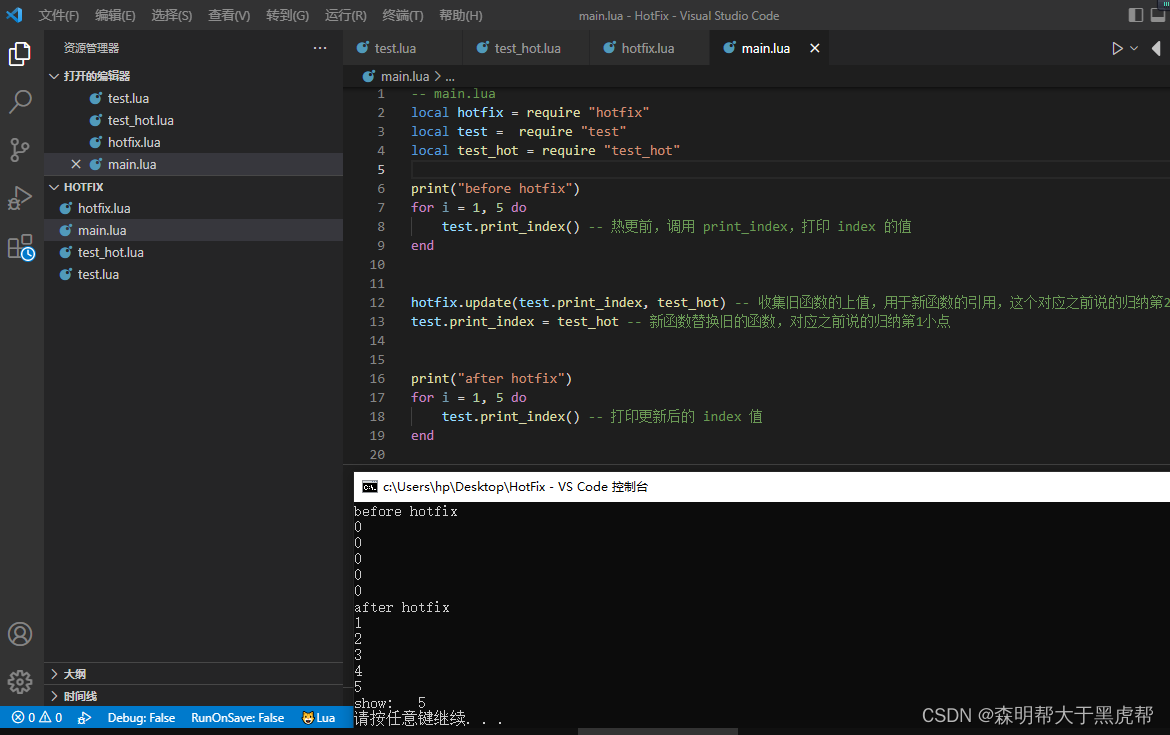
10.实例分析
- 下面就来看下具体 demo 的实现。
-- main.lua
local hotfix = require "hotfix"
local test = require "test"
local test_hot = require "test_hot"
print("before hotfix")
for i = 1, 5 do
test.print_index() -- 热更前,调用 print_index,打印 index 的值
end
hotfix.update(test.print_index, test_hot) -- 收集旧函数的上值,用于新函数的引用,这个对应之前说的归纳第2小点
test.print_index = test_hot -- 新函数替换旧的函数,对应之前说的归纳第1小点
print("after hotfix")
for i = 1, 5 do
test.print_index() -- 打印更新后的 index 值
end
test.show() -- show 函数没有被热更,但它获取到的 index 值应该是 最新的,即 index = 5。
- 接下来看看 test.lua 模块内容:
-- test.lua
local test = {
}
local index = 0
function test.print_index()
print(index)
end
function test.show( )
print("show:", index)
end
return test
- 再看看 热更文件 test_hot.lua 内容:
-- test_hot.lua
local index -- 这个 index 必须声明,不用赋值,才能够引用到 test 模块中的局部变量 index
return function () -- 返回一个闭包函数,这个就是要更新替换后的原型
index = index + 1
print(index)
end
- 最后,再看看 hotfix.lua:
-- hotfix.lua
local hotfix = {
}
local function collect_uv(f, uv)
local i = 1
while true do
local name, value = debug.getupvalue(f, i)
if name == nil then -- 当所有上值收集完时,跳出循环
break
end
if not uv[name] then
uv[name] = {
func = f, index = i } -- 这里就会收集到旧函数 print_index 所有的上值,包括变量 index
if type(value) == "function" then
collect_uv(value, uv)
end
end
i = i + 1
end
end
local function update_func(f, uv)
local i = 1
while true do
local name, value = debug.getupvalue(f, i)
if name == nil then -- 当所有上值收集完时,跳出循环
break
end
-- value 值为空,并且这个 name 在 旧的函数中存在
if not value and uv[name] then
local desc = uv[name]
-- 将新函数 f 的第 i 个上值引用旧模块 func 的第 index 个上值
debug.upvaluejoin(f, i, desc.func, desc.index)
end
-- 只对 function 类型进行递归更新,对基本数据类型(number、boolean、string) 不管
if type(value) == "function" then
update_func(value, uv)
end
i = i + 1
end
end
function hotfix.update(old, new)
local uv = {
}
collect_uv(old, uv)
update_func(new, uv)
end
return hotfix
- 这个用到了 lua 的两个 api 函数,在 Lua 5.3 参考手册 中有介绍。
debug.getupvalue (f, up)
此函数返回函数 f 的第 up 个上值的名字和值。 如果该函数没有那个上值,返回 nil 。
debug.upvaluejoin (f1, n1, f2, n2)
让 Lua 闭包 f1 的第 n1 个上值 引用 Lua 闭包 f2 的第 n2 个上值。
- 我们可以看到, hotfix.lua 做的事也是比较简单的,主要是收集 旧函数的所有上值,更新到新函数中。最后一步替换旧函数是在 main.lua 中完成。
- 最后看看运行结果:
[root@instance test]# lua main.lua
before hotfix
0
0
0
0
0
after hotfix
1
2
3
4
5
-------------
show: 5
4.Lua脚本热更新方案
-
热更新,通俗点说就是补丁,玩家那边知道重启客户端就可以更新到了的,不用卸载重新安装app,相对于单机游戏,这也是网络游戏用得比较多的一个东西吧。
-
首先,大概流程如下:
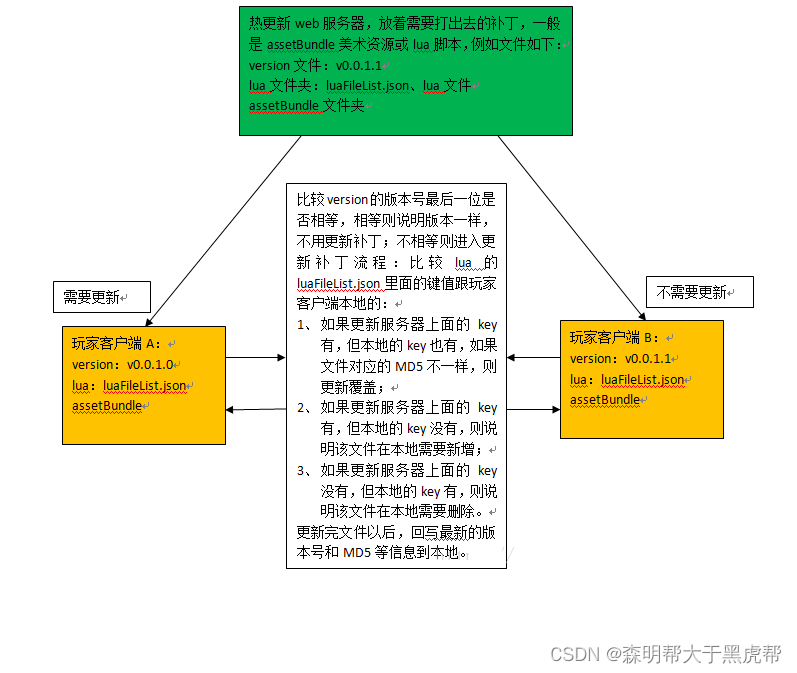
-
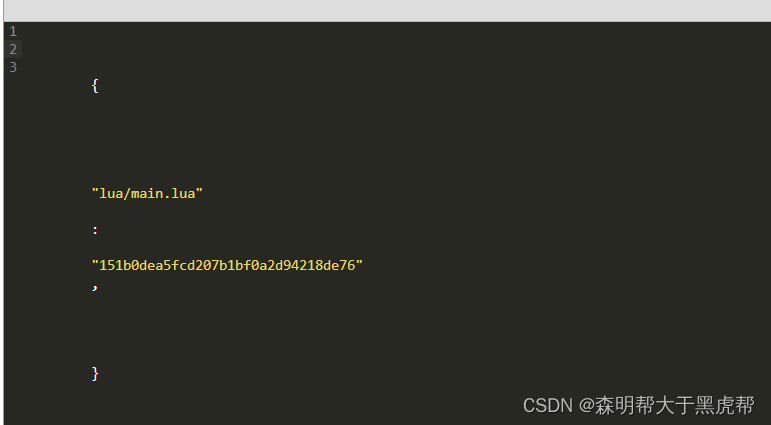
luaFileList.json文件内容一般是lua文件的键值对,key为lua文件路径+文件名,value为MD5值:
5.lua热更新
1.什么是热更新
- 热更新也叫不停机更新,是在游戏服务器运行期间对游戏进行更新。实现不停机修正bug、修改游戏数据等操作。也可以这样讲:一辆车以时速150km跑着,突然爆胎了,然后司机告诉你,我不停车,你去把轮胎换了,小心点。恩
2.热更新原理第一种:
-
lua中的require会阻止多次加载相同的模块。所以当需要更新系统的时候,要卸载掉响应的模块。(把package.loaded里对应模块名下设置为nil,以保证下次require重新加载)并把全局表中的对应的模块表置 nil 。同时把数据记录在专用的全局表下,并用 local 去引用它。初始化这些数据的时候,首先应该检查他们是否被初始化过了。这样来保证数据不被更新过程重置。
-
代码示例:

function reloadUp(module_name)
package.loaded[modulename] = nil
require(modulename)
end
- 这种做法简单粗暴,虽然能完成热更新,但是 问题很多,旧的引用的模块无法得到更新,这种程度的热更新显然不能满足现在的游戏开发需求。
3.热更新原理第二种:
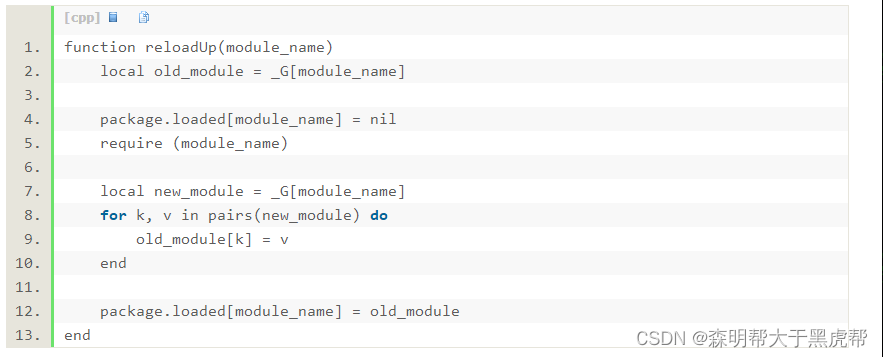
function reloadUp(module_name)
local old_module = _G[module_name]
package.loaded[module_name] = nil
require (module_name)
local new_module = _G[module_name]
for k, v in pairs(new_module) do
old_module[k] = v
end
package.loaded[module_name] = old_module
end
十四、Lua协同程序
1.lua协同程序初阶
Lua 协同程序(coroutine)与线程(这里的线程指的是操作系统的线程)比较类似: 拥有独立的堆栈,独立的局部变量,独立的指令指针,同时又与其它协同程序共享全局变量和其它大部分东西。
一个多线程程序可以同时运行几个线程(并发执行、抢占)。而协程却需要彼此协作地运行,并非真正的多线程,即一个多协程程序在同一时间只能运行一个协程,并且正在执行的协程只会在其显式地要求挂起(suspend)时,它的执行才会暂停(无抢占、无并发)。协同程序有点类似同步的多线程,在等待同一个线程锁的几个线程有点类似协同程序。
协程的用法:

coroutine.running就可以看出来,coroutine在底层实现就是一个线程,当create一个coroutine的时候就是在新线程中注册了一个事件。
resume和yeildr的协作是Lua协程的核心。
举一个经典生产者消费者例子:创建一个生产工厂,让它生产20件产品,每生产一件就把协程挂起,等待客户下一次提交需求的时候才重新resume唤醒。
local newProductor
function productor()
local i = 0
while true do
i = i + 1
send(i) -- 将生产的物品发送给消费者
end
end
function consumer()
local i = receive()
while i < 20 do
