接上一篇博客:Attention Mechanisms in Computer Vision: A Survey(三)
一、Channel & Spatial Attention
通道与空间注意力结合了通道注意力和空间注意力的优点。它自适应地选择重要对象和区域。残差注意力网络开创了通道和空间注意力领域,强调了信息特征在空间和通道维度上的重要性。它采用自下而上的结构,由几个卷积组成,生成一个3D(高度、宽度、通道)注意力图。然而,它有很高的计算成本和有限的接受领域。 为了利用全局空间信息,后来的工作中引入了全局平均池化,并将通道注意力和空间通道注意力解耦,从而增强了特征的辨别能力。
(一)、Residual Attention Network
受ResNet的成功启发,Wang等人通过将注意机制与残差连接相结合,提出了非常深的卷积残差注意网络(RAN)。堆积在残差注意力网络中的每个注意力模块可分为掩码分支和主干分支。主干分支提取特征,并且可以由任何最先进的结构实现,包括预激活残差单元和初始模块。掩码分支使用自下而上自上而下的结构来学习与主干分支的输出特征具有相同大小的掩码。在两个1×1卷积层之后,sigmoid层将输出标准化为[0,1]。总的来说,残差注意力机制可以写成

其中, h u p h_{up} hup是一种自下而上的结构,在残差单位之后使用多次最大池化来增加感受野,而 h d o w n h_{down} hdown是自上而下的部分,使用线性插值来保持输出大小与输入特征图相同。这两个部分之间也存在跳过连接,这在公式中被省略。f代表主干分支,可以是任何最先进的结构。
其结构如下:

在每个注意力模块内部,自下而上,自上而下的前馈结构对空间和跨通道依赖性进行建模,从而实现一致的性能改进。残差注意力可以以端到端的训练方式融入任何深层网络结构。然而,提议的自下而上自上而下的结构未能利用全局空间信息。此外,直接预测3D注意力特征图的计算成本很高。
(二)、 CBAM
(三)、BAM
Park等人与CBAM同时提出了瓶颈注意力·模块(BAM),旨在有效提高网络的表征能力。它使用扩展卷积来扩大空间注意力子模块的感受野,并按照ResNet的建议构建瓶颈结构以节省计算成本。
对于给定的输入特征映射X,BAM推断通道注意 s c ∈ R C s_c∈ R^C sc∈RC与空间注意 S s ∈ R C × H × W S_s∈ R^{C×H×W} Ss∈RC×H×W将两个分支输出的大小调整为后,将两个注意力图相加。与SE块一样,通道注意力分支对特征映射应用全局平均池化来聚合全局信息,然后使用具有通道降维的MLP。为了有效地利用上下文信息,空间注意力分支结合了瓶颈结构和膨胀卷积。总的来说,BAM可以写成

其中 W i 、 b i W_i、b_i Wi、bi分别表示全连接层的权重和偏置, C o n v 1 1 × 1 Conv^{1×1}_1 Conv11×1和 C o n v 2 1 × 1 Conv^{1×1}_2 Conv21×1是用于通道缩减的卷积层。 D C i 3 × 3 DC^{3×3}_i DCi3×3表示一个具有3×3核的膨胀卷积,用于有效利用上下文信息。扩展将注意力映射 s s s_s ss和 s c s_c sc扩展为 R C × H × W R^{C×H×W} RC×H×W。
BAM可以在空间和通道维度上强调或抑制特征,并提高有代表性的特征。应用于通道和空间注意力分支的降维使其能够与任何卷积神经网络集成,而只需很少的额外计算成本。然而,尽管膨胀卷积有效地扩大了感受野,但它仍然无法捕获远程上下文信息以及编码跨域关系。

(四)、scSE
为了聚合全局空间信息,SE块对特征图应用全局池化。然而,它忽略了像素级的空间信息,这在密集预测任务中很重要。因此,Roy等人提出了空间和通道SE块(scSE)。与BAM一样,使用空间SE块作为SE块的补充,提供空间注意力权重,以关注重要区域。
给定输入特征映射X,将空间SE和通道SE两个并行模块应用于特征映射,分别对空间和通道信息进行编码。信道SE模块为普通SE块,而空间SE模块采用1×1卷积进行空间压缩。这两个模块的输出被熔断。整个过程可以写成

其中f表示融合函数,可以是最大值、加法、乘法或级联。 提出的scSE块结合了通道和空间注意力,以增强特征,并捕获像素级的空间信息。分割任务因此受益匪浅。在F-CNN中集成一个scSE块可以在语义切分方面取得一致的改进,而额外的成本可以忽略不计。

