学Python数据科学,玩游戏、学日语、搞编程一条龙。
整套学习自学教程中应用的数据都是《三國志》、《真·三國無雙》系列游戏中的内容。
Pandas 是一个 Python 数据分析库,提供便于数据分析的功能。它提供了一种独特的数据结构,例如数据框(DataFrame),可以进行各种处理。
对于数据框(DataFrame)的表格数据可以像 SQL 或 R 一样进行高速处理操作。
还提供统计方法、启用绘图等功能。Pandas 的一项重要功能是能够编写和读取 Excel、CSV 和许多其他类型的文件并且能有效地进行处理文件。

文章目录
pandas 的安装
在开发环境命令行输入。如果默认用的 Anaconda 安装的话可以略过此过程。
pip install pandas
数据的准备
使用《三國志 13》wiki百科抓取人物的数据(人物详情数据.xlsx),数据的列的说明如下:
基本信息列:名前、字、読み、性別、生年、登場、没年、寿命、死因、父親、母親、相性、列伝。
内政能力列:商業、農業、文化、訓練、巡察、説破、交渉、弁舌、人徳。
军事能力列:威風、神速、奮戦、連戦、攻城、兵器、堅守、水連、一騎、豪傑、鬼謀。
其他信息列:音声、武器、性格、義理、勇愛、才愛、分類、武具興味、書物興味、宝物興味、酒興味、物欲。

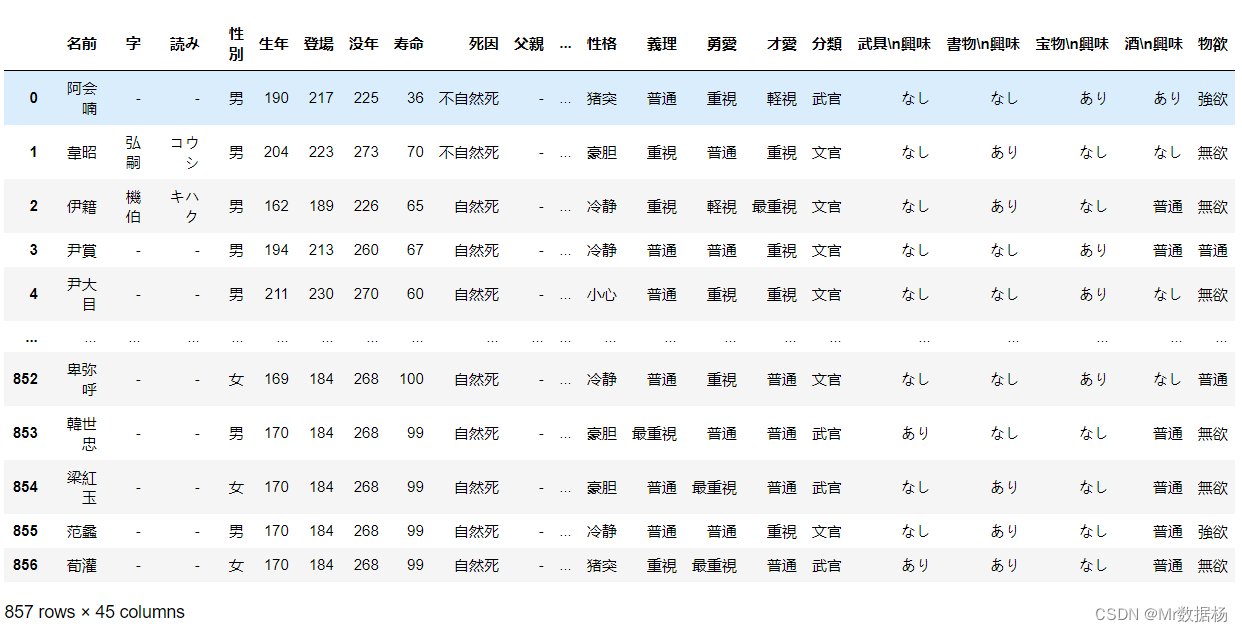
先将数据保存到df中。
import pandas as pd
df = pd.read_excel("Romance of the Three Kingdoms 13/人物详情数据.xlsx")
df
CSV文件的写入和读取
上一章节介绍了 CSV 文件的读写操作 在Python中读取和写入操作CSV文件方法详解,这里复习一下。
CSV 文件的每一行代表一个表格行。默认情况下同一行中的值用逗号分隔,也可以将分隔符更改为分号、制表符、空格或其他字符。
编写 CSV 文件
使用 to_csv() 方法进行文件生成。
df.to_csv('temp_data/data.csv')

此文本文件包含用逗号分隔的数据。第一列包含行索引,可以使用 index=False 方法不保留该索引。
读取 CSV 文件
将数据保存在 CSV 文件中后,可能需要不时加载和使用。要使用到 read_csv() 方法。
