点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:集智书童
 Sequencer: Deep LSTM for Image Classification
Sequencer: Deep LSTM for Image Classification
论文:https://arxiv.org/abs/2205.01972
在最近的计算机视觉研究中,
ViT的出现迅速改变了各种架构设计工作:ViT利用自然语言处理中的Self-Attention实现了最先进的图像分类性能,MLP-Mixer利用简单的多层感知器也实现了具有竞争性的结果。相比之下,一些研究也表明,精心设计的卷积神经网络(CNNs)可以实现媲美ViT的先进性能,而无需借助这些新想法。在这种背景下,人们对什么是适合于计算机视觉的归纳偏差越来越感兴趣。在这里,作者提出
Sequencer,一个全新且具有竞争性的架构,可以替代ViT,为分类问题提供了一个全新的视角。与ViT不同,Sequencer使用LSTM(而不是Self-Attention)对远程依赖关系进行建模。作者还提出了一个二维的
Sequencer模块,其中一个LSTM被分解成垂直和水平的LSTM,以提高性能。虽然结构简单,但是经过实验表明,
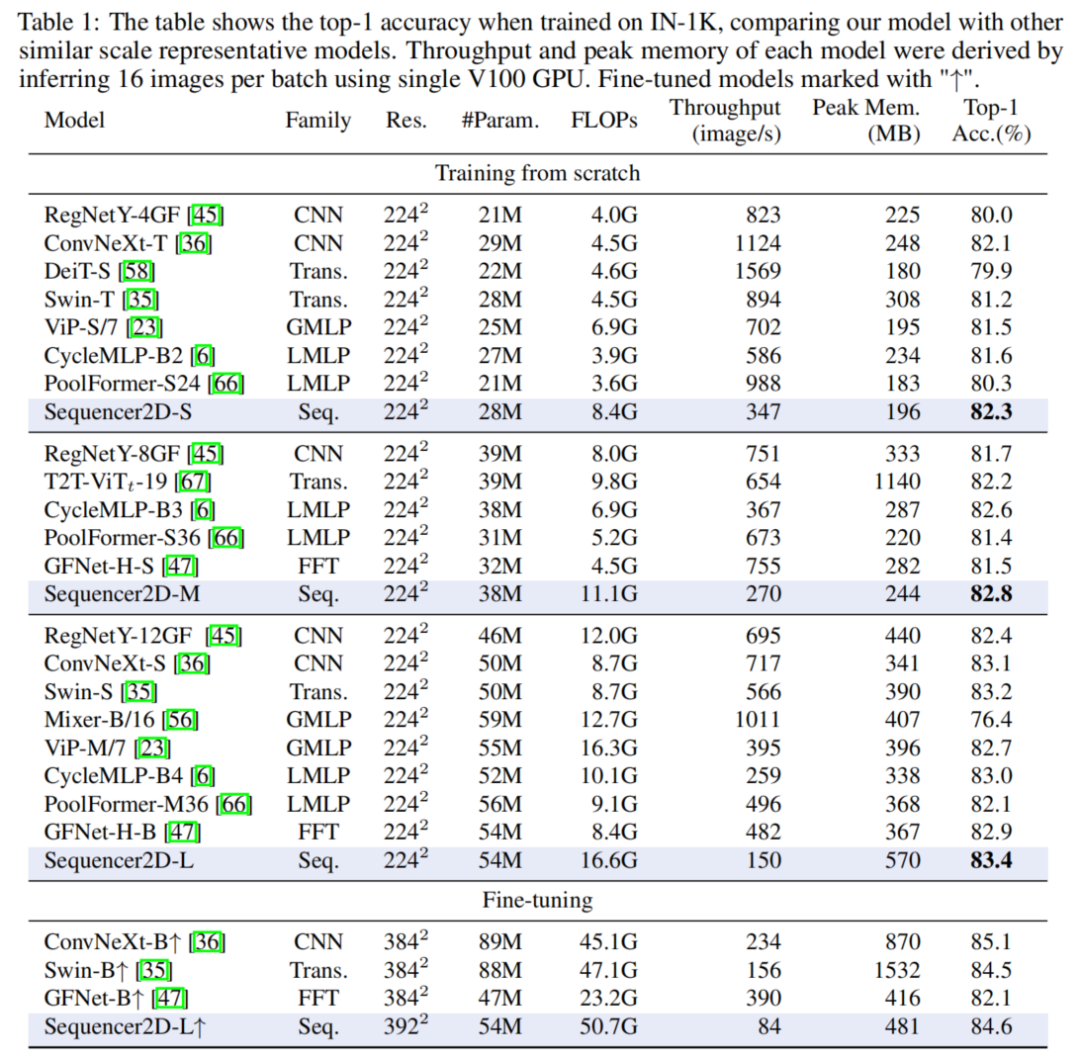
Sequencer的表现令人印象深刻:Sequencer2D-L在ImageNet-1K上仅使用54M参数,实现84.6%的top-1精度。不仅如此,作者还证明了它在双分辨率波段上具有良好的可迁移性和稳健性。
1背景