print(i)
i = receive()
end
end
function receive()
-- 唤醒程序
local status, value = coroutine.resume(newProductor)
return value
end
function send(x)
coroutine.yield(x) -- x表示需要发送的值,值返回以后,就挂起该协同程序
end
-- 创建生产工厂
newProductor = coroutine.create(productor)
consumer()
测试结果:
<font size=4 color=blue协程的作用:
我作为服务器,其实一直都是单线程开发的,对于多线程,协程这些为何存在一直不太理解,知道查阅了这篇博客稍微的了解一些:协程的好处是什么?
一开始大家想要同一时间执行那么三五个程序,大家能一块跑一跑。特别是UI什么的,别一上计算量比较大的玩意就跟死机一样。于是就有了并发,从程序员的角度可以看成是多个独立的逻辑流。内部可以是多cpu并行,也可以是单cpu时间分片,能快速的切换逻辑流,看起来像是大家一块跑的就行。
但是一块跑就有问题了。我计算到一半,刚把多次方程解到最后一步,你突然插进来,我的中间状态咋办,我用来储存的内存被你覆盖了咋办?所以跑在一个cpu里面的并发都需要处理上下文切换的问题。进程就是这样抽象出来个一个概念,搭配虚拟内存、进程表之类的东西,用来管理独立的程序运行、切换。
后来一电脑上有了好几个cpu,好咧,大家都别闲着,一人跑一进程。就是所谓的并行。
因为程序的使用涉及大量的计算机资源配置,把这活随意的交给用户程序,非常容易让整个系统分分钟被搞跪。所以核心的操作需要陷入内核(kernel),切换到操作系统,让老大帮你来做。
有的时候碰着I/O访问,阻塞了后面所有的计算。空着也是空着,老大就直接把CPU切换到其他进程,让人家先用着。当然除了I\O阻塞,还有时钟阻塞等等。一开始大家都这样弄,后来发现不成,太慢了。为啥呀,一切换进程得反复进入内核,置换掉一大堆状态。进程数一高,大部分系统资源就被进程切换给吃掉了。后来搞出线程的概念,大致意思就是,这个地方阻塞了,但我还有其他地方的逻辑流可以计算,这些逻辑流是共享一个地址空间的,不用特别麻烦的切换页表、刷新TLB,只要把寄存器刷新一遍就行,能比切换进程开销少点。
如果我们不要这些功能了,我自己在进程里面写一个逻辑流调度的东西,碰着i\o我就用非阻塞式的。那么我们即可以利用到并发优势,又可以避免反复系统调用,还有进程切换造成的开销,分分钟给你上几千个逻辑流不费力。这就是协程。
本质上协程就是用户空间下的线程。
2.lua协同程序进阶
1.什么是协程
Lua 协同程序(coroutine)与线程(这里的线程指的是操作系统的线程)比较类似: 拥有独立的堆栈,独立的局部变量,独立的指令指针,同时又与其它协同程序共享全局变量和其它大部分东西。
一个多线程程序可以同时运行几个线程(并发执行、抢占)。而协程却需要彼此协作地运行,并非真正的多线程,即一个多协程程序在同一时间只能运行一个协程,并且正在执行的协程只会在其显式地要求挂起(suspend)时,它的执行才会暂停(无抢占、无并发)。协同程序有点类似同步的多线程,在等待同一个线程锁的几个线程有点类似协同程序。
2.协程&线程的作用
一开始大家想要同一时间执行那么三五个程序,大家能一块跑一跑,于是就有了并发。
但是一块跑就有问题了。我计算到一半,刚把多次方程解到最后一步,你突然插进来,我的中间状态咋办,我用来储存的内存被你覆盖了咋办?所以跑在一个cpu里面的并发都需要处理上下文切换的问题。进程就是这样抽象出来个一个概念,搭配虚拟内存、进程表之类的东西,用来管理独立的程序运行、切换。
后来一电脑上有了好几个cpu,好咧,大家都别闲着,一人跑一进程。就是所谓的并行。
有的时候碰着I/O访问,阻塞了后面所有的计算。空着也是空着,老大就直接把CPU切换到其他进程,让人家先用着。当然除了I\O阻塞,还有时钟阻塞等等。一开始大家都这样弄,后来发现不成,太慢了。为啥呀,一切换进程得反复进入内核,置换掉一大堆状态。进程数一高,大部分系统资源就被进程切换给吃掉了。后来搞出线程的概念,大致意思就是,这个地方阻塞了,但我还有其他地方的逻辑流可以计算,这些逻辑流是共享一个地址空间的,不用特别麻烦的切换页表、刷新TLB,只要把寄存器刷新一遍就行,能比切换进程开销少点。
比如在进程里面写一个逻辑流调度的东西,碰着i\o我就用非阻塞式的(比如在加载资源时,我们可以做一些初始化场景的逻辑)。 那么我们就避免反复系统调用,还有进程切换造成的开销,分分钟给你上几千个逻辑流不费力。这就是协程。
3.lua中协程的调用
Lua语言中协程相关的所有函数都被放在全局表coroutine中。
1.coroutine.create()创建协程
我们可以简单的通过coroutine.create()来创建一个协程,该函数只有一个参数即协程要执行的代码的函数(函数体body),然后把创建出来的协程返回给我们。
local coA = coroutine.create(function()
print("hello coroutine")
end)
print(type(coA)) -- 输出字符串thread
2.coroutine.status()协程状态
一个协程有以下四种状态:既挂起(suspended),运行(running),正常(normal),死亡(dead)。我们可以通过coroutine.status()来输出协程的当前状态。
当协程被create出来时,它处在挂起的状态,被唤醒之后会处在运行状态,当协程A唤醒协程B时协程A从运行转换成正常状态,当唤醒成功之后转化为挂起状态。而当整个协程体执行完毕的时候,协程处于死亡状态。
我们可以在coroutine表中找到相关定义:

3.resume和yeild
resume和yeildr的协作是Lua协程的核心,coroutine.resume()把挂起态的协程唤醒,第一个参数是唤醒的协程,之后的参数传给协程体和作为yeild的返回值。coroutine.yeild()把运行态的协程挂起,参数作为resume的返回值。
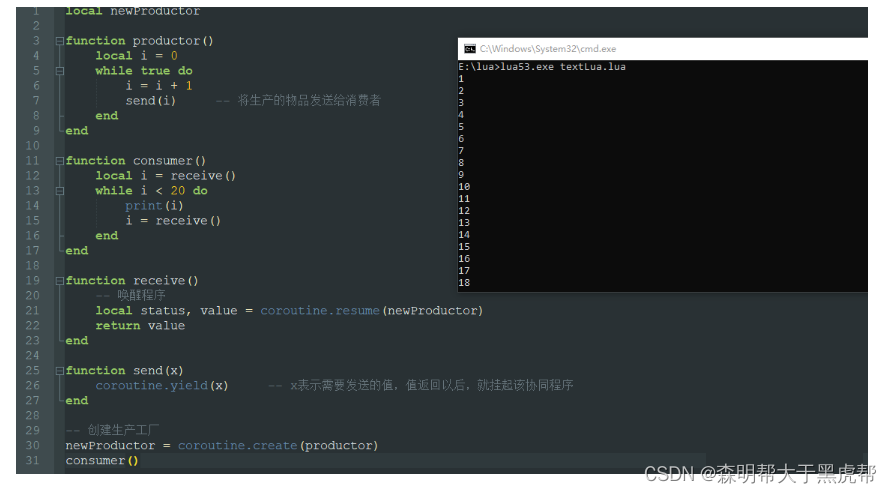
经典生产者消费者例子:创建一个生产工厂,让它生产10件产品,每生产一件就把协程挂起,等待客户下一次提交需求的时候才重新resume唤醒。
local newProductor
-- 生产者
function productor()
local i = 0
while true do
i = i + 1
send(i) -- 将生产的物品发送给消费者
end
end
-- 消费者
function consumer()
local i = receive()
while i <= 10 do
print("生产第"..i.."件商品")
i = receive()
end
end
-- 接受
function receive()
-- 唤醒程序
local status, value = coroutine.resume(newProductor) -- 第一个协程的状态为true时则证明唤醒成功
return value
end
-- 发送
function send(x)
coroutine.yield(x) -- yield的参数作为resume的返回值
end
-- 创建生产工厂
newProductor = coroutine.create(productor)
consumer()
测试结果:

以上的设计称为消费者驱动式的设计,其中生产者是协程,消费者需要使用时才唤醒生产者。同样的我们可以设计消费者为协程,由生产者唤醒的生产者驱动设计。
4.通过协程实现异步I/O
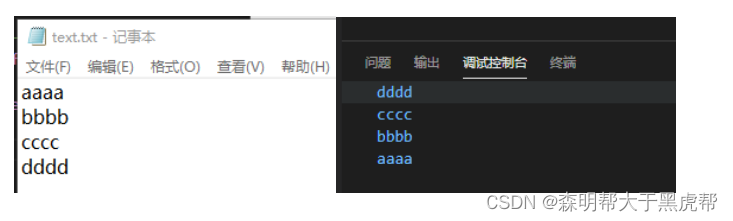
一般的同步IO(读取文件内容,逆序输出)。
local t = {
}
local inp = io.input("text.txt")
local out = io.output()
-- 读取文件中的内容
for line in inp:lines() do
t[#t + 1] = line
end
-- 逆序输出
for i = #t, 1, -1 do
out:write(t[i], "\n")
end
测试结果:
使用异步I/O的方式实现:首先,把读写循环的逻辑抽象出来。使用一个命令队列存放读写的逻辑,若未读取完毕则继续读取,若读取完毕,则进行输出。直至输出完所有的信息之后,则结束逻辑。
local cmdQueue = {
}
local lib = {
}
-- 读
lib.readLine = function(stream, callback)
local nextCmd = function()
callback(stream:read())
end
table.insert(cmdQueue, nextCmd)
end
-- 写
lib.writeLine = function(stream, line, callback)
local nextCmd = function()
