Pandas 是 Python 的一个功能强大且灵活的三方包,可处理标记和时间序列数据。还提供统计方法、启用绘图等功能。Pandas 的一项重要功能是能够编写和读取 Excel、CSV 和许多其他类型的文件并且能有效地进行处理文件。

文章目录
pandas 的安装
在你所在的开发环境命令行输入。如果默认用的Anaconda安装的话可以略过此过程。
pip install pandas
数据的准备
使用 20 个国家/地区相关的数据。数据的列的说明如下:
- Country 表示国家名称。
- Population 单位百万计算。
- Area 千平方公里为单位。
- GDP 国内生产总值以百万美元表示。
- Continent 非洲、亚洲、大洋洲、欧洲、北美洲或南美洲。
- Independence day 独立日是纪念一个国家独立的日子。
| SHORT_NAME | COUNTRY | POP | AREA | GDP | CONT | IND_DAY |
|---|---|---|---|---|---|---|
| CHN | China | 1398.72 | 9596.96 | 12234.78 | Asia | 1949-10-01 |
| IND | India | 1351.16 | 3287.26 | 2575.67 | Asia | 1947-08-15 |
| USA | US | 329.74 | 9833.52 | 19485.39 | N.America | 1776-07-04 |
| IDN | Indonesia | 268.07 | 1910.93 | 1015.54 | Asia | 1945-08-17 |
| BRA | Brazil | 210.32 | 8515.77 | 2055.51 | S.America | 1822-09-07 |
| PAK | Pakistan | 205.71 | 881.91 | 302.14 | Asia | 1947-08-14 |
| NGA | Nigeria | 200.96 | 923.77 | 375.77 | Africa | 1960-10-01 |
| BGD | Bangladesh | 167.09 | 147.57 | 245.63 | Asia | 1971-03-26 |
| RUS | Russia | 146.79 | 17098.25 | 1530.75 | 1992-06-12 | |
| MEX | Mexico | 126.58 | 1964.38 | 1158.23 | N.America | 1810-09-16 |
| JPN | Japan | 126.22 | 377.97 | 4872.42 | Asia | |
| DEU | Germany | 83.02 | 357.11 | 3693.2 | Europe | |
| FRA | France | 67.02 | 640.68 | 2582.49 | Europe | 1789-07-14 |
| GBR | UK | 66.44 | 242.5 | 2631.23 | Europe | |
| ITA | Italy | 60.36 | 301.34 | 1943.84 | Europe | |
| ARG | Argentina | 44.94 | 2780.4 | 637.49 | S.America | 1816-07-09 |
| DZA | Algeria | 43.38 | 2381.74 | 167.56 | Africa | 1962-07-05 |
| CAN | Canada | 37.59 | 9984.67 | 1647.12 | N.America | 1867-07-01 |
| AUS | Australia | 25.47 | 7692.02 | 1408.68 | Oceania | |
| KAZ | Kazakhstan | 18.53 | 2724.9 | 159.41 | Asia | 1991-12-16 |
看到上面的数据有部分是丢失的。使用嵌套字典的方式记录这些数据。
data = {
'CHN': {
'COUNTRY': 'China', 'POP': 1_398.72, 'AREA': 9_596.96,
'GDP': 12_234.78, 'CONT': 'Asia', 'IND_DAY': '1949-10-01'},
'IND': {
'COUNTRY': 'India', 'POP': 1_351.16, 'AREA': 3_287.26,
'GDP': 2_575.67, 'CONT': 'Asia', 'IND_DAY': '1947-08-15'},