Vision Transformer成功的原因被认为是由于Self-Attention建模远程依赖的能力。然而,Self-Attention对于Transformer执行视觉任务的有效性有多重要还不清楚。事实上,只基于多层感知器(MLPs)的MLP-Mixer被提议作为ViTs的一个有吸引力的替代方案。
此外,一些研究表明,精心设计的CNN在计算机视觉方面仍有足够的竞争力。因此,确定哪些架构设计对计算机视觉任务具有内在的有效性是当前研究的一大热点。本文通过提出一种新颖的、具有竞争力的替代方案,为这一问题提供了一个新的视角。

本文提出了Sequencer体系结构,使用LSTM(而不是Self-Attention)进行序列建模。Sequencer的宏观架构设计遵循ViTs,迭代地应用Token Mixing和Channel Mixing,但Self-Attention被基于LSTMs的Self-Attention层取代。特别是,Sequencer使用BiLSTM作为一个构建块。简单的BiLSTM表现出一定的性能水平,而Sequencer可以通过使用类似Vision Permutator(ViP)的思想进一步提高。ViP的关键思想是平行处理垂直轴和水平轴。
作者还引入了2个BiLSTM,用于并行处理上/下和左/右方向。这种修改提高了Sequencer的效率和准确性,因为这种结构减少了序列的长度,并产生一个有空间意义的感受野。
在ImageNet-1K数据集上进行预训练时,新的Sequencer架构的性能优于类似规模的Swin和ConvNeXt等高级架构。它还优于其他无注意力和无CNN的架构,如MLP-Mixer和GFNet,使Sequencer在视觉任务中的Self-Attention具有吸引力的新替代方案。
