最近学RNN的时候对于其中各种输入输出都有点懵,然后参考了刘二大人关于pytorch实践以及下面这篇文章Pytorch深度学习实践(b站刘二大人)P13讲 (RNN循环神经网络高级篇)_努力学习的朱朱的博客-CSDN博客代码把维度问题整理了一下
一、pytorch中embedding在做什么?
我们先看下面这一段代码:
import torch
embedding = torch.nn.Embedding(10, 3)
print(embedding.weight) # 根据索引取embedding中的词向量
input = torch.LongTensor([[0,2,4,5],[4,3,2,0]])
output = embedding(input)
print(output)
print(output.shape)
这段代码输出如下:
Parameter containing:
tensor([[ 0.1540, -0.8776, -0.9737],
[-2.0864, -1.1387, -1.9999],
[ 0.3297, 1.2760, 0.4246],
[-0.4424, 1.0758, -1.3849],
[ 0.6420, -2.5247, -1.1060],
[ 1.0529, 1.3949, -1.0098],
[ 1.1634, -1.1316, -0.1378],
[ 1.3910, 0.9718, 0.1931],
[-1.9672, -0.5770, 1.0776],
[-0.4043, -0.9368, 3.2478]], requires_grad=True)
tensor([[[ 0.1540, -0.8776, -0.9737],
[ 0.3297, 1.2760, 0.4246],
[ 0.6420, -2.5247, -1.1060],
[ 1.0529, 1.3949, -1.0098]],
[[ 0.6420, -2.5247, -1.1060],
[-0.4424, 1.0758, -1.3849],
[ 0.3297, 1.2760, 0.4246],
[ 0.1540, -0.8776, -0.9737]]], grad_fn=<EmbeddingBackward0>)
torch.Size([2, 4, 3])我们可以看到embedding就是跟我我们设置的参数(词典大小vocab_size,词嵌入向量大小embedding_dim)随机生成一个对应维度的向量矩阵,而nn.embedding就相当于根据对应input的index在这个矩阵中取向量,比如input中[0,2,4,5]就对应了向量矩阵中的第0行,第2行,第4行以及第5行。在这个过程中,输入维度是【batch_size, seq_len】(批量大小,句子长度),输出维度是【batch_size, seq_len, embedding_size】。注意,在实际运用过程中输入【batch_size, seq_len】要进行转置再输入,这里写的是没有经过转置的对应维度,仅为了理解embedding的作用。
二、batch_size与seq_len
在TensorFlow中有专门的seq_len来对应于句子长度,但是pytorch中参数如下:
class torch.nn.LSTM(*args, **kwargs) :
input_size:x的特征维度
hidden_size:隐藏层的特征维度
num_layers:lstm隐层的层数,默认为1
bias:False则bihbih=0和bhhbhh=0. 默认为True
batch_first:True则输入输出的数据格式为 (batch, seq, feature)
dropout:除最后一层,每一层的输出都进行dropout,默认为: 0
bidirectional:True则为双向lstm默认为False显然是没有seq_len,那么在pytorch中我们是怎么解决这个问题的呢?这就需要我们自己在数据输入LSTM前将数据进行padding为同一纬度的向量,对于pytorch中LSTM来说,只要保证每一个batch中的seq_len相同即可。一般来说我们有两种方法:
1.自己构造DataLoader:将每个batch_size中的句子都填充为该batch中最长句子的长度(该方法后面讲)
2.用pytorch中的torch.utils.data.Data.TensorDataset和torch.utils.data.DataLoader,使用这个就需要在最开始就把句子都padding为同一长度,用下面方法:
def truncate_pad(line, num_steps, padding_token):
"""截断或填充文本序列"""
if len(line) > num_steps:
return line[:num_steps] # 截断
return line + [padding_token] * (num_steps - len(line)) # 填充
num_steps = 100 #设置padding维度
train_features = torch.tensor([truncate_pad(
vocab[line], num_steps, vocab['<pad>']) for line in tokens])
train_dataset = Data.TensorDataset(X_train, torch.tensor(y_train)) #构造为Dataset
trainloader = DataLoader(train_dataset, batch_size=BATCH_SIZE,shuffle=True) #构造为DataLoader
三、RNN模型的维度
下面就用刘二大人pytorch教学(《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili)中的例子来看看数据在LSTM中流转过程各个维度是怎样的
import torch
import random
import time
import csv
import gzip
from torch.utils.data import DataLoader
import datetime
import matplotlib.pyplot as plt
import numpy as np
# Parameters
HIDDEN_SIZE = 100
BATCH_SIZE = 32
N_LAYER = 2
N_EPOCHS = 20
N_CHARS = 128
USE_GPU = False
class NameDataset(): #处理数据集
def __init__(self, is_train_set=True):
filename = 'names_train.csv.gz' if is_train_set else 'names_test.csv.gz'
with gzip.open(filename, 'rt') as f:
reader = csv.reader(f)
rows = list(reader)
random.shuffle(rows)
rows = rows[:256]
self.names = [row[0] for row in rows] #取出人名
self.len = len(self.names) #人名数量