stream:write(line)
callback()
end
table.insert(cmdQueue, nextCmd)
end
-- 停止
lib.stop = function()
table.insert(cmdQueue, "stop")
end
-- 执行
lib.runLoop = function()
while true do
local nextCmd = table.remove(cmdQueue, 1)
if not nextCmd or nextCmd == "stop" then
break
end
nextCmd()
end
end
return lib
然后,把整个读取的流程编写成一个协程。其中每次进行读写时把协程挂起,当读写完一行之后,则通过回调重新唤醒,从而实现异步I/O。输出的结果是一样的,但若碰到IO阻塞,我们就可以愉快地调用其他协程避免阻塞啦。
local lib = require "asyncLib"
-- 创建协程
local run = function(func)
local coFunc = coroutine.wrap(function()
func()
lib.stop()
end)
coFunc()
lib.runLoop()
end
local putline = function(stream, line)
local co = coroutine.running()
local callback = function()
coroutine.resume(co)
end
lib.writeLine(stream, line, callback)
coroutine.yield()
end
local getLine = function(stream)
local co = coroutine.running()
local callback = function(line)
coroutine.resume(co, line)
end
lib.readLine(stream, callback)
local line = coroutine.yield()
return line
end
-- 调用
run(function()
local t = {
}
local inp = io.input("text.txt")
local out = io.output()
while true do
local line = getLine(inp)
if not line then break end
t[#t + 1] = line
end
for i = #t, 1, -1 do
putline(out, t[i].."\n")
end
end)
十五、Lua垃圾回收机制
在 Lua 中,一共只有8种数据类型,分别为 nil 、boolean 、userdata 、number 、string 、 table 、 function 、 userdata 和 thread 。其中,只有 string table function thread 四种是以引用方式共享,是需要被 GC 管理回收的对象。
Lua采用的是Mark-sweep算法。
1.mark阶段
这个阶段叫做扫描阶段。简单来讲,就是对于现在lua用到的所有对象进行扫描一次。如果某个对象当前跟别的对象有引用关系,那么说明他还在用;如果某个对象跟其他任何对象都没有引用关系了,说明这个对象已经没有用了。这个阶段做完,就可以知道哪些对象还有用,哪些对象不再使用了,下面就交给下一个阶段,sweep阶段。
2.cleaning阶段
这个阶段lua会出里对象的析构和弱引用表,它会遍历标记需要析构的对象,以及遍历弱引用表将要移除的键或者值。
3.sweep阶段
这个阶段做的事情其实很少,关键步骤在前一个阶段做完了。这个阶段根据前一个扫描阶段得到的结果,遍历一遍所有对象。如果这个对象已经标记为不再使用了,就会被清理掉,释放掉所在的内存;如果这个对象还在使用,那么就处理一下状态,等待下一次gc在处理。
4.finalization析构
对标记需要析构的对象进行析构。
这里添加一下对弱表的介绍:若一个存放在表中,那么哪怕这个对象没有被任何地方引用,但是也不会被清除,因为此时这个对象就正在被这个表引用。为了解决这个问题可以在表中的__mode字段来定义该表是一个弱表,那么在GC的时候才会把它给回收掉
__mode = “k” – 代表这个表中的键是弱引用的弱引用表
__mode = “v” – 代表这个表中的值是弱引用的弱引用表
__mode = “kv” – 代表这个表中的键值都是弱引用的弱引用表
无论哪一种情况,只要其中一个键或者值被回收了,那么整个键值对就会被回收,这和我们把变量置位nil其实是将它 删除的原理是一样的。
5.缺陷
在lua5.0之前,早期的 Lua GC 采用的是 stop the world 的实现。一旦发生 gc 就需要等待整个 gc 流程走完。(STW: 在垃圾回收期间除了垃圾回收器线程,其他线程都会被挂起)。
如果mark阶段一次性把所有节点都扫描,再一次性清理完,那么这两个步骤就都很简单了。但是,这样就有效率问题,一次性要把所有对象处理一遍,在大工程里面就绝对是一个瓶颈。
所以,lua5.0以后就把gc改成了增量式的gc,主要是把标记扩展成了三种颜色,下面详细介绍一下。
我们可以将所有对象分成三个状态:
White状态,也就是待访问状态。表示对象还没有被垃圾回收的标记过程访问到。
Gray状态,也就是待扫描状态。表示对象已经被垃圾回收访问到了,但是对象本身对于其他对象的引用还没有进行遍历访问。
Black状态,也就是已扫描状态。。表示对象已经被访问到了,并且也已经遍历了对象本身对其他对象的引用。
将root集合引用到的对象从White设置成Gray,并放到Gray集合中;
while(Gray集合不为空,并且没有超过本次计算量的上限)
{
从Gray集合中移除一个对象O,并将O设置成Black状态;
for(O中每一个引用到的对象O1) {
if(O1在White状态) {
将O1从White设置成Gray,并放到到Gray集合中;
}
}
}
for(任意一个对象O){
if(O在White状态)
销毁对象O;
else
将O设置成White状态;
}
但是由于垃圾回收的过程变成分步的话,那么我们之前已经标注到的状态就可能会发生改变,此时lua提供了屏障barrier在程序正常运行过程中,监控所有的引用改变,然后更换对象的状态。
十六、Lua和C相互调用
lua和c/c++之间是通过lua_Stack 进行交互的,里面通过举出两个例子分别从lua调用c,然后从c调用lua,然后再通过例子来引出讲解lua_Stack中的全局状态机global_stack,数据栈,调用栈等知识。
1.实例lua调用capi
今天是要和大家分享关于luaDebug库的一些内容,但是我在研究luaDebug库的时候,发现它调用了许多的luaAPI,对于没有研究过lua与c/c++交互的我可以说是看到满头大汉,一脸懵逼。所以我就决定从最原始入手,研究lua和c/c++是如何相互调用。今天分享的流程主要是通过举两个c++和lua相互调用的栗子,然后研究底层的实现,紧接着对我们的lua_debug库进行介绍,最后再尝试打印一些堆栈信息。
大家都知道,lua和c/c++之间是通过一个lua_Stack进行交互的,关于lua_Stack,网上对它的叫法有很多,有的说它是一个lua的堆栈,有的说它是lua状态机,也有的将它叫做lua的线程(注意这里的thread是lua的一种数据类型,与操作系统的线程需要区分开),我们可以简单的把lua_Stack当作一个翻译官,负责在c/c++与lua之间翻译,把正确的信息保存并传达给对方。
1.看两个小栗子
要让lua文件与c/c++文件进行交互有两种方式:
- 其一是把我们的CAPI给打包成一个动态链接库dll,然后在运行的时候再加载这些函数。
- 其二是把CAPI给编译到exe文件中。为了方便,以下是测试例子使用的是编译成一个exe文件的方式,准备步骤分三步:
- 新建一个c++控制台项目。
- 下载lua源码,把src目录下的所有文件拷贝到新建的c++目录下。
- include需要用到的lua库函数,生成解决方案即可。
extern "C" {
#include "lua.h"
#include "lualib.h"
#include "lauxlib.h"
}
需要注意的是,因为我们创建的是c++的程序(cocos,u3d,ue4的底层都是c++代码),但是lua的库函数中使用的是纯c的接口,所以我们要extern "C"让编译器帮我们修改一下函数的编译和连接规约。
extern关键字:
my.cpp文件
//
#include "my.h"
CMyWinApp theApp; // 声明和定义了一个全局变量
//------------------------------------------------------------------
// main
//------------------------------------------------------------------