值得注意的是,Sequencer还具有很好的领域稳健性以及尺度稳定性,即使在推理过程中输入的分辨率增加了一倍,也能强烈防止精度退化。此外,对高分辨率数据进行微调的Sequencer可以达到比Swin-B更高的精度。在峰值内存上,在某些情况下,Sequencer往往比ViTs和cnn更经济。虽然由于递归,Sequencer需要比其他模型更多的FLOPs,但更高的分辨率提高了峰值内存的相对效率,提高了在高分辨率环境下的精度/成本权衡。因此,Sequencer作为一种实用的图像识别模型也具有吸引人的特性。
2全新范式
2.1 LSTM的原理
LSTM是一种特殊的递归神经网络(RNN),用于建模序列的长期依赖关系。Plain LSTM有一个输入门,它控制存储输入,一个控制前单元状态的遗忘的遗忘门,以及一个输出门,它控制当前单元状态的单元输出。普通LSTM的公式如下:
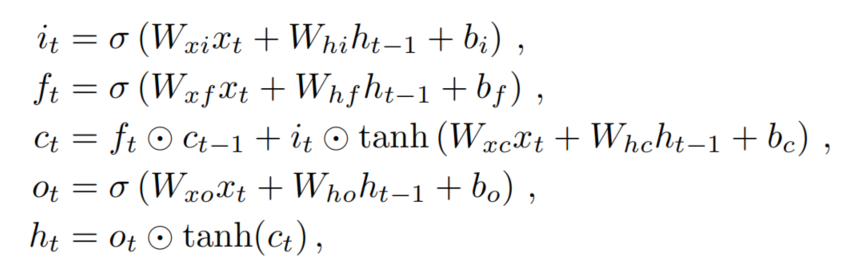
其中σ是logistic sigmoid function,是Hadamard product。
BiLSTM对于预期相互依赖的序列是有利的。一个BiLSTM由2个普通的LSTM组成。设为输入,为反向重排。和分别是用相应的LSTM处理和得到的输出。设为按原顺序重新排列的输出,BiLSTM的输出如下:
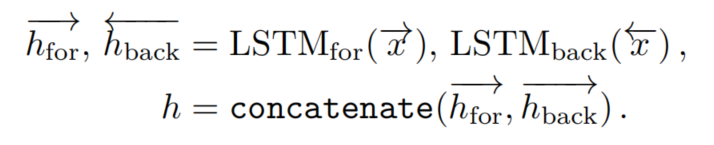
假设和具有相同的隐藏维数D,这是BiLSTM的超参数。因此,向量h的维数为二维。
2.2 Sequencer架构
1、架构总览
本文用LSTM取代Self-Attention层:提出了一种新的架构,旨在节省内存和参数,同时具有学习远程建模的能力。