self.countries = [row[1] for row in rows]#取出国家名
self.country_list = list(sorted(set(self.countries)))#国家名集合,18个国家名的集合
#countrys是所有国家名,set(countrys)把所有国家明元素设为集合(去除重复项),sorted()函数是将集合排序
#测试了一下,实际list(sorted(set(self.countrys)))==sorted(set(self.countrys))
self.country_dict = self.getCountryDict()#转变成词典
self.country_num = len(self.country_list)#得到国家集合的长度18
def __getitem__(self, index):
return self.names[index], self.country_dict[self.countries[index]]
def __len__(self):
return self.len
def getCountryDict(self):
country_dict = dict() #创建空字典
for idx, country_name in enumerate(self.country_list,0): #取出序号和对应国家名
country_dict[country_name] = idx #把对应的国家名和序号存入字典
return country_dict
def idx2country(self,index): #返回索引对应国家名
return self.country_list(index)
def getCountrysNum(self): #返回国家数量
return self.country_num
trainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE,shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE,shuffle=False)
for item in trainloader:
print(item)
N_COUNTRY = trainset.getCountrysNum() 为了方便展示,我只选择了其中256来演示,我们可以看一下样本转为dataloader后的样子:

每一个batch由32个名字和对应国家组成,接下俩我们需要将其转变为向量
def name2list(name):
"""返回ASCII码表示的姓名列表与列表长度"""
arr = [ord(c) for c in name]
return arr, len(arr)
def make_tensors(names, countries):
sequences_and_lengths = [name2list(name) for name in names]表
name_sequences = [sl[0] for sl in sequences_and_lengths]
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths])
countries = countries.long()
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx]
return seq_tensor, seq_lengths, countries这段代码做的其实就是把每个batch转化为每个名字长度一致的向量,每一个batch向量维度为:batch*seq_len
我们可以看一下处理后的数据:
for i, (names, countries) in enumerate(trainloader, 1):
print('names',names, 'Coounties',countries)
inputs, seq_lengths, target = make_tensors(names, countries)
print('inputs, seq_lengths, target',inputs, seq_lengths, target)
print('inputs.shape',inputs.shape)
names ('Balawin', 'Likhovtsev', 'Cullen', 'Abadi', 'Uzky', 'Moshnyaga', 'Abrosimov', 'Fencl', 'Antar', 'Pastore', 'Matjeka', 'Larsen', 'Mikhalkov', 'Chavez', 'Agoshkov', 'Hasek', 'Fedotko', 'Koury', 'Winter', 'Hautem', 'Dioli', 'Chershintsev', 'Herbert', 'Anami', 'Makferson', 'Christakos', 'Molnovetsky', 'Tsagareli', 'Hublaryan', 'Matskovsky', 'Radford', 'Antyushin') Coounties tensor([13, 13, 4, 0, 13, 13, 13, 2, 0, 9, 2, 4, 13, 14, 13, 6, 13, 0,
4, 3, 9, 13, 4, 10, 13, 7, 13, 13, 13, 13, 4, 13])
inputs, seq_lengths, target tensor([[ 67, 104, 101, 114, 115, 104, 105, 110, 116, 115, 101, 118],
[ 77, 111, 108, 110, 111, 118, 101, 116, 115, 107, 121, 0],
[ 76, 105, 107, 104, 111, 118, 116, 115, 101, 118, 0, 0],
[ 67, 104, 114, 105, 115, 116, 97, 107, 111, 115, 0, 0],
[ 77, 97, 116, 115, 107, 111, 118, 115, 107, 121, 0, 0],
[ 77, 111, 115, 104, 110, 121, 97, 103, 97, 0, 0, 0],
[ 65, 98, 114, 111, 115, 105, 109, 111, 118, 0, 0, 0],
[ 77, 105, 107, 104, 97, 108, 107, 111, 118, 0, 0, 0],
[ 77, 97, 107, 102, 101, 114, 115, 111, 110, 0, 0, 0],
[ 84, 115, 97, 103, 97, 114, 101, 108, 105, 0, 0, 0],
[ 72, 117, 98, 108, 97, 114, 121, 97, 110, 0, 0, 0],
[ 65, 110, 116, 121, 117, 115, 104, 105, 110, 0, 0, 0],
[ 65, 103, 111, 115, 104, 107, 111, 118, 0, 0, 0, 0],