int main()
{
CWinApp* pApp = AfxGetApp();
return 0;
}
//------------------------------------------------------------------
MFC.cpp
#include "my.h" // it should be mfc.h, but for CMyWinApp definition, so...
extern CMyWinApp theApp; // 提示编译器此变量定义在其他文件中,遇到这个变量时到其他模块中去寻找
CWinApp* AfxGetApp()
{
return theApp.m_pCurrentWinApp;
}
extern可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义。
extern C用法:
典型的,一个C++程序包含其它语言编写的部分代码。类似的,C++编写的代码片段可能被使用在其它语言编写的代码中。不同语言编写的代码互相调用是困难的,甚至是同一种编写的代码但不同的编译器编译的代码。例如,不同语言和同种语言的不同实现可能会在注册变量保持参数和参数在栈上的布局,这个方面不一样。
为了使它们遵守统一规则,可以使用extern指定一个编译和连接规约。例如,声明C和C++标准库函数strcyp(),并指定它应该根据C的编译和连接规约来链接:
extern "C" char* strcpy(char*,const char*);
extern "C"指令中的C,表示的一种编译和连接规约,而不是一种语言。C表示符合C语言的编译和连接规约的任何语言,如Fortran、assembler等。
还有要说明的是,extern "C"指令仅指定编译和连接规约,但不影响语义。例如在函数声明中,指定了extern “C”,仍然要遵守C++的类型检测、参数转换规则。
如果你有很多语言要加上extern “C”,你可以将它们放到extern “C”{ }中。
extern "C"{
typedef int (*CFT) (const void*,const void*);//style of C
void qsort(void* p,size_t n,size_t sz,CFT cmp);//style of C
}
extern "C"的真实目的是实现类C和C++的混合编程。在C++源文件中的语句前面加上extern “C”,表明它按照类C的编译和连接规约来编译和连接,而不是C++的编译的连接规约。这样在类C的代码中就可以调用C++的函数or变量等。(注:我在这里所说的类C,代表的是跟C语言的编译和连接方式一致的所有语言)
1.创建lua_Stack
前文提及lua_Stack是c/c++与lua的翻译官,所以在它们交互之前我们首先需要生成一个lua_Stack:
lua_State *L = luaL_newstate();
然后我们需要打开lua给我们提供的标准库:
luaL_openlibs(L);
其实lua早已经在我们不经意间调用了c的api。
2.第一个栗子:c++调用lua的函数
我们首先需要新建一个lua文件,名称随意我这里使用的是luafile.lua。然后我们在lua文件中定义一个function,举一个最简单的减法吧。
然后就是使用luaL_dofile方法让我们的lua_Stack编译并执行这个文件,我们在打lua引用其他文件的时候知道loadfile是只编译,dofile是编译且每次执行,require是在package.loaded中查找此模块是否存在,不存在才执行,否则返回该模块。luaL_dofile和luaL_loadfile和上述原理相似,luaL_loadfile是仅编译,luaL_dofile是编译且执行。
然后通过lua_getglobal方法可以通过lua的全局表拿到lua的全局函数,并将它压入栈底(我们可以把lua_Stack的存储结构理解为下图的样子,实际上肯定没有那么简单,我们往下看)。
lua数据栈的抽象图:
我们可以通过两种索引来获取lua_Stack的调用栈所指向的数据:
static TValue *index2addr (lua_State *L, int idx) {
CallInfo *ci = L->ci;
if (idx > 0) {
TValue *o = ci->func + idx;
api_check(L, idx <= ci->top - (ci->func + 1), "unacceptable index");
if (o >= L->top) return NONVALIDVALUE;
else return o;
}
else if (!ispseudo(idx)) {
/* negative index */
api_check(L, idx != 0 && -idx <= L->top - (ci->func + 1), "invalid index");
return L->top + idx;
}
else if (idx == LUA_REGISTRYINDEX)
return &G(L)->l_registry;
else {
/* upvalues */
idx = LUA_REGISTRYINDEX - idx;
api_check(L, idx <= MAXUPVAL + 1, "upvalue index too large");
if (ttislcf(ci->func)) /* light C function? */
return NONVALIDVALUE; /* it has no upvalues */
else {
CClosure *func = clCvalue(ci->func);
return (idx <= func->nupvalues) ? &func->upvalue[idx-1] : NONVALIDVALUE;
}
}
}
然后把两个参数按顺序压入栈中(不同类型压栈的函数接口大家可以查阅文档),然后调用pcall函数执行即可:
/* c++调用lua函数 */
luaL_dofile(L, "luafile.lua");
lua_getglobal(L, "l_sub");
lua_pushnumber(L, 1);
lua_pushnumber(L, 2);
lua_pcall(L, 2, 1, 0);
cout << lua_tostring(L, 1) << endl;
为了更方便看出栈中的数据,我写了个函数,遍历输出栈中所有的数据。
static int stackDump(lua_State *L)
{
int i = 0;
int top = lua_gettop(L); // 获取栈中元素个数。
cout << "当前栈的数量:" << top << endl;
for (i = 1; i <= top; ++i) // 遍历栈中每个元素。
{
int t = lua_type(L, i); // 获取元素的类型。
switch (t)
{
case LUA_TSTRING: // strings
cout << "参数" << i << " :" << lua_tostring(L, i);
break;
case LUA_TBOOLEAN: // bool
cout << "参数" << i << " :" << lua_toboolean(L, i) ? "true" : "false";
break;
case LUA_TNUMBER: // number
cout << "参数" << i << " :" << lua_tonumber(L, i);
break;
default: // other values
cout << "参数" << i << " :" << lua_typename(L, t);
break;
}
cout << " ";
}
cout << endl;
return 1;
}
然后我们再看看输出的结果:
因为c++比起lua更接近底层语言,编译速度更快,所以一般来讲c++调用lua的接口只是配置一些全局数据,传递一些触摸,点击事件给lua而已。
3.第二个栗子:lua调用c++的函数
来到今天关键的部分,就是lua调用c/c++的API。上一个栗子我们有提及,我们是通过全局表拿到lua的函数,那么我们要给lua传递一个函数,同样要通过这个全局表进行注册,然后才被lua进行调用。
void lua_register (lua_State *L, const char *name, lua_CFunction f);
- 流程分三步:
- 在c/c++中定义函数
- 注册在lua全局表中
- lua文件中调用
我们举一个简单加法的栗子:
static int c_add(lua_State *L)
{
stackDump(L);
double arg1 = luaL_checknumber(L, 1);
double arg2 = luaL_checknumber(L, 2);
lua_pushnumber(L, arg1 + arg2);
return 1;
}
...