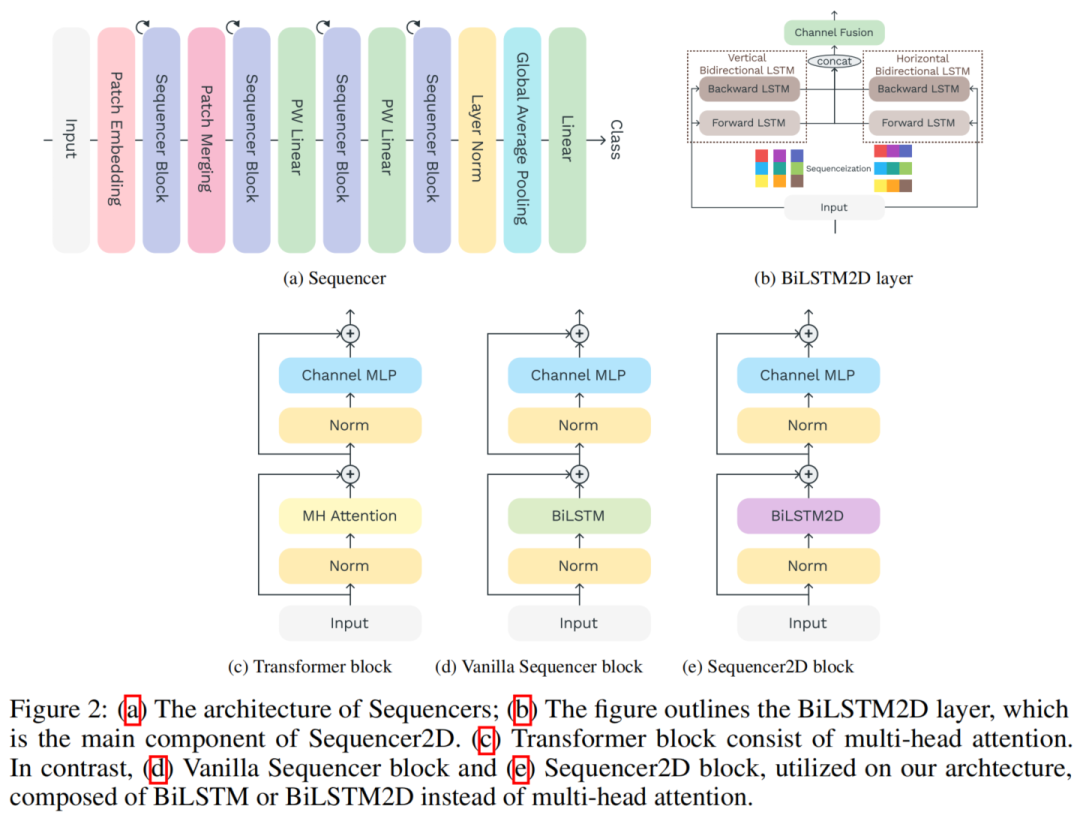
图2a显示了Sequencer体系结构的整体结构。Sequencer架构以不重叠的Patches作为输入,并将它们投影到特征图上。Sequencer Block是Sequencer的核心组件,由以下子组件组成:
BiLSTM层可以经济、全局地Mixing空间信息MLP用于Channel Mixing
当使用普通BiLSTM层时,Sequencer Block称为Vanilla Sequencer block;当使用BiLSTM2D层作为Sequencer Block时,Sequencer Block称为Sequencer2D block。最后一个块的输出通过全局平均池化层送到线性分类器。
2、BiLSTM2D layer
作者提出了BiLSTM2D层作为一种有效Mixing二维空间信息的技术。它有2个普通的BiLSTM,一个垂直的BiLSTM和一个水平的BiLSTM。
对于输入
402 Payment Required
被视为一组序列,其中 是垂直方向上的Token数量,W是水平方向上的
序列数量,C是通道维度。所有序列 都输入到
垂直BiLSTM中,共享权重和隐藏维度D:
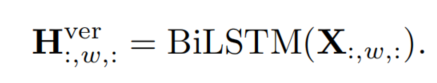
用与上述相似的方式,被视为一组序列,所有序列被输入到水平BiLSTM中,共享权重和隐藏维度D:
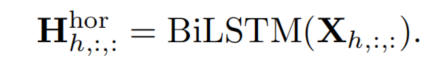
然后将合并到中,同时将合并到。最后送入FC层。这些流程制定如下:

伪代码如下:

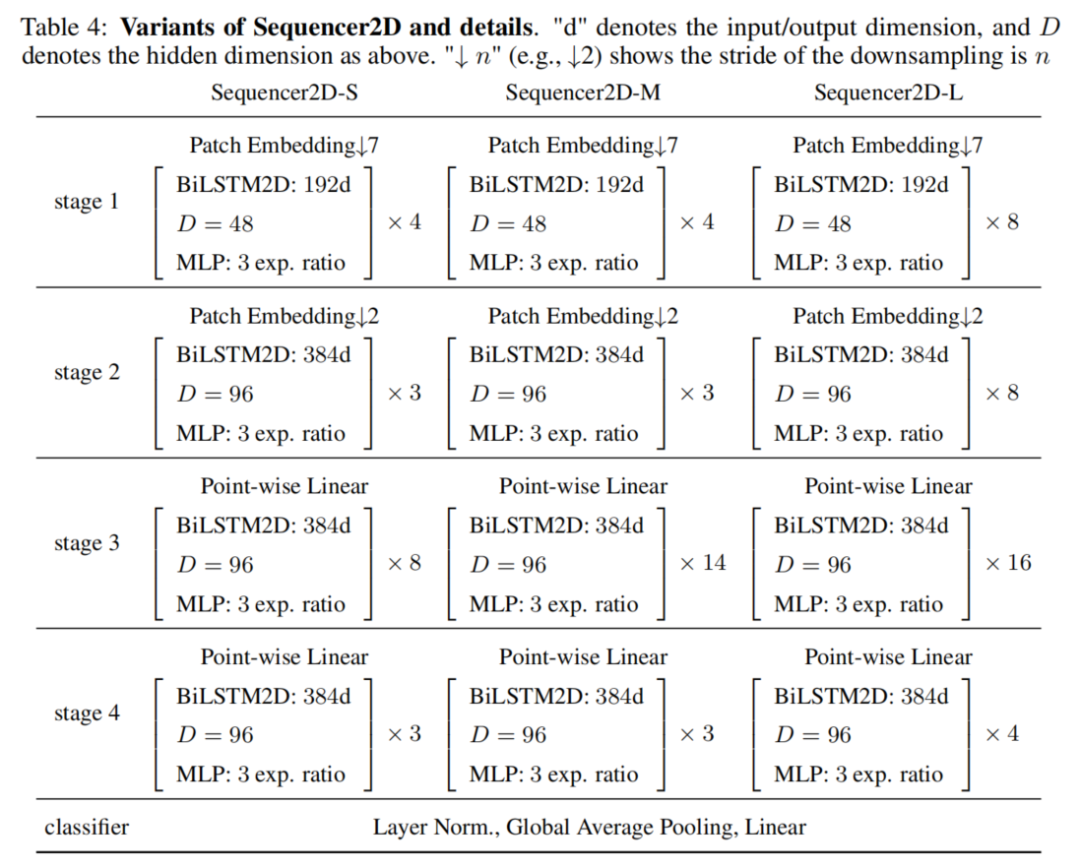
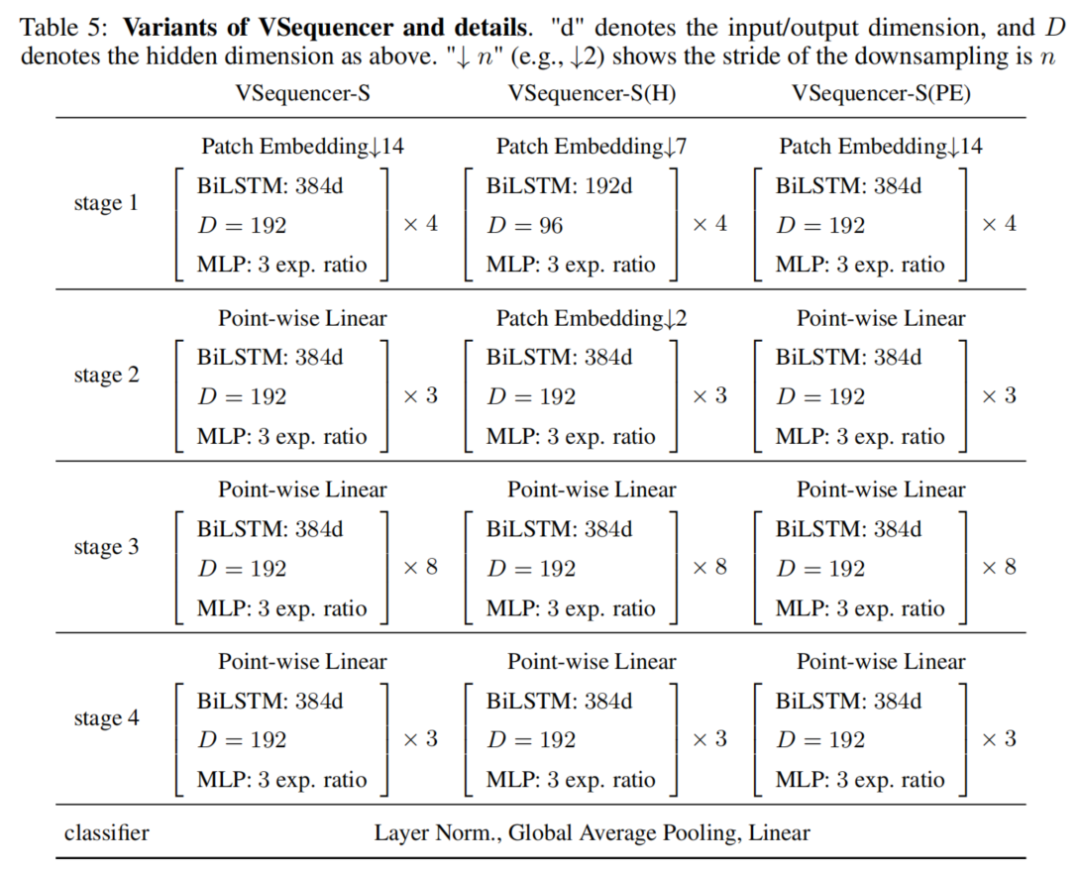
3、架构变体
为了比较由Sequencer 2D组成的不同深度的模型,本文准备了3种不同深度的模型:18、24和36。模型的名称分别为Sequencer2D-S、Sequencer2D-M和Sequencer2D-L。隐藏维度设置为D=C/4。
3实验
3.1 ImageNet-1K
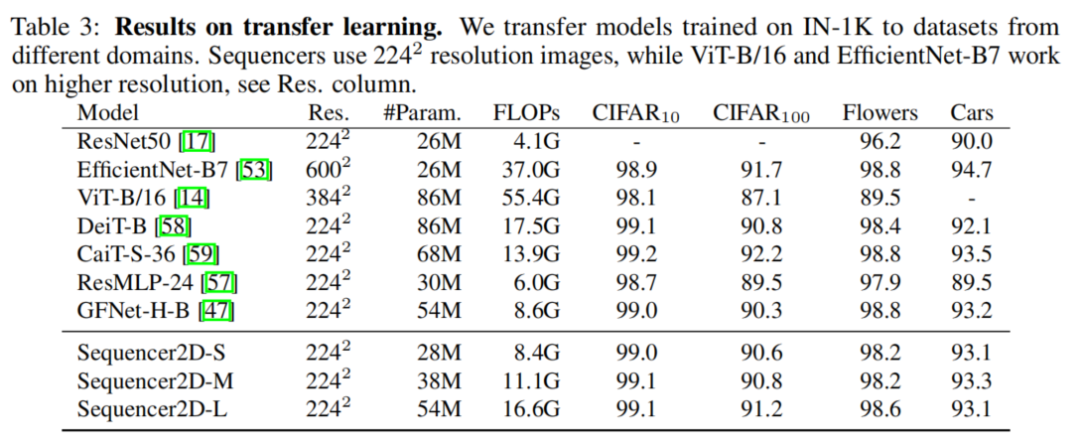
3.2 迁移学习
3.3 稳健性实验

3.4 可视化分析
一般来说,CNN具有局部化的、逐层扩展的感受野,而没有移动窗口的ViT捕获的是全局依赖。相比之下,作者Sequencer不清楚信息是如何处理的。因此作者计算了ResNet-50、DeiT-S和Sequencer2D-S的ERF,如图5所示。

Sequencer2D-S的ERFs在所有层中形成十字形。这一趋势使其不同于DeiT-S和ResNet-50等著名模型。更值得注意的是,在浅层中,Sequencer2D-S比ResNet-50的ERF更宽,尽管没有DeiT那么宽。这一观察结果证实了Sequencer中的lstm可以像预期的那样建模长期依赖关系,并且Sequencer可以识别足够长的垂直或水平区域。因此,可以认为,Sequencer识别图像的方式与CNN或ViT非常不同。
Sequencer论文PDF下载
后台回复:Sequencer,即可下载上面论文
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()