'USA': {
'COUNTRY': 'US', 'POP': 329.74, 'AREA': 9_833.52,
'GDP': 19_485.39, 'CONT': 'N.America',
'IND_DAY': '1776-07-04'},
'IDN': {
'COUNTRY': 'Indonesia', 'POP': 268.07, 'AREA': 1_910.93,
'GDP': 1_015.54, 'CONT': 'Asia', 'IND_DAY': '1945-08-17'},
'BRA': {
'COUNTRY': 'Brazil', 'POP': 210.32, 'AREA': 8_515.77,
'GDP': 2_055.51, 'CONT': 'S.America', 'IND_DAY': '1822-09-07'},
'PAK': {
'COUNTRY': 'Pakistan', 'POP': 205.71, 'AREA': 881.91,
'GDP': 302.14, 'CONT': 'Asia', 'IND_DAY': '1947-08-14'},
'NGA': {
'COUNTRY': 'Nigeria', 'POP': 200.96, 'AREA': 923.77,
'GDP': 375.77, 'CONT': 'Africa', 'IND_DAY': '1960-10-01'},
'BGD': {
'COUNTRY': 'Bangladesh', 'POP': 167.09, 'AREA': 147.57,
'GDP': 245.63, 'CONT': 'Asia', 'IND_DAY': '1971-03-26'},
'RUS': {
'COUNTRY': 'Russia', 'POP': 146.79, 'AREA': 17_098.25,
'GDP': 1_530.75, 'IND_DAY': '1992-06-12'},
'MEX': {
'COUNTRY': 'Mexico', 'POP': 126.58, 'AREA': 1_964.38,
'GDP': 1_158.23, 'CONT': 'N.America', 'IND_DAY': '1810-09-16'},
'JPN': {
'COUNTRY': 'Japan', 'POP': 126.22, 'AREA': 377.97,
'GDP': 4_872.42, 'CONT': 'Asia'},
'DEU': {
'COUNTRY': 'Germany', 'POP': 83.02, 'AREA': 357.11,
'GDP': 3_693.20, 'CONT': 'Europe'},
'FRA': {
'COUNTRY': 'France', 'POP': 67.02, 'AREA': 640.68,
'GDP': 2_582.49, 'CONT': 'Europe', 'IND_DAY': '1789-07-14'},
'GBR': {
'COUNTRY': 'UK', 'POP': 66.44, 'AREA': 242.50,
'GDP': 2_631.23, 'CONT': 'Europe'},
'ITA': {
'COUNTRY': 'Italy', 'POP': 60.36, 'AREA': 301.34,
'GDP': 1_943.84, 'CONT': 'Europe'},
'ARG': {
'COUNTRY': 'Argentina', 'POP': 44.94, 'AREA': 2_780.40,
'GDP': 637.49, 'CONT': 'S.America', 'IND_DAY': '1816-07-09'},
'DZA': {
'COUNTRY': 'Algeria', 'POP': 43.38, 'AREA': 2_381.74,
'GDP': 167.56, 'CONT': 'Africa', 'IND_DAY': '1962-07-05'},
'CAN': {
'COUNTRY': 'Canada', 'POP': 37.59, 'AREA': 9_984.67,
'GDP': 1_647.12, 'CONT': 'N.America', 'IND_DAY': '1867-07-01'},
'AUS': {
'COUNTRY': 'Australia', 'POP': 25.47, 'AREA': 7_692.02,
'GDP': 1_408.68, 'CONT': 'Oceania'},
'KAZ': {
'COUNTRY': 'Kazakhstan', 'POP': 18.53, 'AREA': 2_724.90,
