Pytorch 卷积层
0. 环境介绍
环境使用 Kaggle 里免费建立的 Notebook
小技巧:当遇到函数看不懂的时候可以按 Shift+Tab 查看函数详解。
1. 从全连接到卷积
多层感知机十分适合处理表格数据,其中行对应样本,列对应特征。 对于表格数据,我们寻找的模式可能涉及特征之间的交互,但是我们不能预先假设任何与特征交互相关的先验结构。 此时,多层感知机可能是最好的选择,然而对于高维感知数据(图片,视频等),这种缺少结构的网络可能会变得不实用。
注 :深度神经网络也不适合用于处理表格数据。
大家可以看一下以下资料:
深度神经网络为什么在表格数据上就是不行呢
论文地址
1.0 猫狗图像分类
假设有一个充分的猫狗照片数据集,每张照片具有百万级别的像素,这意味着网络的每次输入都有一百万( 1 0 6 10^6 106)个维度(先不考虑 RGB 通道)。即使将隐藏层维度降低到 1000 ( 1 0 3 ) 1000(10^3) 1000(103),这个全连接层也将有 1 0 6 × 1 0 3 = 1 0 9 10^6 \times 10^3 = 10^9 106×103=109 个参数。
参数量太多,需要大量的 GPU 资源和分布式优化训练的经验。
然而,如今人类和机器都能很好地区分猫和狗:这是因为图像中本就拥有丰富的结构,而这些结构可以被人类和机器学习模型使用。 卷积神经网络(convolutional neural networks,CNN)是机器学习利用自然图像中一些已知结构的创造性方法。
1.1 平移不变性和局部性
假设你想从一张图片中找到某个物体。 合理的假设是:无论哪种方法找到这个物体,都应该和物体的位置无关。
沃尔多游戏:在这个游戏中包含了许多充斥着活动的混乱场景,而沃尔多通常潜伏在一些不太可能的位置,读者的目标就是找出他。 尽管沃尔多的装扮很有特点,但是在眼花缭乱的场景中找到他也如大海捞针。 然而沃尔多的样子并不取决于他潜藏的地方,因此我们可以使用一个“沃尔多检测器”扫描图像。 该检测器将图像分割成多个区域,并为每个区域包含沃尔多的可能性打分。 卷积神经网络正是将空间不变性(spatial invariance)的这一概念系统化,从而基于这个模型使用较少的参数来学习有用的表示。
总结下来就是两个原则:
- 平移不变性(translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。
- 局部性(locality):神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。
1.2 多层感知机的限制
使用 [ X ] i , j [\mathbf{X}]_{i, j} [X]i,j 和 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j 分别表示输入图像和隐藏表示中位置 ( i , j ) (i, j) (i,j) 处的像素。
[ H ] i , j = [ U ] i , j + ∑ k ∑ l [ W ] i , j , k , l [ X ] k , l = [ U ] i , j + ∑ a ∑ b [ V ] i , j , a , b [ X ] i + a , j + b . \begin{aligned} \left[\mathbf{H}\right]_{i, j} &= [\mathbf{U}]_{i, j} + \sum_k \sum_l[\mathsf{W}]_{i, j, k, l} [\mathbf{X}]_{k, l}\\ &= [\mathbf{U}]_{i, j} + \sum_a \sum_b [\mathsf{V}]_{i, j, a, b} [\mathbf{X}]_{i+a, j+b}.\end{aligned} [H]i,j=[U]i,j+k∑l∑[W]i,j,k,l[X]k,l=[U]i,j+a∑b∑[V]i,j,a,b[X]i+a,j+b.