df = pd.read_csv('temp_data/data.csv', index_col=0)
df
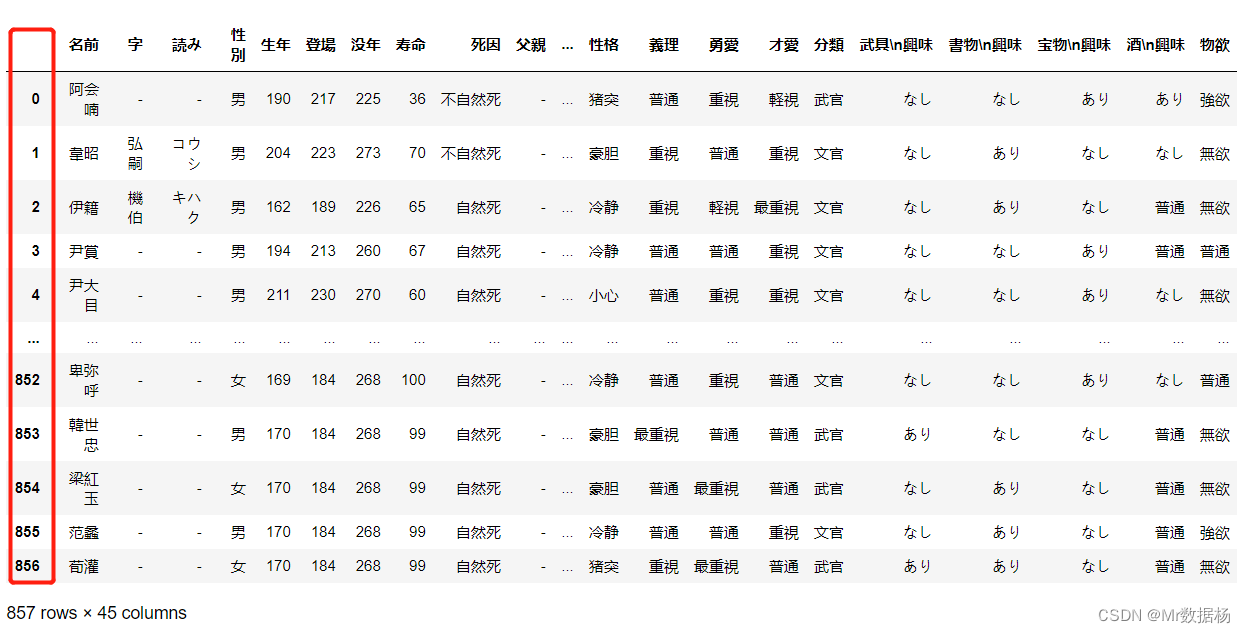
index_col = 0 的作用在行索引的列编号或者列名的指定,如果没有指定则会自动生成一列作为索引。
Excel文件的写入和读取
Microsoft Excel 是当下使用最广泛的电子表格软件。虽然旧版本使用二进制 .xls文件,但 Excel 2007 引入了新的基于 XML 的 .xlsx 文件。
在 Pandas 中读取和写入 Excel 文件,类似于 CSV 文件。
很多旧的教程里都会提到一些必备的三方包,例如:
- xlwt 写入 .xls 文件
- openpyx l或 XlsxWriter 写入 .xlsx 文件
- xlrd 读取 Excel 文件
安装这些需要执行下面的命令,如果你是直接安装的 Anacanda 可以省略此步骤。
pip install xlwt openpyxl xlsxwriter xlrd
编写 Excel 文件
使用 to_excel() 方法进行文件生成。
df.to_excel('temp_data/data.xlsx')

第一列包含行索引,可以使用 index=False 方法不保留该索引。
读取 Excel 文件
将数据保存在 Excel 文件中后,可能需要不时加载和使用。要使用到 read_excel() 方法。
df = pd.read_excel('temp_data/data.xlsx', index_col=0)
df
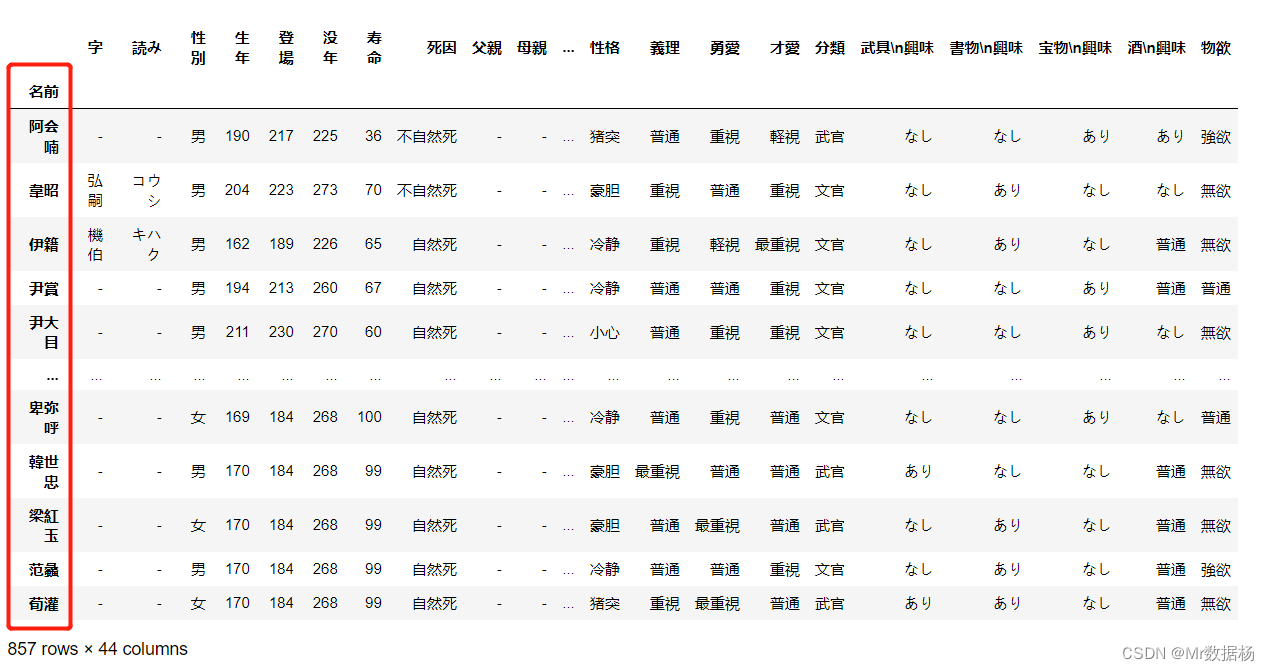
index_col = 0 的作用在行索引的列编号或者列名的指定,如果没有指定则会自动生成一列作为索引。
Pandas IO API
Pandas IO Tools 允许将 Series 和 DataFrame 对象保存到剪贴板、对象或各种类型文件的 API,还支持从剪贴板、对象或文件加载数据。
文件的写入
Series 和 DataFrame 对象具有能够将数据和标签写入剪贴板或文件的方法。以 pattern 命名.to_<file-type>(),其中<file-type>是目标文件的类型。