'GDP': 159.41, 'CONT': 'Asia', 'IND_DAY': '1991-12-16'}
}
columns = ('COUNTRY', 'POP', 'AREA', 'GDP', 'CONT', 'IND_DAY')
通过创建 pandas 实例 DataFrame 加载 data 数据。
import pandas as pd
df = pd.DataFrame(data).T
df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.8 Asia NaN
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.4 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.2 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.2 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.5 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.4 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.9 159.41 Asia 1991-12-16
CSV文件的写入和读取
逗号分隔值 (CSV) 是包含.csv包含表格数据的扩展名的纯文本文件。用于存储大量数据的最流行的文件格式之一。CSV 文件的每一行代表一个表格行。默认情况下同一行中的值用逗号分隔,也可以将分隔符更改为分号、制表符、空格或其他字符。
编写 CSV 文件
使用 to_csv() 方法进行文件生成。
df.to_csv('data.csv')
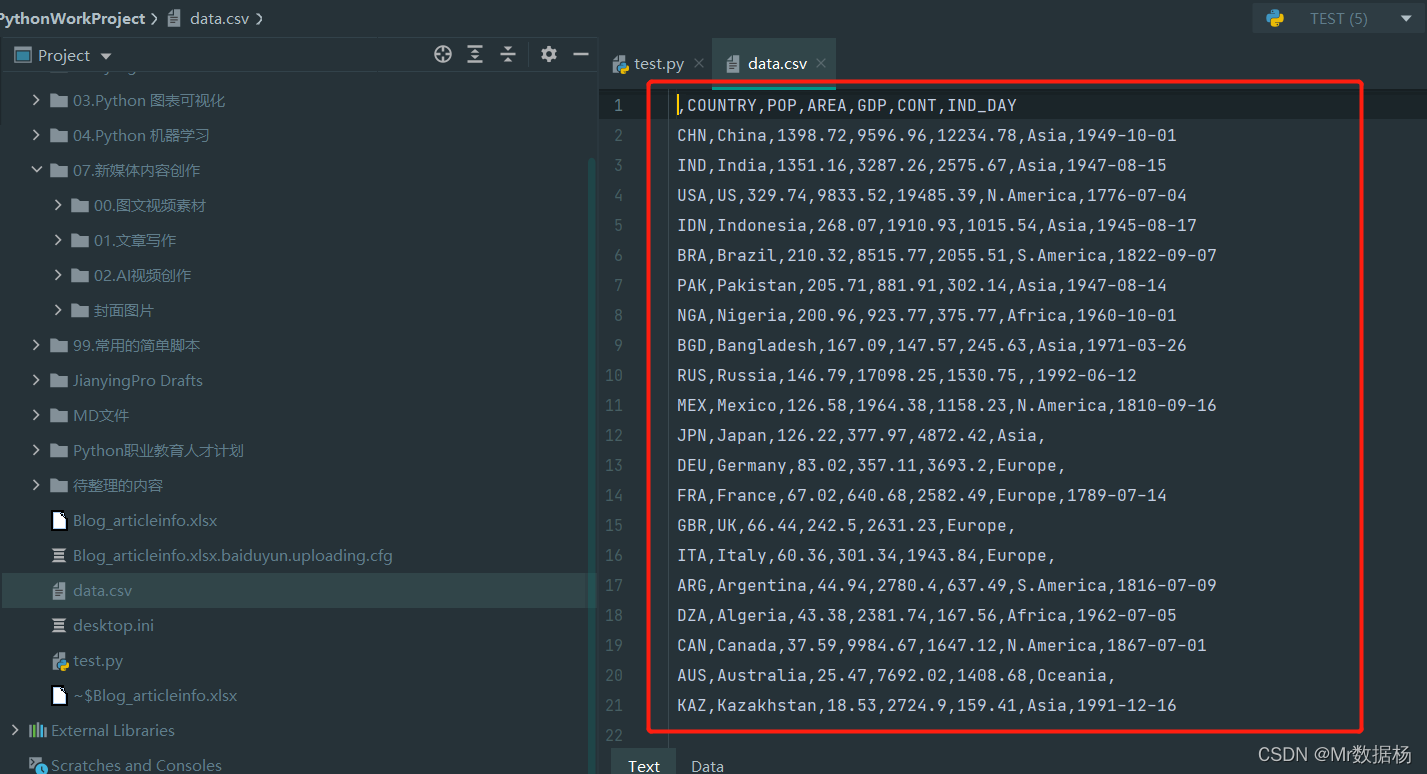
此文本文件包含用逗号分隔的数据。第一列包含行索引,可以使用 index=False 方法不保留该索引。
读取 CSV 文件
将数据保存在 CSV 文件中后,可能需要不时加载和使用。要使用到 read_csv() 方法。
df = pd.read_csv('data.csv', index_col=0)
print(df)
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia 1949-10-01
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.20 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
index_col = 0 的作用在行索引的列编号或者列名的指定,如果没有指定则会自动生成一列作为索引。
Excel文件的写入和读取
Microsoft Excel 是当下使用最广泛的电子表格软件。虽然旧版本使用二进制.xls文件,但 Excel 2007 引入了新的基于 XML 的.xlsx文件。可以在 Pandas 中读取和写入 Excel 文件,类似于 CSV 文件。
很多旧的教程里都会提到一些必备的三方包,例如:
- xlwt 写入 .xls 文件
- openpyx l或 XlsxWriter 写入 .xlsx 文件
- xlrd 读取 Excel 文件
安装这些需要执行下面的命令,如果你是直接安装的Anacanda可以省略此步骤。
pip install xlwt openpyxl xlsxwriter xlrd
编写 Excel 文件
使用 to_excel() 方法进行文件生成。
df.to_excel('data.xlsx')
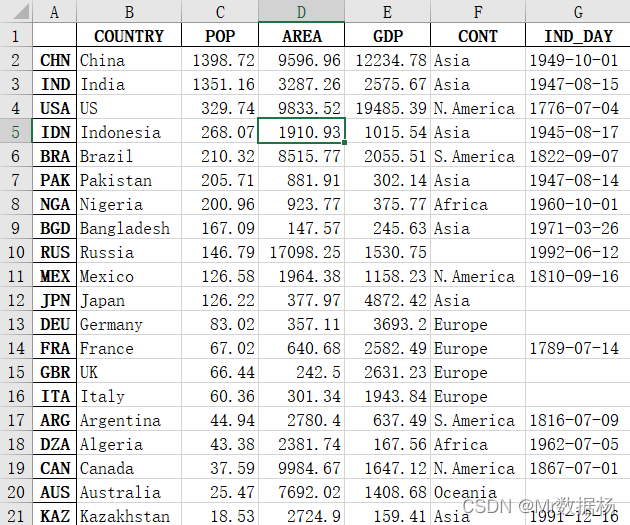
读取 Excel 文件
将数据保存在 Excel 文件中后,可能需要不时加载和使用。要使用到 read_excel() 方法。
>>> df = pd.read_excel('data.xlsx', index_col=0)
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia 1949-10-01
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.20 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
Pandas IO API