为了使每个隐藏神经元都能接收到每个输入像素的信息,我们将参数从权重矩阵(如同我们先前在多层感知机中所做的那样)替换为四阶权重张量 W W W。 U U U 为偏置参数。 a a a 和 b b b 通过在正偏移和负偏移之间移动覆盖了整个图像。 [ V ] i , j , a , b [\mathsf{V}]_{i, j, a, b} [V]i,j,a,b 表示像素 ( i , j ) (i, j) (i,j) 对于像素 ( i + a , j + b ) (i+a, j+b) (i+a,j+b) 的权重。
可以发现参数量很大。
1.3 引入平移不变性
意味着对象在输入 X X X 中的平移,应该仅导致隐藏层 H H H 中的平移。也就是说 V V V 和 U U U 不依赖于 ( i , j ) (i, j) (i,j) 的值,即 [ V ] i , j , a , b = [ V ] a , b [\mathsf{V}]_{i, j, a, b} = [\mathbf{V}]_{a, b} [V]i,j,a,b=[V]a,b。而且 U U U 为一个常数 u u u。
[ H ] i , j = u + ∑ a ∑ b [ V ] a , b [ X ] i + a , j + b . [\mathbf{H}]_{i, j} = u + \sum_a\sum_b [\mathbf{V}]_{a, b} [\mathbf{X}]_{i+a, j+b}. [H]i,j=u+a∑b∑[V]a,b[X]i+a,j+b.
这就是卷积(convolution)。我们是在使用系数 [ V ] a , b [\mathbf{V}]_{a, b} [V]a,b 对位置 ( i , j ) (i, j) (i,j) 附近的像素 ( i + a , j + b ) (i+a, j+b) (i+a,j+b) 进行加权得到 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j。
这样看的话, [ V ] a , b [\mathbf{V}]_{a, b} [V]a,b 的参数量比 [ V ] i , j , a , b [\mathsf{V}]_{i, j, a, b} [V]i,j,a,b 要少了很多。
1.4 引入局部性
为了收集训练参数 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j 的相关信息,我们不应偏离到距 ( i , j ) (i, j) (i,j) 很远的地方。这意味着在 ∣ a ∣ > Δ |a|> \Delta ∣a∣>Δ 或 ∣ b ∣ > Δ |b|> \Delta ∣b∣>Δ 的范围之外,我们可以设置 [ V ] a , b = 0 [\mathbf{V}]_{a, b} = 0 [V]a,b=0。因此,我们可以将 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j 重写为:
[ H ] i , j = u + ∑ a = − Δ Δ ∑ b = − Δ Δ [ V ] a , b [ X ] i + a , j + b . [\mathbf{H}]_{i, j} = u + \sum_{a = -\Delta}^{\Delta} \sum_{b = -\Delta}^{\Delta} [\mathbf{V}]_{a, b} [\mathbf{X}]_{i+a, j+b}. [H]i,j=u+a=−Δ∑Δb=−Δ∑Δ[V]a,b[X]i+a,j+b.
上式就是一个卷积层(convolutional layer),卷积神经网络(CNN)就是包含卷积层的一类特殊的神经网络。
V V V 被称为卷积核(convolution kernel)或者滤波器(filter),亦或简单地称之为该卷积层的权重,通常该权重是可学习的参数。
当图像处理的局部区域很小时,卷积神经网络与多层感知机的训练差异可能是巨大的:以前,多层感知机可能需要数十亿个参数来表示网络中的一层,而现在卷积神经网络通常只需要几百个参数,而且不需要改变输入或隐藏表示的维数。 参数大幅减少的代价是,我们的特征现在是平移不变的,并且当确定每个隐藏活性值时,每一层只包含局部的信息。 以上所有的权重学习都将依赖于归纳偏置。当这种偏置与现实相符时,我们就能得到样本有效的模型,并且这些模型能很好地泛化到未知数据中。 但如果这偏置与现实不符时,比如当图像不满足平移不变时,我们的模型可能难以拟合我们的训练数据。
2. 卷积层
卷积层严格来讲,是错误的叫法,因为它所表达的运算其实是交叉相关运算(cross-correlation),而不是卷积运算。
注::
想了解卷积的意义,这里推荐 B 站 一位 up 主的视频:
从“卷积”、到“图像卷积操作”、再到“卷积神经网络”,“卷积”意义的3次改变
2.1 2D 卷积层
输入 X X X 是 ( 3 × 3 ) (3 \times 3) (3×3) 的张量,卷积核 W W W 为 ( 2 × 2 ) (2 \times 2) (2×2)。
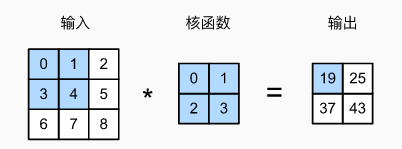
输出 Y Y Y 大小等于输入 X X X 大小 n h × n w n_h \times n_w nh×nw 减去卷积核 W W W 大小 k h × k w k_h \times k_w kh×kw,即:
( n h − k h + 1 ) × ( n w − k w + 1 ) . (n_h-k_h+1) \times (n_w-k_w+1). (nh−kh+1)×(nw−kw+1).