除了之前介绍的 .to_csv() 和 .to_excel() 以外还有 .to_json()、.to_html()、.to_sql()、.to_pickle() 四种方法。
文件的读取
对应上面文件的写入对应读取的方法也是对应的,read_csv() 和 read_excel() 以外还包括 .read_json()、.read_html()、.read_sql()、.read_pickle() 四种方法
不同文件类型的操作
CSV 文件
.to_csv() 需要在括号中指定文件的路径,并且路径所执行的文件名后缀必须是csv,否则不会创建任何文件。
s = df.to_csv()
print(s)
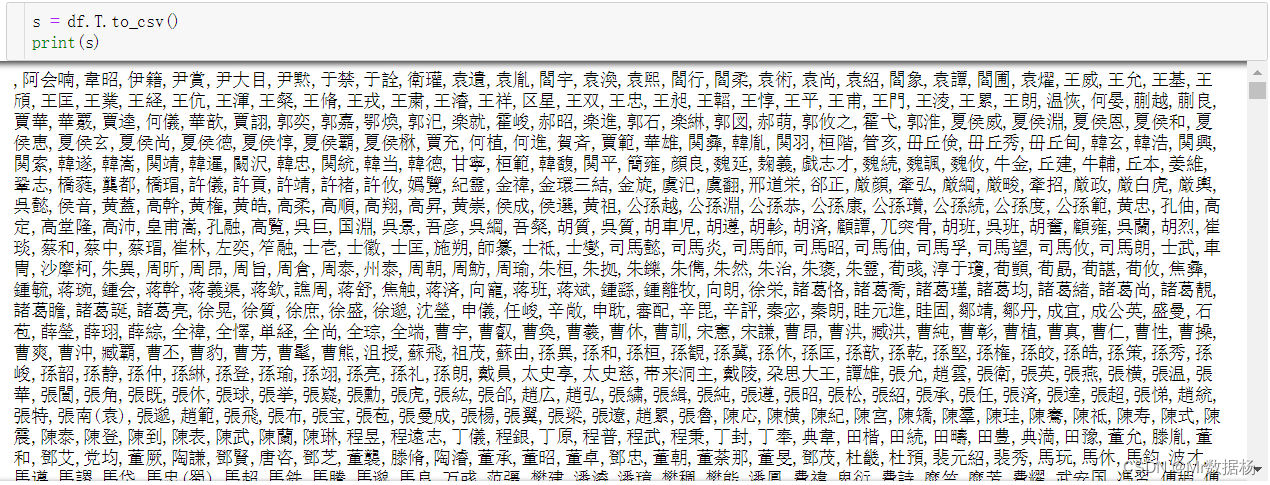
这里的 s 是字符串,而不是 csv 格式文件。
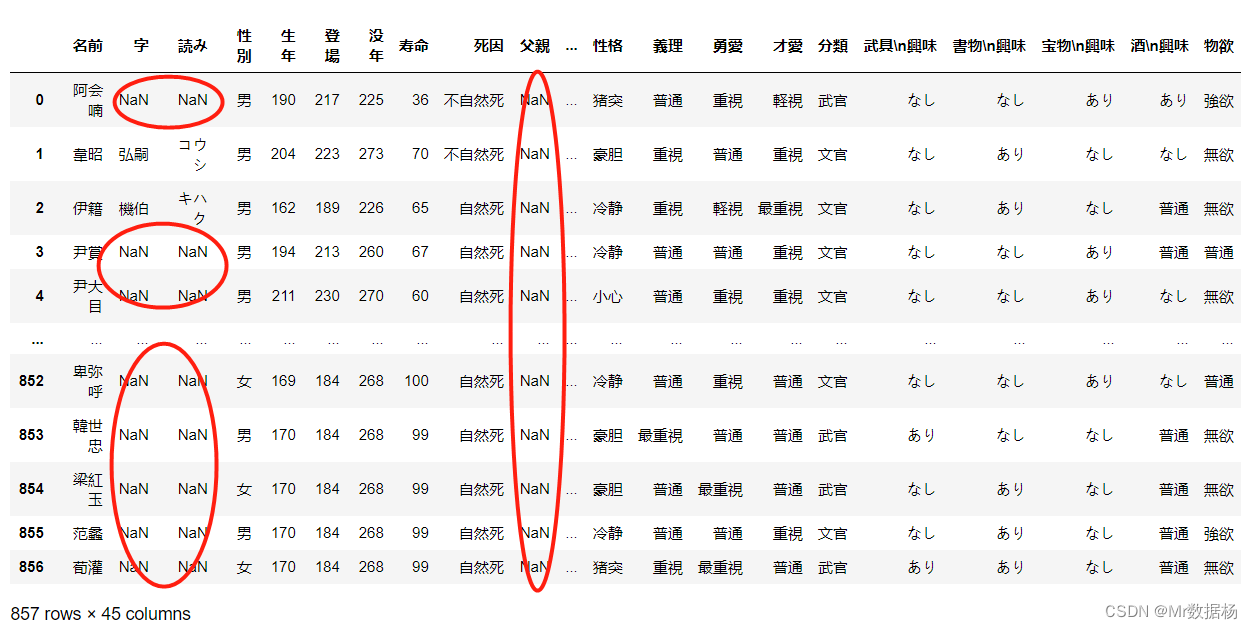
在未来进行数据分析、机器学习、深度学习业务的时候缺失值是一定要处理的。可以使用 pandas 自带处理缺失值的功能。不过首先要知道缺失值使用 nan(float型) 表示的,可以通过 float(‘nan’)、math.nan、numpy.nan 这三种方法获取对应的值。
对于该数据是完整的不存在缺失值,这里将单元格中 - 的数据转换成 nan 数据,制作一份包含缺失数据的内容(手动清空 data.xlsx 中的 - 数据)。
df = pd.read_excel('temp_data/data.xlsx')
df
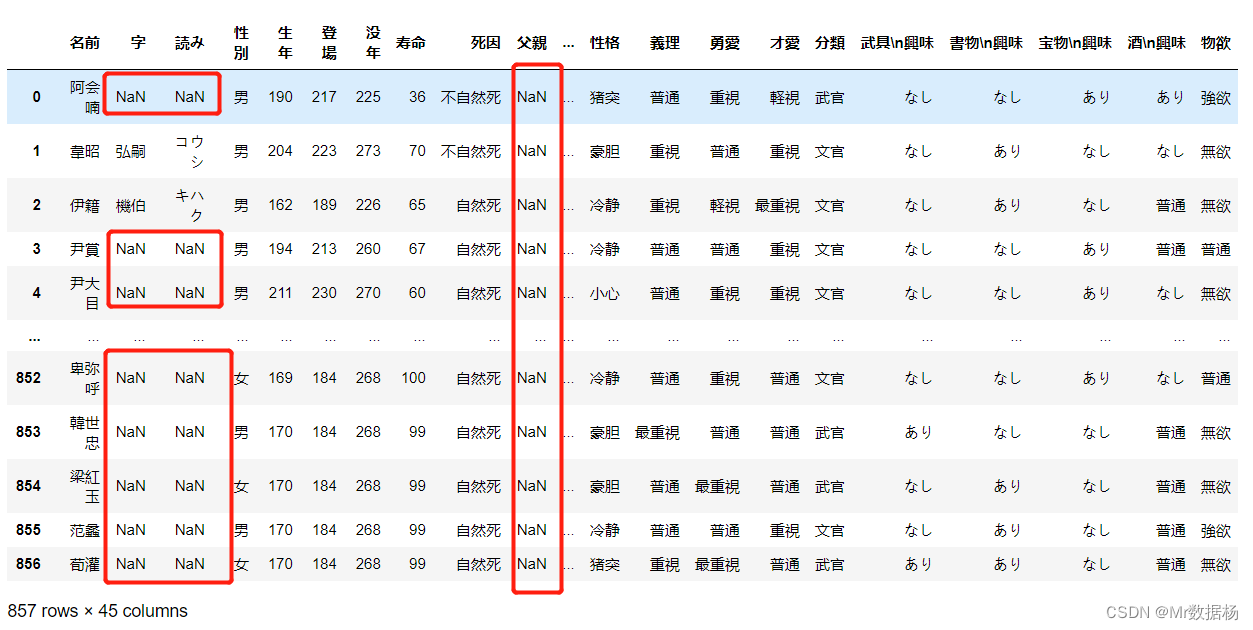
对于保存 CSV 文件时想要标记出来缺失值的位置可以使用 na_rep 进行赋值的方法。
df.to_csv('temp_data/new-data.csv', na_rep='(missing)')

Pandas 读取文件时默认将空字符串 ( ‘’ ) 和 ‘nan’、‘-nan’、‘NA’、‘N/A’、‘NaN’、‘null’ 视为缺失值。如果不想进行默认替换的话可以使用 keep_default_na=False(默认),如果需要替换成其他的标签可以使用 na_values。
Pandas在读取文件时将其 ‘(missing)’ 替换为 nan 。
pd.read_csv('temp_data/new-data.csv', index_col=0, na_values='(missing)')