Pandas IO Tools 允许将 Series 和 DataFrame 对象保存到剪贴板、对象或各种类型文件的 API,还支持从剪贴板、对象或文件加载数据。
文件的写入
Series 和 DataFrame 对象具有能够将数据和标签写入剪贴板或文件的方法。以 pattern 命名.to_<file-type>(),其中<file-type>是目标文件的类型。
除了之前介绍的 .to_csv() 和 .to_excel() 以外还有 .to_json()、.to_html()、.to_sql()、.to_pickle() 四种方法。
文件的读取
对应上面文件的写入对应读取的方法也是对应的,read_csv() 和 read_excel() 以外还包括 .read_json()、.read_html()、.read_sql()、.read_pickle() 四种方法
不同文件类型的操作
CSV 文件
.to_csv() 需要在括号中指定文件的路径,并且路径所执行的文件名后缀必须是csv,否则不会创建任何文件。
df = pd.DataFrame(data).T
s = df.to_csv()
print(s)
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,1949-10-01
IND,India,1351.16,3287.26,2575.67,Asia,1947-08-15
USA,US,329.74,9833.52,19485.39,N.America,1776-07-04
IDN,Indonesia,268.07,1910.93,1015.54,Asia,1945-08-17
BRA,Brazil,210.32,8515.77,2055.51,S.America,1822-09-07
PAK,Pakistan,205.71,881.91,302.14,Asia,1947-08-14
NGA,Nigeria,200.96,923.77,375.77,Africa,1960-10-01
......
这里的 s 是字符串,而不是 csv 格式文件。
这时候会发现数据中会有缺失值,在未来进行数据分析、机器学习、深度学习业务的时候缺失值是一定要处理的。可以使用 pandas 自带处理缺失值的功能。不过首先要知道缺失值使用 nan(float型) 表示的,可以通过 float(‘nan’)、math.nan、numpy.nan 这三种方法获取对应的值。
获取 Russia 行 CONT 列的缺失值。
df.loc['RUS', 'CONT']
nan
对于保存 CSV 文件时想要标记出来缺失值的位置可以使用 na_rep 进行赋值的方法。
df.to_csv('new-data.csv', na_rep='(missing)')
......
RUS,Russia,146.79,17098.25,1530.75,(missing),1992-06-12
MEX,Mexico,126.58,1964.38,1158.23,N.America,1810-09-16
JPN,Japan,126.22,377.97,4872.42,Asia,(missing)
DEU,Germany,83.02,357.11,3693.2,Europe,(missing)
......
Pandas 读取文件时默认将空字符串 ( ‘’ ) 和 ‘nan’、’-nan’、‘NA’、‘N/A’、‘NaN’、‘null’ 视为缺失值。如果不想进行默认替换的话可以使用 keep_default_na=False(默认),如果需要替换成其他的标签可以使用 na_values。
Pandas在读取文件时将其 ‘(missing)’ 替换为 nan 。
pd.read_csv('new-data.csv', index_col=0, na_values='(missing)')
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia 1949-10-01
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.20 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
当数据读取加载成功后,默认的会分配数据类型到每个列,可以使用 .dtype 进行查看。
df = pd.read_csv('data.csv', index_col=0)
df.dtypes
COUNTRY object
POP float64
AREA float64
GDP float64
CONT object
IND_DAY object