int main() {
...
lua_register(L, "c_add", c_add);
}
注意这里的返回值并不是直接return答案,答案我们需要同样压入栈中,给lua_Stack这个翻译官"翻译",return的是答案的个数(lua支持多返回值)。
1.分析这两个栗子
我们回顾刚才的代码,一切的一切是从创建一个lua_Stack,也就是调用luaL_newstate()开始的。
LUALIB_API lua_State *luaL_newstate (void) {
lua_State *L = lua_newstate(l_alloc, NULL);
if (L) lua_atpanic(L, &panic);
return L;
}
可以看到luaL_newstate除了生成一个lua_Stack之外,还包装了一层错误预警,处理lua保护环境以外的报错,我们可以查阅以下文档lua_atpanic的作用。
我们继续往下看lua_newstate方法。
LUA_API lua_State *lua_newstate (lua_Alloc f, void *ud) {
int i;
lua_State *L;
global_State *g;
/* 分配一块lua_State结构的内容块 */
LG *l = cast(LG *, (*f)(ud, NULL, LUA_TTHREAD, sizeof(LG)));
if (l == NULL) return NULL;
L = &l->l.l;
g = &l->g;
L->next = NULL;
L->tt = LUA_TTHREAD;
g->currentwhite = bitmask(WHITE0BIT);
L->marked = luaC_white(g);
/* 初始化一个线程的栈结构数据 */
preinit_thread(L, g);
g->frealloc = f;
g->ud = ud;
g->mainthread = L;
g->seed = makeseed(L);
g->gcrunning = 0; /* no GC while building state */
g->GCestimate = 0;
g->strt.size = g->strt.nuse = 0;
g->strt.hash = NULL;
setnilvalue(&g->l_registry);
g->panic = NULL;
g->version = NULL;
g->gcstate = GCSpause;
g->gckind = KGC_NORMAL;
g->allgc = g->finobj = g->tobefnz = g->fixedgc = NULL;
g->sweepgc = NULL;
g->gray = g->grayagain = NULL;
g->weak = g->ephemeron = g->allweak = NULL;
g->twups = NULL;
g->totalbytes = sizeof(LG);
g->GCdebt = 0;
g->gcfinnum = 0;
g->gcpause = LUAI_GCPAUSE;
g->gcstepmul = LUAI_GCMUL;
for (i=0; i < LUA_NUMTAGS; i++) g->mt[i] = NULL;
if (luaD_rawrunprotected(L, f_luaopen, NULL) != LUA_OK) {
//f_luaopen函数中调用了 stack_init 函数
/* memory allocation error: free partial state */
close_state(L);
L = NULL;
}
return L;
}
- lua_newstate主要做了3件事情:
- 新建一个global_state和一个lua_State。
- 初始化默认值,创建全局表等。
- 调用f_luaopen函数,初始化栈、字符串结构、元方法、保留字、注册表等重要部件。
- 全局状态机global_state:
- global_State 里面有对主线程的引用,有注册表管理所有全局数据,有全局字符串表,有内存管理函数,有GC 需要的把所有对象串联起来的相关信息,以及一切 lua 在工作时需要的工作内存。我们以为的是c/c++ 和 lua之间只通过一个翻译官lua_Stack,但其实还有一个负责数据存放,回收的翻译公司global_State,客户只需要直接和翻译官打交道,但是一些翻译档案还是要翻译公司存放管理。
- lua线程lua_State:
- lua_State是暴露给用户的数据类型,是一个lua程序的执行状态,也是lua的一个线程thread。大致分为4个主要模块,分别是独立的数据栈StkId,数据调用栈CallInfo ,独立的调试钩子以及错误处理机制。而在调用栈中我们就可以通过func域获得所在函数的源文件名,行号等诸多调试信息。
- f_luaopen函数:
- f_luaopen函数,非常重要,主要作用:初始化栈、初始化字符串结构、初始化原方法、初始化保留字实现、初始化注册表等。
static void f_luaopen (lua_State *L, void *ud) {
global_State *g = G(L);
UNUSED(ud);
stack_init(L, L); /* init stack */
init_registry(L, g); //初始化注册表
luaS_init(L); //字符串结构初始化
luaT_init(L); //元方法初始化
luaX_init(L); //保留字实现
g->gcrunning = 1; /* allow gc */
g->version = lua_version(NULL);
luai_userstateopen(L);
可以先看看注册表是怎么样初始化的:会把当前的线程设置为注册表的第一个元素,全局表设置位第二个元素。
static void init_registry (lua_State *L, global_State *g) {
TValue temp;
/*创建注册表,初始化注册表数组部分大小为LUA_RIDX_LAST*/
Table *registry = luaH_new(L);
sethvalue(L, &g->l_registry, registry);
luaH_resize(L, registry, LUA_RIDX_LAST, 0);
/*把这个注册表的数组部分的第一个元素赋值为主线程的状态机L*/
setthvalue(L, &temp, L); /* temp = L */
luaH_setint(L, registry, LUA_RIDX_MAINTHREAD, &temp);
/*把注册表的数组部分的第二个元素赋值为全局表,即registry[LUA_RIDX_GLOBALS] = table of globals */
sethvalue(L, &temp, luaH_new(L)); /* temp = new table (global table) */
luaH_setint(L, registry, LUA_RIDX_GLOBALS, &temp);
}
在得到一个初始化后的lua_Stack之后,要想lua能拿到CAPI,我们会对c/c++的函数进行注册。
lua_register(L, "c_add", c_add);
那么我们继续往下看看究竟这个函数做了什么。
#define lua_register(L,n,f) (lua_pushcfunction(L, (f)), lua_setglobal(L, (n)))
分成两部分:首先把c/c++的函数弄成一个闭包push到lua_Stack数据栈中,判断是否溢出并对栈顶元素自增,然后就是把这个函数给注册在注册表中。
LUA_API void lua_setglobal (lua_State *L, const char *name) {
Table *reg = hvalue(&G(L)->l_registry);
lua_lock(L); /* unlock done in 'auxsetstr' */
// LUA_RIDX_GLOBALS是全局环境在注册表中的索引
auxsetstr(L, luaH_getint(reg, LUA_RIDX_GLOBALS), name);
}
我们知道lua把所有的全局表里存放在一个_G的表中,而LUA_RIDX_GLOBALS就是全局环境在注册表中的索引。至此我们就把我们的c/c++的API注册在lua的全局表中,所以lua文件中就能访问到该函数了。
十七、Lua的一些实例测试
(1) 字符串把“abc”,换成“bcd”
local str ="abcdefgh";
b = string.gsub(str, "%abc", "ddc");
str = b;
print(str);
(2) if的使用方法
If 条件 then
语句1
Else
语句2
end
(3) 如何对表中元素排序后输出
从小到大
Table.sort(表名)
For k,v inipairs(table)
Print(k,v)
End
从大到小
Table.Sort(a)
For i=1,#a,1 do
b[i] =a[#a-i+1]
end
(4) 写一个返回多值的函数
function foo2 ()
return 'a','b'
end
返回的值之间用逗号隔开
(5) 写一个可变参数得函数
Function foo(…)
Retrun #{
…}
End
…是可变参数的意思,上述函数等价于select(#,…)
我们还可以通过select(n,。。。)找到第n个参数
十八、lua的命名规范以及注释方法
1.lua命名规范
lua和C/C++一样,允许我们使用数字,下划线,字母任意组合成为变量的名称。
- 但是要注意以下几点:
- 1. 数字不能作为开头
- 2.下划线加英文大写单词一般是lua系统自己使用的,我们应该尽量避免使用
- 3.lua的一些保留字,如if,for,return,break等不能使用
- 4.lua命名是大小写敏感的,所以And和AND是不一样的变量
2.lua注释方式
lua使用 – 来进行单行的注释
使用–[[
长注释
]] 来进行长注释
十九、lua条件与循环
1.条件选择语句if
lua里面是这样实现条件选择语句的:
if + 条件 + then + 执行语句 + end
if a < 0 then
a = a + 2
end
else if a >= 0 then
return a
end
上述例子我们可以使用elseif来实现:
if a < 0 then
a = a + 2
elseif a >= 0 then
return a
end
此时我们比之前的例子就少写了一个end,如果要多次elseif就省略了多个end,比较方便。
2. while循环语句
语法:while + 循环条件 + do + 循环体 + end
while i < 10 do
i = i + 1
end
3. repeat…until循环语句
语法:repeat + 循环体 + until + 终止条件
repeat
i = i + 1
until i >=10
4. for循环语句
语法:for var = exp1,exp2,exp3 do 循环体 end
exp1是初始值,exp2是终止值,exp3是步长,步长也就是我们每一次循环后var要增加或减少多少,若不写则默认为1。
问题来了:加入我初始值小于终止值,且步长为负程序会如何?
