一、简介
Redis 是开源免费, key-value 内存数据库,主要解决高并发、大数据场景下,热点数据访问的性能问题,提供高性能的数据快速访问。项目中部分数据访问比较频繁,对下游 DB(例如 MySQL)造成服务压力,这时候可以使用缓存来提高效率。
Redis 的主要特点包括:
- Redis数据存储在内存中,可以提高热点数据的访问效率
- Redis 除了支持 key-value 类型的数据,同时还支持其他多种数据结构的存储;
- Redis 支持数据持久化存储,可以将数据存储在磁盘中,机器重启数据将从磁盘重新加载数据;
Redis 作为缓存数据库和 MySQL 这种结构化数据库进行对比。
- 从数据库类型上,Redis 是 NoSQL 半结构化缓存数据库, MySQL 是结构化关系型数据库;
- 从读写性能上,MySQL 是持久化硬盘存储,读写速度较慢, Redis 数据存储读取都在内存,同时也可以持久化到磁盘,读写速度较快;
- 从使用场景上,Redis 一般作为 MySQL 数据读取性能优化的技术选型,彼此配合使用。Redis用于存储热数据或者缓存数据,并不存在相互替换的关系。
二、Redis 基本数据结构与实战场景
- redis的数据结构可以理解为Java数据类型中的
Map<String,Object>,key是String类型,value是下面的类型。只不过作为一个独立的数据库单独存在,所以Java中的Map怎么用,redis就怎么用,大同小异。 - 字符串类型的数据结构可以理解为
Map<String,String> - list类型的数据结构可以理解为
Map<String,List<String>> - set类型的数据结构可以理解为
Map<String,Set<String>> - hash类型的数据结构可以理解为
Map<String,HashMap<String,String>>
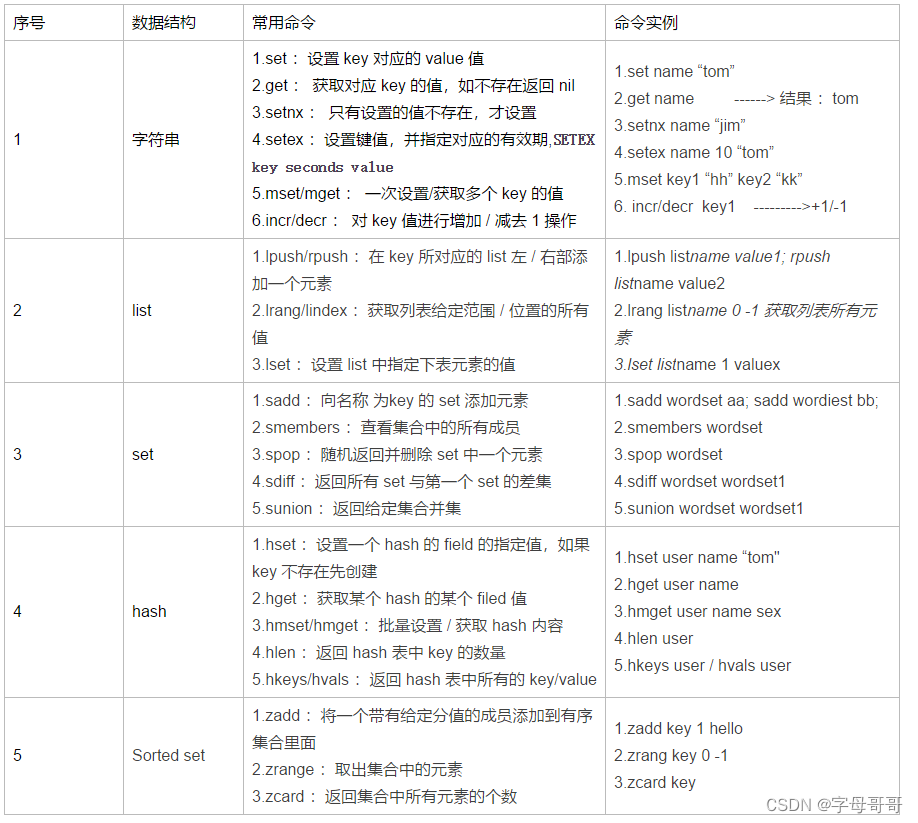
上图中命令行更正:lrange,不是lrang
三、 redis应用场景解析
3.1 String 类型使用场景
场景一:商品库存数
从业务上,商品库存数据是热点数据,交易行为会直接影响库存。而 Redis 自身 String 类型提供了:
incr key #增加一个库存
decr key # 减少一个库存
incrby key 10 # 增加20个库存
decrby key 15 # 减少15个库存
- set goods_id 10; 设置 id 为 good_id 的商品的库存初始值为 10;
- decr goods_id; 当商品被购买时候,库存数据减 1。
依此类推的场景:商品的浏览次数,问题或者回复的点赞次数等。这种计数的场景都可以考虑利用 Redis 来实现。
场景二:时效信息存储
Redis 的数据存储具有自动失效能力。也就是存储的 key-value 可以设置过期时间,SETEX mykey 60 "value"中的第2个参数就是过期时间。
比如,用户登录某个 App 需要获取登录验证码, 验证码在 30 秒内有效。
- 生成验证码:生成验证码并使用 String 类型在reids存储验证码,同时设置 30 秒的失效时间。如:
SETEX validcode 30 "value" - 验证过程:用户获得验证码之后,我们通过
get validcode获取验证码,如果获取不到说明验证码过期了。
3.2 List 类型使用场景
list 是按照插入顺序排序的字符串链表。可以在头部和尾部插入新的元素(双向链表实现,两端添加元素的时间复杂度为 O(1)) 。
场景一:消息队列实现
目前有很多专业的消息队列组件 Kafka、RabbitMQ 等。 我们在这里仅仅是使用 list 的特征来实现消息队列的要求。在实际技术选型的过程中,大家可以慎重思考。
list 存储就是一个队列的存储形式:
- lpush key value; 在 key 对应 list 的头部添加字符串元素;
- rpop key; 移除列表的最后一个元素,返回值为移除的元素。
场景二:最新上架商品
在交易网站首页经常会有新上架产品推荐的模块, 这个模块是存储了最新上架前 100 名。这时候使用 Redis 的 list 数据结构,来进行 TOP 100 新上架产品的存储。
Redis ltrim 指令对一个列表进行修剪(trim),这样 list 就会只包含指定范围的指定元素。
ltrim key start end
start 和 end 都是由 0 开始计数的,这里的 0 是列表里的第一个元素(表头),1 是第二个元素。
如下伪代码演示:
//把新上架商品添加到链表里
ret = r.lpush("new:goods", goodsId)
//保持链表 100 位
ret = r.ltrim("new:goods", 0, 99)
//获得前 100 个最新上架的商品 id 列表
newest_goods_list = r.lrange("new:goods", 0, 99)
3.3 set 类型使用场景
set 也是存储了一个集合列表功能。和 list 不同,set 具备去重功能(和Java的Set数据类型一样)。当需要存储一个列表信息,同时要求列表内的元素不能有重复,这时候使用 set 比较合适。与此同时,set 还提供的交集、并集、差集。
例如,在交易网站,我们会存储用户感兴趣的商品信息,在进行相似用户分析的时候, 可以通过计算两个不同用户之间感兴趣商品的数量来提供一些依据。
//userid 为用户 ID , goodID 为感兴趣的商品信息。
sadd "user:userId" goodID
sadd "user:101" 1
sadd "user:101" 2
sadd "user:102" 1
Sadd "user:102" 3
sinter "user:101" "user:102" # 返回值是1
获取到两个用户相似的产品, 然后确定相似产品的类目就可以进行用户分析。类似的应用场景还有, 社交场景下共同关注好友, 相似兴趣 tag 等场景的支持。
3.4 Hash 类型使用场景
Redis 在存储对象(例如:用户信息)的时候需要对对象进行序列化转换然后存储,还有一种形式,就是将对象数据转换为 JSON 结构数据,然后存储 JSON 的字符串到 Redis。
对于一些对象类型,还有另外一种比较方便的类型,那就是按照 Redis 的 Hash 类型进行存储。
hset key field value
例如,我们存储一些网站用户的基本信息, 我们可以使用:
hset user101 name "小明"
hset user101 phone "123456"
hset user101 sex "男"
这样就存储了一个用户基本信息,存储信息有:{name : 小明, phone : “123456”,sex : “男”}
当然这种类似场景还非常多, 比如存储订单的数据,产品的数据,商家基本信息等。大家可以参考来进行存储选型。但是不适合存储关联关系比较复杂的数据,那种场景还得用关系型数据库比较方便。
3.5 Sorted Set 类型使用场景
Redis sorted set 的使用场景与 set 类似,区别是 set 不是自动有序的,而 sorted set 可以通过提供一个 score 参数来为存储数据排序,并且是自动排序,插入既有序。业务中如果需要一个有序且不重复的集合列表,就可以选择 sorted set 这种数据结构。
比如:商品的购买热度可以将购买总量 num 当做商品列表的 score,这样获取最热门的商品时就是可以自动按售卖总量排好序。
排序,插入既有序。业务中如果需要一个有序且不重复的集合列表,就可以选择 sorted set 这种数据结构。
比如:商品的购买热度可以将购买总量 num 当做商品列表的 score,这样获取最热门的商品时就是可以自动按售卖总量排好序。