dtype: object
使用 dtype 来指定所需的数据类型,也可以使用 parse_date 强制转换数据类型。
dtypes = {
'POP': 'float32', 'AREA': 'float32', 'GDP': 'float32'}
df = pd.read_csv('data.csv', index_col=0, dtype=dtypes,parse_dates=['IND_DAY'])
df.dtypes
COUNTRY object
POP float32
AREA float32
GDP float32
CONT object
IND_DAY datetime64[ns]
dtype: object
df['IND_DAY'].head(11)
CHN 1949-10-01
IND 1947-08-15
USA 1776-07-04
IDN 1945-08-17
BRA 1822-09-07
PAK 1947-08-14
NGA 1960-10-01
BGD 1971-03-26
RUS 1992-06-12
MEX 1810-09-16
JPN NaT
并且日数据可以进行格式化操作。
df = pd.read_csv('data.csv', index_col=0, parse_dates=['IND_DAY'])
df.to_csv('formatted-data.csv', date_format='%B %d, %Y')
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,"October 01, 1949"
IND,India,1351.16,3287.26,2575.67,Asia,"August 15, 1947"
USA,US,329.74,9833.52,19485.39,N.America,"July 04, 1776"
IDN,Indonesia,268.07,1910.93,1015.54,Asia,"August 17, 1945"
BRA,Brazil,210.32,8515.77,2055.51,S.America,"September 07, 1822"
PAK,Pakistan,205.71,881.91,302.14,Asia,"August 14, 1947"
NGA,Nigeria,200.96,923.77,375.77,Africa,"October 01, 1960"
BGD,Bangladesh,167.09,147.57,245.63,Asia,"March 26, 1971"
RUS,Russia,146.79,17098.25,1530.75,,"June 12, 1992"
MEX,Mexico,126.58,1964.38,1158.23,N.America,"September 16, 1810"
JPN,Japan,126.22,377.97,4872.42,Asia,
DEU,Germany,83.02,357.11,3693.2,Europe,
FRA,France,67.02,640.68,2582.49,Europe,"July 14, 1789"
GBR,UK,66.44,242.5,2631.23,Europe,
ITA,Italy,60.36,301.34,1943.84,Europe,
ARG,Argentina,44.94,2780.4,637.49,S.America,"July 09, 1816"
DZA,Algeria,43.38,2381.74,167.56,Africa,"July 05, 1962"
CAN,Canada,37.59,9984.67,1647.12,N.America,"July 01, 1867"
AUS,Australia,25.47,7692.02,1408.68,Oceania,
KAZ,Kazakhstan,18.53,2724.9,159.41,Asia,"December 16, 1991"
保存 csv 文件的时还可以使用其他一些参数。
- sep 表示值分隔符。
- decimal 表示小数分隔符。
- encoding 设置文件编码。
- header 指定是否要在文件中写入列标签。
s = df.to_csv(sep=';', header=False)
print(s)
CHN;China;1398.72;9596.96;12234.78;Asia;1949-10-01
IND;India;1351.16;3287.26;2575.67;Asia;1947-08-15
USA;US;329.74;9833.52;19485.39;N.America;1776-07-04