[ 66, 97, 108, 97, 119, 105, 110, 0, 0, 0, 0, 0],
[ 80, 97, 115, 116, 111, 114, 101, 0, 0, 0, 0, 0],
[ 77, 97, 116, 106, 101, 107, 97, 0, 0, 0, 0, 0],
[ 70, 101, 100, 111, 116, 107, 111, 0, 0, 0, 0, 0],
[ 72, 101, 114, 98, 101, 114, 116, 0, 0, 0, 0, 0],
[ 82, 97, 100, 102, 111, 114, 100, 0, 0, 0, 0, 0],
[ 67, 117, 108, 108, 101, 110, 0, 0, 0, 0, 0, 0],
[ 76, 97, 114, 115, 101, 110, 0, 0, 0, 0, 0, 0],
[ 67, 104, 97, 118, 101, 122, 0, 0, 0, 0, 0, 0],
[ 87, 105, 110, 116, 101, 114, 0, 0, 0, 0, 0, 0],
[ 72, 97, 117, 116, 101, 109, 0, 0, 0, 0, 0, 0],
[ 65, 98, 97, 100, 105, 0, 0, 0, 0, 0, 0, 0],
[ 70, 101, 110, 99, 108, 0, 0, 0, 0, 0, 0, 0],
[ 65, 110, 116, 97, 114, 0, 0, 0, 0, 0, 0, 0],
[ 72, 97, 115, 101, 107, 0, 0, 0, 0, 0, 0, 0],
[ 75, 111, 117, 114, 121, 0, 0, 0, 0, 0, 0, 0],
[ 68, 105, 111, 108, 105, 0, 0, 0, 0, 0, 0, 0],
[ 65, 110, 97, 109, 105, 0, 0, 0, 0, 0, 0, 0],
[ 85, 122, 107, 121, 0, 0, 0, 0, 0, 0, 0, 0]]) tensor([12, 11, 10, 10, 10, 9, 9, 9, 9, 9, 9, 9, 8, 7, 7, 7, 7, 7,
7, 6, 6, 6, 6, 6, 5, 5, 5, 5, 5, 5, 5, 4]) tensor([13, 13, 13, 7, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 9, 2, 13, 4,
4, 4, 4, 14, 4, 3, 0, 2, 0, 6, 0, 9, 10, 13])
inputs.shape torch.Size([32, 12])这里展示的就是一个batch的数据情况,接下来就开始构造我们的RNN模型,这里用的是GRU
class RNNClassifier(torch.nn.Module):
def __init__(self, vocab_size, embedding_size, output_size, n_layers=1, bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = embedding_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(vocab_size, embedding_size)#input.shape=(seqlen,batch) output.shape=(seqlen,batch,hiddensize)
self.gru = torch.nn.GRU(embedding_size, self.hidden_size , n_layers, bidirectional=bidirectional)
self.fc = torch.nn.Linear(self.hidden_size * self.n_directions, output_size)
def forward(self, input, seq_lengths):
input = input.t()
print('input.shape',input.shape)
batch_size = input.size(1)
hidden =self._init_hidden(batch_size)
print('hidden shape',hidden.shape)
embedding = self.embedding(input)
print('embedding shape',embedding.shape)
seq_lengths = seq_lengths.cpu()
output, hidden = self.gru(embedding, hidden)
print("output, hidden",output.shape, hidden.shape)
if self.n_directions ==2:
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)
else:
hidden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
def _init_hidden(self,batch_size):
hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size)
return create_tensor(hidden)然后开始训练模型
def trainModel():
total_loss = 0
for i, (names, countries) in enumerate(trainloader, 1):
optimizer.zero_grad()
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths) #把输入和序列放入分类器
loss = criterion(output, target) #计算损失
loss.backward()
optimizer.step()
total_loss += loss.item()
#打印输出结果
if i == len(trainset) // BATCH_SIZE :
print(f'loss={total_loss / (i * len(inputs))}')
return total_loss
print("Train for %d epochs..." % N_EPOCHS)
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
if USE_GPU:
device = torch.device('cuda:0')
classifier.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr = 0.001)
for epoch in range(1, N_EPOCHS+1):
#训练
print('%d / %d:' % (epoch, N_EPOCHS))
trainModel()
我们可以看一下维度的情况(只截取了部分结果):,
Train for 20 epochs...