(五)、Triplet Attention
在CBAM和BAM中,通道注意和空间注意是独立计算的,忽略了这两个领域之间的关系。Misra等人受空间注意力的激励,提出了三重注意,这是一种轻量级但有效的注意机制,用于捕捉跨域交互。
给定一个输入特征映射X,三重注意使用三个分支,每个分支都在捕获H、W和C中任意两个域之间的跨域交互中发挥作用。在每个分支中,首先对输入应用沿不同轴的旋转操作,然后Z-pool层负责聚合零维信息。最后,一个内核大小为k×k的标准卷积层对最后两个领域之间的关系进行建模。这个过程可以写成
其中 P m 1 Pm_1 Pm1和 P m 2 Pm_2 Pm2表示分别沿H轴和W轴逆时针旋转90度◦ 而 P m − 1 Pm^{−1} Pm−1表示倒数。Z-Pool沿第零维连接最大池化和平均池化。

与CBAM和BAM不同,三重态注意强调捕获跨域交互的重要性,而不是独立计算空间注意和通道注意。这有助于捕获丰富的区分性特征表示。由于其简单而高效的结构,三重态注意可以很容易地添加到经典骨干网络中。

(六)、SimAM
Yang等人强调了在提出SimAM时学习不同通道和空间领域的注意力权重的重要性,SimAM是一个简单、无参数的注意模块,能够直接估计3D权重,而不是扩展一维或二维权重。SimAM的设计基于著名的神经科学理论,因此无需手动微调网络结构。 受空间抑制现象的启发,他们提出应强调显示抑制效应的神经元,并将每个神经元的能量函数定义为:


(七)、Coordinate attention
SE块在建模跨通道关系之前使用全局池聚合全局空间信息,但忽略了位置信息的重要性。BAM和CBAM采用卷积来捕获局部关系,但无法建模长期依赖关系。为了解决这些问题,Hou等人提出了协调注意力,这是一种新的注意机制,它将位置信息嵌入到通道注意中,从而使网络能够以较小的计算成本关注大的重要区域。 协调注意力机制有两个连续的步骤:协调信息嵌入和协调注意力生成。首先,池化内核的两个空间范围对每个通道进行水平和垂直编码。在第二步中,对两个池化层的级联输出应用共享的1×1卷积变换函数。然后,坐标注意力将得到的张量拆分为两个独立的张量,以产生具有相同数量的通道注意力向量 ,用于输入X的水平和垂直坐标。这可以写成

其中 G A P h GAP^h GAPh和 G A P w GAP^w GAPw表示垂直坐标和水平坐标的池化函数, s h ∈ R C × 1 × W s^h∈ R^{C×1×W} sh∈RC×1×W和 s w ∈ R C × H × 1 s_w∈ R^{C×H×1} sw∈RC×H×1代表相应的注意权重。 通过协调注意力,网络可以准确地获得目标的位置。这种方法比BAM和CBAM有更大的感受野。与SE块一样,它还模拟了跨通道关系,有效地增强了学习功能的表达能力。由于其轻量级设计和灵活性,它可以轻松地用于 mobile networks的经典构建块。

(八)、DANet
(九)、RGA
在关系感知的全局注意力(RGA)中,协调注意力和DANet强调捕捉远程上下文,而Zhang等人则强调成对关系提供的全局结构信息的重要性,并使用它生成注意力特征图。RGA有两种形式,空间RGA(RGA-S)和通道RGA(RGA-C)。RGA-S首先将输入特征映射X重塑为C×(H×W)和成对关系矩阵 R ∈ R ( H × W ) × ( H × W ) R∈ R^{(H×W)×(H×W)} R∈R(H×W)×(H×W)的计算采用

位置i处的关系向量 r i r_i ri通过在所有位置叠加成对关系来定义:

空间关系感知特征 y i y_i yi可以写成

其中 g a v g c g^c_{avg} gavgc表示通·道域中的全局平均池化。最后,位置i的空间注意力得分由
RGA-C与RGA-S的形式相同,只是将输入特征映射作为一组H×W维特征。RGA使用全局关系为每个特征节点生成注意力分数,从而提供有价值的结构信息并显著增强表征能力。RGA-S和RGA-C足够灵活,可用于任何CNN网络;Zhang等人建议按顺序联合使用它们,以更好地捕捉空间和跨通道关系。


(十)、Self-Calibrated Convolutions
在分组卷积成功的推动下,Liu等人提出了自校准卷积,作为扩大每个空间位置感受野的一种方法。
自校准卷积与标准卷积一起使用。它首先在通道域中将输入特征X划分为 X 1 X_1 X1和 X 2 X_2 X2。自校准卷积首先使用平均池化来减少输入大小并扩大感受野:

其中r是池化核的大小和步幅。然后使用卷积对通道关系进行建模,并使用双线性插值算子 U p U_p Up对特征图进行上采样:

接下来,元素相乘完成自校准过程: 
最后,形成的输出特征映射为:

这种自校准卷积可以扩大网络的接收范围,提高网络的适应性。它在图像分类和某些下游任务(如实例分割、目标检测和关键点检测)中取得了优异的效果。
十一、SPNet
空间池化通常在一个小区域上运行,这限制了它捕获远程依赖关系并将重点放在遥远区域的能力。为了克服这一点,Hou等人提出了 strip pooling,这是一种新的池化方法,能够在水平或垂直空间域中编码远程上下文。

strip pooling有两个分支用于水平和垂直strip pooling。水平strip pooling汇集部分首先汇集输入特征水平方向上的特征 F ∈ R C × H × W F∈ R^{C×H×W} F∈RC×H×W