当数据读取加载成功后,默认的会分配数据类型到每个列,可以使用 .dtype 进行查看。
df = pd.read_csv('temp_data/data.csv', index_col=0)
df.dtypes
名前 object
字 object
読み object
性別 object
生年 int64
登場 int64
没年 int64
寿命 int64
死因 object
父親 object
母親 object
相性 object
列伝 object
商業 int64
農業 int64
文化 int64
訓練 int64
巡察 int64
説破 int64
交渉 int64
弁舌 int64
人徳 int64
威風 int64
神速 int64
奮戦 int64
連戦 int64
攻城 int64
兵器 int64
堅守 int64
水連 int64
一騎 int64
豪傑 int64
鬼謀 int64
音声 object
武器 object
性格 object
義理 object
勇愛 object
才愛 object
分類 object
武具\n興味 object
書物\n興味 object
宝物\n興味 object
酒\n興味 object
物欲 object
dtype: object
使用 dtype 来指定所需的数据类型,也可以使用 parse_date 强制转换r日期数据类型,并且日数据可以进行格式化操作。
保存 csv 文件的时还可以使用其他一些参数。
- sep 表示值分隔符。
- decimal 表示小数分隔符。
- encoding 设置文件编码。
- header 指定是否要在文件中写入列标签。
s = df.to_csv(sep=';', header=False)
print(s)

JSON 文件
JSON 是 JavaScript 对象表示法。JSON 文件是用于数据交换的明文文件,遵循 ISO/IEC 21778:2017 和 ECMA-404标准 并使用 .json 作为后缀扩展名。Python 和 Pandas 提供了 json 的内置支持并且可以很好地处理 JSON 文件。
为了方便显示数据,提取几个列的数据进行展示。
df = df[['名前', '字', '読み', '性別', '生年', '登場', '没年', '寿命', '死因']]