IDN;Indonesia;268.07;1910.93;1015.54;Asia;1945-08-17
BRA;Brazil;210.32;8515.77;2055.51;S.America;1822-09-07
PAK;Pakistan;205.71;881.91;302.14;Asia;1947-08-14
NGA;Nigeria;200.96;923.77;375.77;Africa;1960-10-01
BGD;Bangladesh;167.09;147.57;245.63;Asia;1971-03-26
RUS;Russia;146.79;17098.25;1530.75;;1992-06-12
MEX;Mexico;126.58;1964.38;1158.23;N.America;1810-09-16
JPN;Japan;126.22;377.97;4872.42;Asia;
DEU;Germany;83.02;357.11;3693.2;Europe;
FRA;France;67.02;640.68;2582.49;Europe;1789-07-14
GBR;UK;66.44;242.5;2631.23;Europe;
ITA;Italy;60.36;301.34;1943.84;Europe;
ARG;Argentina;44.94;2780.4;637.49;S.America;1816-07-09
DZA;Algeria;43.38;2381.74;167.56;Africa;1962-07-05
CAN;Canada;37.59;9984.67;1647.12;N.America;1867-07-01
AUS;Australia;25.47;7692.02;1408.68;Oceania;
KAZ;Kazakhstan;18.53;2724.9;159.41;Asia;1991-12-16
JSON 文件
JSON 是 JavaScript 对象表示法。JSON 文件是用于数据交换的明文文件,遵循 ISO/IEC 21778:2017 和 ECMA-404标准 并使用 .json 作为后缀扩展名。Python 和 Pandas 提供了 json 的内置支持并且可以很好地处理 JSON 文件。
.to_json() 保存数据到 json 文件。
df = pd.DataFrame(data).T
df.to_json('data-columns.json')
data-columns.json 有一个大字典,其中列标签作为键,对应的内部字典作为值。
index 结构 json 模式。
df.to_json('data-index.json', orient='index')
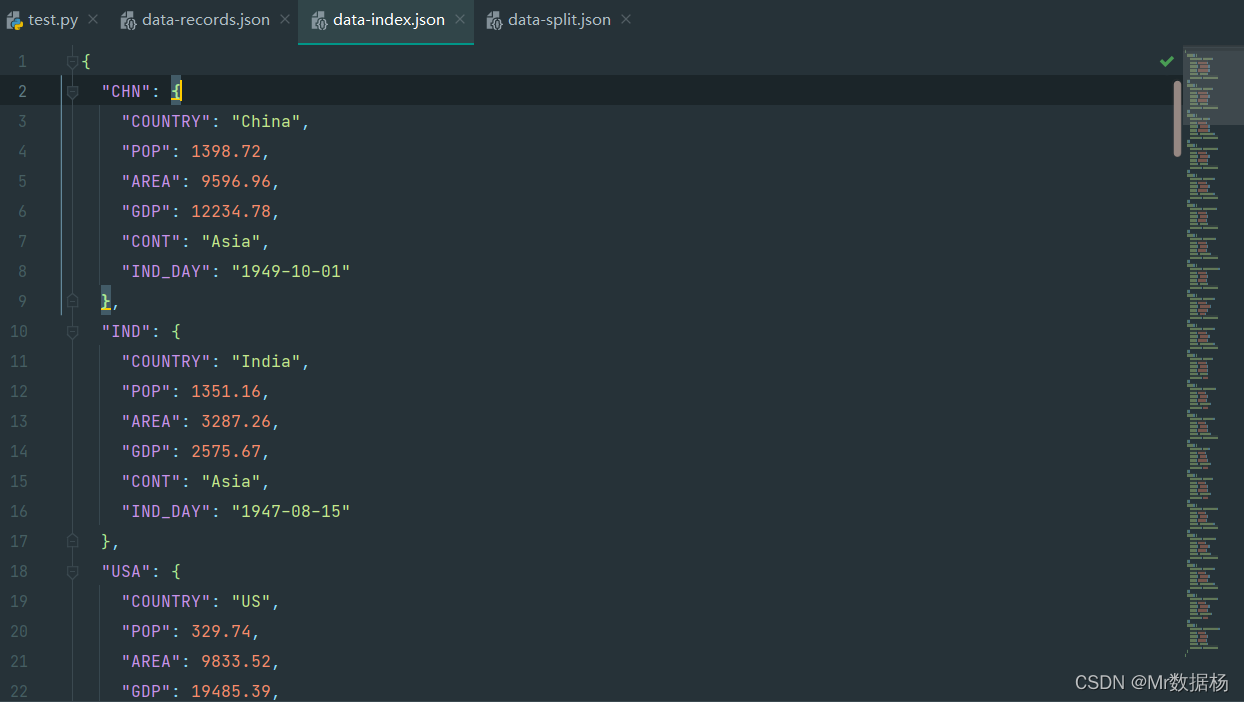
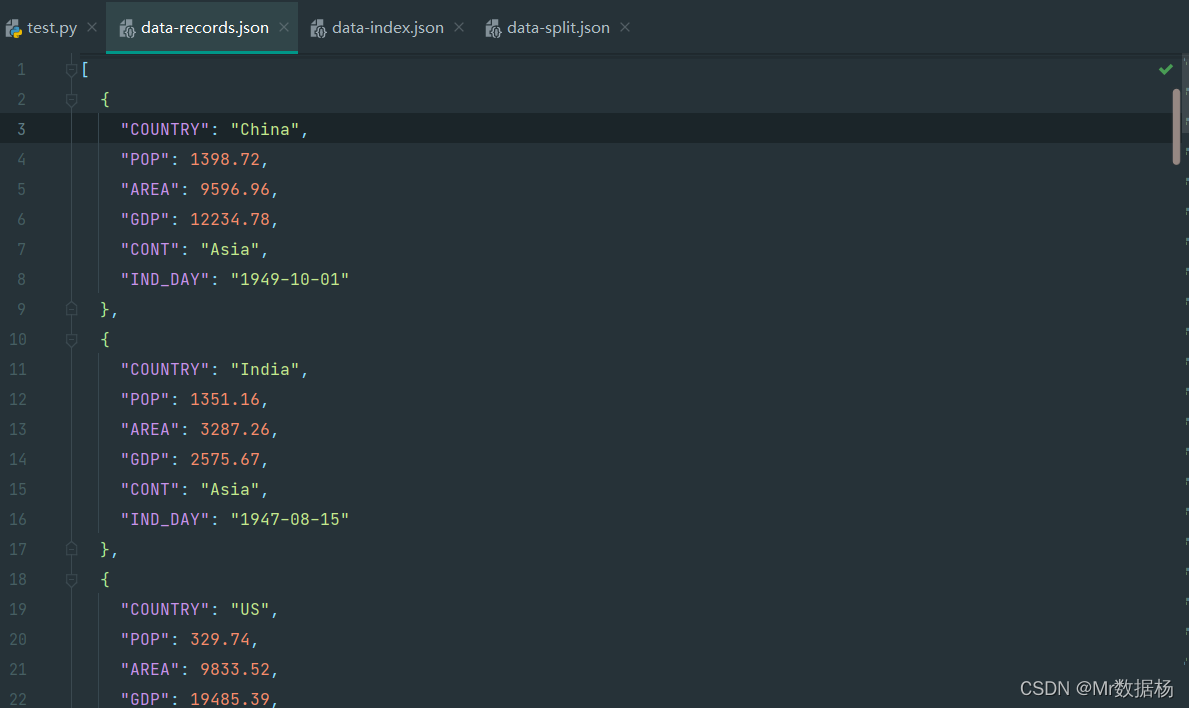
records 结构 json 模式。
df.to_json('data-records.json', orient='records')
split 结构 json 模式。
df.to_json('data-split.json', orient='split')
JSON 格式存储数据时,可能会丢失行和列的顺序,可以实现构建一列索引记录数据的顺序。
保存 json 文件的时还可以使用其他一些参数。
- encoding 设置编码。
- convert_dates 设置日期格式。
- dtype 和 precise_float 设置数据的精度。
- . 将数字数据直接解码为 NumPy 数组(numpy=True)。
HTML 文件
HTML是一个纯文本文件,使用超文本标记语言在浏览器呈现网页。HTML 文件的扩展名是 .html 和 .htm。需要安装 lxml 或者 html5lib 才能处理和解析 HTML 文件。
pip install lxml html5lib
.to_html() 保存数据到 html 文件。
df = pd.DataFrame(data).T
df.to_html('data.html')
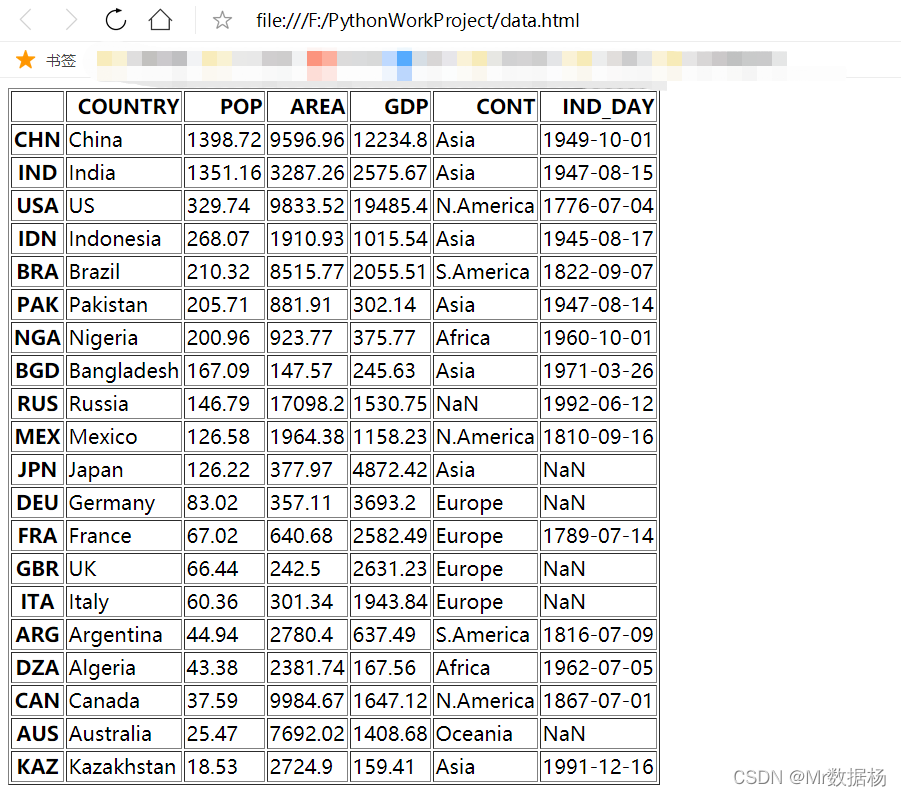
保存 html 文件的时还可以使用其他一些参数。
- header 是否保存列名。
- index 是否保存行标签。
- classes 分配级联样式表 CSS 类。
- render_links 指定是否将 URL 转换为 HTML 链接。
- table_id 将 CSS 分配给id标签table。
- escape 决定是否将字符<、>和转换&为 HTML 安全字符串。
Excel 文件