然后在y中应用核大小为3的一维卷积来捕获不同行和通道之间的关系。重复W次,使输出 y v y_v yv与输入形状一致: 
垂直条strip pooling以类似的方式执行。最后,两个分支的输出使用元素求和进行融合,以生成注意特征图: 
在混合池模块(MPM)中进一步开发了strip pooling模块(SPM)。两者都考虑空间和通道关系,以克服卷积神经网络的局部性。SPNet实现了几个复杂语义分割基准的最新结果。
(十二)、SCA-CNN

由于CNN具有自然的空间性、通道性和多层性,Chen等人提出了一种新的基于空间和通道性注意力的卷积神经网络(SCA-CNN)。它是为图像字幕的任务而设计的,并使用了一个编码器-解码器框架,其中CNN首先将输入图像编码为一个向量,然后LSTM将该向量解码为一个单词序列。给定输入特征映射X和上一时间步LSTM隐藏状态 h t − 1 ∈ R d h_{t−1}∈ R^d ht−1∈Rd是一种空间注意机制,它在LSTM隐藏状态 h t − 1 h_{t−1} ht−1的指导下,更加关注语义有用的区域, 空间注意力模型为:

⊕ 表示矩阵和向量的加法。类似地,通道注意力首先聚合全局信息,然后使用隐藏状态计算通道注意力权重向量 h t − 1 h_{t−1} ht−1:

总的来说,SCA机制可以用两种方式之一编写。如果在空间注意力之前应用通道注意力

如果空间注意力最先被使用

f ( ⋅ ) f(·) f(⋅)表示调制函数,该函数将特征映射X和注意映射作为输入,然后输出调制后的特征映射Y。 与以前的注意机制不同,SCA Net平等地考虑每个图像区域,并使用全局空间信息告知网络关注的位置,SCA Net利用语义向量生成空间注意力特征图以及通道方向的注意权重向量。SCA-CNN不仅仅是一个强大的注意力模型,它还提供了一个更好的理解,即在句子生成过程中,该模型应该关注的地方和内容。
(十三)、GALA
大多数注意力机制只使用来自类别标签的微弱监督信号来学习关注点,这启发了Linsley等人研究显性人类监督如何影响注意力模型的表现和可解释性。作为概念证明,Linsley等人提出了全局和局部注意力(GALA)模块,该模块通过空间注意机制扩展了SE块。
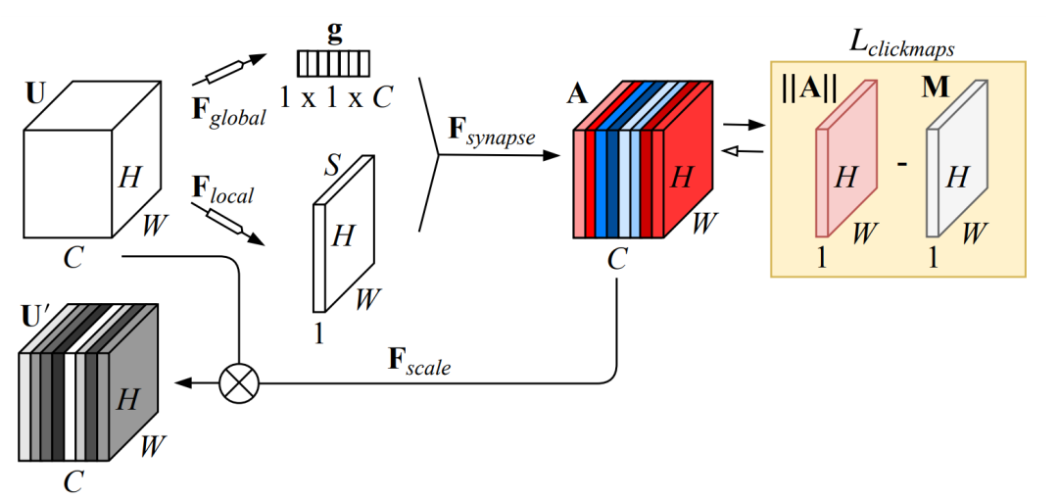
给定输入功能映射X,GALA使用一个注意力掩码,将全局和本地注意力结合起来,告诉网络关注的位置和内容。在SE块中,全局注意力通过全局平均池化聚合全局信息,然后使用多层感知器生成通道方向的注意力权重向量。在局部注意力中,对输入进行两次连续的1×1卷积以生成位置权重图。局部和全局路径的输出通过加法和乘法进行组合。GALA可以表示为:

a , m ∈ R C a,m∈ R^C a,m∈RC是表示通道权重向量的可学习参数。 在人工提供的功能重要性地图的监督下,GALA显著提高了代表性,可以与任何CNN主干网结合。