.to_json() 保存数据到 json 文件。
df.head().T.to_json('temp_data/data-columns.json',force_ascii=False)

index 结构 json 模式。
df.head().T.to_json('temp_data/data-index.json', orient='index',force_ascii=False)

records 结构 json 模式。
df.head().T.to_json('temp_data/data-records.json', orient='records',force_ascii=False)

split 结构 json 模式。
df.head().T.to_json('temp_data/data-split.json', orient='split',force_ascii=False)

JSON 格式存储数据时,可能会丢失行和列的顺序,可以实现构建一列索引记录数据的顺序。
保存 json 文件的时还可以使用其他一些参数。
- encoding 设置编码。
- convert_dates 设置日期格式。
- dtype 和 precise_float 设置数据的精度。
- . 将数字数据直接解码为 NumPy 数组(numpy=True)。
HTML 文件
HTML是一个纯文本文件,使用超文本标记语言在浏览器呈现网页。HTML 文件的扩展名是 .html 和 .htm。需要安装 lxml 或者 html5lib 才能处理和解析 HTML 文件。
pip install lxml html5lib
.to_html() 保存数据到 html 文件。
df = pd.DataFrame(data).T
df.to_html('temp_data/data.html')
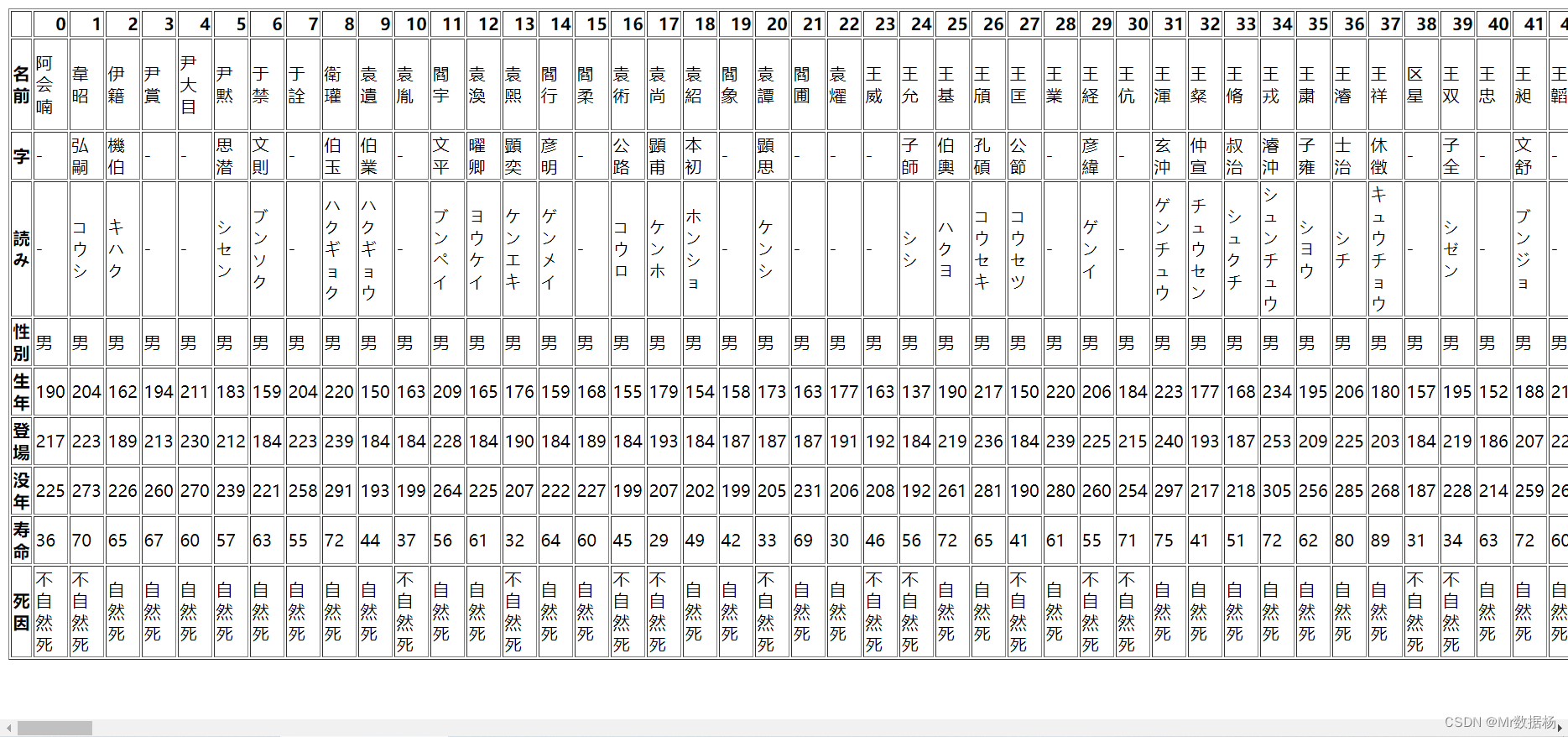
保存 html 文件的时还可以使用其他一些参数。
- header 是否保存列名。
- index 是否保存行标签。
- classes 分配级联样式表 CSS 类。
- render_links 指定是否将 URL 转换为 HTML 链接。
- table_id 将 CSS 分配给id标签table。