答: 此时它们会执行一次循环体结束循环。
回顾一下我们之前的pairs和ipairs:
for k,v in pairs(table) do
print(k,v) -- 输出的是键值对,是映射,nil也会输出但是顺序可能会乱
end
for k,v in ipairs(table) do
print(k,v) -- 输出的是序列,顺序不乱遇到空值则停下
end
5.提前结束循环
1.break: 直接结束这一重循环。
2.return: 返回值后直接结束所有循环。
3.continue: 结束当重当次的循环。
4.goto: 转移去标签的位置,标签的语法::标签名 : : – 记得慎用。
二十、lua代码优化,别再依赖if…else了
今天讲解一下我在工作中遇到的代码优化问题。需求是这样的:我需要在项目的通用资源弹窗中加入一个新的资源道具,但是以前的通用弹窗道具可以换算成元宝,有自己的容量。但是新的道具是“英雄经验”是没有上述的属性的,所以有部分的逻辑是不适用于新增的道具,因此我一开始的处理方式是直接在各个判断的逻辑中加入if,else。只要展示的道具是英雄经验的话,则不执行那部分不适用的逻辑判断。写的代码又臭又长,但是没办法,只能硬着头皮递交上去。下面是我提交的部分代码:
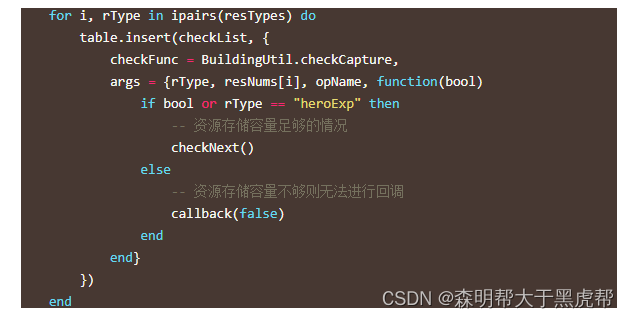
反正就是见招拆招,用ifelse来跳过所有的不合适的逻辑判断,整个项目下来,功能没改多少,ifelse多了十几个,然后原本大佬前辈们写出的优雅简洁的代码就被我破坏了。果不其然上交之后,主管找我谈话了,他问我,如果后面再多加几个资源,你是不是一直在后面加ifelse?这样的代码可读性和修改起来是不是很麻烦?
如果对于一些通用的资源,适合所有逻辑的,则按照以前的程序走,对于新增不合适的,我们则执行简略的逻辑,跳过某些判断。
听到这里,难道是要对资源分成两类,然后进行两套的逻辑判断吗?我于是问主管是不是传参,区分两类的资源,然后执行不同的逻辑。主管高深莫测的说,非也,你还是太小看lua了。然后啪啦啪啦的写下了下面这段代码:
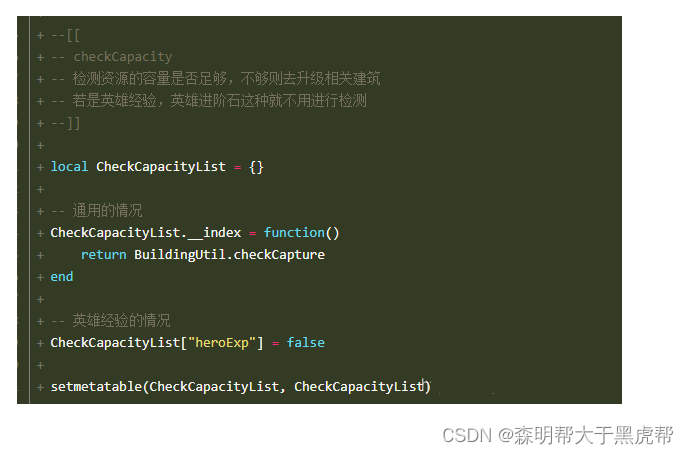
元表,居然是元表!!!主管把逻辑抽了出来,然后把抽出表中的__index字段定义成了通用的逻辑判断函数,然后特殊的就直接写进去,我们知道在lua的面向对象的流程执行的过程中,如果查找一个表的元素,找得到就返回该值,找不到则通过__index字段往他父类上找,以前我一直以为__index只能是一个表,结果原来是一个函数的话,程序会执行__index字段的函数,获取其返回值。所以说我们只需要把通用的逻辑执行函数写在__index字段中,而特殊的写出来,则巧妙的完成了需求,且可拓展性增强了许多。
说实话,这次的经历让我触动挺大的,从实习以来,自己就仿佛成为了一个ifelse,for循环的无脑机器。确实有很多优雅的写法需要我们去学习,不要无脑的为了完成需求而去完成需求。
二十一、lua数值型for和泛型for
可能有老哥这个时候就要吐槽了,纳尼!我写了那么久lua,你今天叫我怎么使用for?这不是愚蠢的妈妈给愚蠢开门–愚蠢到家了吗?? 诶确实我知道各位大牛都已经熟练使用for语句了, 但是知其然,然后知其所以然。今天就给大家分析分析for语句的底层逻辑。
-- 数值型
for i = 1, 10, 2 do
print(i)
end
-- 泛型
local tableA = {
1,2,3}
for key, value in ipairs(tableA) do
print(key)
print(value)
end
1.数值型for
数值型的for相对简单,如上述栗子,首先它会在循环体中生成这个i的局部变量,然后根据 起始数值,终止数值,步长来进行一个循环(1,10,2)。当我们想要执行最多次的循环(不是死循环)时,可以用 math.huge()来获取最大的循环次数。
值得一提的是:控制变量i实际上是一个局部变量,不可以在循环体外访问。以及步长可以不填,其默认值为1。
for i = 1, 3 do
print(i) -- 输出1,2,3
end
print(i) -- 输出nil
2.泛型for
泛型for在循环过程内保存了迭代器函数。它实际上保存着3个值:一个迭代器函数、一个恒定状态和一个控制变量。

-- 模板
for <var-list> in <exp-list> do
<body>
end
-- 实例
local tableA = {
1,2,3}
for key, value in ipairs(tableA) do
print(key)
print(value)
end
- 迭代器函数:就是在in后面的表达式,如上面的代码中,就是遍历ipairs的方法(iter后文有写)。
- 恒定状态:恒定状态就是不会在循环体中被影响的数据结构,实际上就是遍历的这个表。
- 控制变量:上述代码中的控制变量又key,value。它存放着迭代器函数返回的多返回值,若多于两个则舍弃多余的,少于两个则用nil补齐。当控制变量中的第一个,也就是key为nil时,那么就会退出循环体。
所以for的模板就等价于下面的代码:
-- 模板
for var_1, ..., var_n in <explist> do <block> end
-- 就等价于以下代码:
do
local _f, _s, _var = <explist> -- 返回迭代器函数、恒定状态和控制变量的初值
while true do
local var_1, ..., var_n = _f(_s, _var)
_var = var_1
if _var == nil then break end
<block>
end
end
end
所以使用ipairs进入循环的例子就等价于下面的代码:
function iter(tb,i)
i = i + 1
if nil == tb[i] then
return nil,nil
else
return i,tb[i]
end
end
function ipairs(tb)
return iter,tb,0
end
for i,v in ipairs(tb1) do
print(i,v)
end
pairs相类似,但是其迭代器函数直接使用了lua的基本函数next,所以其迭代其函数时next。
function pairs(tb)
return next,tb,nil
end
for k,v in pairs(tb2) do
print(k,v)
end
二十二、lua模式匹配
lua中模式匹配的问题,由于lua中没有正则表达式,那么它是如何实现模式匹配的呢。
模式匹配相关的函数:
string.find(),string.match(),string.gmatch(),string.gsub()
1.string.find()
string.find(原字符串,目标字符串)里面填入两个参数, 作用是从目源字符串中找到目标字符串的起始和终止索引,我们可以看看下面这个例子:
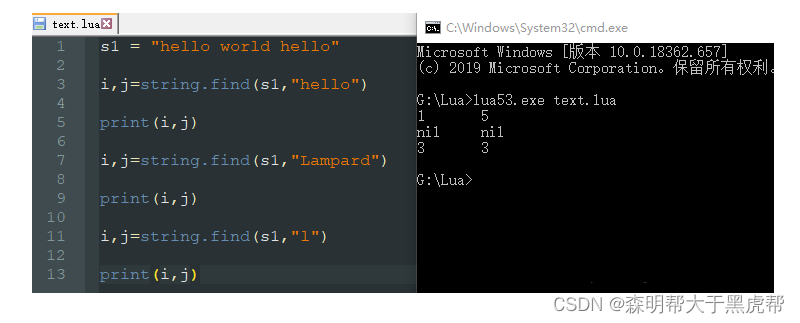
string.find()这个函数,能够找到目标字符串的起始位置和初始位置,但是只能返回第一个出现的目标字符串,若找不到目标,字符串则返回nil值。
2.string.match()
string.match()也同样在一个字符串中搜索模式,但是与string.find()不同的是,match返回的是字串本身。
-- 比如说我们这样做
s = “hello world”
s1 = string.match(s,"hello")
-- 那么此时s1就等于hello
是不是有人已经跟我一样准备吐槽了:这特码有啥用???