然后再加上一个偏置项 b b b, Y Y Y 表达式为:
Y = X ★ W + b Y = X ★ W + b Y=X★W+b
★ ★ ★ 表示卷积运算, W W W 和 b b b 是可学习的参数。卷积核的大小 k h × k w k_h \times k_w kh×kw 是超参数。
3. 图像卷积代码实现
3.1 2D 卷积运算
!pip install d2l
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
# 输出的形状
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
# * 对应位置相乘再求和
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
验证上述实现的输出:
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
corr2d(X, K)

3.2 2D卷积层
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
3.3 图像中目标的边缘检测
X = torch.ones((6, 8))
X[:, 2:6] = 0
X
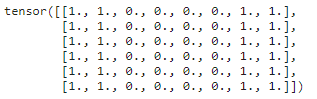
构造一个 ( 1 × 2 ) (1 \times 2) (1×2) 的卷积核 K K K,如果水平相邻的两元素相同,则输出为零,否则输出为非零。
K = torch.tensor([[1.0, -1.0]])
输出 Y Y Y 中的 1 1 1 代表从白色到黑色的边缘, − 1 -1 −1 代表从黑色到白色的边缘,其他情况的输出为 0 0 0。
Y = corr2d(X, K)
Y
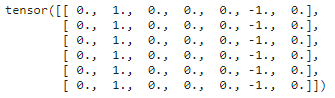
现在我们将输入的二维图像转置,再运算。 其输出如下,之前检测到的垂直边缘消失了。 这个卷积核 K K K 只可以检测垂直边缘,无法检测水平边缘:
corr2d(X.t(), K)

3.4 学习由 X X X 生成 Y Y Y 的卷积核 K K K
上一节(3.3)我们是设置的卷积核 K K K 的值,通过与 X X X 运算得到了 Y Y Y,下面我们通过 X X X 和 Y Y Y 训练学习出来 K K K。
我们先构造一个卷积层,并将其卷积核初始化为随机张量。接下来,在每次迭代中,我们比较 Y Y Y 与卷积层输出的平方误差,然后计算梯度来更新卷积核。为了简单起见,我们在此使用内置的二维卷积层,并忽略偏置:
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {
i+1}, loss {
l.sum():.3f}')

注:关于为什么损失需要 sum() 之后再 backward() :
参考 https://zhuanlan.zhihu.com/p/427853673
查看所学的卷积核的权重张量:
conv2d.weight.data.reshape((1, 2))
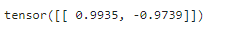
3.5 加入偏置 b b b 后训练
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=True)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
conv2d.bias.data[:] -= lr * conv2d.bias.grad
if (i + 1) % 2 == 0:
print(f'epoch {
i+1}, loss {
l.sum():.3f}')

可以发现无法收敛,这个时候应该调小学习率 lr 并且增加训练 epoch 数量:
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=True)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 1e-2 # 学习率
for i in range(30):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
conv2d.bias.data[:] -= lr * conv2d.bias.grad
if (i + 1) % 2 == 0:
print(f'epoch {
i+1}, loss {
l.sum():.3f}')
print(conv2d.weight.data.reshape((1, 2)), conv2d.bias.data)