- escape 决定是否将字符<、>和转换&为 HTML 安全字符串。
Excel 文件
to_excel() 进行 excel 保存的时候还可以指定对应的 sheet 名。
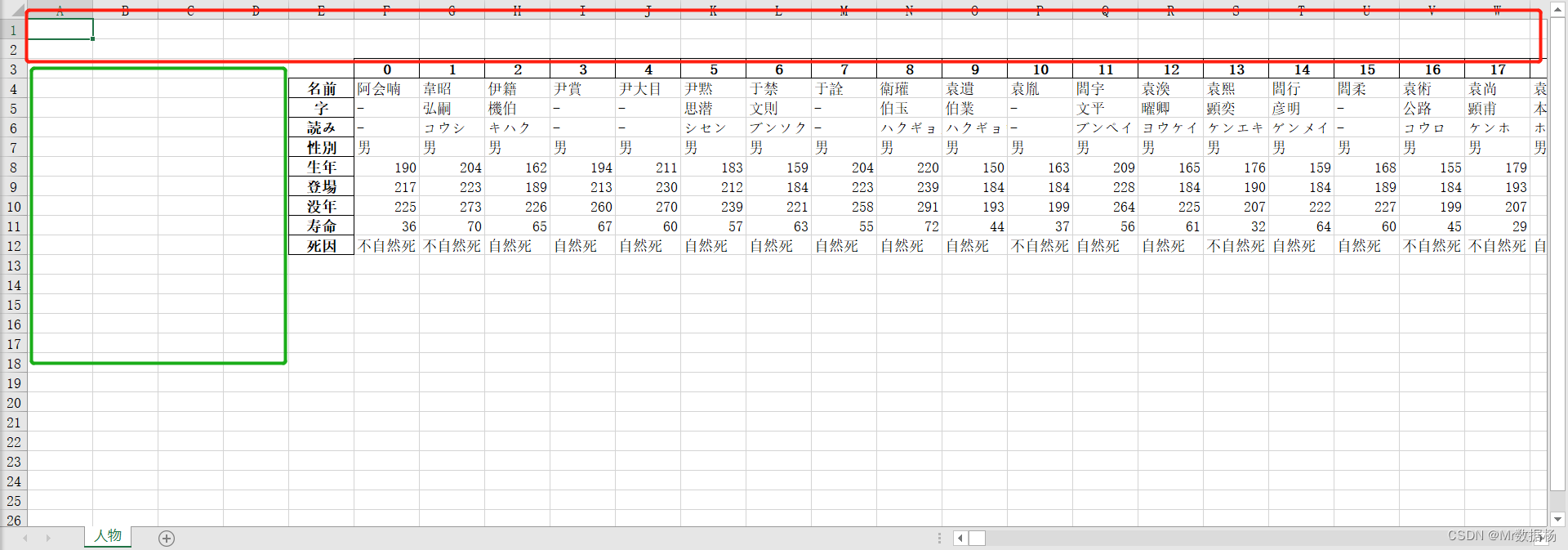
df.T.to_excel('temp_data/data.xlsx', sheet_name='人物')
并且还可以指定最开始写入的单元格。
df.T.to_excel('data-shifted.xlsx', sheet_name='人物',startrow=2, startcol=4)
SQL 文件
Pandas IO 工具还可以读写数据库,需要使用 SQLAlchemy 进行操作。并且 Python 有一个内置的 SQLite 驱动程序。
安装 SQLAlchemy。
pip install sqlalchemy
使用 create_engine() 导入并创建数据库引擎。
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://user:password@localhost/sanguo?charset=utf8')
.to_sql() 保存数据。
df.to_sql('table', con=engine,if_exists='append',index=0)
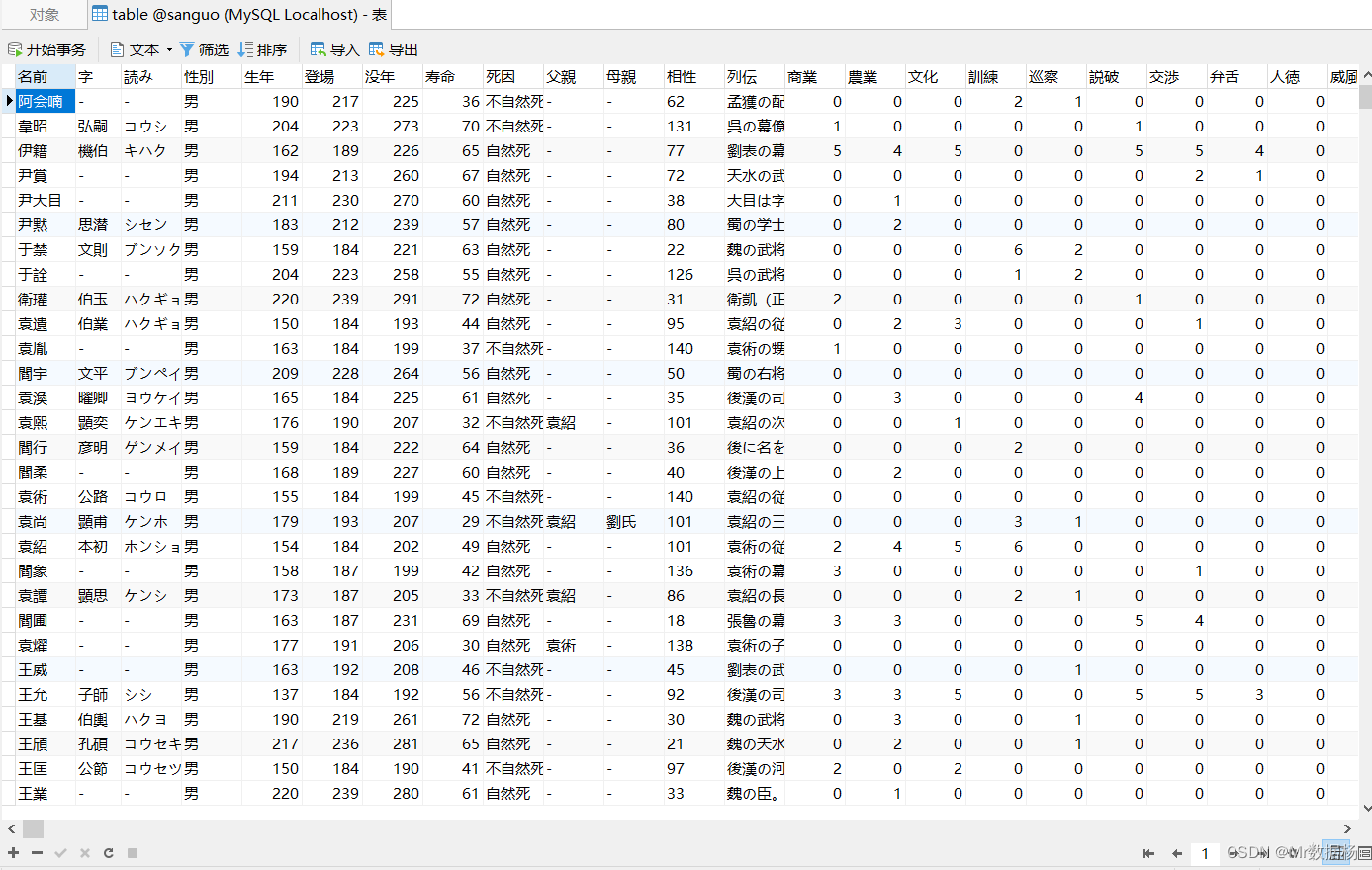
具有相同名称和路径的数据库可以使用的操作有:
- if_exists=‘fail’ 引发ValueError错误。
- if_exists=‘replace’ 删除表并插入新值。
- if_exists=‘append’ 将新值插入表中。
Pickle 文件
Pickling 是将 Python 对象转换为字节流的行为。Python pickle 文件是保存 Python 对象的数据和层次结构的二进制文件,通常具有扩展名 .pickle 或 .pkl。
.to_pickle() 保存数据。
df.to_pickle('temp_data/data.pickle')
使用 read_pickle() 从 pickle 文件中获取数据。
df = pd.read_pickle('temp_data/data.pickle')