to_excel() 进行 excel 保存的时候还可以指定对应的 sheet 名。
df = pd.DataFrame(data).T
df.to_excel('data.xlsx', sheet_name='COUNTRIES')
并且还可以指定最开始写入的单元格。
df.to_excel('data-shifted.xlsx', sheet_name='COUNTRIES',startrow=2, startcol=4)

SQL 文件
Pandas IO 工具还可以读写数据库,需要使用 SQLAlchemy 进行操作。并且 Python 有一个内置的 SQLite 驱动程序。
安装 SQLAlchemy。
pip install sqlalchemy
使用 create_engine() 导入并创建数据库引擎。
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://user:password@localhost/database?charset=utf8')
.to_sql() 保存数据。
df.to_sql('table', con=engine,if_exists='append',index=0)

具有相同名称和路径的数据库可以使用的操作有:
- if_exists=‘fail’ 引发ValueError错误。
- if_exists=‘replace’ 删除表并插入新值。
- if_exists=‘append’ 将新值插入表中。
Pickle 文件
Pickling 是将 Python 对象转换为字节流的行为。Python pickle 文件是保存 Python 对象的数据和层次结构的二进制文件,通常具有扩展名 .pickle 或 .pkl。
.to_pickle() 保存数据。
dtypes = {
'POP': 'float64', 'AREA': 'float64', 'GDP': 'float64','IND_DAY': 'datetime64'}
df = pd.DataFrame(data).T.astype(dtype=dtypes)
df.to_pickle('data.pickle')
使用 read_pickle() 从 pickle 文件中获取数据。
df = pd.read_pickle('data.pickle')
df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia 1949-10-01
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaT
DEU Germany 83.02 357.11 3693.20 Europe NaT
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaT
ITA Italy 60.36 301.34 1943.84 Europe NaT
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaT
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
海量数据的应用
如果文件太大而无法保存或处理,可以采取多种方法来减少所需的磁盘空间的处理方式,例如:压缩文件、只选择你想要的列、省略不需要的行、强制使用不太精确的数据类型、将数据拆分成块 等方式。
压缩和解压缩文件
常用的文件后缀包括 ‘.gz’、’.bz2’、’.zip’、’.xz’。
Pandas 数据保存的时候可以自行推断压缩类型。
import pandas as pd
df = pd.DataFrame(data).T
df.to_csv('data.csv')
df.to_csv('data.csv.zip')
对比一下不同的保存方式。

然后可以使用 read_csv() 读取该文件。
df = pd.read_csv('data.csv.zip', index_col=0,parse_dates=['IND_DAY'])
df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia NaT
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaT
DEU Germany 83.02 357.11 3693.20 Europe NaT
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaT
ITA Italy 60.36 301.34 1943.84 Europe NaT
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaT
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
可以使用可选参数指定压缩类型,其中可选参数有:‘infer’、‘gzip’、‘bz2’、‘zip’、‘xz’、None。
pickle的文件压缩方法写入和读取的方法。
df = pd.DataFrame(data).T
df.to_pickle('data.pickle.compress', compression='gzip')
df = pd.read_pickle('data.pickle.compress', compression='gzip')
数据列的选取
可以使用 usecols 从加载文件中选择要读取的数据列。
df = pd.read_csv('data.csv', usecols=['COUNTRY', 'AREA'])
df.head(5)
COUNTRY AREA
0 China 9596.96
1 India 3287.26
2 US 9833.52
3 Indonesia 1910.93
4 Brazil 8515.77
也可以用使用列索引的方式读取数据。
df = pd.read_csv('data.csv',index_col=0, usecols=[0, 1, 3])
df.head(5)
COUNTRY AREA
CHN China 9596.96
IND India 3287.26
USA US 9833.52
IDN Indonesia 1910.93
BRA Brazil 8515.77
行省略
当数据应用与机器学习和深度学习模型的时候,可能不需要全部的数据集用于计算,仅仅加载需要计算容量的数据即可,因此可以使用选择行数据的方式进行。一般方式有3种:
- skiprows:在文件开头要跳过的行数,或者如果是类似列表的对象,则要跳过的行的从零开始的索引。
- skipfooter:文件末尾要跳过的行数。
- nrows:要读取的行数。
结合 range() 跳过奇数索引的行,保留偶数的行。
df = pd.read_csv('data.csv', index_col=0, skiprows=range(1, 20, 2))
强制使用不太精确的数据类型
这样做的最大好处就是可以节省大量的内存。
df.dtypes
COUNTRY object
POP float32
AREA float32
GDP float32
CONT object
IND_DAY datetime64[ns]
dtype: object
例如带有浮点数的列是 64 位浮点数,这种类型的每个数字 float64 占用 64 位或 8 个字节。如果是列是 32 位浮点数,这种类型的每个数字 float32 占用 32 位或 4 个字节。
表示的内容是一样的,但是内存空间节省了一半。
chunksize 块遍历
chunksize 可以将数据拆分为较小的块并一次处理一个块。
data_chunk = pd.read_csv('data.csv', index_col=0, chunksize=8)
可以结合 for 循环的方式拼接数据汇总要读取的全体数据信息。
for df_chunk in pd.read_csv('data.csv', index_col=0, chunksize=8):
print(df_chunk, end='\n\n')
print('memory:', df_chunk.memory_usage().sum(), 'bytes',
end='\n\n\n')
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia 1947-10-01
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
memory: 448 bytes
COUNTRY POP AREA GDP CONT IND_DAY
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.20 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
memory: 448 bytes
COUNTRY POP AREA GDP CONT IND_DAY
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
memory: 224 bytes