1 / 20:
input.shape torch.Size([10, 32])
hidden shape torch.Size([4, 32, 100])
embedding shape torch.Size([10, 32, 100])
output, hidden torch.Size([10, 32, 200]) torch.Size([4, 32, 100])
input.shape torch.Size([14, 32])
hidden shape torch.Size([4, 32, 100])
embedding shape torch.Size([14, 32, 100])
output, hidden torch.Size([14, 32, 200]) torch.Size([4, 32, 100])
input.shape torch.Size([13, 32])
hidden shape torch.Size([4, 32, 100])
embedding shape torch.Size([13, 32, 100])
output, hidden torch.Size([13, 32, 200]) torch.Size([4, 32, 100])
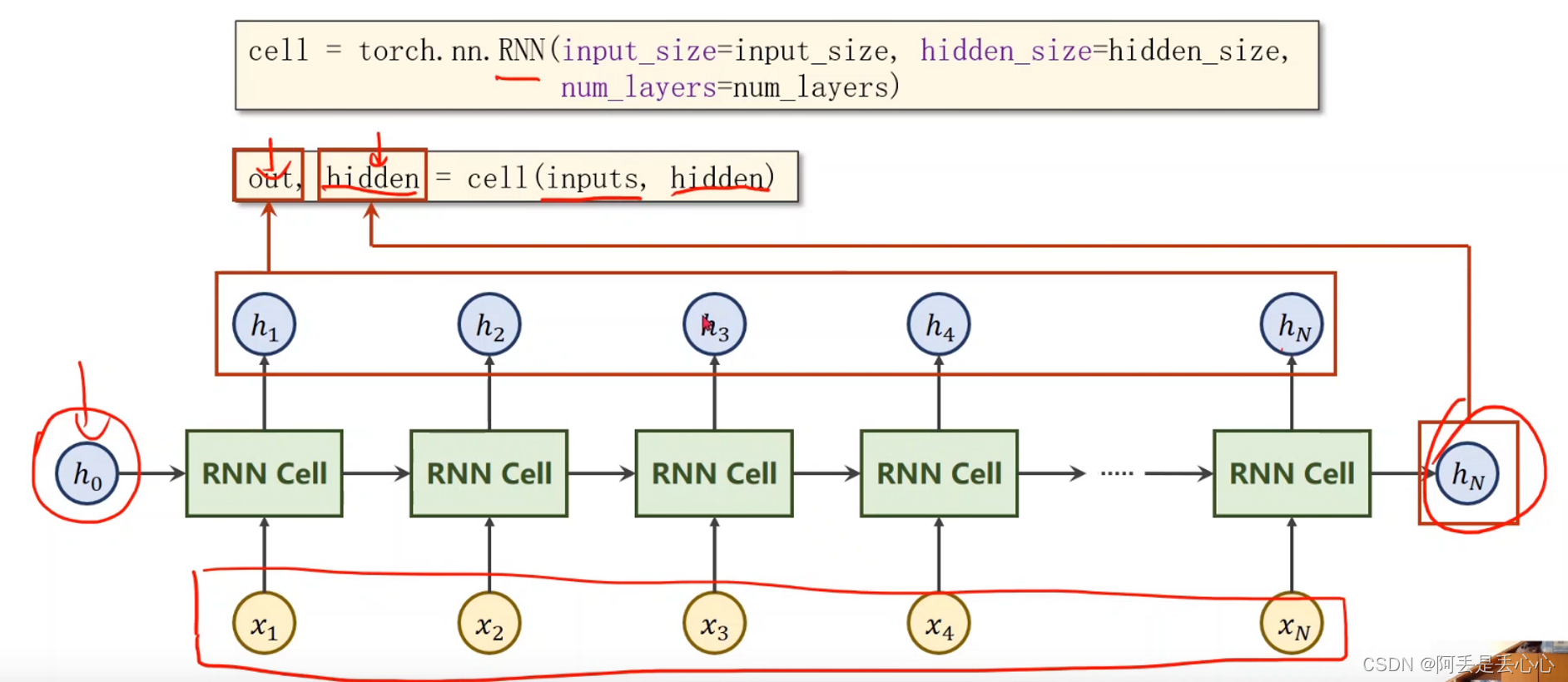
input就是我们经过向量化的一个batch向量,因为在这里进行了转置,由之前的(batch_size, seq_len)变为了(seq_len,batch_size),其中seq_len就对应于一个batch中最长的单词(句子)长度
hidden就是GRU中隐藏层输出(最开始我们先初始化h0),它对应的维度是(n_layers * n_directions, batch_size, hidden_size)
embedding代表的是input经过nn.Embedding层计算后得到的结果,他的维度是:(seq_len,batch_size, embedding_size)
经过GRU模型后有两个输出结果,output:(seq_len, batch, n_directions*hidden_size),hn:(n_layers*n_directions, batch, hiddem_size)
这里的output和hn分别对应的是中间所有输出以及最后隐藏层输出:
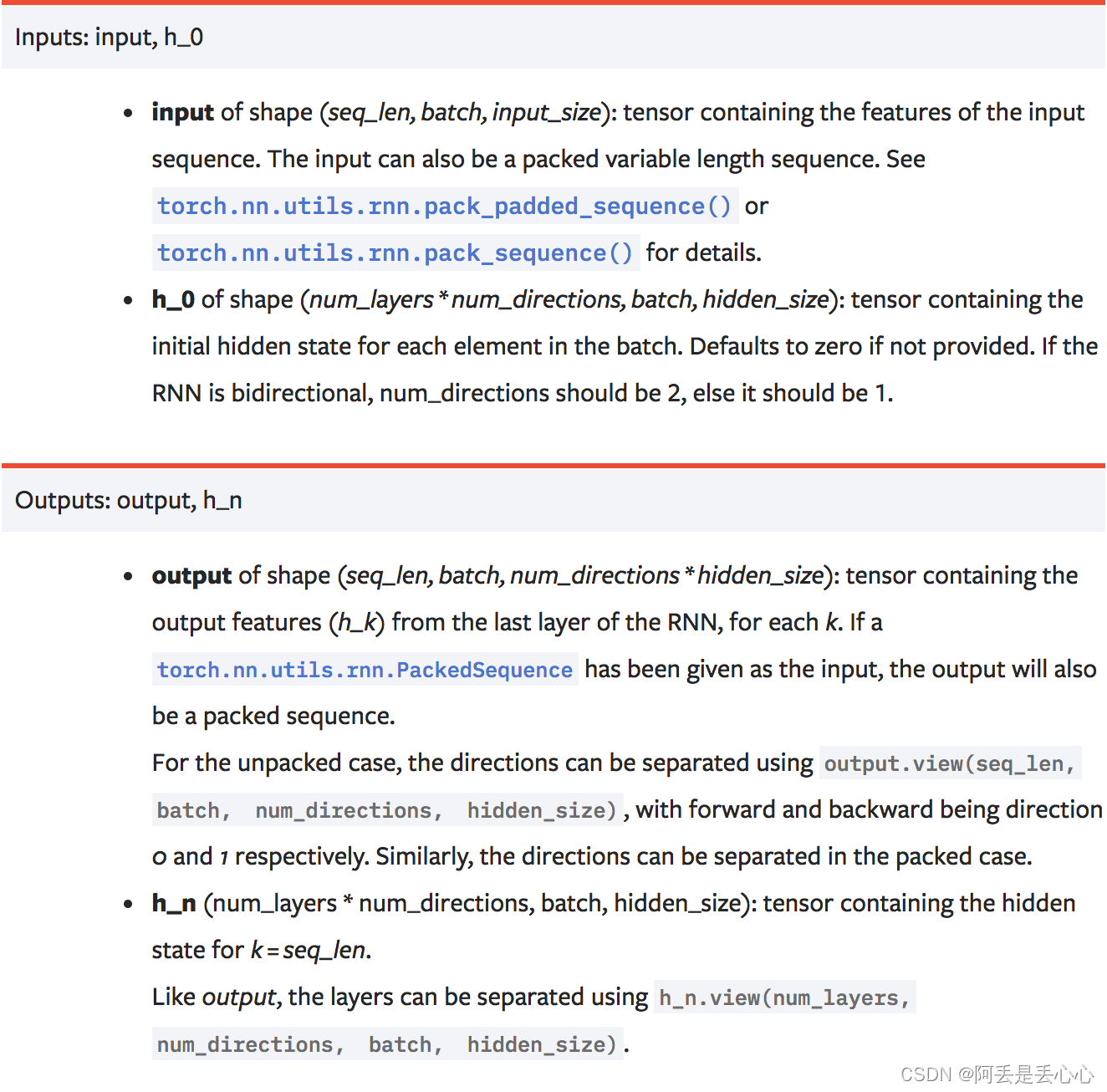
 也可以直接看官方说明:
也可以直接看官方说明:
这篇文章主要讲了一下RNN模型的维度问题,希望对大家有帮助!