海量数据的应用
如果文件太大而无法保存或处理,可以采取多种方法来减少所需的磁盘空间的处理方式,例如:压缩文件、只选择你想要的列、省略不需要的行、强制使用不太精确的数据类型、将数据拆分成块 等方式。
压缩和解压缩文件
常用的文件后缀包括 ‘.gz’、‘.bz2’、‘.zip’、‘.xz’。
Pandas 数据保存的时候可以自行推断压缩类型。
import pandas as pd
df.to_csv('temp_data/data.csv')
df.to_csv('temp_data/data.csv.zip')
df.to_csv('temp_data/data.csv.gz')
df.to_csv('temp_data/data.csv.xz')
df.to_csv('temp_data/data.csv.bz2')
对比一下不同的保存方式。
然后可以使用 read_csv() 读取该文件。
df = pd.read_csv('temp_data/data.csv.zip', index_col=0)
可以使用可选参数指定压缩类型,其中可选参数有:‘infer’、‘gzip’、‘bz2’、‘zip’、‘xz’、None。
pickle的文件压缩方法写入和读取的方法。
df = pd.DataFrame(data).T
df.to_pickle('temp_data/data.pickle.compress', compression='gzip')
df = pd.read_pickle('temp_data/data.pickle.compress', compression='gzip')
数据列的选取
可以使用 usecols 从加载文件中选择要读取的数据列。
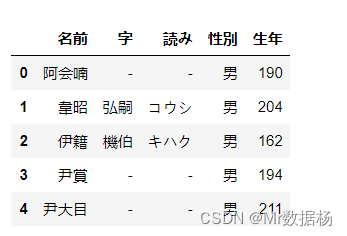
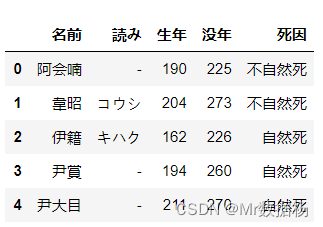
df = pd.read_csv('temp_data/data.csv', usecols=['名前', '字'])
df.head(5)
也可以用使用列索引的方式读取数据。
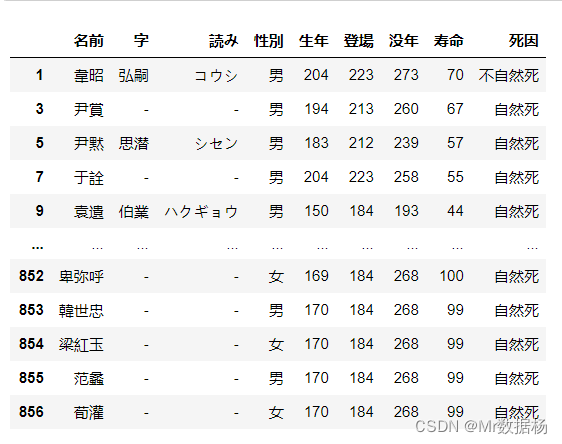
df = pd.read_csv('temp_data/data.csv',index_col=0, usecols=[0, 1, 3])