别急,match的强大之处是在于可以通过字符分类找到想找的答案,比如这样:
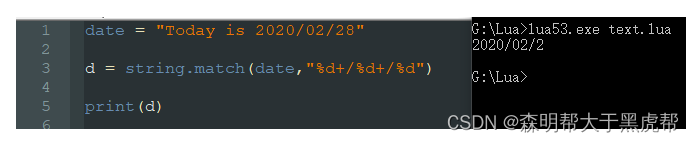
至于%d是个什么东西,我们往下继续说。
3.string.gmatch()
string.gmatch()语法和string.match()一样,但是返回的是一个函数。
我们在使用string.match()和string.find()的时候,找到的都是第一个出现的字符串。
但是加入我想把所有目的字符串都找出来呢?string.gmatch()就可以帮我们解决这个问题了。

其中%a是找到英文字符,%a+是找到所有连着的字符,%d我们上文的意义是找数字,%d+是找连着的数字。那么究竟还有哪一些规格呢?本书给了如下的表格:
. --任意字符
%a --字母
%c --控制字符
%d --数字
%l --小写字母
%g --除空格外的字符
%p --标点符号
%u --大写字符
%w --字母和数字
%x --十六进制数字
4.string.gsub()
string.gsub()这个函数我们之前接触过,它的作用是从原字符串中寻找目标字符串,然后将之改成想要的字符串。
语法:string.gsub(原字符串,目的字符串,更改后的字符串,更改的次数)。
其中参数四的作用是目的字符串要被更改的次数,比较少用,不使用时默认全部都要更改。
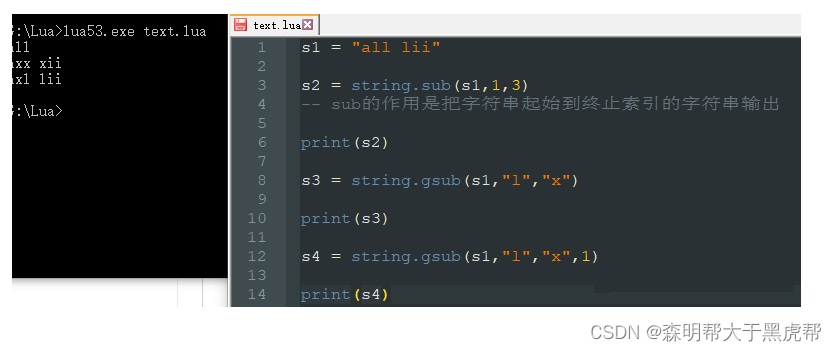
二十三、lua模式匹配练习
【【key1,value1】,【key2,value2】】这种存储结构的键值对取出来。
当时我冒出的想法是,先把它拆开小部分:先解决从【key1,value1】中提取键值对 。因为对库函数的不熟悉,所以我的代码是这样写的:
function GetKeyVaule(str)
local MyStr = string.match(str,"%[(.-)%]")
local key= string.match(MyStr,"%a+")
local value = string.match(MyStr,"%d+")
print(key,value)
end
很复杂对吧:我想的是先消除了两个括号,然后再把键值对从拆开括号中提出 ,于是就出了版本二:
function GetMember (str)
Keywords = {
}
for w in string.gmatch(str,"%a+") do
Keywords[#Keywords + 1] = w
end
Valuewords = {
}
for w in string.gmatch(str,"%d+") do
Valuewords[#Valuewords + 1] = w
end
for i=1, #Keywords do
print(Keywords[i],Valuewords[i])
end
end
GetMember(s)
这次我直接把键和值分别存到不同的表中,然后用的时候 再分别取值 。但是也不足够 , 还可以简化,后来我一想为何要分两次循环呢?于是版本三来了:
function GetKV (str)
for k,v in string.gmatch(str,"%[(%a+),(%d+)%]") do
print(k,v)
end
end
GetKV(s)
二十四、lua之数据结构(多维数组,链表,队列)
1.数组
1.一维数组
常见的一维数组起始就是我们的lua中的table序列,我们可以直接通过表构造器在一句表达式中创建并初始化数组:
squares = {
1,2,3,4,5,6,7,8} --切记lua的table默认是从1开始的
那么如果我们需要固定数组的大小,我们可以这样做:
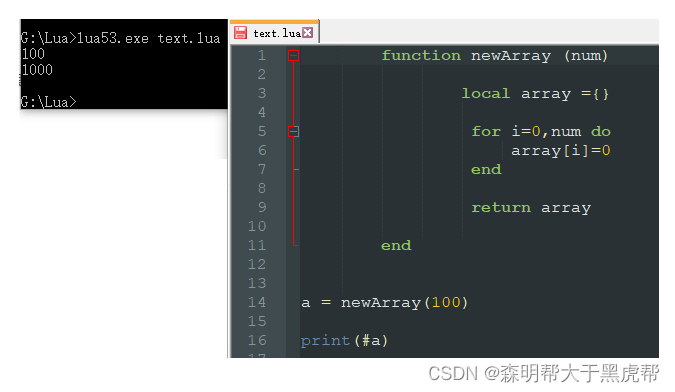
获取数组的长度可以使用#array,插入删除可以使用table自带的insert和delete函数,所以一维数组十分简单。
2.二维数组
实现二维数组也不难,比如说我们要实现一个NM二维矩阵,我们只需要把一个表中从1到N的索引都指向含有M个元素的表,那么就能实现NM的二维数组了。
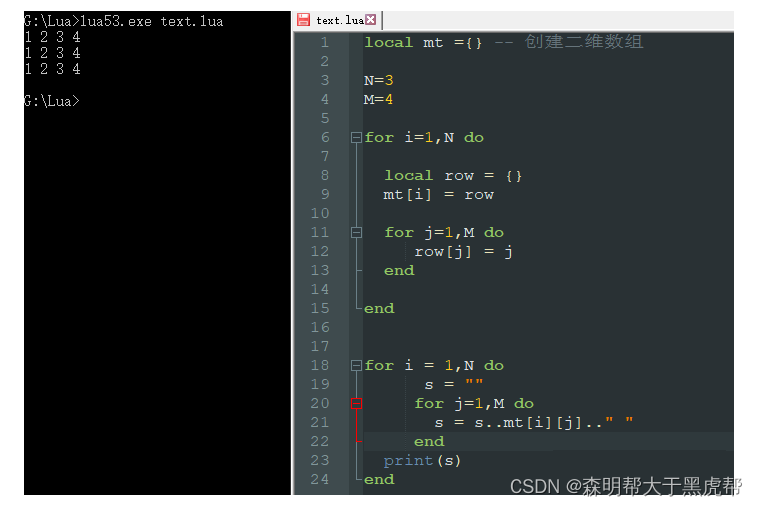
2.链表
实现链表起始也很简单,我们只需要定义这样的一个表:
list = {
value , -- value是数值类型的
next -- next是表类型的
}
那么我们就可以通过以下的方法来便利整个表,从而实现插入,删除,搜索等各种功能。
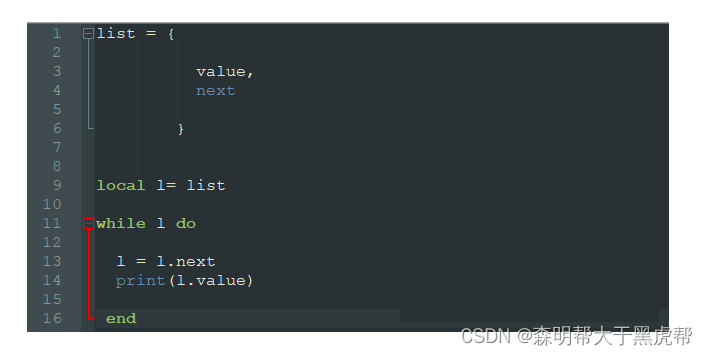
3.栈和队列
栈和队列的插入都是可以通过#表取得整个结构的大小然后对【#表+1】来进行赋值。
他们的差别是如果要取出元素的额话,栈是从最末尾段取出,也就是直接把【#表】置为nil就可以了。
队列的话是需要把首个元素个取出并删除,此时我们可以调用table里面的remove函数,table.remove(表,1)来进行操作。
二十五、rawset & rawget方法
1.什么是rawset & rawget
早在之前我们就讲述过,如果对一个表进行查找的时候,若表中不存在该值,则会查找该表的原表访问其原表__index字段来解决。而若对表输入一个不存在的值,则会查找该表的原表访问其原表__newindex字段来解决。
而rawset & rawget则是绕过原表这一过程,直接把操作这个表相应的结论直接输出。

举个例子:
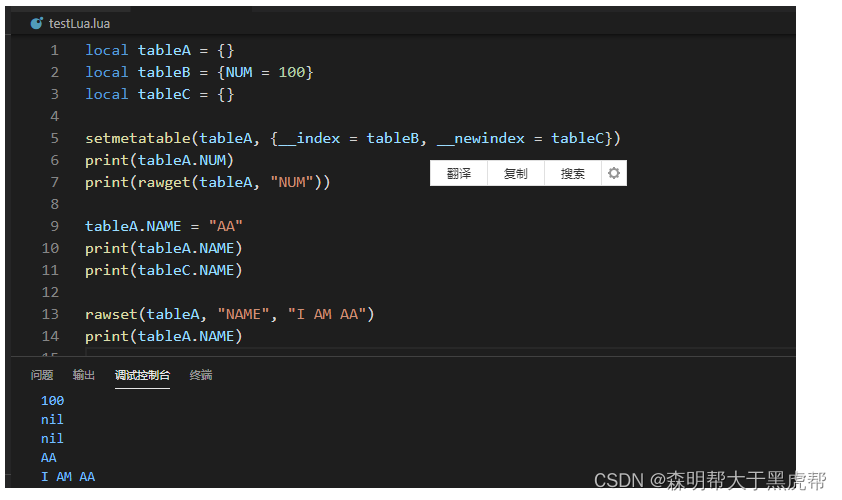
二十六、lua环境ENV
1.全局环境_G
lua使用一个表来保存全局变量,一方面简化了Lua语言内部的实现,另一方面可以像操作一个普通表一样操作这个表。 lua把全局环境本身保存到全局变量_G中(因此_G._G 和 _G是等价的),我们可以通过_G来访问/设置全局变量。
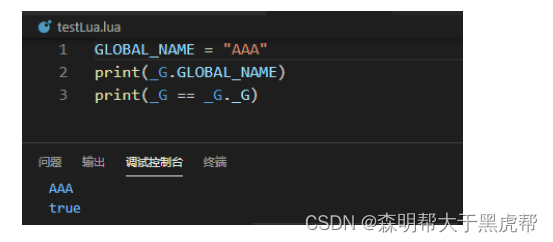
Lua中的全局变量不需要声明就可以使用,虽然这种行为对于小程序来说可能会比较方便。但是对于大型项目来说可能会引起一些BUG,因为_G就是一个表结构,因此我们可以利用元表的机制来避免这种情况。
对不存在的key赋值:
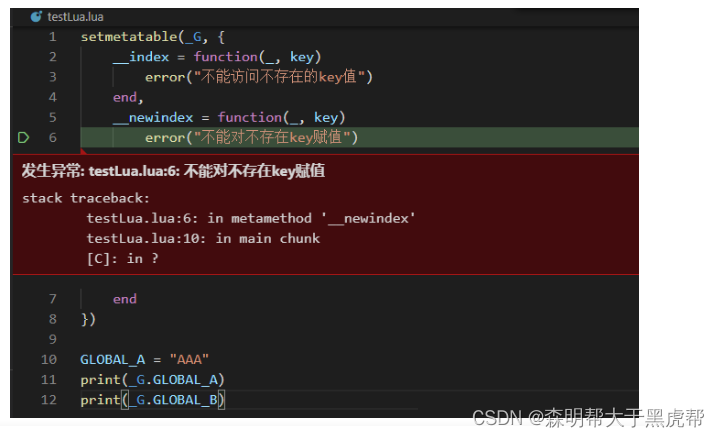
访问不存在的key:
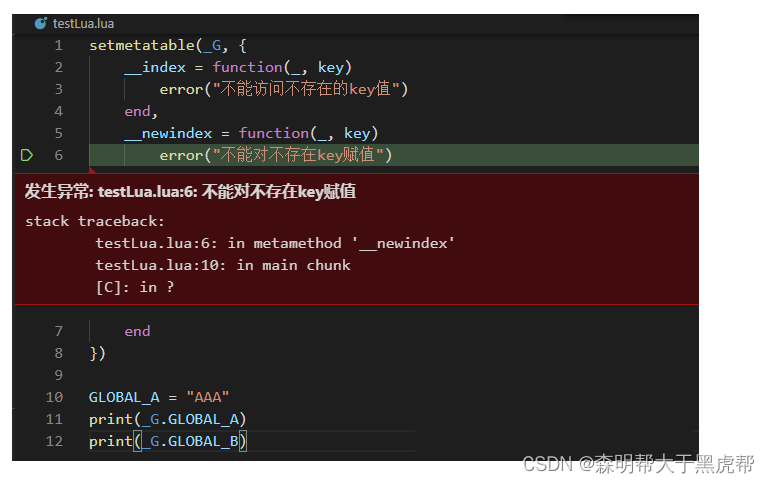
那么如果我们需要声明一个新的全局变量的时候,使用rawset函数就可以了。rawset可以绕过元方法直接对表复制。

Lua不允许值为nil的全局变量,因为值为nil的全局变量都会被自动地认为自己是未声明的。但是,要允许值为nil的全局变量也不难,只需要引入一个辅助表来保存已声明的名称即可。
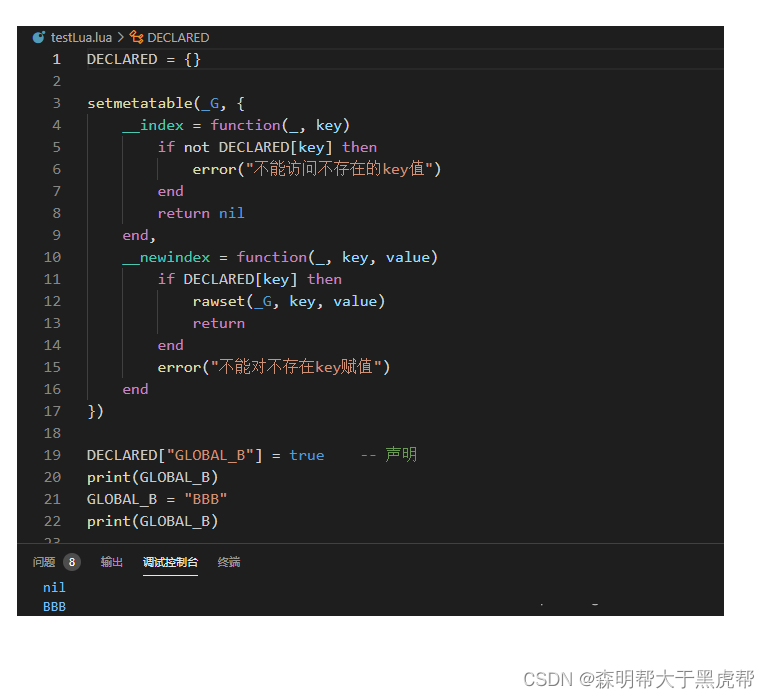
2.非全局环境_ENV
lua 5.2 正式发布了,对于 lua 语言本身的修改,重中之重就是对 environment 这个概念的修改,本质上,lua 取消了原有意义上的 environment,而是通过使用非全局变量_ENV(上值upvalue)来保存这个全局环境 。全局变量实际上只是一个语法糖,编译时再前面加上了 _ENV. 的前缀。这样,从 load 开始,第一个 chunk 就被加上了 _ENV 这个 upvalue ,然后依次传递下去。

- 简单来说其实就是经历了这三个步骤:
- 编译器在编译所有代码段之前,在外层创建局部变量_ENV。
- 编译器将所有的自由名称var变换为_ENV.var。
- 函数load使用全局环境(保存在_G)初始化代码段的第一个上值,即Lua语言内部维护的一个普通的表。
当我们声明一个"全局"变量时,其实是把这个变量声明到用全局环境初始化的上值_ENV中而已。当我们把_ENV置空之后就会丢失掉全局函数的环境。
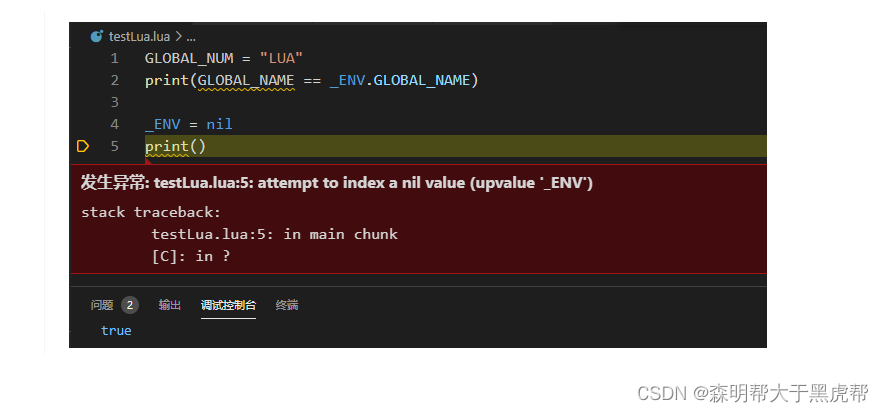
这么做的好处是什么呢?
在我看来,这就有点像C++中的命名空间,一方面能够保护_G这个全局环境不被污染,另一方面则是避免了同名函数发生覆盖的情况。如果想调用某模块的全局函数需要先引入该模块。

如果调用不同模块之间的同名函数,那么会调用最后require的模块函数。
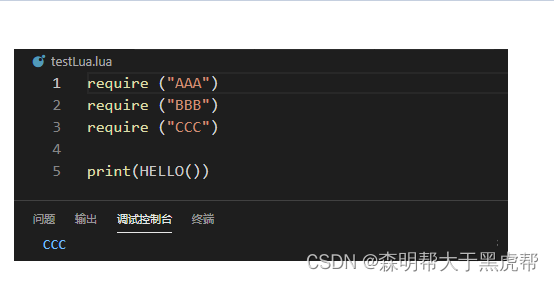
最后,其实_ENV也不一定非要使用全局环境初始化,我们可以通过loadfile中的可选参数,给这个模块创立一个新的环境。这样做的好处是哪怕此时有恶意代码进入该模块,也无法访问到其他全局数据。