df.head(5)
行省略
当数据应用与机器学习和深度学习模型的时候,可能不需要全部的数据集用于计算,仅仅加载需要计算容量的数据即可,因此可以使用选择行数据的方式进行。一般方式有3种:
- skiprows:在文件开头要跳过的行数,或者如果是类似列表的对象,则要跳过的行的从零开始的索引。
- skipfooter:文件末尾要跳过的行数。
- nrows:要读取的行数。
结合 range() 跳过奇数索引的行,保留偶数的行。
df = pd.read_csv('temp_data/data.csv', index_col=0, skiprows=range(1, 20, 2))
强制使用不太精确的数据类型
这样做的最大好处就是可以节省大量的内存。
df.dtypes
名前 object
字 object
読み object
性別 object
生年 int64
登場 int64
没年 int64
寿命 int64
死因 object
dtype: object
例如带有浮点数的列是 64 位浮点数,这种类型的每个数字 float64 占用 64 位或 8 个字节。如果是列是 32 位浮点数,这种类型的每个数字 float32 占用 32 位或 4 个字节。
表示的内容是一样的,但是内存空间节省了一半。
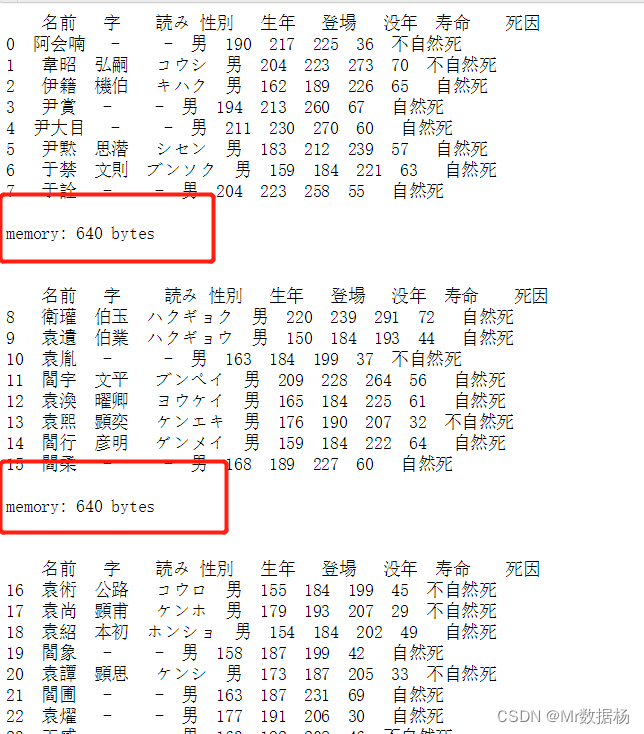
chunksize 块遍历
chunksize 可以将数据拆分为较小的块并一次处理一个块。
data_chunk = pd.read_csv('temp_data/data.csv', index_col=0, chunksize=8)
data_chunk
<pandas.io.parsers.TextFileReader at 0x2587ef8a390>
可以结合 for 循环的方式拼接数据汇总要读取的全体数据信息。
for df_chunk in pd.read_csv('temp_data/data.csv', index_col=0, chunksize=8):
print(df_chunk, end='\n\n')
print('memory:', df_chunk.memory_usage().sum(), 'bytes',
end='\n\n\n')